Cloud Data Warehouse vs tradiční Data Warehouse Concepts
cloudové datové sklady jsou novou normou. Pryč jsou dny, kdy vaše firma musela nakupovat hardware, vytvářet serverové místnosti a najímat, trénovat a udržovat specializovaný tým zaměstnanců, kteří jej provozují. Nyní s několika kliknutími na notebook a kreditní kartu máte přístup k prakticky neomezenému výpočetnímu výkonu a úložnému prostoru.
to však neznamená, že tradiční nápady datového skladu jsou mrtvé. Klasická teorie datového skladu je základem většiny toho, co dělají cloudové datové sklady.
V tomto článku, budeme vysvětlit, tradiční datového skladu pojmy, které potřebujete vědět a nejdůležitější cloud ty z výběru nejlepších služeb: Amazon, Google, a Paletu. Nakonec skončíme analýzou nákladů a přínosů tradičních datových skladů vs. cloud, abyste věděli, který z nich je pro vás ten pravý.
začněme.
- Tradiční Datového Skladu Pojmy
- Fakta, Rozměry, a Opatření
- Normalizace a Denormalizace
- Datové Modely
- tabulka faktů
- Star Schema vs. Snowflake Schema
- OLAP vs. OLTP
- Tři Vrstvy Architektury
- Virtuální Datový Sklad / Data Mart
- Kimball vs. Inmon
- ETL vs ELT
- Enterprise Data Warehouse
- koncepty cloudového datového skladu
- Cloud Datového Skladu Pojmy – Amazon rudý posuv
- klastry
- uzly
- oddíly / řezy
- Sloupcové úložiště
- komprese
- načítání dat
- Cloud Databáze Skladu – Google BigQuery
- služba bez serverů
- souborový systém Colossus
- Dremel Execution Engine
- Sdílení Dat
- Streaming a Dávkové Požití
- Cloud Datového Skladu Pojmy – Paletou
- primární klíče
- Inkrementální Klávesy
- Vnořené Datové
- Historie Tabulky
- transformace
- String Formáty
- Ochrana Dat
- Řízení Přístupu
- IP Whitelisting
- závěr: tradiční vs. Data Warehouse Concepts ve stručnosti
- Tradiční Datového Skladu Pojmy
- Cloud Data Warehouse Concepts-Amazon Redshift jako příklad
- Cloud Datového Skladu Pojmy – BigQuery, jako Například
- Tradiční vs. Cloud Analýzy Nákladů a Přínosů
- Dozvědět se Více o Datových Skladech
Tradiční Datového Skladu Pojmy
datový sklad je jakýkoliv systém, který shromažďuje data z široké škály zdrojů v rámci organizace. Datové sklady se používají jako centralizované datové úložiště pro analytické a reportingové účely.
tradiční datový sklad se nachází přímo na místě ve vašich kancelářích. Zakoupíte hardware, serverové místnosti a najmete zaměstnance, aby je provozovali. Nazývají se také on-premise, on-prem nebo (gramaticky nesprávné) on-premise datové sklady.
Fakta, Rozměry, a Opatření
základní stavební bloky informací v datovém skladu jsou fakta, rozměry a opatření.
fakt je část vašich dat, která označuje konkrétní výskyt nebo transakci. Pokud například vaše firma prodává květiny, některé skutečnosti, které byste viděli ve svém datovém skladu, jsou:
- prodáno 30 růží v obchodě za 19$.99
- Objednal 500 nových květináčů z Číny za $1500
- Zaplaceno plat pokladní pro tento měsíc $1000
Několik čísel lze popsat každou skutečnost, a my tato čísla opatření. Některá opatření k popisu skutečnosti si 500 nových květináčů z Číny za $1500 jsou:
- objednané Množství – 500
- Náklady – $1500
Když analytici pracují s daty, provádět výpočty na opatření (např. součet, maximum, průměr) sbírat postřehy. Například, možná budete chtít znát průměrný počet květináčů, které si objednáte každý měsíc.
dimenze kategorizuje fakta a opatření a poskytuje strukturované informace o označování pro ně – jinak by být jen sbírka neuspořádané čísla! Některé rozměry popisovat skutečnost si 500 nových květináčů z Číny za $1500 jsou:
- Země zakoupit od – Čína
- Čas zakoupit – 1 pm
- předpokládaný den příjezdu, má – 6. června
nelze provést výpočty na rozměry explicitně, a tak pravděpodobně nebude být velmi užitečné – jak můžete najít průměrné příjezdu datum objednávky’? Je však možné vytvořit nová opatření z dimenzí, která jsou užitečná. Pokud například znáte průměrný počet dní mezi datem objednávky a datem příjezdu, můžete lépe naplánovat nákupy akcií.
Normalizace a Denormalizace
Normalizace je proces efektivně uspořádání dat v datovém skladu (nebo jakékoliv jiné místo, které ukládá data). Hlavním cílem je snížit redundanci dat-tj. odstranit všechna duplicitní data – a zlepšit integritu dat-tj. zlepšit přesnost dat. Existují různé úrovně normalizace a žádná shoda pro “nejlepší” metodu. Všechny metody však zahrnují ukládání samostatných, ale souvisejících informací do různých tabulek.
normalizace má mnoho výhod, například:
- Rychlejší vyhledávání a řazení na každém stole
- Jednodušší tabulky se data změny příkazy rychleji psát a spouštět
- Méně redundantních dat znamená, že ušetříte na disku, a tak můžete sbírat a ukládat více dat
Denormalizace je proces záměrně přidání redundantních kopií nebo skupiny údajů již normalizované údaje. Není to stejné jako u normalizovaných dat. Denormalizace zlepšuje výkon čtení a usnadňuje manipulaci s tabulkami do požadovaných formulářů. Když analytici pracují s datovými sklady, obvykle provádějí pouze čtení dat. Denormalizovaná data jim tak mohou ušetřit obrovské množství času a bolesti hlavy.
