Společné Hledání: open source projekt přináší zpět PageRank
Přihlašte se k odběru denní rekapitulace někdy-měnící se trh hledání krajiny.
Poznámka: odesláním tohoto formuláře souhlasíte s podmínkami Third Door Media. Respektujeme vaše soukromí.

během posledních několika let Google pomalu snižoval množství dat dostupných odborníkům SEO. Nejprve to byla data klíčových slov, pak PageRank skóre. Nyní je to specifický objem vyhledávání z AdWords (pokud neutrácíte nějakou moolu). Více se o tom můžete dočíst ve vynikajícím článku Russe Jonese, který podrobně popisuje dopad výzkumu jeho společnosti a nahlédnutí do údajů clickstream pro disambiguaci objemu.
jednou z položek, do kterých jsme se v poslední době skutečně zapojili, jsou běžná data procházení. V našem oboru existuje několik týmů, které tyto údaje již nějakou dobu používají, takže jsem se cítil trochu pozdě na hru. Common Crawl data je open source projekt, který v pravidelných intervalech škrábe celý internet. Naštěstí, Amazon, je to skvělá společnost, se vrhla na ukládání dat, aby byla k dispozici mnoha lidem bez vysokých nákladů na skladování.
kromě Běžné Procházení dat, tam je non-zisk tzv. Společné Hledání, jehož posláním je vytvořit alternativní open source a transparentní vyhledávače — naopak, v mnoha ohledech, Google. To vzbudilo můj zájem, protože to znamená, že všichni mohou hrát, vylepšovat a modifikovat signály se dozvíte, jak vyhledávače fungují bez velké časové investice od ground zero.
Časté Vyhledávání dat
v Současné době, Společný Vyhledávání používá následující datové zdroje pro výpočet jejich hledání žebříčku (To je převzato přímo z jejich webové stránky):
- Společné Procházení: největší otevřít úložiště webových procházení data. Toto je v současné době náš jedinečný zdroj nezpracovaných údajů o stránce.
- Wikidata: Bezplatná propojená databáze, která slouží jako centrální úložiště strukturovaných dat mnoha projektů Wikimedia, jako je Wikipedia, Wikivoyage a Wikisource.
- UT1 Blacklist: Udržuje Fabrice Prigent z Université Toulouse 1 Capitole, tento blacklist roztřídění domén a adres Url do několika kategorií, včetně “dospělých” a “phishing.”
- DMOZ: také známý jako Open Directory Project, je to nejstarší a největší webový adresář, který je stále naživu. Ačkoli jeho data nejsou tak spolehlivá jako v minulosti, stále je používáme jako zdroj signálu a metadat.
- Web Data Commons hypertextové odkazy grafy: grafy všech hypertextových odkazů z 2012 společné procházení archivu. V současné době používáme jeho harmonický soubor Centrality jako dočasný signál hodnocení na doménách. V blízké budoucnosti plánujeme provést vlastní analýzu webového grafu.
- Alexa top 1M sites: Alexa řadí webové stránky na základě kombinované míry zobrazení stránek a jedinečných uživatelů stránek. Je známo, že je demograficky zaujatý. Používáme jej jako dočasný signál hodnocení na doménách.
Common Search ranking
Kromě těchto zdrojů dat používá při zkoumání kódu také délku URL, délku cesty a doménu PageRank jako signály hodnocení ve svém algoritmu. Hle, aj, od července, Common Search má svá vlastní data na hostitelské úrovni PageRank, a všichni jsme to zmeškali.
za chvíli se dostanu na PageRank (PR), ale je zajímavé zkontrolovat kód Common Crawl, zejména ranker.py část se nachází tady, protože opravdu se může dostat do sedadla řidiče s laděním váhy signály, že to používá rank stránky:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
zvláštní poznámka, také, je, že Společné Hledání používá BM25 jako podobnost opatření klíčové slovo tělo dokumentu a meta data. BM25 je lepší měřit, než TF-IDF, protože to trvá délka dokumentu v úvahu, což znamená 200-word dokument, který obsahuje vaše klíčové slovo pětkrát, je pravděpodobně důležitější než 1500-word dokument, který má stejný počet krát.
je také vhodné říci, že počet signálů je zde velmi základní a zjevně chybí mnoho vylepšení (a dat), které Google integroval do svého algoritmu hodnocení vyhledávání. Jednou z klíčových věcí, na které pracujeme, je použít data dostupná v Common Crawl a infrastrukturu Common Search k vyhledávání vektorů témat pro obsah, který je relevantní na základě sémantiky, nejen shoda klíčových slov.
na stránce PageRank
na stránce zde naleznete odkazy na stránku PageRank na úrovni hostitele pro běžné procházení v červnu 2016. Používám ten s názvem pagerank-top1m.txt.gz (top 1 milion), protože druhý soubor je 3 GB a více než 112 milionů domén. Dokonce i v R, nemám dostatek stroj načíst bez omezení ven.
Po stažení, budete muset přinést soubor do pracovního adresáře v R. PageRank data ze Společné Hledání není normalizován a také není v čisté 0-10 formátu, který jsme všichni zvyklí. Běžné vyhledávání používá ” max (0, min(1, float (rank) / 244660.58)) — – v podstatě hodnost domény dělená hodností Facebook-jako metoda převodu dat do distribuce mezi 0 a 1. Ale to ponechává určité určité mezery, v tom, že by to zanechalo Linkedin PageRank jako 1.4, když je zmenšen o 10.

