Ceph
Benchmark Ceph Cluster Performance venstre
et af de mest almindelige spørgsmål, vi hører, er “hvordan kontrollerer jeg, om min klynge kører med maksimal ydelse?”. Spekulerer ikke mere – i denne vejledning, Vi leder dig gennem nogle værktøjer, du kan bruge til at benchmarke din Ceph-klynge.
Bemærk: ideerne i denne artikel er baseret på Sebastian Han ‘s blogindlæg, TelekomCloud’ s blogindlæg og input fra Ceph udviklere og ingeniører.
få Baseline præstationsstatistik
grundlæggende handler benchmarking om sammenligning. Du ved ikke, om din Ceph-klynge udfører under pari, medmindre du først identificerer, hvad dens maksimale ydeevne er. Så før du begynder at benchmarke din klynge, skal du få baseline performance Statistik for de to hovedkomponenter i din Ceph-infrastruktur: dine diske og dit netværk.
Benchmark dine diske Larst
den enkleste måde at benchmarke din disk er med DD. Brug følgende kommando til at læse og skrive en fil, og husk at tilføje Oflag-parameteren for at omgå disksidecachen:shell> dd if=/dev/zero of=here bs=1G count=1 oflag=direct
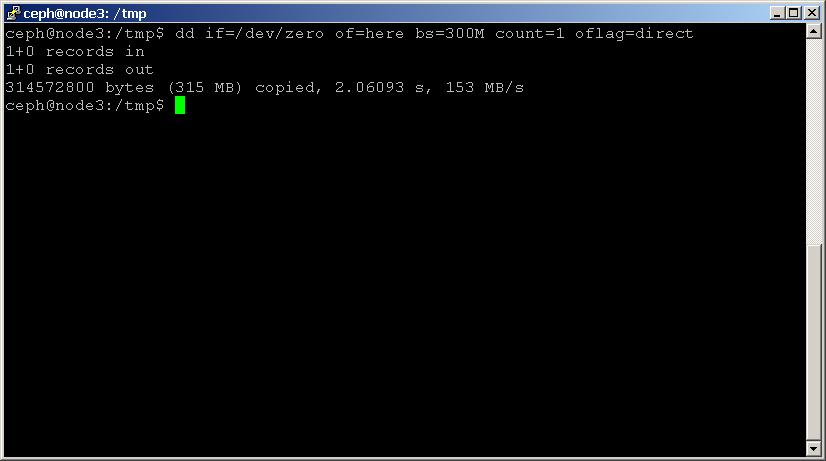
Bemærk den sidste angivne statistik, som angiver diskens ydeevne i MB / sek. udfør denne test for hver disk i din klynge, og noter resultaterne.
Benchmark dit Netværkslog
en anden nøglefaktor, der påvirker Ceph-klyngens ydeevne, er netværksgennemstrømning. Et godt værktøj til dette er iperf, der bruger en klient-serverforbindelse til at måle TCP-og UDP-båndbredde.
du kan installere iperf ved hjælp af apt-get install iperf eller yum install iperf.
iperf skal installeres på mindst to noder i din klynge. Start derefter iperf-serveren på en af noderne ved hjælp af følgende kommando:
shell> iperf -s
på en anden node skal du starte klienten med følgende kommando og huske at bruge IP-adressen på den node, der er vært for iperf-serveren:
shell> iperf -c 192.168.1.1
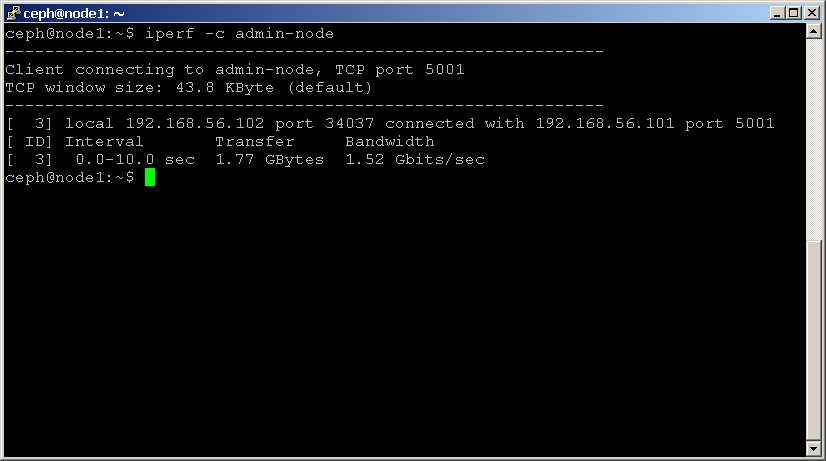
Bemærk båndbreddestatistikken i Mbits/sek, da dette angiver den maksimale kapacitet, der understøttes af dit netværk.
