vývoj clusteru plánovacího systému
Kubernetes se stal de facto standardem v oblasti orchestrace kontejnerů. Všechny aplikace budou v budoucnu vyvíjeny a provozovány na Kubernetes. Účelem této série článků je představit základní principy implementace Kubernetes hlubokým a jednoduchým způsobem.
Kubernetes je systém plánování klastrů. Tento článek představuje především některé starší clusterové plánovací systémové architektury Kubernetes. Tím, že analyzuje jejich nápady designu a architektury charakteristiky, můžeme studovat vývoj procesu clusteru plánování architektury systému, a hlavní problém, který musí být považován v návrhu architektury. To bude velmi užitečné při porozumění architektuře Kubernetes.
Musíme pochopit některé základní pojmy z clusteru plánovací systém, aby bylo jasné, vysvětlím pojem pomocí příkladu, předpokládejme, že chceme realizovat distribuovaný Cron. Systém spravuje sadu hostitelů Linuxu. Uživatel definovat úlohu prostřednictvím API poskytované systémem. systém bude pravidelně provádět odpovídající úkol na základě definice úlohy, v tomto příkladu, základní pojmy jsou níže:
- Cluster: Linux hostitelů spravovaných tento systém tvoří zdroj bazén spustit úkoly. Tento fond zdrojů se nazývá Cluster.
- úloha: definuje, jak cluster plní své úkoly. V tomto příkladu je Crontab přesně jednoduchá úloha, která jasně ukazuje, co je třeba udělat (spouštěcí skript) v jakém čase(časový interval).Definice některých úloh je složitější, například definice úlohy, která má být dokončena v několika úkolech, a závislosti mezi úkoly, jakož i požadavky na zdroje každého úkolu.
- úkol: úloha musí být naplánována do konkrétních výkonnostních úkolů. Pokud definujeme úlohu pro provedení skriptu v 1am každou noc, pak je proces skriptu prováděný v 1am každý den úkolem.
při navrhování systému plánování clusteru jsou hlavní úkoly systému dvě:
- plánování úkolů: Po práci jsou předloženy ke clusteru plánovací systém, předložená práce musí být rozděleny na konkrétní plnění úkolů a výsledky provádění úkolů, které musí být sledovány a monitorovány. V příkladu distribuovaného Cron musí plánovací systém včas zahájit proces v souladu s požadavky operace. Pokud se proces nepodaří provést, opakování je nutné atd. Některé složité scénáře, jako je Hadoop Map Snížit, plánovací systém musí rozdělit Mapu úkol Snížit do odpovídající více Map a Snížit úkoly, a nakonec ten hlavní výsledek zpracování údajů.
- plánování zdrojů: v podstatě se používá k přiřazení úkolů a zdrojů a vhodné prostředky jsou přiděleny ke spuštění úkolů podle využití zdrojů hostitelů v clusteru. To je podobný proces plánování algoritmu operačního systému, hlavním cílem plánování zdrojů je zlepšit využití zdrojů, tak daleko, jak je to možné, a snížit čekací dobu pro úkoly pod podmínkou fixní zásobu zdrojů, a snížit zpoždění úkolu nebo času odezvy (pokud je dávkový úkol, to se odkazuje na dobu, od začátku do konce pracovní činnosti, pokud je online typ odpovědi úkoly, jako jsou Webové aplikace, které se týká každé doby odezvy na požadavek), Úkol prioritou musí být vzaty v úvahu, přičemž je stejně spravedlivé, jako možné (zdroje jsou spravedlivě přiděleny všem úkolům). Některé z těchto cílů jsou protichůdné a je třeba je vyvážit, jako je využití zdrojů, doba odezvy, spravedlnost a priority.
