Konkávní Trup
Vytvoření clusteru hranice pomocí K-nejbližších sousedů přístup
před pár měsíci, Napsal jsem zde na Střední článek o mapování ve velké BRITÁNII dopravních nehod horké skvrny. Většinou jsem se zajímal o ilustraci použití algoritmu DBSCAN clustering na geografických datech. V článku jsem použil geografické informace zveřejněné vládou Spojeného království o hlášených dopravních nehodách. Mým cílem bylo spustit proces shlukování založený na hustotě, abych našel oblasti, kde jsou dopravní nehody hlášeny nejčastěji. Konečným výsledkem bylo vytvoření souboru geo-plotů představujících tato horká místa nehod.
shromážděním všech bodů v daném clusteru můžete získat představu o tom, jak by cluster vypadal na mapě, ale chybí vám důležitá informace: vnější tvar clusteru. V tomto případě mluvíme o uzavřeném mnohoúhelníku, který lze na mapě znázornit jako geo-plot. Libovolný bod uvnitř geo-oplocení lze předpokládat, že patří do clusteru, což činí tento tvar zajímavá informace: můžete jej použít jako diskriminátor funkce. Všechny nově odebrané body, které spadají do polygonu, lze předpokládat, že patří do odpovídajícího clusteru. Jak jsem naznačil v článku, můžete použít takové polygony k uplatnění rizika jízdy, jejich použitím ke klasifikaci vlastní vzorkované polohy GPS.
otázkou nyní je, jak vytvořit smysluplný mnohoúhelník z oblaku bodů, které tvoří konkrétní cluster. Můj přístup v prvním článku byl poněkud naivní a odrážel řešení, které jsem již použil ve výrobním kódu. Toto řešení znamenalo umístění kruhu vystředěného na každý z bodů clusteru a poté sloučení všech kruhů dohromady a vytvoření mnohoúhelníku ve tvaru mraku. Výsledek není příliš pěkný, ani realistický. Také, pomocí kruzích jako základní tvar pro budování konečné polygon, tyto budou mít více bodů než efektivnější tvar, čímž se zvyšuje náklady na skladování a výrobu zařazení detekční algoritmy, pomalejší běh.

Na druhou stranu, tento přístup má tu výhodu, že je výpočetně jednoduchý (alespoň z vývojářského hlediska), protože používá Urostlý cascaded_union funkce sloučit všechny kruhy dohromady. Další výhodou je, že tvar polygonu je implicitně definován pomocí všech bodů v clusteru.
pro sofistikovanější přístupy musíme nějak identifikovat hraniční body clusteru, ty, které definují tvar mračna bodů. Zajímavé je, že s některými implementacemi DBSCAN můžete skutečně obnovit hraniční body jako vedlejší produkt procesu shlukování. Bohužel tato informace (zřejmě) není k dispozici na implementaci SciKit Learn, takže si musíme vystačit.
první přístup, který se objevil na mysli, byl výpočet konvexního trupu množiny bodů. To je dobře zřejmé, algoritmus, ale trpí problémem není zpracování konkávní tvary, jako je tento:

Tento tvar není správně zachytit podstatu základních bodů. Pokud by byl použit jako diskriminátor, některé body by byly nesprávně klasifikovány jako uvnitř clusteru, pokud nejsou. Potřebujeme jiný přístup.
alternativa konkávního trupu
naštěstí existují alternativy k tomuto stavu věcí: můžeme vypočítat konkávní trup. Tady je to, co konkávní trup vypadá, když se aplikuje na stejné body jako v předchozím obrázku:

Nebo třeba tenhle:
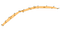
Jak můžete vidět, a na rozdíl od konvexní trupu, není tam žádná jednotná definice, co konkávní trup sadu bodů. S algoritmus, který zde předkládám, volba, jak konkávní chcete, aby vaše trupy být provedeno prostřednictvím jediného parametru: k — počet nejbližších sousedů považován během trupu výpočet. Uvidíme, jak to bude fungovat.