Výhody denormalizované:
- Méně tabulek minimalizovat potřebu tabulky spojnic, které urychluje údajů analytiků workflow a vede je objevování více užitečné postřehy v datech
- Méně stolů zjednodušit dotazy, což vede k menšímu počtu chyb
Datové Modely
To by bylo naprosto neefektivní ukládat všechny vaše data v jeden masivní stůl. Váš datový sklad tedy obsahuje mnoho tabulek, které můžete spojit a získat konkrétní informace. Hlavní tabulka se nazývá tabulka faktů a rozměrové tabulky ji obklopují.
prvním krokem při navrhování datového skladu je vytvoření koncepčního datového modelu, který definuje požadovaná data a vztahy na vysoké úrovni mezi nimi.
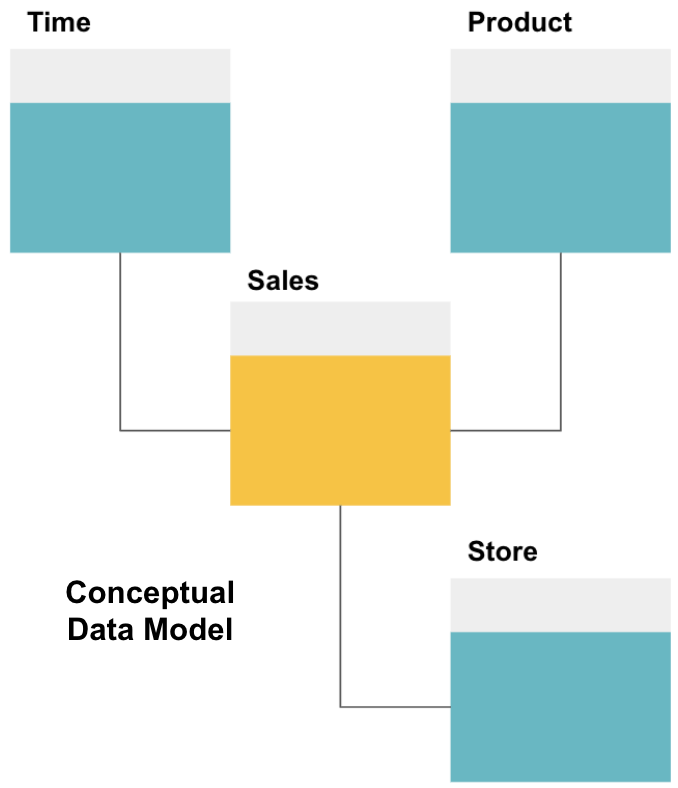
zde jsme definovali koncepční model. Ukládáme údaje o prodeji a máme tři další tabulky-čas, produkt , a obchod-které poskytují další, podrobnější informace o každém prodeji. Fakt tabulka je prodej, a ostatní jsou rozměrové tabulky.
dalším krokem je definování logického datového modelu. Tento model podrobně popisuje data v jednoduché angličtině, aniž by se obával, jak je implementovat do kódu.
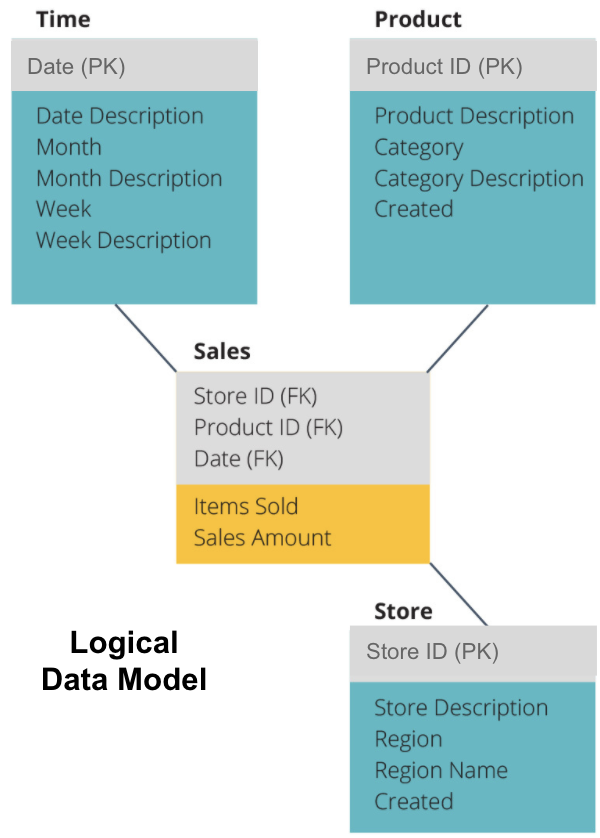
nyní jsme vyplnili, které informace každá tabulka obsahuje v jednoduché angličtině. Každý z Času, Produktů a Obchodu rozměr tabulky ukazuje, Primární Klíč (PK) v šedém poli a odpovídající data v modré krabice. Prodejní tabulka obsahuje tři cizí klíče (FK), takže se může rychle spojit s ostatními tabulkami.
poslední fází je vytvoření fyzického datového modelu. Tento model vám řekne, jak implementovat datový sklad v kódu. Definuje tabulky, jejich strukturu a vztah mezi nimi. Určuje také datové typy pro sloupce a vše je pojmenováno tak, jak bude v konečném datovém skladu, tj. Nakonec každá tabulka dimenzí začíná DIM_ a každá tabulka faktů začíná FACT_.
