Cloud Data lager vs Traditionelle Data lager koncepter
Cloud-baserede data lagre er den nye norm. Borte er de dage, hvor din virksomhed skulle købe udstyr, oprette serverrum og leje, træne og vedligeholde et dedikeret team af medarbejdere til at køre det. Nu, med et par klik på din bærbare computer og et kreditkort, kan du få adgang til praktisk talt ubegrænset computerkraft og lagerplads.
dette betyder dog ikke, at traditionelle datalagerideer er døde. Klassisk datalagerteori understøtter det meste af, hvad skybaserede datalagre gør.
i denne artikel forklarer vi de traditionelle datalagerkoncepter, du har brug for at kende, og de vigtigste cloud-koncepter fra et udvalg af de bedste udbydere:
lad os komme i gang.
- traditionelle Datalagerkoncepter
- fakta, dimensioner og mål
- normalisering og denormalisering
- datamodeller
- faktatabel
- Stjerneskema vs. snefnugskema
- OLAP vs. OLTP
- tre Tier arkitektur
- virtuelt datalager / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data lager
- Cloud Data lager koncepter
- Cloud Data lager koncepter –
- klynger
- noder
- partitioner/skiver
- Columnar Storage
- komprimering
- indlæsning af Data
- Cloud Database lager – Google Storforespørgsel
- Serverløs Service
- Colossus filsystem
- Dremel Eksekveringsmotor
- datadeling
- Streaming og Batchindtagelse
- cloud Data Lagerkoncepter – Panoply
- primære nøgler
- inkrementelle nøgler
- indlejrede Data
- Historiktabeller
- transformationer
- Strengformater
- databeskyttelse
- adgangskontrol
- IP-hvidliste
- konklusion: traditionelle kontra Datalagerkoncepter i korte træk
- traditionelle Datalagerkoncepter
- cloud Data Lagerkoncepter som eksempel
- Cloud Data Lagerkoncepter – Storforespørgsel som eksempel
- traditionel vs. Cloud Cost-Benefit-analyse
- Lær mere om datalager
traditionelle Datalagerkoncepter
et datalager er ethvert system, der samler data fra en lang række kilder i en organisation. Datalagre bruges som centraliserede datalagre til analytiske og rapporteringsformål.
et traditionelt datalager er placeret på stedet på dine kontorer. Du køber udstyret, serverrummet og ansætter personalet til at køre det. De kaldes også On-premises, on-prem eller (grammatisk forkert) on-premise datalager.
fakta, dimensioner og mål
de centrale byggesten for information i et datalager er fakta, dimensioner og mål.
en kendsgerning er den del af dine data, der angiver en bestemt forekomst eller transaktion. For eksempel, hvis din virksomhed sælger blomster, er nogle fakta, du vil se i dit datalager:
- solgt 30 roser i butikken for $19.99
- bestilte 500 nye blomsterpotter fra Kina til $1500
- betalt løn af kasserer for denne måned $1000
flere tal kan beskrive hver kendsgerning, og vi kalder disse tal foranstaltninger. Nogle foranstaltninger til at beskrive det faktum ‘bestilte 500 nye blomsterpotter fra Kina til $1500’ er:
- antal bestilt-500
- omkostninger – $1500
når analytikere arbejder med data, udfører de beregninger på målinger (f.eks. For eksempel vil du måske vide det gennemsnitlige antal blomsterpotter, du bestiller hver måned.
en dimension kategoriserer fakta og foranstaltninger og giver strukturerede mærkningsoplysninger til dem – ellers ville de bare være en samling af uordnede tal! Nogle dimensioner til at beskrive det faktum ‘bestilte 500 nye blomsterpotter fra Kina til $1500’ er:
- land købt fra – Kina
- tid købt – 1 pm
- forventet ankomstdato – 6. juni
du kan ikke udføre beregninger på dimensioner eksplicit, og det ville sandsynligvis ikke være meget nyttigt – hvordan kan du finde ‘gennemsnitlig ankomstdato for ordrer’? Det er dog muligt at oprette nye mål fra dimensioner, og disse er nyttige. For eksempel, hvis du kender det gennemsnitlige antal dage mellem ordredato og ankomstdato, kan du bedre planlægge aktiekøb.