Algoritmus
algoritmus uvádím zde byl popsán před více než deseti lety Adriano Moreira a Maribel Yasmina Santos z Univerzity v Minho, Portugalsko . Z abstraktní:
Tento článek popisuje algoritmus pro výpočet obálky množiny bodů v rovině, které vytváří konvexní na non-konvexní trupy, které představují oblasti obsazené body. Navrhovaný algoritmus je založen na přístupu k-nejbližších sousedů, kde hodnota k, jediný parametr algoritmu, se používá k řízení “hladkosti” konečného řešení.
protože použiji tento algoritmus na geografické informace, musely být provedeny některé změny, a to při výpočtu úhlů a vzdáleností . Ale to nijak nemění podstatu algoritmu, které lze obecně popsat následujícími kroky:
- Najít místo s nejnižší y (latitude) koordinovat a dělat to aktuální.
- najděte k-nejbližší body k aktuálnímu bodu.
- Z k-nejbližších bodů, vyberte ten, který odpovídá největší obrat doprava z předchozího úhlu. Zde použijeme koncept ložiska a začneme s úhlem 270 stupňů (přímo na západ).
- zkontrolujte, zda přidáním nového bodu do rostoucího řádku se neprotíná. Pokud ano, vyberte jiný bod z nejbližšího k nebo restartujte s větší hodnotou k.
- udělejte nový bod aktuálním bodem a odstraňte jej ze seznamu.
- po iteracích k přidejte první bod zpět do seznamu.
- smyčka na číslo 2.
algoritmus se zdá být poměrně jednoduchý, ale existuje řada detailů, které je třeba věnovat pozornost, zejména proto, že se zabýváme geografickými souřadnicemi. Vzdálenosti a úhly se měří jiným způsobem.
kód
zde publikuji je upravená verze kódu předchozího článku. Stále najdete stejný kód clusteru a stejný generátor clusteru ve tvaru cloudu. Aktualizovaná verze nyní obsahuje balíček s názvem geomath.hulls, kde najdete třídu ConcaveHull. Chcete-li vytvořit své konkávní trupy postupujte takto:
V kódu výše, points je matice o rozměrech (N, 2), kde řádky obsahují pozorovaných bodů a sloupce obsahují zeměpisné souřadnice (zeměpisná délka, zeměpisná šířka). Výsledné pole má přesně stejnou strukturu, ale obsahuje pouze body, které patří do polygonálního tvaru clusteru. Filtr svého druhu.
protože budeme zpracovávat pole, je přirozené přivést NumPy do boje. Všechny výpočty byly řádně vektorizována, kdykoli je to možné, a bylo vynaloženo úsilí s cílem zlepšit výkon při přidávání a odebírání položek z pole (spoiler: oni nejsou vůbec hýbat). Jedním z chybějících vylepšení je paralelizace kódu. Ale to může počkat.
uspořádal jsem kód kolem algoritmu, jak je uvedeno v příspěvku, i když některé optimalizace byly provedeny během překladu. Algoritmus je postaven na řadě podprogramů, které jsou jasně identifikovány papírem, takže je teď dostaneme z cesty. Pro vaše pohodlí při čtení budu používat stejná jména jako v novinách.
CleanList —čištění seznamu bodů se provádí v konstruktoru třídy:
Jak můžete vidět, seznam bodů je implementován jako NumPy pole z výkonových důvodů. Čištění seznamu se provádí na řádku 10, kde jsou zachovány pouze jedinečné body. Pole datové sady je uspořádáno s pozorováním v řádcích a geografickými souřadnicemi ve dvou sloupcích. Všimněte si, že jsem také vytváří Boolean pole na lince 13, které budou použity na index do hlavní datové sady pole, uvolnění fuška, odstranění položek, a, jednou za čas, a dodává je zpět. Viděl jsem tuto techniku s názvem “maska” na NumPy dokumentaci, a to je velmi silný. Pokud jde o prvočísla, budu o nich diskutovat později.
FindMinYPoint — To vyžaduje malou funkci:
Tato funkce je volána s dataset pole jako argument a vrátí index bod s nejnižší šířky. Všimněte si, že řádky jsou kódovány zeměpisnou délkou v prvním sloupci a zeměpisnou šířkou ve druhém sloupci.