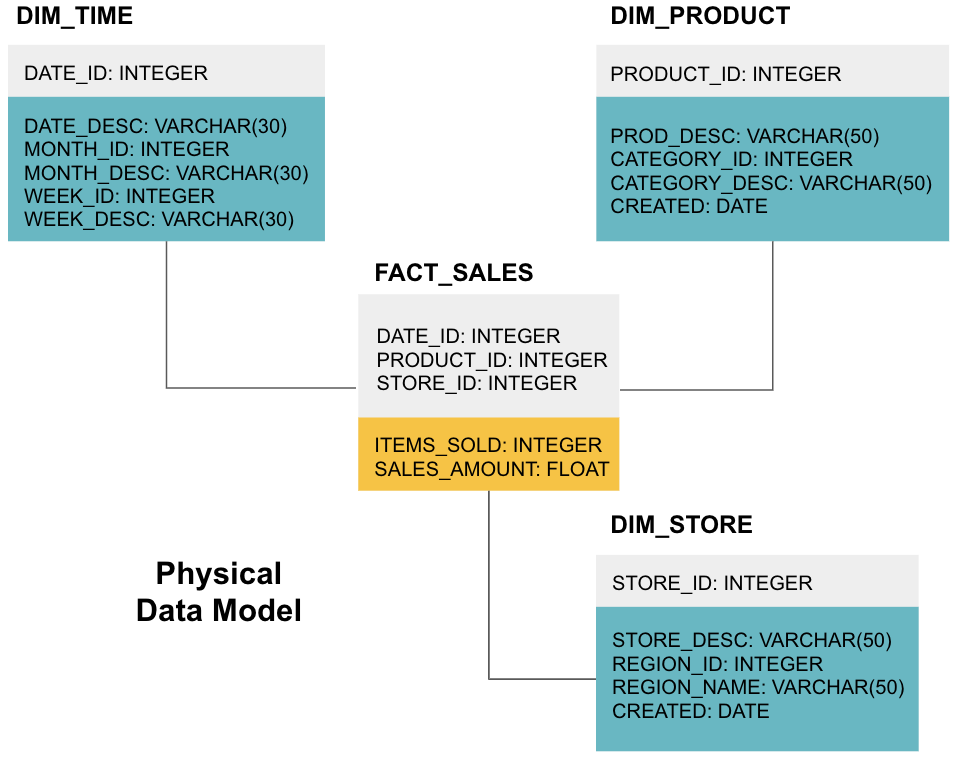
Nyní víte, jak navrhnout datový sklad, ale tam jsou některé nuance fakt a dimenze tabulky, které budeme vysvětlovat dál.
tabulka faktů
každá obchodní funkce-např. prodej, marketing, finance – má odpovídající tabulku faktů.
tabulky faktů mají dva typy sloupců: sloupce rozměrů a sloupce faktů. Sloupce kót-v našich příkladech šedá barva-obsahují cizí klíče (FK), které používáte ke spojení tabulky faktů s tabulkou kót. Tyto cizí klíče jsou primární klíče (PK) pro každou z kótovacích tabulek. Sloupce faktů-v našich příkladech žluté barvy-obsahují skutečná data a opatření, která mají být analyzována, např. počet prodaných položek a celková hodnota prodeje v dolaru.
tabulka faktů bez faktů je určitý typ tabulky faktů, která má pouze sloupce kót. Takové tabulky jsou užitečné pro sledování událostí, jako student prezenční nebo zaměstnanec dovolenou, rozměry říct vše, co potřebujete vědět o událostech.
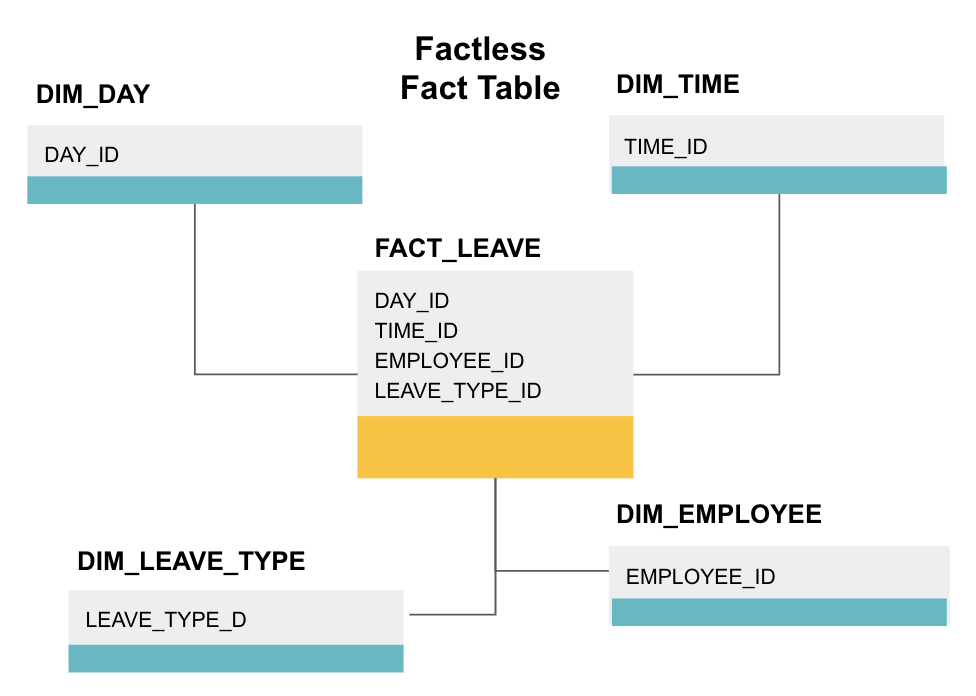
výše uvedená faktická tabulka sleduje dovolenou zaměstnanců. Neexistují žádná fakta, protože stačí vědět:
- co den byli pryč (DAY_ID).
- jak dlouho byli vypnuti (TIME_ID).
- kdo byl na dovolené (EMPLOYEE_ID).
- jejich důvod pro dovolenou, např., nemoc, dovolená, jmenování lékaře atd. (LEAVE_TYPE_ID).
Star Schema vs. Snowflake Schema
všechny výše uvedené datové sklady měly podobné uspořádání. To však není jediný způsob, jak je uspořádat.
dvě nejběžnější schémata používaná k uspořádání datových skladů jsou star a snowflake. Obě metody používají kótové tabulky, které popisují informace obsažené v tabulce faktů.
hvězdné schéma vezme informace z tabulky faktů a rozdělí je do denormalizovaných kót. Důraz na hvězdné schéma je kladen na rychlost dotazu. K propojení faktových tabulek s každou dimenzí je zapotřebí pouze jedno spojení, takže dotazování na každou tabulku je snadné. Protože jsou však tabulky denormalizovány, často obsahují opakovaná a redundantní data.
