Clustering a K Znamená: Definice & shlukové Analýzy v Excelu
Statistiky Definice > Clustering / shluková Analýza
Co je Clustering?
shlukování ve statistice označuje, jak jsou data shromažďována (“seskupena”) faktory jako:
- věk.
- velikost domácnosti.
- příjem.
- nebo úroveň vzdělání.
třídění dat do klastrů někdy vede k většímu zkoumání dat. Například klastry rakoviny mohou naznačovat nějaký problém v životním prostředí. Nebo, mohou být jen výsledkem náhodného charakteru. Shluková analýza bývá v mnoha případech Subjektivní; záleží na tom, co v datech vnímáte jako běžná vlákna. Tato technika není ve statistice nic nového; pokud jste někdy vytvořili sloupcový graf, pravděpodobně jste již vytvořili klastry(i když jste to tak nenazývali). Například sloupcový graf ukazuje plemen psů vyžaduje, abyste clusteru podle plemene (Sibiřský Husky, Border Kolie, německý Ovčák…) nebo graf příjmů mohou být seskupeny do nízké, střední a vysoké úrovně příjmů.
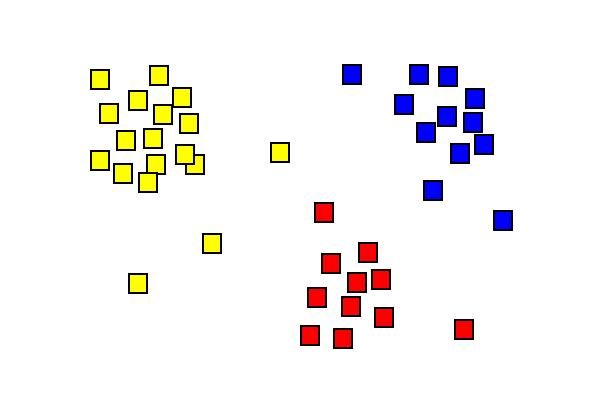
výsledky analýzy clusteru ukazující tři různé barevné shluky.
klastry mohou být založeny na faktorech, jako jsou:
- shlukování založené na vzdálenosti. Položky jsou seřazeny podle jejich blízkosti (nebo vzdálenosti). Například, případy rakoviny mohou být seskupeny, pokud jsou na stejné geografické poloze.
- koncepční shlukování. Položky jsou seskupeny podle faktorů, které mají položky společné. Například klastry rakoviny by mohly být seskupeny podle ” lidí, kteří pracují ve výrobě.”
Typy Shlukování
- Exkluzivní Shlukování. Každá položka může patřit pouze do jednoho clusteru. Nemůže patřit do jiného shluku.
- Fuzzy shlukování: datovým bodům je přiřazena pravděpodobnost příslušnosti k jednomu nebo více shlukům.
- Překrývající Se Shlukování. Každá položka může patřit do více než jednoho clusteru.
- Hierarchické Shlukování. Jedná se o složitější přístup ke shlukování používaný při dolování dat. V zásadě má každá položka svůj vlastní cluster. Dvojice shluků je spojena na základě podobností, což dává o jeden klastr méně. Tento proces se opakuje, dokud nejsou všechny položky seskupeny. Dendrogram je graf, který ukazuje hierarchické klastry.
- Pravděpodobnostní Shlukování. Data jsou seskupena pomocí algoritmů, které spojují položky pomocí vzdáleností nebo hustot. To se obvykle provádí počítačem.
- Wardova metoda: používá minimální rozptyl v každém kroku k vytvoření relativně malých, sudých klastrů.
K znamená shlukování
shlukování je jen způsob, jak seskupit sadu dat do menších sad. Dva způsoby, jak seskupit soubor dat, jsou kvantitativně (pomocí čísel) a kvalitativně (pomocí kategorií). Například knihy o Amazon.com jsou uvedeny jak podle kategorie (kvalitativní), tak podle bestselleru (kvantitativní). K-means clustering je jedním z nejjednodušších učení bez učitele algoritmy, které řeší clustering problémy pomocí kvantitativní metoda: můžete předem definovat počet shluků a použít jednoduchý algoritmus, aby třídit vaše data. To znamená ,že “jednoduché” ve světě výpočetní techniky se nerovná jednoduchému v reálném životě. To je vlastně NP-těžký problém, takže budete chtít použít software pro shlukování K-znamená. Některé programy, které to provedou za vás (klikněte na odkaz pro postup) jsou:
- SPSS.
- r
- MATLAB
obecné kroky za K-means clustering algoritmus, jsou:
- Rozhodnout, kolik shluků (k).
- umístěte centrální body k na různá místa (obvykle daleko od sebe).
- vezměte každý datový bod a umístěte jej blízko příslušného centrálního bodu. Opakujte, dokud nebudou přiřazeny všechny datové body.
- přepočítejte k nové centrální body jako barycentra.
- opakujte přiřazení datových bodů, tentokrát k novému centrálnímu bodu (barycenter).
- opakujte 4 a 5, dokud se středové body (barycentry) již nepohybují.
shlukování k-prostředků: formálnější definice
formálnějším způsobem definování shlukování k-prostředků je kategorizace n objektů do K (K>1) předem definovaných skupin. Cílem je minimalizovat vzdálenost od každého datového bodu ke clusteru. Jinými slovy, najít: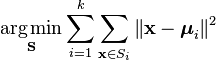
kde:
X je datový bod
k je počet shluků
ui je průměr bodů v Si.
shluková Analýza vs. Diskriminační Analýza
shluková analýza je velmi podobná diskriminační analýzy. Obě metody zahrnují oddělení do skupin. Klastrová analýza je však způsob, jak identifikovat skupiny, zatímco diskriminační analýza vyžaduje, abyste skupiny znali dříve, než začnete s analýzou. Řekněme například, že jste měli skupinu psychiatrických pacientů s abnormálním chováním. Shluková analýza vám může pomoci najít odlišné skupiny, jako pacienti s anamnézou zneužívání, pacienti s PTSD, nebo ti, kteří mají halucinace. Pokud byste měli provést diskriminační analýzu na stejné skupině lidí, musíte znát diagnózy pacientů, než je začnete zařazovat do skupin.
Clustering v aplikaci Excel
Microsoft Excel má dolování dat doplněk pro vytváření klastrů. Pokyny najdete zde. Průvodce pracuje s tabulkami aplikace Excel, rozsahy nebo dotazníky průzkumu analýzy. Tento doplněk lze na rozdíl od nástroje detekovat Kategorie přizpůsobit. Nástroj detekce kategorií je navíc omezen na data z tabulek.
použít:
- stáhněte a nainstalujte doplněk Data Mining.
- klikněte na “dolování dat”, poté na “Cluster” a poté na ” další.”
- řekněte Excelu, kde jsou vaše data. Vyberte například rozsah dat. Stránka shlukování bude k dispozici.
- Clustering: ponechte, jak je pro automatické seskupování, nebo můžete určit počet skupin.
- segmenty: ponechte tak, jak je pro automatické seskupování, nebo zadejte počet kategorií.
Stephanie Glen. “Clustering a K znamená: definice & Clusterová analýza v aplikaci Excel” od StatisticsHowTo.com: Základní statistiky pro nás ostatní! https://www.statisticshowto.com/clustering/
——————————————————————————
Potřebujete pomoci s úkoly nebo zkoušky otázka? S Chegg Study, můžete získat krok za krokem řešení vašich otázek od odborníka v oboru. Váš první 30 minut s Chegg tutorem je zdarma!