Hadoop MRv1
Map Reduce je druh paralelního výpočetního modelu. Hadoop může spustit tento druh clusterové platformy pro správu paralelních počítačů. MRv1 je první generace verze Map snížit plánování úloh motoru Hadoop platformy. Stručně řečeno, MRv1 je zodpovědný za plánování a provádění úlohy na clusteru a návrat k výsledkům výpočtu, když uživatel definuje mapu snížit výpočet a odeslat ji Hadoop. Zde je to, co architektura MRv1 vypadá:
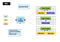
architektura je poměrně jednoduchá, standardní Master/Slave architektura má dvě základní součásti:
- Job Tracker je hlavní součástí správy clusteru, který je zodpovědný za plánování zdrojů i plánování úkolů.
- Task Tracker běží na každém počítači v clusteru, který je zodpovědný za spouštění konkrétních úkolů na hostiteli a stav hlášení.
S popularitou Hadoop a zvýšení různé požadavky, MRv1 má následující problémy být lepší:
- výkon má určitou překážkou: maximální počet uzlů podporujících správu je 5 000 a maximální počet úkolů podporujících provoz je 40 000. Stále existuje prostor pro zlepšení.
- není dostatečně flexibilní pro rozšíření nebo podporu jiných typů úloh. Kromě úkolů typu Map reduce existuje v ekosystému Hadoop mnoho dalších typů úkolů, které je třeba naplánovat, jako je Spark, Hive, HBase, Storm, Oozie atd. Proto je zapotřebí obecnější plánovací systém, který může podporovat a rozšiřovat více typů úloh
- Nízké využití zdrojů: MRv1 staticky nastaví fixní počet slotů pro každý uzel, a každý slot může být použit pouze pro konkrétní typ úkolu (Mapa nebo Snížit), což vede na problém využití zdrojů. Například velké množství mapových úkolů stojí ve frontě na nečinné zdroje, ale ve skutečnosti je velké množství redukčních slotů nečinných pro stroje.
- problémy s více nájmy a více verzemi. Například, různá oddělení spouštění úloh ve stejném clusteru, ale jsou logicky odděleny od sebe navzájem, nebo se spustit různé verze Hadoop ve stejném clusteru.
PŘÍZE
PŘÍZE(Další Zdrojů, Vyjednavač), je druhý-generace Hadoop ,jejichž hlavním účelem je vyřešit všechny druhy problémů v MRv1. PŘÍZE architektura vypadá takto:

jednoduché pochopení PŘÍZE je, že hlavní zlepšení oproti MRv1 je rozdělit povinnosti původní JobTrack do dvou různých složek: Resource Manager a Aplikace Master
- Resource Manager: Je zodpovědný za plánování zdrojů, spravuje všechny zdroje, přiřazuje zdroje různým typům úkolů a snadno rozšiřuje algoritmus plánování zdrojů prostřednictvím zásuvné architektury.
- Application Master: je zodpovědný za plánování úkolů. Každá úloha (nazývaná aplikace v přízi) spustí odpovídající Master aplikace, který je zodpovědný za rozdělení úlohy na konkrétní úkoly a žádost o zdroje od správce zdrojů, spuštění úkolu, sledování stavu úkolu a hlášení výsledků.
Pojďme se podívat na to, jak tato architektura změnit vyřešen MRv1 různé problémy:
- Rozdělení původní plánování úloh povinnosti Job Tracker, a výsledkem je významné zlepšení výkonu. Úkolem plánování povinnosti původního Job Tracker byly rozděleny tak, aby být provedeny pomocí Aplikace Master a Aplikace Master byl distribuován, každá instance pouze zpracována žádost jedné Práci, proto je povýšen maximální počet uzlů clusteru od 5000 do 10000.
- komponenty plánování úloh, Master aplikací a plánování zdrojů jsou odděleny a dynamicky vytvářeny na základě požadavků na úlohy. Jedna instance aplikace Master je zodpovědná pouze za jednu úlohu plánování, což usnadňuje podporu různých typů úloh.