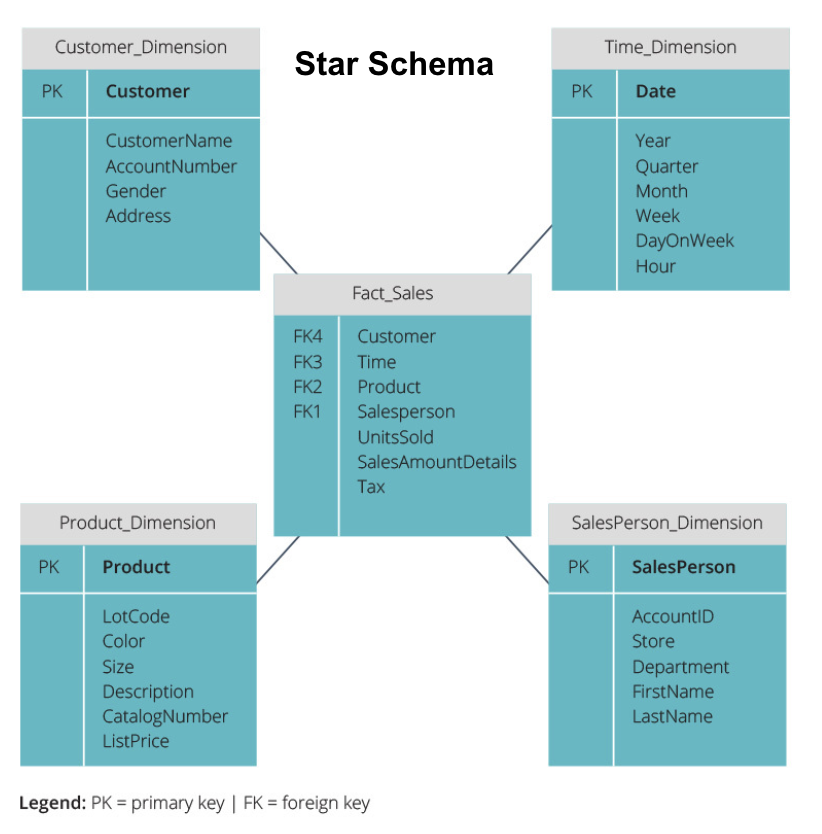
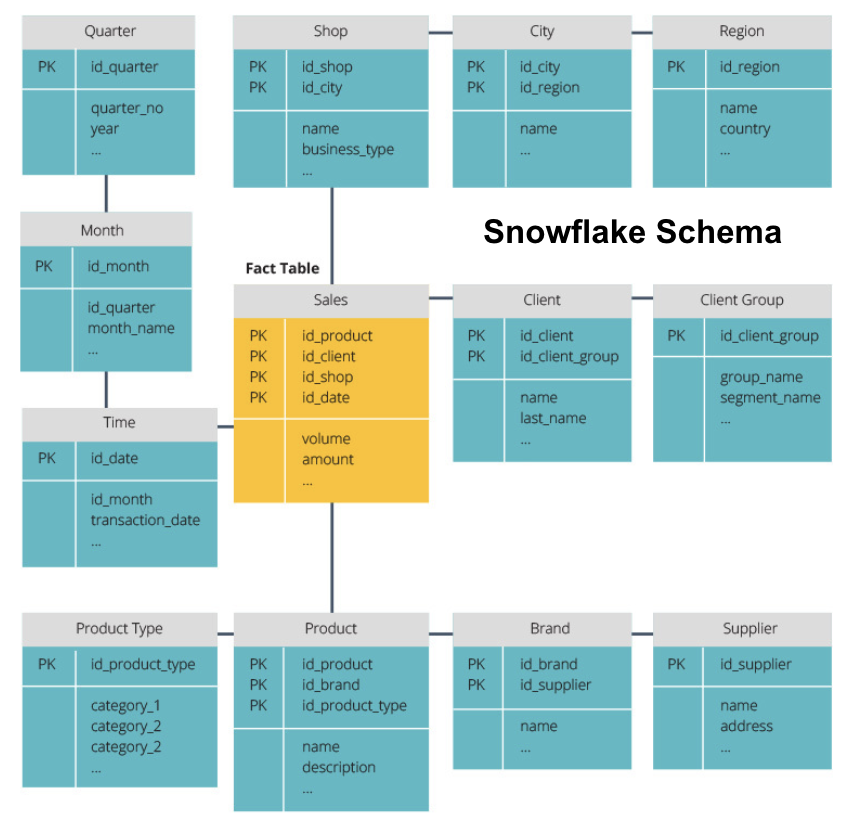
schéma sněhové vločky rozděluje tabulku faktů do řady normalizovaných kótovacích tabulek. Normalizace vytváří více rozměrových tabulek, a tak snižuje problémy s integritou dat. Dotazování je však náročnější pomocí schématu sněhové vločky, protože pro přístup k příslušným datům potřebujete více spojení tabulky. Takže máte méně redundantních dat, ale je těžší získat přístup.
nyní vysvětlíme některé základní pojmy datového skladu.
OLAP vs. OLTP
Online transakční zpracování (OLTP) je charakterizováno transakcemi s krátkým zápisem, které zahrnují front-end aplikace podnikové datové architektury. OLTP databáze zdůrazňují rychlé zpracování dotazů a zabývají se pouze aktuálními daty. Podniky je používají k zachycení informací pro obchodní procesy a poskytování zdrojových dat pro datový sklad.
online analytické zpracování (OLAP) umožňuje spouštět složité čtené dotazy a provádět tak podrobnou analýzu historických transakčních dat. Systémy OLAP pomáhají analyzovat data v datovém skladu.
Tři Vrstvy Architektury
Tradiční datové sklady jsou obvykle strukturovány ve třech úrovních:
- Spodní patro: databáze, server, typicky RDBMS, který extrahuje data z různých zdrojů pomocí brány. Zdroje dat přivádí do této úrovně zahrnují provozní databáze a další typy front-end dat, jako jsou CSV a JSON soubory.