nu hvor du har nogle baseline-numre, kan du begynde at benchmarke din Ceph-klynge for at se, om den giver dig lignende ydeevne. Benchmarking kan udføres på forskellige niveauer: du kan udføre benchmarking på lavt niveau af selve lagringsklyngen, eller du kan udføre benchmarking på højere niveau af nøglegrænsefladerne, såsom blokenheder og objektportaler. I de følgende afsnit diskuteres hver af disse tilgange.
Bemærk: Før du kører nogen af benchmarks i efterfølgende sektioner, skal du slippe alle caches ved hjælp af en kommando som denne:shell> sudo echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
Benchmark a Ceph Storage Cluster Ceph
Ceph inkluderer rados bench-kommandoen, designet specielt til at benchmarke en RADOS storage cluster. For at bruge det skal du oprette en opbevaringspool og derefter bruge rados bench til at udføre et skrivebenchmark, som vist nedenfor.
rados-kommandoen er inkluderet i Ceph.
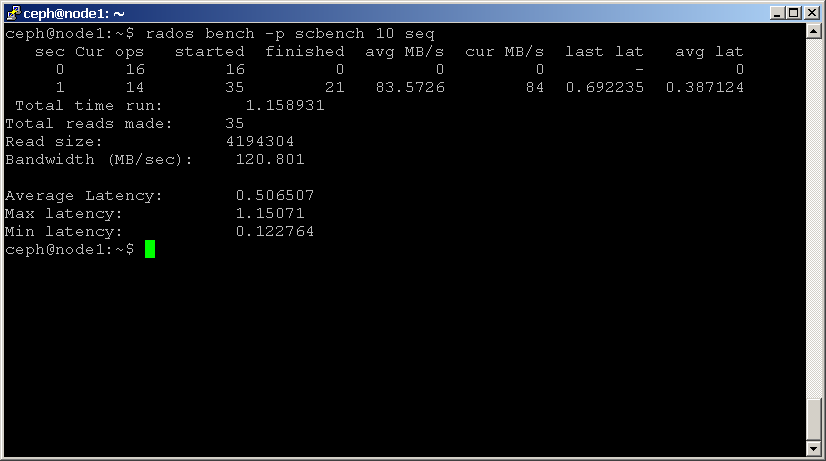
shell> ceph osd pool create scbench 128 128
shell> rados bench -p scbench 10 write --no-cleanup
dette skaber en ny pulje med navnet ‘scbench’ og derefter udfører en skrive benchmark for 10 sekunder. Bemærk indstillingen –no-cleanup, som efterlader nogle data. Outputtet giver dig en god indikator for, hvor hurtigt din klynge kan skrive data.
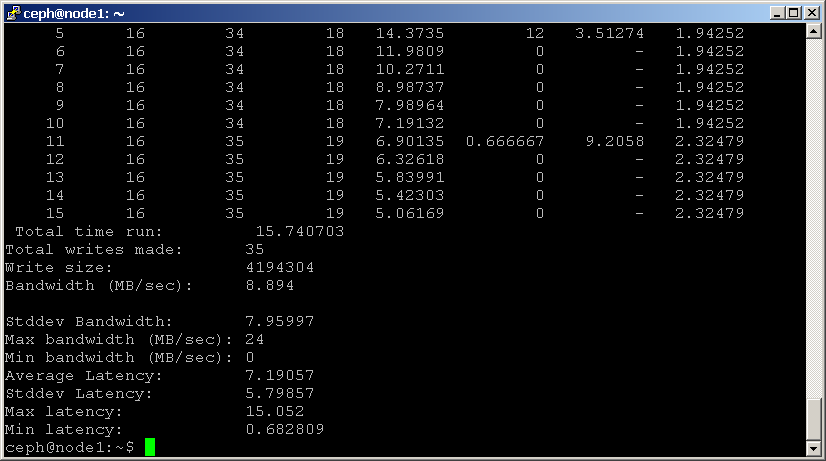
der findes to typer læsebenchmarks: sekv for sekventielle læsninger og rand for tilfældige læsninger. For at udføre et læsebenchmark skal du bruge kommandoerne nedenfor:shell> rados bench -p scbench 10 seq
shell> rados bench -p scbench 10 rand
du kan også tilføje parameteren-t for at øge samtidigheden af læser og skriver (som standard til 16 tråde) eller parameteren-b for at ændre størrelsen på det objekt, der skrives (som standard til 4 MB). Det er også en god ide at køre flere kopier af dette benchmark mod forskellige puljer for at se, hvordan ydeevnen ændres med flere klienter.