normalisering og denormalisering
normalisering er processen med effektiv organisering af data i et datalager (eller ethvert andet sted, der gemmer data). De vigtigste mål er at reducere dataredundans-dvs. fjerne eventuelle duplikatdata – og forbedre dataintegriteten-dvs.forbedre nøjagtigheden af data. Der er forskellige niveauer af normalisering og ingen konsensus for den ‘bedste’ metode. Imidlertid involverer alle metoder lagring af separate, men relaterede stykker information i forskellige tabeller.
der er mange fordele ved normalisering, såsom:
- hurtigere søgning og sortering på hver tabel
- enklere tabeller gør dataændringskommandoer hurtigere at skrive og udføre
- mindre overflødige data betyder, at du sparer på diskplads, og så kan du indsamle og gemme flere data
denormalisering er processen med bevidst at tilføje overflødige kopier eller grupper af data til allerede normaliserede data. Det er ikke det samme som un-normaliserede data. Denormalisering forbedrer læseydelsen og gør det meget lettere at manipulere tabeller til formularer, du ønsker. Når analytikere arbejder med datalagre, udfører de typisk kun læsninger på dataene. Således kan denormaliserede data spare dem store mængder tid og hovedpine.
fordele ved denormalisering:
- færre tabeller minimerer behovet for tabelforbindelser, hvilket fremskynder dataanalytikernes arbejdsgang og får dem til at opdage mere nyttig indsigt i dataene
- færre tabeller forenkler forespørgsler, der fører til færre fejl
datamodeller
det ville være vildt ineffektivt at gemme alle dine data i en massiv tabel. Så dit datalager indeholder mange tabeller, som du kan deltage sammen for at få specifikke oplysninger. Hovedbordet kaldes en faktatabel, og dimensionstabeller omgiver det.
det første trin i design af et datalager er at opbygge en konceptuel datamodel, der definerer de ønskede data og forholdet på højt niveau mellem dem.
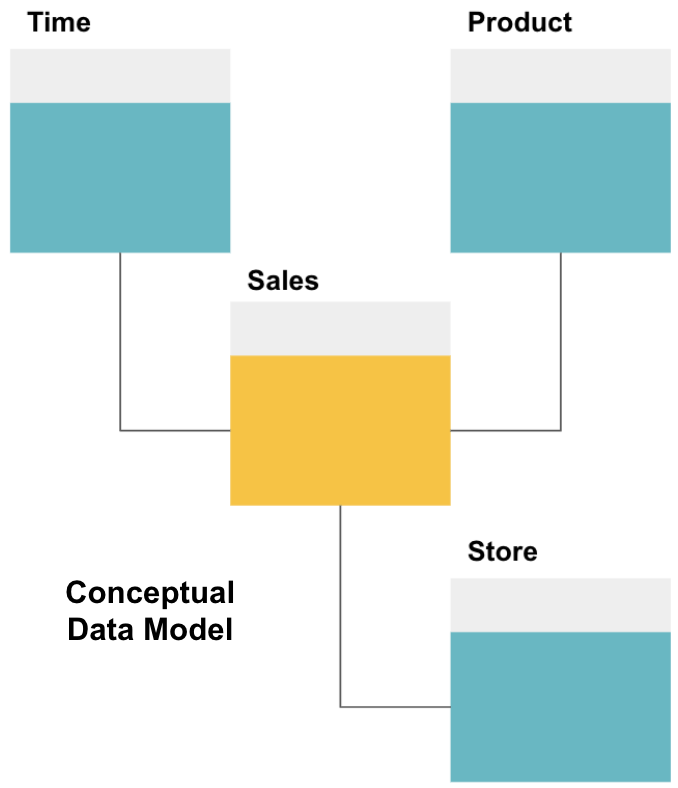
her har vi defineret den konceptuelle model. Vi lagrer salgsdata og har tre ekstra tabeller – tid, Produkt, og butik – der giver ekstra, mere detaljeret information om hvert salg. Faktatabellen er salg, og de andre er dimensionstabeller.
det næste trin er at definere en logisk datamodel. Denne model beskriver dataene detaljeret på almindeligt engelsk uden at bekymre sig om, hvordan man implementerer dem i kode.