- Střední úroveň: OLAP server, který buď
- Přímo implementuje operace, nebo
- Mapy operace na multidimenzionálních dat standardní relační operace, např., sloučení XML nebo JSON data do řádků v tabulkách.
- Top Tier: nástroje pro dotazování a reporting pro analýzu dat a business intelligence.
Virtuální Datový Sklad / Data Mart
Virtuální datové sklady používá distribuované dotazy na několik databází, bez integrace dat do jednoho fyzického datového skladu.
datové obchody jsou podmnožiny datových skladů orientované na specifické obchodní funkce, jako je prodej nebo finance. Datový sklad obvykle kombinuje informace z několika datových tržišť ve více obchodních funkcích. Datový obchod však obsahuje data ze sady zdrojových systémů pro jednu obchodní funkci.
Kimball vs. Inmon
Existují dva přístupy k návrhu datového skladu, navržených Bill Inmon a Ralph Kimball. Bill Inmon je americký počítačový vědec, který je uznáván jako otec datového skladu. Ralph Kimball je jedním z původních architektů datových skladů a na toto téma napsal několik knih.
oba odborníci měli protichůdné názory na to, jak by měly být datové sklady strukturovány. Tento konflikt dal vzniknout dvěma myšlenkovým směrům.
přístup Inmon je design shora dolů. S metodikou Inmon je datový sklad vytvořen jako první a je považován za ústřední součást analytického prostředí. Data jsou pak shrnuta a distribuována z Centralizovaného skladu do jednoho nebo více závislých datových tržišť.
přístup Kimball má pohled zdola nahoru na návrh datového skladu. V této architektuře, organizace vytváří samostatné datové tržiště, které poskytují pohledy do jednotlivých oddělení v rámci organizace. Datový sklad je kombinací těchto datových tržišť.
ETL vs ELT
Extract, Transform, Load (ETL) popisuje proces extrakce dat ze zdrojových systémů (typicky transakční systémy), převod dat do formátu nebo struktuře vhodné pro dotazování a analýzu, a nakonec nahrávání do datového skladu. ETL využívá samostatnou pracovní databázi a před načtením aplikuje na extrahovaná data řadu pravidel nebo funkcí.
Extract, Load, Transform (ELT) je jiný přístup k načítání dat. ELT bere data z různých zdrojů a načte je přímo do cílového systému, jako je datový sklad. Systém pak transformuje načtená data na vyžádání, aby umožnil analýzu.
ELT nabízí rychlejší načítání než ETL, ale vyžaduje výkonný systém pro provádění datových transformací na vyžádání.
Enterprise Data Warehouse
enterprise data warehouse je určen jako jednotný, centralizovaný sklad obsahující všechny transakční informace v Organizaci, aktuální i historické. Podnikový datový sklad by měl obsahovat údaje ze všech oblastí souvisejících s podnikáním, jako je marketing, prodej, finance a lidské zdroje.
to jsou základní myšlenky, které tvoří tradiční datové sklady. Nyní se podívejme na to, jaké cloudové datové sklady k nim přidaly.
koncepty cloudového datového skladu
cloudové datové sklady jsou nové a neustále se mění. Pro nejlepší pochopení jejich základních pojmů je nejlepší se dozvědět o předních řešeních cloudového datového skladu.
tři přední řešení cloudového datového skladu jsou Amazon Redshift, Google BigQuery a Panoply. Níže vysvětlujeme základní pojmy z každé z těchto služeb, abychom vám poskytli obecné pochopení toho, jak fungují moderní datové sklady.
Cloud Datového Skladu Pojmy – Amazon rudý posuv
tyto pojmy jsou použity v Amazon rudý posuv cloud datového skladu, ale může se vztahovat na další řešení datového skladu v budoucnosti na základě Amazon infrastruktury.
klastry
Amazon Redshift zakládá svou architekturu na klastrech. Cluster je jednoduše skupina sdílených výpočetních prostředků, nazývaných uzly.
uzly
uzly jsou výpočetní prostředky, které mají CPU, RAM a místo na pevném disku. Cluster obsahující dva nebo více uzlů se skládá z uzlu leader a výpočetních uzlů.
Vůdce uzly komunikovat s klientskými programy a kompilovat kód spustit dotazy, přiřazení k výpočetní uzly. Výpočetní uzly spouštějí dotazy a vrátí výsledky do uzlu leader. Výpočetní uzel provádí pouze dotazy, které odkazují tabulky uložené v tomto uzlu.
oddíly / řezy
Amazon oddíly každý výpočetní uzel do řezů. Plátek obdrží přidělení paměti a místa na disku v uzlu. Více řezů pracuje paralelně, aby se urychlila doba provádění dotazu.
Sloupcové úložiště
Redshift používá sloupcové úložiště, což umožňuje lepší výkon analytického dotazu. Místo ukládání záznamů v řádcích ukládá hodnoty z jednoho sloupce pro více řádků. Následující diagramy, aby to jasnější:
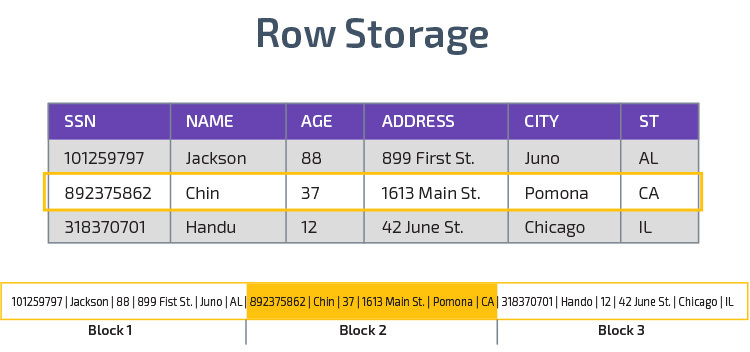
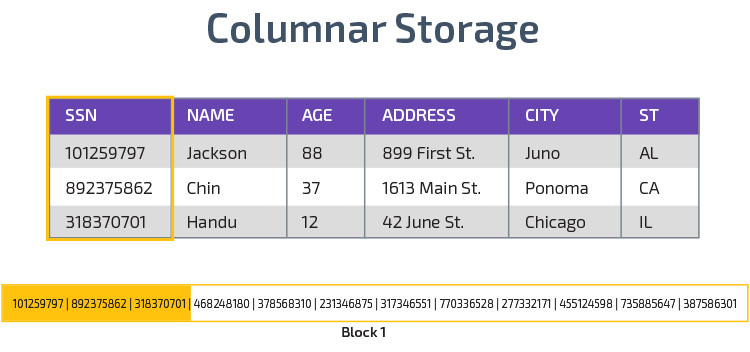
Sloupcová úložiště, je možné číst data rychleji, což je zásadní pro analytické dotazy, které pokrývají mnoho sloupců v datové sadě. Sloupcové úložiště také zabírá méně místa na disku, protože každý blok obsahuje stejný typ dat, což znamená, že může být komprimován do určitého formátu.