- nádoby izolace technologie je zavedena, každý úkol je spustit v izolovaném kontejneru, který výrazně zlepšuje využití zdrojů podle úkolu je poptávka po zdrojích, které mohou být alokovány dynamicky. Nevýhodou je, že správa zdrojů a alokace mají pouze jednu dimenzi paměti.
mesos architecture
cílem návrhu příze je stále sloužit plánování ekosystému Hadoop. Cíl společnosti Mesos se blíží, je navržen jako obecný plánovací systém, který dokáže řídit provoz celého datového centra. Jak vidíme, architektonický návrh společnosti Mesos používal pro referenci hodně příze, plánování úloh a plánování zdrojů nesou různé moduly Samostatně. Největším rozdílem mezi Mesos a YARN je však způsob plánování zdrojů, je navržen jedinečný mechanismus nazvaný nabídka zdrojů. Tlak plánování zdrojů se dále uvolňuje a zvyšuje se také škálovatelnost plánování úloh.

hlavní složky Mesos jsou:
- Mesos Mistr: To je součástí výhradní odpovědnost za přidělování Zdrojů a složek řízení, což je Správce prostředků odpovídající uvnitř PŘÍZE. Režim provozu se však mírně liší, pokud bude projednán později.
- rámec: je zodpovědný za plánování úloh, různé typy úloh budou mít odpovídající rámec, například rámec Spark, který je zodpovědný za úlohy Spark.
Resource Nabídka Mesos
To se může zdát jako Mesos a PŘÍZE architektur jsou velmi podobné, ale ve skutečnosti, v aspektu řízení Zdrojů, Mistr Mesos má velmi unikátní (a poněkud bizarní) Zdroje Nabízejí mechanismus:
- PŘÍZE je Vytáhnout: Zdroje poskytnuté Resource Manager v PŘÍZE je pasivní,když spotřebitelé zdrojů (Aplikace Master) potřebuje zdroje, může volat rozhraní Správce prostředků k získání prostředků, a Resource Manager pouze pasivně reaguje na potřeby Aplikace Master.
- Mesos je Push: zdroje poskytované Master of Mesos jsou aktivní. Master of Mesos bude pravidelně přebírat iniciativu a tlačit všechny současné dostupné zdroje (takzvané nabídky zdrojů, od nynějška to budu nazývat nabídkou) do rámce. Pokud existují úkoly, které má rámec provádět, nemůže aktivně žádat o zdroje, pokud nebudou obdrženy nabídky. Rámec vybere kvalifikovaný zdroj z Nabídky přijmout (tento pohyb se nazývá Přijmout v Mesos,) a odmítnout zbývající nabídky (tento pohyb se nazývá Odmítnout). Pokud v tomto kole nabídky není dostatek kvalifikovaných zdrojů, musíme počkat na další kolo Master, abychom nabídli nabídku.
věřím, že když uvidíte tento mechanismus aktivní nabídky, budete mít stejný pocit se mnou. To znamená, že účinnost je relativně nízká a vzniknou následující problémy:
- účinnost rozhodování jakéhokoli rámce ovlivňuje celkovou účinnost. Pro konzistenci může Master poskytnout nabídku pouze jednomu rámci najednou a počkat, až rámec vybere nabídku, než zbytek poskytne dalšímu rámci. Tímto způsobem bude mít rozhodovací účinnost jakéhokoli rámce vliv na celkovou účinnost.
- “plýtvání” hodně času na rámcích, které nevyžadují zdroje. Mesos opravdu neví, který rámec potřebuje zdroje. Takže tam bude rámec s požadavky na zdroje je ve frontě na nabídku, ale rámec bez požadavků na zdroje přijímá nabídku často.
