časová Synchronizace v Distribuovaných Systémech
pokud se ocitnete obeznámeni s webovými stránkami, jako jsou facebook.com nebo google.s, možná ne méně než jednou jste přemýšleli, jak tyto webové stránky zvládnou miliony nebo dokonce desítky milionů požadavků za sekundu. Bude existovat nějaký jediný komerční server, který vydrží toto obrovské množství požadavků, v tom smyslu, že každá žádost může být doručena včas koncovým uživatelům?
Potápění hlouběji do této záležitosti, jsme dorazili na koncept distribuované systémy, kolekce nezávislých počítačů (nebo uzly), které se jeví svým uživatelům jako jeden souvislý systém. Tento pojem koherence pro uživatele, je jasné, protože věří, že jsou co do činění s jeden obrovský stroj, který má podobu více procesů běží paralelně zpracovat šarží žádostí najednou. Pro lidi, kteří chápou systémovou infrastrukturu, se však věci jako takové neukazují tak snadno.
Pro tisíce nezávislých strojů současně běžících, které mohou přesahovat přes více časových pásem a kontinentů, některé typy synchronizace nebo koordinace musí být uvedeny pro tyto stroje efektivně spolupracovat s navzájem (tak, že se mohou objevit jako jeden). V tomto blogu budeme diskutovat o synchronizaci času a o tom, jak dosahuje konzistence mezi stroji při objednávání a kauzalitě událostí.
obsah tohoto blogu bude uspořádán následovně:
- synchronizace hodin
- logické hodiny
- Take away
- co bude dál?
fyzické hodiny
v centralizovaném systému je čas jednoznačný. Téměř všechny počítače mají “hodiny reálného času” sledovat čas, obvykle v synchronizaci s přesně opracovaný křemen. Na základě dobře definované kmitočtové oscilace tohoto křemene může operační systém počítače přesně sledovat vnitřní čas. I když je počítač vypnutý nebo jde ven poplatku, quartz pokračuje klíště vzhledem k CMOS baterie, malý powerhouse integrované na základní desce. Když se počítač připojí k síti (Internetu), OS pak kontakty časovač server, který je vybaven UTC přijímač nebo přesné hodiny, aby přesně obnovit místní časovač, pomocí Network Time Protocol, také volal NTP.
i když je tato frekvence krystalového křemene přiměřeně stabilní, není možné zaručit, že všechny krystaly různých počítačů budou pracovat na přesně stejné frekvenci. Představte si systém s n počítači, jejichž každý krystal běží mírně odlišnými rychlostmi, což způsobí, že se hodiny postupně dostanou ze synchronizace a při čtení dávají různé hodnoty. Rozdíl v časových hodnotách způsobených tímto se nazývá zkosení hodin.
za těchto okolností se věci dostaly do nepořádku za to, že mají více prostorově oddělených strojů. Pokud je žádoucí použití více vnitřních fyzických hodin, jak je synchronizujeme s hodinami v reálném světě? Jak je můžeme synchronizovat mezi sebou?
Network Time Protocol
společný přístup pro páru-wise synchronizace mezi počítači je pomocí modelu klient-server.e nechat klienty kontaktovat server. Podívejme se na následující příklad s 2 automaty a a B:
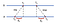
nejprve a odešle časové označení požadavku s hodnotou T₀ na B. B, jako přijde zpráva, záznamy okamžiku přijetí T₁ z vlastních místní čas a odpovědi, s poselstvím timestamped s T₂, využívá dříve zaznamenané hodnoty T₁. A konečně, A, po obdržení odpovědi od B, zaznamenává čas příjezdu T₃. Do účtu za dobu prodlení v doručování zpráv, počítáme Δ₁ = T₁-T₀, Δ₂ = T₃-T₂. Nyní, odhadem posun vzhledem k B je:

na základě θ můžeme buď zpomalit hodiny A, nebo je upevnit tak, aby mohly být oba stroje vzájemně synchronizovány.
vzhledem k tomu, že NTP je použitelný v páru, lze hodiny B nastavit na hodiny A. Je však nerozumné nastavit hodiny v B, pokud je známo, že jsou přesnější. Chcete-li tento problém vyřešit, NTP rozděluje servery do vrstev, jsem.e pořadí serverů, takže hodiny od méně přesné servery s menší hodností budou synchronizovány k těm přesnější ty s vyšší hodností.