komprese
komprese snižuje velikost uložených dat. V Redshift, kvůli způsobu ukládání dat, dochází ke kompresi na úrovni sloupců. Redshift umožňuje komprimovat informace ručně při vytváření tabulky nebo automaticky pomocí příkazu Kopírovat.
načítání dat
pomocí příkazu Redshift COPY můžete načíst velké množství dat do datového skladu. Příkaz COPY využívá architekturu MPP společnosti Redshift k paralelnímu čtení a načítání dat ze souborů na Amazonu S3, z tabulky DynamoDB nebo textového výstupu z jednoho nebo více vzdálených hostitelů.
je také možné streamovat data do Redshift pomocí služby Amazon Kinesis Firehose.
Cloud Databáze Skladu – Google BigQuery
tyto pojmy jsou použity v Google BigQuery cloud datového skladu, ale může se vztahovat na další řešení v budoucnosti založené na Google infrastruktury.
služba bez serverů
BigQuery používá architekturu bez serverů. S BigQuery nemusí podniky spravovat fyzické serverové jednotky, aby provozovaly své datové sklady. Místo toho BigQuery dynamicky řídí přidělování svých výpočetních zdrojů. Podniky využívající službu jednoduše platí za ukládání dat na gigabajt a dotazy na terabajt.
souborový systém Colossus
BigQuery používá nejnovější verzi distribuovaného souborového systému Google s kódovým označením Colossus. Souborový systém Colossus používá sloupcové ukládání a kompresní algoritmy pro optimální ukládání dat pro analytické účely.
Dremel Execution Engine
Dremel execution engine používá sloupcové rozvržení dotaz obrovské zásoby údajů rychle. Dremel spuštění motor lze spustit ad-hoc dotazy na miliardy řádků během několika sekund, protože používá masivně paralelní zpracování v podobě stromu architektury.
stromová Architektura distribuuje dotazy mezi několika mezilehlými servery z kořenového serveru. Mezilehlé servery tlačí dotaz dolů na leaf servery (obsahující uložená data), které Data skenují paralelně. Na cestě zpět do stromu odešle každý listový server výsledky dotazu a mezilehlé servery provedou paralelní agregaci dílčích výsledků.
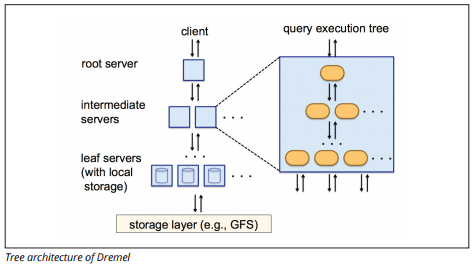
Zdroj obrázku
Dremel umožňuje organizacím spouštět dotazy až na desítky tisíc serverů současně. Podle společnosti Google dokáže Dremel skenovat 35 miliard řádků bez indexu za desítky sekund.
Sdílení Dat
Google BigQuery je serverless architektura umožňuje podnikům snadno sdílet data s jinými organizacemi bez nutnosti tyto organizace investovat ve svém vlastním skladu.
organizace, které chtějí dotazovat sdílená data, tak mohou učinit a budou platit pouze za dotazy. Není třeba vytvářet nákladná sdílená datová Sila, mimo datovou infrastrukturu organizace, a kopírovat data do těchto sil.
Streaming a Dávkové Požití
je možné načíst data do BigQuery od Google Cloud Storage, včetně CSV, JSON (newline-čárkami), a Avro soubory, stejně jako Google Cloud datového Úložiště záloh. Můžete také načíst data přímo z čitelného zdroje dat.
BigQuery také nabízí streamingové API pro načítání dat do systému rychlostí milionů řádků za sekundu bez provedení zatížení. Data jsou k dispozici pro analýzu téměř okamžitě.
Cloud Datového Skladu Pojmy – Paletou
Paletu je all-in-one skladu, který kombinuje ETL s výkonným datového skladu. Je to nejjednodušší způsob, jak synchronizovat, ukládat a přistupovat k datům společnosti tím, že eliminuje vývoj a kódování spojené s transformací, integrací a správou velkých dat.
níže jsou uvedeny některé z hlavních konceptů v Panoply data warehouse týkající se modelování dat a ochrany dat.
primární klíče
primární klíče zajistí, že všechny řádky v tabulkách jsou jedinečné. Každá tabulka má jeden nebo více primárních klíčů, které definují, co představuje jeden jedinečný řádek v databázi. Všechna rozhraní API mají výchozí primární klíč pro tabulky.
Inkrementální Klávesy
Paletu používá přírůstkové klíč k ovládání atributy pro postupně načítání dat do datového skladu ze zdrojů, spíše než překládání celý dataset pokaždé, když se něco změní. Tato funkce je užitečná pro větší datové sady, které mohou trvat dlouho, než se přečtou většinou nezměněná data. Inkrementální klíč označuje poslední bod aktualizace řádků v daném zdroji dat.