V reakci na výše uvedené otázky, Mesos poskytl některé mechanismy ke zmírnění problémů, jako je například nastavení časového limitu pro Rámec, aby se rozhodnutí, nebo umožní Rámec odmítnout nabídky, nastavením, aby to bylo Potlačit státu. Protože se nejedná o zaměření této diskuse, podrobnosti jsou zde zanedbávány.
ve skutečnosti existují některé zjevné výhody pro Mesos pomocí tohoto mechanismu aktivní nabídky:
- výkon je evidentně lepší. Cluster může podporovat až 100 000 uzlů podle simulačního testování, pro produkční prostředí Twitteru může největší cluster podporovat 80 000 uzlů. hlavním důvodem je, že aktivní nabídka mechanismu Mesos Master dále zjednodušuje odpovědnost Mesos. proces plánování zdrojů, přiřazení zdrojů k úkolům, v Mesos je rozdělen do dvou fází: zdroje k nabídce a nabídka k úkolu. Mistr Mesos je zodpovědný pouze za dokončení první fáze a přizpůsobení druhé fáze je ponecháno na rámci.
- flexibilnější a schopnější splnit odpovědnější zásady plánování úkolů. Například strategie využití zdrojů všech nebo nic.
Plánování algoritmus Mesos DRF (Dominantní Zdroj Spravedlnost)
Jako pro DRF algoritmus, to vlastně nemá nic společného s naším chápáním Mesos architektury, ale to je velmi základní a důležité v Mesos, tak jsem se to vysvětlit trochu více zde.
jak již bylo zmíněno výše, Mesos zase poskytuje nabídku frameworku, takže který rámec by měl být vybrán pro poskytování nabídky pokaždé? Toto je hlavní problém, který má být vyřešen algoritmem DRF. Základním principem je zohlednit jak spravedlnost, tak efektivitu. Při splnění všech požadavků na zdroje rámce by mělo být co nejspravedlivější zabránit tomu, aby jeden rámec spotřebovával příliš mnoho zdrojů a hladověl jiné rámce k smrti.
DRF je varianta algoritmu min-max fairness. Jednoduše řečeno, je vybrat Rámec s nejnižším dominantním využitím zdrojů, který bude pokaždé poskytovat nabídku. Jak vypočítat dominantní využití zdrojů rámce? Ze všech typů zdrojů obsazených rámcem je jako dominantní zdroj vybrán typ zdroje s nejnižší mírou obsazenosti zdrojů. Jeho míra obsazenosti zdrojů je přesně dominantním využitím zdrojů rámce. Například procesor Framework zabírá 20% celkového zdroje, 30% paměti a 10% disku. Takže dominantní využití zdrojů rámce bude 10%, oficiální termín nazývá disk jako dominantní zdroj, a toto 10% se nazývá dominantní využití zdrojů.
konečným cílem DRF je distribuovat zdroje rovnoměrně mezi všechny rámce. Pokud Framework X přijme v tomto kole nabídky příliš mnoho zdrojů, bude to trvat mnohem déle, než se dostane příležitost dalšího kola nabídky. Nicméně, pečlivé čtenáře, zjistíte, že tam je předpoklad, v tomto algoritmu, který je, po Rámec přijímá zdrojů, to uvolní je rychle, jinak tam bude dva důsledky:
- z Jiných rámců vyhladovět k smrti. Jeden rámec a přijímá většinu zdrojů v klastru najednou a úkol běží bez ukončení, takže většina zdrojů je neustále obsazena rámcem a a další rámce již nebudou mít zdroje.
- Vyhladov se k smrti. Protože dominantní využití zdrojů tohoto rámce je vždy velmi vysoké, takže není šance získat nabídku na dlouhou dobu, takže nelze spustit více úkolů.
takže Mesos je vhodný pouze pro plánování krátkých úkolů a Mesos byly původně navrženy pro krátké úkoly datových center.
Shrnutí
Od velké architektury, všechny plánovací systém architektura je Master/Slave architektura, Otrok konci je instalován na každém počítači s požadavkem managementu, který se používá pro sběr informací o hostiteli, a plnit úkoly na hostitele. Master je zodpovědný především za plánování zdrojů a plánování úkolů. Plánování zdrojů má vyšší požadavky na výkon a plánování úkolů má vyšší požadavky na škálovatelnost. Obecným trendem je diskutovat o dvou druzích oddělení povinností a doplnit je různými složkami.