når du har dataene, kan du begynde at sammenligne klyngens læse-og skrivestatistikker med de disk-kun benchmarks, der er udført tidligere, identificere, hvor meget af et præstationsgab der findes (hvis nogen), og begynde at lede efter grunde.
du kan rydde op benchmark data efterladt af skrive benchmark med denne kommando:
shell> rados -p scbench cleanup
Benchmark a Ceph Block Device List
hvis du er fan af Ceph block-enheder, er der to værktøjer, du kan bruge til at benchmarke deres ydeevne. Ceph inkluderer allerede RBD bench-kommandoen, men du kan også bruge det populære i/O benchmarking-værktøj fio, som nu leveres med indbygget understøttelse af RADOS-blokenheder.
kommandoen rbd er inkluderet i Ceph. RBD-understøttelse i fio er relativt ny, derfor skal du hente den fra dens lager og derefter kompilere og installere den ved hjælp af_ configure && make && make install_. Bemærk, at du skal installere udviklingspakken librbd-dev med apt-get install librbd-dev eller yum install librbd-dev, før du kompilerer fio for at aktivere dens RBD-support.
før du bruger et af disse to værktøjer, skal du dog oprette en blokenhed ved hjælp af kommandoerne nedenfor:shell> ceph osd pool create rbdbench 128 128
shell> rbd create image01 --size 1024 --pool rbdbench
shell> sudo rbd map image01 --pool rbdbench --name client.admin
shell> sudo /sbin/mkfs.ext4 -m0 /dev/rbd/rbdbench/image01
shell> sudo mkdir /mnt/ceph-block-device
shell> sudo mount /dev/rbd/rbdbench/image01 /mnt/ceph-block-device
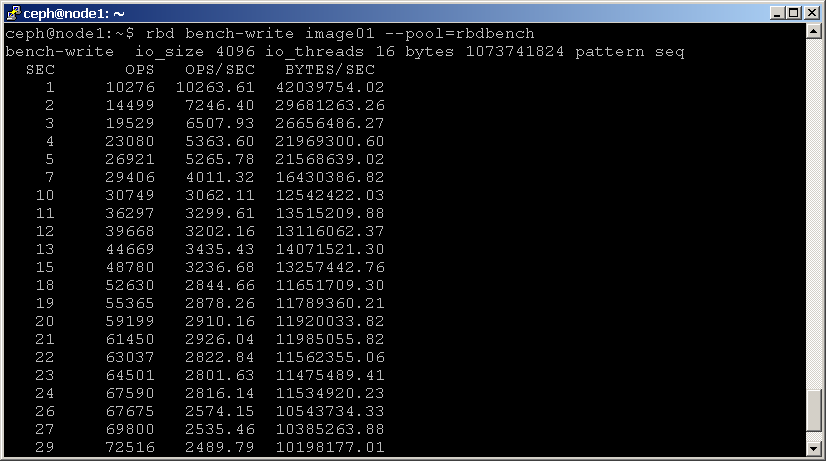
RBD bench-skriv kommando genererer en række sekventielle skriver til billedet og måle skrive gennemløb og latenstid. Her er et eksempel:
shell> rbd bench-write image01 --pool=rbdbench
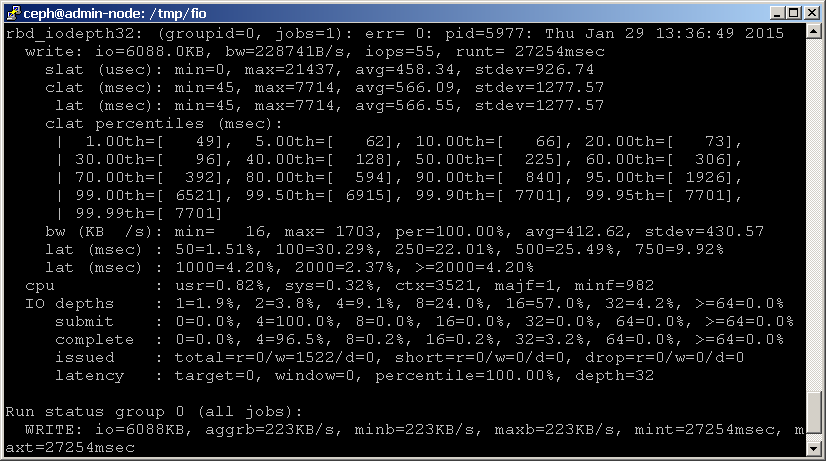
eller du kan bruge fio til at benchmarke din blokenhed. Et eksempel rbd.fio skabelon er inkluderet i fio kildekode, som udfører en 4K tilfældig skrive test mod en RADOS blok enhed via librbd. Bemærk, at du bliver nødt til at opdatere skabelonen med de korrekte navne til din pool og enhed, som vist nedenfor.