Vnořené Datové
Vnořená data nejsou plně kompatibilní s BI apartmá a standardní dotazy SQL—Paletu se zabývá vnořených dat pomocí silně relační model, který nemá povolení vnořených hodnot. Paletu transformuje vnořených dat v těchto ohledech:
- Subtables: ve výchozím nastavení, Řadu transformuje vnořených dat do souboru mnoho-k-mnoha nebo jeden-to-many vztah tabulek, které jsou ploché relační tabulky.
- zploštění: pokud je tento režim povolen, Panoply zplošťuje vnořenou strukturu na záznam, který ji obsahuje.
Historie Tabulky
Někdy je třeba analyzovat data o sledování změny dat v průběhu času, aby přesně vidět, jak se data změní (například adresy lidí).
k provádění takových analýz Panoply používá tabulky historie, což jsou tabulky časových řad, které obsahují historické snímky každého řádku v původní statické tabulce. Poté můžete provést přímý dotaz na původní tabulku nebo revize tabulky přetočením do libovolného časového bodu.
transformace
Panoply používá ELT, což je variace na původní proces integrace dat ETL. Jakmile vložíte data ze zdroje do datového skladu, Panoply je okamžitě transformuje. Tento proces vám poskytuje analýzu dat v reálném čase a optimální výkon ve srovnání se standardním procesem ETL.
String Formáty
Paletu analyzuje řetězec formáty a zpracovává je, jako kdyby byly vnořené objekty v původní údaje. Podporované formáty řetězců jsou CSV, TSV, JSON, JSON-Line, formát objektu Ruby, řetězce dotazů URL a protokoly webové distribuce.
Ochrana Dat
Paletu je postaven na vrcholu AWS, tak to má nejnovější bezpečnostní záplaty a možnosti šifrování poskytované AWS, včetně hardwarově akcelerované šifrování RSA a Amazon rudý posuv je konkrétní sadu bezpečnostních funkcí.
Extra ochrana pochází z sloupcové šifrování, což vám umožní používat vaše soukromé klíče, které nejsou uloženy na Paletu servery.
Řízení Přístupu
Paletu používá dva-krok ověřování, aby se zabránilo neoprávněnému přístupu, a oprávnění systém umožňuje omezit přístup k určité tabulky, zobrazení nebo sloupce. Detekce anomálií identifikuje dotazy přicházející z nových počítačů nebo z jiné země, což vám umožní tyto dotazy Blokovat, pokud neobdrží ruční schválení.
IP Whitelisting
doporučujeme blokovat připojení z neznámých zdrojů pomocí firewallu, nebo AWS security group a whitelist rozsah IP adres, které Paletou datové zdroje vždy používat při přístupu k databázi.
závěr: tradiční vs. Data Warehouse Concepts ve stručnosti
abychom to zabalili, shrneme koncepty představené v tomto dokumentu.
Tradiční Datového Skladu Pojmy
- Fakta a opatření: opatření je vlastnost, na které výpočty mohou být provedeny. Sbírku opatření označujeme jako fakta, ale někdy se termíny používají zaměnitelně.
- Normalizace: proces snižování množství duplicitních dat, což vede k více paměti efektivní datový sklad, který je pomalejší na dotaz.
- dimenze: Používá se ke kategorizaci a kontextualizaci faktů a opatření, což umožňuje analýzu a podávání zpráv o těchto opatřeních.
- koncepční datový model: definuje kritické datové entity na vysoké úrovni a vztahy mezi nimi.
- logický datový model: Popisuje datové vztahy, entity a atributy v jednoduché angličtině bez obav o tom, jak je implementovat do kódu.
- fyzikální datový model: reprezentace toho, jak implementovat návrh dat v konkrétním systému správy databází.
- Star schema: vezme tabulku faktů a rozdělí své informace do denormalizovaných rozměrových tabulek.
- Snowflake schema: rozdělí tabulku faktů do normalizovaných rozměrových tabulek. Normalizace snižuje problémy s redundancí dat a zlepšuje integritu dat, ale dotazy jsou složitější.
- OLTP: Online systémy zpracování transakcí usnadňují rychlé, transakčně orientované zpracování pomocí jednoduchých dotazů.
- OLAP: online analytické zpracování umožňuje spouštět složité čtené dotazy a provádět tak podrobnou analýzu historických transakčních dat.
- Data mart: archiv dat zaměřený na konkrétní subjekt nebo oddělení v rámci organizace.
- přístup Inmon: přístup datového skladu Bill Inmon definuje datový sklad jako centralizované úložiště dat pro celý podnik. Data marts mohou být postaveny z datového skladu, aby sloužily analytickým potřebám různých oddělení.
- Kimball přístup: Ralph Kimball popisuje datový sklad jako sloučení kritických datových tržišť, které jsou nejprve vytvořeny pro analytické potřeby různých oddělení.
- ETL: Integruje data do datového skladu extrakcí z různých transakční zdroje, transformace dat optimalizovat pro analýzu, a nakonec nahrávání do datového skladu.
- ELT: Variace na ETL, která extrahuje surová data ze zdrojů dat organizace a načte je do datového skladu. V případě potřeby se transformuje pro analytické účely.
- Enterprise Data Warehouse: EDW konsoliduje data ze všech oblastí souvisejících s podnikem.
Cloud Data Warehouse Concepts-Amazon Redshift jako příklad
- Cluster: skupina sdílených výpočetních zdrojů založených v cloudu.
- Node: výpočetní zdroj obsažený v clusteru. Každý uzel má svůj vlastní procesor, RAM a místo na pevném disku.
- Sloupcové skladování: Tím se hodnoty tabulky ukládají spíše do sloupců než do řádků, což optimalizuje data pro agregované dotazy.
- komprese: techniky pro zmenšení velikosti uložených dat.
- načítání dat: získávání dat ze zdrojů do cloudového datového skladu. V Redshift můžete použít příkaz Kopírovat nebo službu streamování dat.