RemovePoint
AddPoint-Jedná se o no-brainery, díky použití pole indices. Toto pole se používá k ukládání aktivních indexů do hlavního pole datových sad, takže odstranění položek z datové sady je hračka.
ačkoli algoritmus popsaný v článku vyžaduje přidání bodu do pole, které tvoří trup, je ve skutečnosti implementován jako:
později bude proměnná test_hull přiřazena zpět k hull , pokud je řetězec řádku považován za neprotínající se. Ale tady se dostávám před zápas. Odstranění bodu z dataset pole je stejně jednoduché jako:
self.indices = False
Přidání zpět, je jen otázka obracející, že pole hodnoty na stejný index zpět na true. Ale všechno toto pohodlí přichází s cenou, že musíme mít přehled o indexech. Více o tom později.
NearestPoints — Věci začnou získat zajímavé tady, protože nemáme co do činění s rovinné souřadnice, takže s Pythagoras a v s Haversine:
Všimněte si, že druhý a třetí parametr jsou pole v datovém souboru ve formátu: zeměpisná délka, v prvním sloupci a zeměpisné šířky ve druhé. Jak vidíte, tato funkce vrací pole vzdáleností v metrech mezi bodem ve druhém argumentu a body ve třetím argumentu. Jakmile je budeme mít, můžeme snadno získat nejbližší sousedy k. Existuje však specializovaná funkce a zaslouží si nějaké vysvětlení:
funkce začíná vytvořením pole se základními indexy. Jedná se o indexy bodů, které nebyly odstraněny z pole datových sad. Například, pokud jsme na desetibodovém clusteru začali odstraněním prvního bodu, pole základních indexů by bylo . Dále vypočítáme vzdálenosti a třídíme výsledné indexy pole. První k jsou extrahovány a poté použity jako maska pro načtení základních indexů. Je to trochu zkroucené, ale funguje to. Jak vidíte, funkce nevrací pole souřadnic,ale pole indexů do pole datových sad.
SortByAngle-je zde více problémů, protože nepočítáme jednoduché úhly, počítáme ložiska. Ty se měří jako nula stupňů na sever, přičemž úhly se zvyšují ve směru hodinových ručiček. Zde je jádro kódu, který počítá ložiska:
funkce vrací pole ložiska, měřeno od bodu, jehož index je v první argument, body, jejichž indexy jsou v třetí argument. Třídění je jednoduché:
v tomto okamžiku pole kandidátů obsahuje indexy nejbližších bodů k seřazené podle sestupného pořadí ložiska.
IntersectQ-místo toho, abych válcoval své vlastní funkce průsečíku čar, obrátil jsem se na Shapely o pomoc. Ve skutečnosti, zatímco budova polygon, jsme v podstatě manipulace řádku řetězec, připojí segmenty, které se neprotínají s předchozí. Testování je jednoduchý: vybrali jsme pod konstrukcí trupu pole, převést do Urostlý line string objekt, a test, zda je jednoduché (non self-protínající se), nebo ne.
Stručně řečeno, tvarovaný řetězec se stává složitým, pokud se sám zkříží, takže predikát is_simple se stává falešným. Snadný.
PointInPolygon-to se ukázalo jako nejsložitější implementovat. Dovolte mi vysvětlit tím, že při pohledu na kód, který provádí konečné trupu polygon validace (kontroly, pokud všechny body klastru jsou zahrnuty v polygonu):
Urostlý funkce test na křižovatce a zahrnutí by mělo být dost, aby zkontrolovat, zda poslední trupu polygon překrývá všechny clusteru bodů, ale nebyly. Proč? Urostlý je koordinovat-agnostik, takže to bude zpracovávat zeměpisné souřadnice vyjádřené v zeměpisné šířky a délky přesně stejným způsobem, jako souřadnic v Karteziánské rovině. Ale svět se chová jinak, když žijete na kouli, a úhly (nebo ložiska) nejsou konstantní podél geodézie. Příklad odkazu na geodetickou linku spojující Bagdád s Ósakou to dokonale ilustruje. Stává se tak, že za určitých okolností může algoritmus obsahovat bod založený na kritériu ložiska, ale později, pomocí Shapelyho rovinných algoritmů, být považován za tak mírně mimo polygon. To je to, co tam dělá korekce malé vzdálenosti.