ioengine=rbd
clientname=admin
pool=rbdbench
rbdname=image01
rw=randwrite
bs=4k
iodepth=32
kør derefter fio som følger:shell> fio examples/rbd.fio
Benchmark en Ceph-Objektportal til Ceph
når det kommer til benchmarking af Ceph-objektportalen, skal du ikke lede længere end hurtigbænk, benchmarkingsværktøjet, der følger med OpenStack hurtig. Hurtigbænkværktøjet tester ydeevnen for din Ceph-klynge ved at simulere klient PUT and GET-anmodninger og måle deres ydeevne.
du kan installere hurtigbænk ved hjælp af pip installer hurtig& & pip installer hurtigbænk.
hvis du vil bruge hurtigbænk, skal du først oprette en portbruger og underbruger, som vist nedenfor:shell> sudo radosgw-admin user create --uid="benchmark" --display-name="benchmark"
shell> sudo radosgw-admin subuser create --uid=benchmark --subuser=benchmark:swift
--access=full
shell> sudo radosgw-admin key create --subuser=benchmark:swift --key-type=swift
--secret=guessme
shell> radosgw-admin user modify --uid=benchmark --max-buckets=0
opret derefter en konfigurationsfil til hurtigbænk på en klientvært, som nedenfor. Husk at opdatere autentificerings-URL ‘ en for at afspejle den for din Ceph-objektportal og for at bruge det korrekte brugernavn og legitimationsoplysninger.
auth = http://gateway-node/auth/v1.0
user = benchmark:swift
key = guessme
auth_version = 1.0
du kan nu køre et benchmark som nedenfor. Brug parameteren-c til at justere antallet af samtidige forbindelser (dette eksempel bruger 64) og parameteren-s til at justere størrelsen på det objekt, der skrives (dette eksempel bruger 4K-objekter). Parametrene-n og-g styrer antallet af objekter, der skal placeres og hentes henholdsvis.shell> swift-bench -c 64 -s 4096 -n 1000 -g 100 /tmp/swift.conf
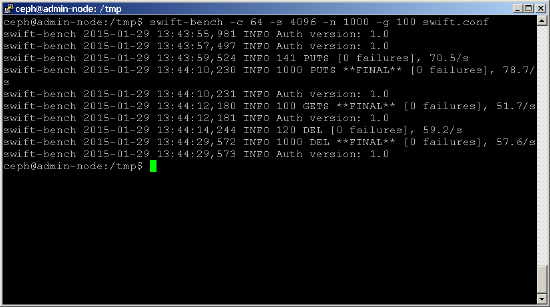
selvom hurtigbænk måler ydeevne i antal objekter / SEK, er det let nok at konvertere dette til MB/sek ved at multiplicere med størrelsen på hvert objekt. Du skal dog være forsigtig med at sammenligne dette direkte med de baseline-diskpræstationsstatistikker, du har opnået tidligere, da en række andre faktorer også påvirker disse statistikker, såsom:
- niveauet for replikation (og latenstid overhead)
- Fuld data journal skriver (udlignet i nogle situationer af journal data coalescing)
- fsync på OSDs for at garantere datasikkerhed
- metadata overhead for at holde data gemt i RADOS
- latency overhead (netværk, Ceph, etc) gør readahead vigtigere
tip: Når det kommer til objektportalens ydeevne, er der ingen hård og hurtig regel, du kan bruge til nemt at forbedre ydeevnen. I nogle tilfælde har Ceph-ingeniører været i stand til at opnå bedre ydeevne end baseline ved hjælp af smarte caching-og koalesceringsstrategier, mens objektportalens ydeevne i andre tilfælde har været lavere end diskens ydeevne på grund af latenstid, fsync og metadata overhead.
konklusion
der er en række værktøjer til rådighed til at benchmarke en Ceph-klynge på forskellige niveauer: disk, netværk, klynge, enhed og Port. Du skal nu have et indblik i, hvordan du nærmer dig benchmarkingprocessen og begynder at generere ydelsesdata for din klynge. Held og lykke!