Škálovatelné, Distribuované Sekundární Indexování v Scylla

datový model v Skyllou a Apache Cassandra oddíly dat mezi uzly clusteru pomocí klíč oddílu, která je definována podle schématu databáze. Použití klíče oddílu poskytuje efektivní způsob, jak vyhledat řádky pomocí klíče oddílu, protože uzel, který vlastní řádek, můžete najít pomocí klíče oddílu. Bohužel to také znamená, že nalezení řádku pomocí klíče bez oddílu vyžaduje úplné skenování tabulky, které je neefektivní. Sekundární indexy jsou v Apache Cassandra mechanismem, který umožňuje efektivní vyhledávání klíčů bez oddílů vytvořením indexu.
v tomto blogu se dozvíte:
- Jak Apache Cassandra implementuje Sekundární Indexy pomocí místní indexování
- důvod, Proč jsme se rozhodli přijmout jiné provádění strategie pro Scyllu pomocí globální indexování
- Jak globální indexování ovlivňuje, jak byste měli použít Sekundární Indexování
- Jak vytvořit svůj vlastní Sekundární Indexy a jejich použití v aplikaci CQL dotazy
Pozadí
Velikost indexu je úměrná velikosti indexovaných údajů. Jako data v Skyllou a Apache Cassandra je distribuován do více uzlů, je to nepraktické ukládat celý index na jeden uzel. Apache Cassandra implementuje sekundární indexy jako lokální indexy, což znamená, že index je uložen na stejném uzlu jako data, která jsou indexována z tohoto uzlu. Ve prospěch místní index se píše, že jsou velmi rychlé, ale nevýhodou je, že čte mít potenciálně dotaz každý uzel najít index provádět vyhledávání, které umožňuje místní indexy nezdolatelné na velké shluky. Kromě nativních sekundárních indexů má Apache Cassandra také další místní indexovací schéma, Sstable Attached Secondary Index (SASI), které podporuje složité dotazy a vyhledávání. Z hlediska škálovatelnosti má však přesně stejné vlastnosti jako původní sekundární indexy.
Materializované pohledy v Skyllou a Apache Cassandra je mechanismus, který automaticky denormalize dat ze základní tabulky na zobrazení tabulky pomocí různých partition key. To řeší problém škálovatelnosti místních indexů, ale přichází s náklady na úložiště, protože v nejhorším případě musíte duplikovat celou tabulku. Zhmotněné pohledy proto nenahrazují sekundární indexy pro všechny případy použití. Materializované pohledy však poskytují nezbytnou infrastrukturu pro implementaci sekundárních indexů pomocí globálního indexování, což je implementační přístup pro Scyllu.
Globální Indexování
Scylla má jiný přístup než Apache Cassandra a realizuje Sekundární Indexy pomocí globální indexování. Při globálním indexování se pro každý index vytvoří Zhmotněný pohled. Materializované zobrazení má indexovaný sloupec jako klíč oddílu a primární klíč (klíč oddílu a klíče shlukování) indexovaného řádku jako klíče shlukování. Scylla rozděluje indexované dotazy na dvě části: (1) dotaz v tabulce indexu pro načtení klíčů oddílů pro indexovanou tabulku a (2) dotaz do indexované tabulky pomocí načtených klíčů oddílů. Výhodou tohoto přístupu je, že můžeme použít hodnotu indexovaného sloupce k nalezení odpovídajícího řádku indexové tabulky v clusteru, takže čtení je škálovatelné. Nevýhodou tohoto přístupu je, že zápisy jsou pomalejší než s místní indexování, protože všechny režijní vedení index zobrazit up-to-date.
dotaz na indexovaný sloupec vypadá následovně. Předpokládejme, že tabulka, která vypadá takto:
A dotaz na email sloupec, který není klíč oddílu, ale má index:
V první fázi (1), dotaz dorazí na uzel 7, který působí jako koordinátor pro dotaz. Uzel si všimne, že dotazujeme na indexovaný sloupec, a proto ve fázi (2) vydá tabulku read to index v uzlu 2, která má řádek indexové tabulky pro “”. Dotaz vrací sadu ID uživatelů, které se používají ve fázi (3) k načtení obsahu indexované tabulky.