následující kód načte dataset a přidat PR sloupec s lépe aproximovat PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
museli Jsme hrát asi trochu s čísly, aby si to někde blízko (několik vzorků z domén, které jsem si vzpomněla, PR) se stará Google PR. Níže uvádíme několik příkladů výsledků PageRank:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Tady je graf 100.000 náhodné vzorky. Vypočítané skóre PageRank je podél osy Y a původní společné skóre vyhledávání je podél osy X.
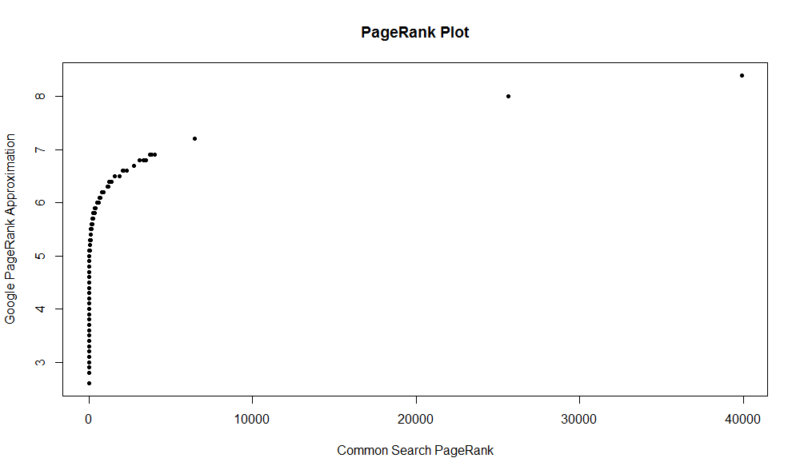
chytit své vlastní výsledky, můžete spustit následující příkaz v R (Jen nahradit své vlastní domény):
df

Mějte na paměti, že tento dataset má pouze horní jeden milion domén podle Pageranku, tak z 112 milionů domén, které Běžné Vyhledávání indexovány, tam je dobrá šance, že vaše stránky nemusí tam být, pokud to nemá dobrý odkaz profil. Tato metrika také neobsahuje žádné údaje o škodlivosti odkazů, pouze přiblížení popularity vašeho webu s ohledem na odkazy.
společné vyhledávání je skvělý nástroj a skvělý základ. Těším se stále více zapojit s komunitou a doufejme, že naučit se pochopit, matice a šrouby za vyhledávačů lépe, ve skutečnosti pracuje na jednu. S R a trochou kódu můžete mít rychlý způsob, jak zkontrolovat PR na milion domén během několika sekund. Doufám, že se vám to líbilo!
přihlaste se k odběru našich denních rekapitulací neustále se měnícího prostředí marketingu vyhledávání.
Poznámka: odesláním tohoto formuláře souhlasíte s podmínkami Third Door Media. Respektujeme vaše soukromí.
O Autorovi

JR Oakes je senior ředitel technické SEO výzkumu na Lokomotivu. Dříve byl ředitelem technického SEO v agentuře Adapt Partners. Pracuje s klienty na široké škále front, včetně technických problémů, výkon, CTR, schopnost procházení, obsah, a analýza dat. JR miluje testování, kódování a prototypování řešení obtížných problémů s marketingovým vyhledáváním. Když nepracuje, rád čte o rozvíjejících se technologiích, hraní na basovou kytaru, sledování vysokoškolského basketbalu, vaření a trávení času se svými přáteli a rodinou. Je také jedním ze spoluorganizátorů Raleigh SEO Meetup, Raleigh SEO Conference, a RTP SEO Meetup.