Berkeley Algoritmus
V kontrastu s klienty pravidelně kontaktovat server pro přesné synchronizace času, Gusella a Zatti, v roce 1989 Berkeley Unix papír , navrhla model klient-server, ve kterém časový server (daemon) průzkumy veřejného mínění, každý stroj pravidelně se zeptat, kolik je tam. Na základě odpovědí, vypočítá round-trip pro zprávy, průměry aktuální čas s neznalostí jakéhokoli odlehlých hodnot v časových hodnot, “vypráví všechny ostatní stroje, aby se předem jejich hodiny na nový čas nebo zpomalit jejich hodiny dolů, dokud některé uvedené snížení haw bylo dosaženo” .
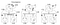
logické hodiny
udělejme krok zpět a přehodnotíme naši základnu pro synchronizovaná časová razítka. V předchozí části jsme přiřadit konkrétní hodnoty pro všechny zúčastněné stroje’ hodiny, od nynějška mohou dohodnout na globální časové ose na události, které se dějí během spuštění systému. Na celé časové ose však skutečně záleží pořadí, ve kterém k souvisejícím událostem dochází. Například, pokud se nějak potřebujeme pouze vědět, událost se děje před událostí B, nezáleží na tom, jestli Tₐ = 2, Tᵦ = 6 nebo Tₐ = 4, Tᵦ = 10, tak dlouho, jak Tₐ < Tᵦ. To posouvá naši pozornost do oblasti logických hodin, kde je synchronizace ovlivněna definicí vztahu “stane se před” Leslie Lamport .
Lamport je Logické Hodiny
V jeho fenomenální 1978 papír, Čas, Hodiny, a Řazení Akcí v distribuovaném Systému , Lamport definovanými “stane-před” vztah “→” takto:
1. Pokud a A b jsou události ve stejném procesu a a přichází před b, pak a→b.
2. Pokud je odeslání zprávy jedním procesem a b je příjem stejné zprávy od jiného procesu, pak a→b.
3. Pokud a→b a b→c, pak a→c.
Pokud se události x, y se vyskytují v různé procesy, které nemusíte vyměňovat zprávy, ani x → y ani y → x platí, že x a y jsou řekl, aby být souběžné. Vzhledem k funkci C, která přiřadí časovou hodnotu C (a) pro událost, na které se všechny procesy shodují, pokud a A b jsou události v rámci stejného procesu a a nastane před b, C(a) < C (b)*. Podobně, pokud a je odeslání zprávy jedním procesem a b je příjem této zprávy jiným procesem, C (a) < C (b)**.
nyní se podívejme na algoritmus, který Lamport navrhl pro přiřazení časů událostem. Zvažte následující příklad s clusterem 3 procesy A, B, C:

hodiny těchto 3 procesů pracují na vlastním načasování a jsou zpočátku mimo synchronizaci. Každé hodiny mohou být implementovány pomocí jednoduchého softwarového čítače, zvyšovaného o určitou hodnotu každých t časových jednotek. Nicméně, hodnoty, o které hodiny je zvýšen liší na proces: 1 pro A, 5 pro B, a 2 pro C
V čase 1, pošle zprávu m1 do bodu B. V době příjezdu, hodiny na B čte 10 ve své vnitřní hodiny. Od té doby, co byla zpráva odeslána byla timestamped s časem 1, hodnota 10 v procesu B je jistě možné (můžeme odvodit, že to trvalo 9 klíšťata, aby se dospělo B z).
nyní zvažte zprávu m2. Opouští B v 15 a dorazí na C v 8. Tato hodnota hodin na C je zjevně nemožná, protože čas nemůže jít zpět. Z ** a skutečnost, že m2 opouští v 15, musí dorazit na 16 nebo později. Proto musíme aktualizovat aktuální hodnotu času na C, aby byla větší než 15 (pro jednoduchost přidáme +1 k času). Jinými slovy, když přijde zpráva a přijímač je hodiny ukazují hodnotu, která předchází časové razítko, které označuje zprávu odeslání, přijímač rychle dopředu jeho času jeden jednotku času více, než čas odjezdu. Na obrázku 6 vidíme, že m2 nyní koriguje hodnotu hodin na C až 16. Podobně m3 a m4 dorazí na 30 a 36.
Z výše uvedeného příkladu, Maarten van Steen et al formuluje Lamport algoritmus takto:
1. Před provedením události (tj. odeslání zprávy přes síť,…), pᵢ zvýší cᵢ: c
2. Když proces P sends odešle zprávu m ke zpracování Pj, nastaví m časové razítko ts (m) se rovná Cᵢ po provedení předchozího kroku.
3. Po přijetí zprávy m upraví proces Pj vlastní lokální čítač jako Cj < – max{Cj, ts (m)}, po kterém provede první krok a doručí zprávu do aplikace.