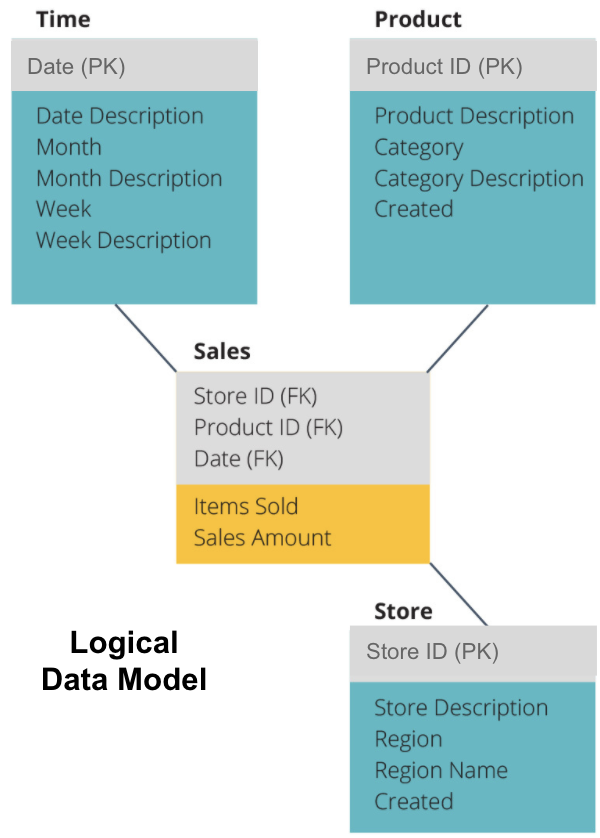
nu har vi udfyldt, hvilke oplysninger hver tabel indeholder på almindeligt engelsk. Hver af tids -, produkt-og Lagringsdimensionstabellerne viser den primære nøgle (PK) i det grå felt og de tilsvarende data i de blå felter. Salgstabellen indeholder tre udenlandske nøgler (FK), så den hurtigt kan slutte sig til de andre tabeller.
det sidste trin er at oprette en fysisk datamodel. Denne model fortæller dig, hvordan du implementerer datalageret i kode. Det definerer tabeller, deres struktur og forholdet mellem dem. Det specificerer også datatyper for kolonner, og alt er navngivet som det vil være i det endelige datalager, dvs.alle caps og forbundet med understregninger. Endelig starter hver dimensionstabel med DIM_, og hver faktatabel starter med FACT_.
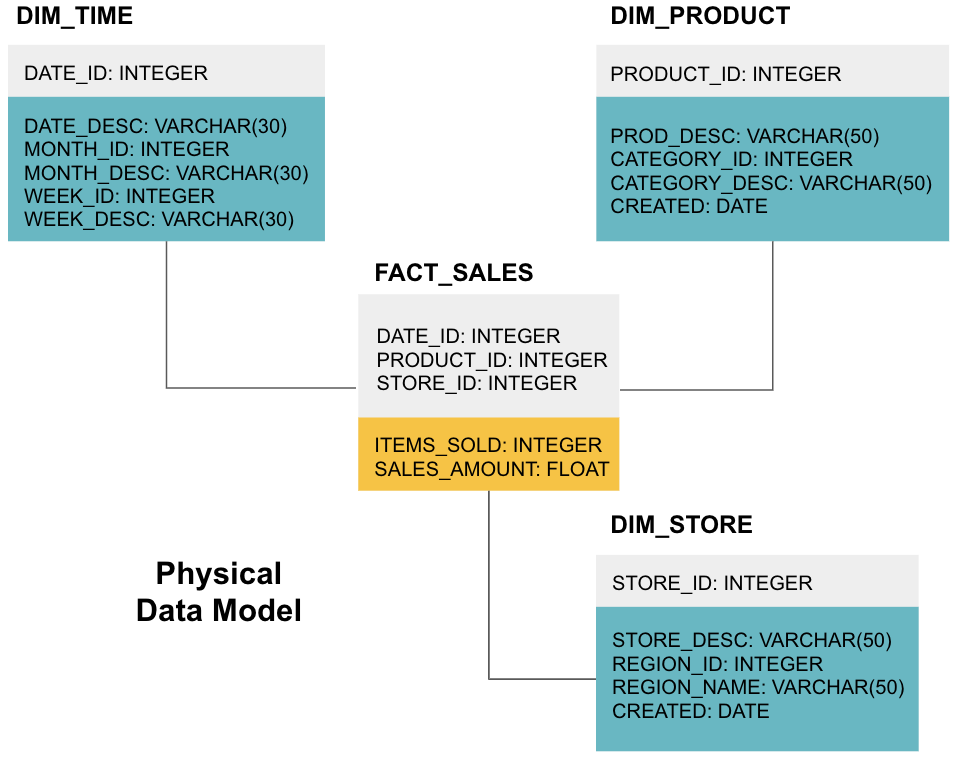
nu ved du, hvordan du designer et datalager, men der er et par nuancer til fakta og dimensionstabeller, som vi forklarer næste.