chvíli mi trvalo, než jsem to zjistil. Moje pomoc při ladění byla QGIS, skvělý kus svobodného softwaru. Na každém kroku podezřelých výpočtů bych výstup dat ve formátu WKT do souboru CSV, které mají být čteny jako vrstva. Skutečný zachránce!
a konečně, pokud polygon nepokryje všechny body clusteru, jedinou možností je zvýšit k a zkusit to znovu. Zde jsem přidal trochu své vlastní intuice.
Prime k
článek naznačuje, že hodnota k se zvýší o jednu a že algoritmus se provede znovu od nuly. Moje rané testy s touto možností nebyly příliš uspokojivé: časy běhu by byly na problematických klastrech pomalé. To bylo způsobeno pomalým nárůstem k, tak jsem se rozhodl použít další plán zvýšení: tabulku prvočísel. Algoritmus již začíná k=3, takže bylo snadné rozšíření, aby se vyvíjel na seznamu prvočísel. To je to, co vidíte v rekurzivním volání:
mám slabost pro prvočísla, víš…
Vyhodit
konkávní trup polygony generované tímto algoritmem je třeba ještě nějaký další zpracování, protože se bude pouze rozlišovat bodů uvnitř trupu, ale ne blízko. Řešením je přidat do těchto hubených shluků nějaké polstrování. Zde používám přesně stejnou techniku jako dříve, a tady je to, jak to vypadá:

Tady, kdysi jsem Urostlý bufferfunkce stačit.
funkce přijímá tvarovaný mnohoúhelník a vrací nafouknutou verzi sebe sama. Druhým parametrem je poloměr v metrech přidaného polstrování.
spuštění kódu
začněte stažením kódu z úložiště GitHub do místního počítače. Soubor, který chcete spustit, je ShowHotSpots.py v hlavním adresáři. Při prvním provedení kód přečte údaje o dopravních nehodách ve Velké Británii z let 2013 až 2016 a seskupí je. Výsledky jsou pak ukládány do mezipaměti jako soubor CSV pro následné spuštění.
Ty pak budou prezentovány s dvě mapy: první je generována pomocí mrak ve tvaru shluků, zatímco druhý používá konkávní clustering algoritmus popsány zde. Zatímco se spustí kód generování polygonu, můžete vidět, že je hlášeno několik poruch. Abychom pochopili, proč algoritmus nedokáže vytvořit konkávní trup, kód zapíše klastry do souborů CSV do adresáře data/out/failed/. Jako obvykle můžete použít QGIS k importu těchto souborů jako vrstev.
v Podstatě tento algoritmus selže, když se nenajde dostatek bodů, aby “chodit” na tvar bez sebe-protínající se. To znamená, že musíte být připraveni buď vyřadit tyto shluky, nebo uplatnit jiné zacházení s nimi (konvexní trupu nebo splynuly bubliny).
konkávnost
je to zábal. V tomto článku jsem představil metodu post-zpracování DBSCAN generovaných geografických shluků do konkávních tvarů. Tato metoda může poskytnout lepší vnější polygon pro klastry ve srovnání s jinými alternativami.
děkujeme za přečtení a užijte si šťourat s kódem!
Kryszkiewicz m., Lasek P. (2010) TI-DBSCAN: shlukování s DBSCAN pomocí trojúhelníkové nerovnosti. In: Szczuka m., Kryszkiewicz m., Ramanna s., Jensen R., Hu Q. (eds) hrubé množiny A současné trendy ve výpočetní technice. RSCTC 2010. Poznámky k přednášce v informatice, vol 6086. Springer, Berlin, Heidelberg
Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, str. 2825-2830, 2011
Moreira, A. a Santos, M. Y., 2007, Konkávní Trup: K-nejbližších sousedů přístup pro výpočet oblasti obsazené množina bodů,
Vypočítat vzdálenost, ložiska a další mezi zeměpisné Šířky/Délky bodů
GitHub