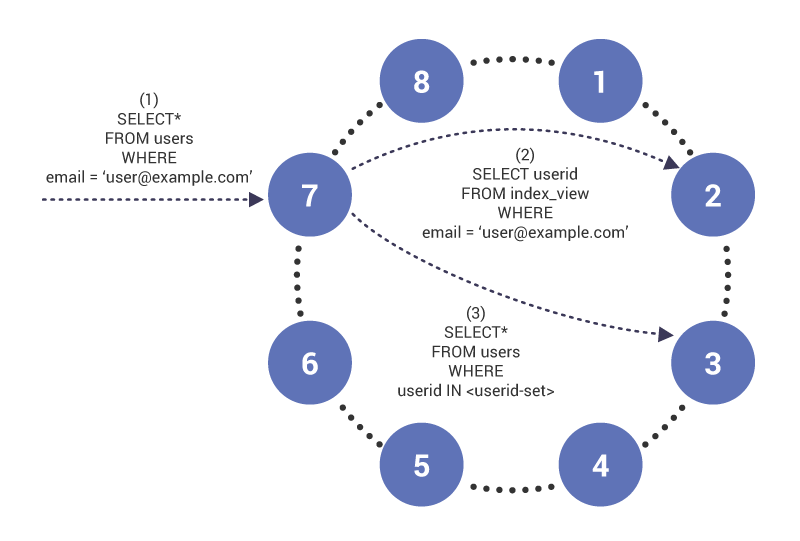
příklad
nejprve musíme vytvořit schéma. V tomto příkladu máme tabulku, která představuje informace o uživateli s id jako klíč oddílu a jméno, e-mail, a země jako pravidelné rubriky:
pak Jsme se vyplnit tabulku s nějakými testy údaje získané s Mockaroo:
sekundární indexy jsou navrženy tak, aby umožňovaly efektivní dotazování sloupců klíčů bez oddílu. Zatímco Apache Cassandra také podporuje dotazy na sloupce bez oddílů pomocí ALLOW FILTERING, je to velmi neefektivní (vyžadující skenování celé tabulky) a v současné době není Scylla podporována (podrobnosti viz problém #2200).
sloupce tabulky indexujte pomocí příkazu vytvořit INDEX. Chcete-li například vytvořit indexy pro sloupce e-mailů a zemí, spusťte následující příkazy CQL:
Scylla automaticky vytvoří Materializované View, který má indexovaný sloupec jako klíč oddílu a cílové tabulky primární klíč (klíč oddílu a clustering klíče) jako clustering klíče.
například Zhmotněný pohled pro index ve sloupci email vypadá následovně:
pokud by výše uvedený pohled byl vytvořen jako běžná tabulka, účinně by vypadal takto:
email sloupec je použit jako klíč oddílu pro index tabulka a userid je zahrnut jako clustering klíč, který nám umožňuje efektivně najít partition klíče pro cílové tabulky pomocí email.
můžete použít DESCRIBE příkaz zobrazit celou schématu pro ks.users tabulka, včetně vytvořených indexů a pohledů:
Nyní se Sekundární Index v místě, můžete dotaz indexovaných sloupců, jako kdyby byly partition klíče:
skončili Jsme s příkladem!
kdy použít sekundární indexy?
sekundární indexy jsou (většinou) transparentní pro aplikaci. Dotazy mají přístup ke všem sloupcům v tabulce a můžete přidávat a odebírat indexy beze změny aplikace. Sekundární Indexy mohou mít také méně prostoru nad hlavou, než Materializované Pohledy, protože Sekundární Indexy potřebovat pouze duplicitní indexované sloupce a primárního klíče, není dotazován sloupce jako s Materializované View. Ze stejného důvodu mohou být aktualizace efektivnější u sekundárních indexů, protože pouze změny primárního klíče a indexovaného sloupce způsobují aktualizaci v zobrazení indexu. V případě zhmotněného pohledu vyžaduje aktualizace některého ze sloupců, které se objeví v zobrazení, aktualizaci doprovodného pohledu.
jako vždy závisí rozhodnutí, zda použít sekundární indexy nebo zhmotněné pohledy, na požadavcích vaší aplikace. Pokud potřebujete maximální výkon a pravděpodobně budete dotazovat na konkrétní sadu sloupců, měli byste použít zhmotněné pohledy. Pokud však aplikace potřebuje dotazovat na různé sady sloupců, sekundární indexy jsou lepší volbou, protože mohou být přidány a odstraněny s menší režií úložiště v závislosti na potřebách aplikace.
chcete se dozvědět více o sekundárních indexech? Podívejte se na mou prezentaci ze Scylla Summit 2017 na SlideShare. Pokud si chcete tuto funkci vyzkoušet, očekává se, že bude v nadcházejícím vydání Scylla 2.2.