Cloud Datového Skladu Pojmy – BigQuery, jako Například
- Serverless služby: cloud poskytovatel dynamicky řídí přidělování stroj, zdroje založené na částku, kterou uživatel spotřebuje. Poskytovatel cloudu skrývá rozhodnutí o správě serveru a plánování kapacity od uživatelů služby.
- Colossus file system: distribuovaný souborový systém, který používá sloupcové úložiště a algoritmy komprese dat k optimalizaci dat pro analýzu.
- Dremel execution engine: dotazovací motor, který používá masivně paralelní zpracování a sloupcové úložiště k rychlému provádění dotazů.
- sdílení dat: ve službě bez serverů je praktické dotazovat se na sdílená data jiné organizace bez investic do ukládání dat-za dotazy jednoduše zaplatíte—
- streamování dat: vkládání dat v reálném čase do datového skladu bez provedení zátěže. Data můžete streamovat v dávkových požadavcích, což jsou vícenásobná volání API kombinovaná do jednoho požadavku HTTP.
Tradiční vs. Cloud Analýzy Nákladů a Přínosů
| Nákladů/Přínosů, | Tradiční | Cloud |
| Náklady | Velké počáteční náklady na nákup a instalaci on-prem systému. potřebujete hardware, serverovny a odborný personál (který platíte průběžně). pokud si nejste jisti, kolik úložného prostoru potřebujete, existuje riziko vysokých potopených nákladů, které je obtížné obnovit. |
není třeba kupovat hardware, serverové místnosti nebo najímat specialisty. žádné riziko potopených nákladů-nákup většího úložiště v budoucnu je snadný. navíc náklady na skladování a výpočetní výkon v průběhu času klesají. |
| Škálovatelnost | Jakmile jste max ven vaše stávající serverové místnosti nebo hardwarové kapacity, možná budete muset koupit nový hardware a postavit/koupit více místa k domu. navíc musíte koupit dostatek úložiště, abyste se vyrovnali se špičkami; většinu času se tedy většina úložiště nepoužívá. |
můžete snadno koupit více úložiště, jak a kdy ji budete potřebovat. často stačí zaplatit za to, co používáte, takže existuje malé nebo žádné riziko přeplatku. |
| integrace | protože cloud computing je normou, většina integrací, které chcete provést, bude do cloudových služeb. připojení vlastního datového skladu k nim může být náročné. |
protože cloudové datové sklady jsou již v cloudu, připojení k řadě dalších cloudových služeb je jednoduché. |
| zabezpečení | máte úplnou kontrolu nad svým datovým skladem. porovnáním množství dat, která máte k dispozici, s Amazonem nebo Googlem, jste menším cílem zlodějů. Takže je pravděpodobnější, že zůstanete sami. |
poskytovatelé cloudových datových skladů mají týmy plné vysoce kvalifikovaných bezpečnostních inženýrů, jejichž jediným účelem je zajistit, aby jejich produkt byl co nejbezpečnější. nejvýznamnější společnosti na světě je spravují, a proto implementují bezpečnostní postupy světové úrovně. |
| Správa | přesně víte, kde jsou vaše data, a můžete k nim přistupovat lokálně. menší riziko, že vysoce citlivá data neúmyslně poruší zákon, například cestováním po celém světě na cloudovém serveru. |
špičkoví poskytovatelé cloudových datových skladů zajišťují, že jsou v souladu se zákony o správě a zabezpečení, jako je GDPR. Navíc pomáhají vašemu podnikání zajistit, že jste v souladu. tam byly problémy týkající se přesně vědět, vaše data jsou a kde se pohybuje. Tyto problémy jsou aktivně řešeny a řešeny. všimněte si, že ukládání obrovského množství vysoce citlivých dat v cloudu může být v rozporu se specifickými zákony. To je jeden případ, kdy cloud computing může být nevhodné pro vaše podnikání. |
| spolehlivost | pokud váš datový sklad on-prem selže, je vaší odpovědností jej opravit. váš IT tým má přístup k fyzickému hardwaru a má přístup ke každé softwarové vrstvě, aby mohl řešit problémy. Tento rychlý přístup může vyřešit problémy mnohem rychleji. Neexistuje však žádná záruka, že váš sklad bude mít každý rok určitou dobu provozu. |
poskytovatelé cloudových datových skladů zaručují jejich spolehlivost a provozuschopnost ve svých SLA. pracují na masivně distribuovaných systémech po celém světě, takže pokud dojde k selhání na jednom, je velmi nepravděpodobné, že by vás to ovlivnilo. |
| ovládání | váš datový sklad je postaven na míru podle vašich potřeb. Teoreticky dělá to, co chcete, když chcete, způsobem, kterému rozumíte. | nemáte úplnou kontrolu nad svým datovým skladem. většinu času je však kontrola, kterou máte, více než dost. |
| rychlost | pokud jste malá společnost na jednom geografickém místě s malým množstvím dat, bude vaše zpracování dat rychlejší. mluvíme však o milisekundách vs. sekundách pro dokončení některých procesů. velká společnost působící ve více zemích pravděpodobně neuvidí významné zvýšení rychlosti se systémem on-prem. |
Cloud poskytovatelé investovali a vytvořili systémy, které implementují Masivně Paralelního Zpracování (MPP), vlastní-postavený architektury a provedení motorů, a inteligentní zpracování dat algoritmy. cloudové datové sklady jsou výsledkem let výzkumu a testování za účelem vytvoření zdrojů optimalizovaných pro rychlost a výkon. může být v některých případech o něco pomalejší než on-prem, ale tato zpoždění jsou pro člověka často zanedbatelná (sekundy vs. milisekundy). |
Panoply je bezpečné místo pro ukládání, synchronizaci a přístup ke všem obchodním datům. Panoply lze nastavit během několika minut, vyžaduje nulovou průběžnou údržbu a poskytuje online podporu, včetně přístupu ke zkušeným architektům dat. Zkuste Panoply zdarma po dobu 14 dnů.
Dozvědět se Více o Datových Skladech
- Datového Skladu, Architektura: Tradiční vs. Cloud
- Databáze vs. Datový Sklad
- Data Mart vs. Datový Sklad