Vektorové Hodiny
vzpomeň si na Lamport definice “stane-před” vztah, pokud jsou dvě události a a b takové, že se vyskytuje dříve než b, pak a je také umístěn v objednávce před b, je C(a) < C(b). Nicméně, to neznamená, reverzní kauzality, protože nemůžeme odvodit, že jde před b pouze porovnáním hodnot C(a) C(b) (důkaz je ponechán jako cvičení pro čtenáře).
aby získali více informací o objednání událostí na základě jejich časové razítko, Vektorové Hodiny, pokročilejší verze Lamport je Logické Hodiny, se navrhuje. Pro každý proces Pᵢ systému algoritmus udržuje vektor VCᵢ s následujícími atributy:
1. VCᵢ: místní logické hodiny na Pᵢ nebo počet událostí, ke kterým došlo před aktuálním časovým razítkem.
2. Pokud VCᵢ = k, Pᵢ ví, že k události došlo v Pj.
algoritmus vektorových hodin pak jde následovně:
1. Před provedením události P records zaznamená, že se nová událost stane sama o sobě spuštěním VC
2. Když Pᵢ odešle zprávu m PJ, nastaví časové razítko ts (m) rovnající se VCᵢ po provedení předchozího kroku.
3. Když je přijata zpráva m, proces PJ aktualizovat každý k vlastních vektorových hodin: VCJ max max { VCJ, ts (m)}. Poté pokračuje v provádění prvního kroku a doručí zprávu do aplikace.
Podle těchto kroků, pokud proces Pj obdrží zprávu m z procesu Pᵢ s časové razítko ts(m), ví, že počet událostí, které nastaly v Pᵢ mimochodem předcházelo zaslání m. Navíc, Pj také ví o událostech, které byly známé Pᵢ o dalších procesů před zasláním m. (Ano, to je pravda, pokud jste týkajících tento algoritmus Drby Protokolu 🙂).
doufejme, že vysvětlení vás nenechá příliš dlouho poškrábat hlavu. Pojďme se ponořit do příkladu, abychom zvládli koncept:

V tomto příkladu máme tři procesy P₁, P₂, a P₃ případně výměnu zpráv synchronizovat své hodiny spolu. P₁ odešle zprávu m1 v logickém čase VC₁ = (1, 0, 0) (Krok 1) na P₂. P₂, po obdržení m1 s časové razítko ts(m1) = (1, 0, 0), upravuje své logické čas VC₂ k (1, 1, 0) (krok 3) a odešle zprávu m2 zpátky do P₁ s timestamp (1, 2, 0) (krok 1). Podobně proces P₁ přijímá zprávu m2 z P₂, mění své logické hodiny na (2, 2, 0) (Krok 3), poté vyšle zprávu m3 na P at na (3, 2, 0). P₃ upraví hodiny na (3, 2, 1) (Krok 1) poté, co obdrží zprávu m3 z P₁. Později přijme zprávu m4, odeslanou P at v (1, 4, 0), a tím upraví své hodiny na (3, 4, 2) (Krok 3).
na základě toho, jak rychle posuneme interní hodiny pro synchronizaci, událost a předchází událost B, pokud pro všechny k, ts(a) ≤ ts(b), a existuje alespoň jeden index k’, pro který ts (a) < ts(b). Není těžké vidět ,že (2, 2, 0) předchází (3, 2, 1), ale (1, 4, 0) a (3, 2, 0) se mohou navzájem konfliktovat. Proto pomocí vektorových hodin můžeme zjistit, zda existuje příčinná závislost mezi dvěma událostmi.
Take away
pokud jde o koncept času v distribuovaném systému, primárním cílem je dosáhnout správného pořadí událostí. Události mohou být umístěny buď v chronologickém pořadí s fyzickými hodinami, nebo v logickém pořadí s Lamtportovými logickými hodinami a vektorovými hodinami podél časové osy provádění.
co bude dál?
Další v řadě, se budeme jít nad tím, jak čas synchronizace může poskytnout překvapivě jednoduché odpovědi na některé typické problémy v distribuovaných systémech: na-většinou-one zprávy , mezipaměti soudržnost a vzájemné vyloučení .
Leslie Lamport: Čas, Hodiny a uspořádání událostí v distribuovaném systému. 1978.
Barbara Liskov: praktické využití synchronizovaných hodin v distribuovaných systémech. 1993.
Maarten van Steen, Andrew s. Tanenbaum: distribuované systémy. 2017.
Barbara Liskov, Liuba Shrira, John Wroclawski: Efektivní nanejvýš jednou zprávy založené na synchronizovaných hodinách. 1991.
Cary G. Gray, David R. Cheriton: Leases: účinný mechanismus Odolný proti chybám pro konzistenci mezipaměti distribuovaných souborů. 1989.
Ricardo Gusella, Stefano Zatti: přesnost synchronizace hodin dosažená tempem v Berkeley UNIX 4.3 BSD. 1989.