faktatabel
hver forretningsfunktion – f.eks.
faktatabeller har to typer kolonner: dimensionskolonner og faktakolonner. Dimensionskolonner – farvet grå i vores eksempler-indeholder udenlandske nøgler (FK), som du bruger til at deltage i en faktatabel med en dimensionstabel. Disse udenlandske nøgler er de primære nøgler (PK) for hver af dimensionstabellerne. Faktakolonner – farvet gul i vores eksempler-indeholder de faktiske data og mål, der skal analyseres, f.eks.
en faktatabel er en bestemt type faktatabel, der kun har dimensionskolonner. Sådanne tabeller er nyttige til sporing af begivenheder, såsom studerendes deltagelse eller medarbejderorlov, da dimensionerne fortæller dig alt hvad du behøver at vide om begivenhederne.
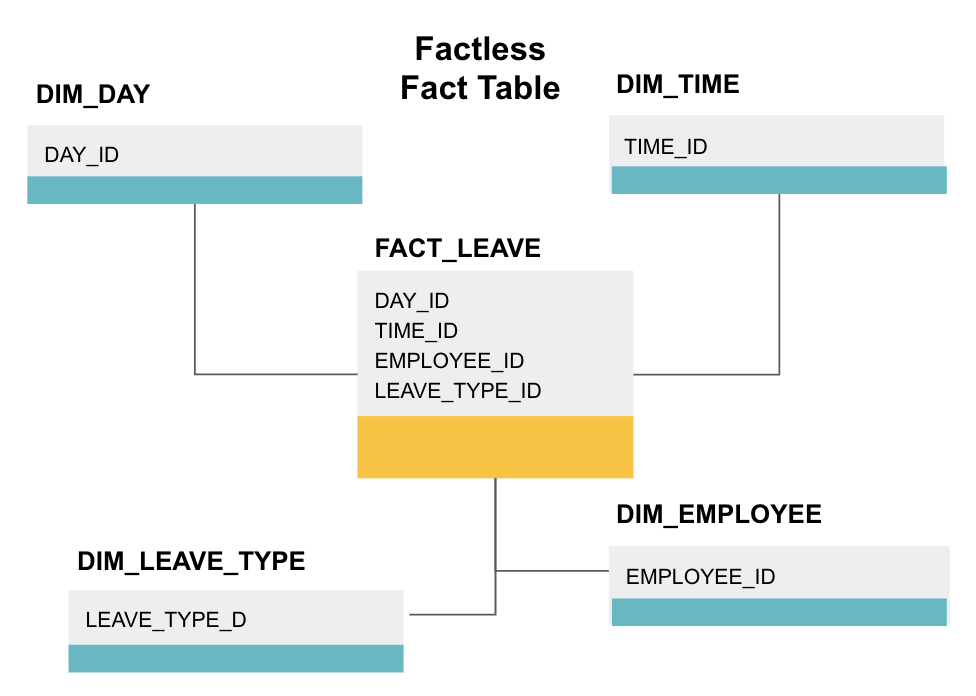
ovenstående faktabord sporer medarbejderorlov. Der er ingen fakta, da du bare skal vide:
- hvilken dag var de væk (DAY_ID).
- hvor længe de var slukket (TIME_ID).
- hvem var på orlov (EMPLOYEE_ID).
- deres grund til at være på orlov, f. eks., sygdom, ferie, lægeudnævnelse mv. (LEAVE_TYPE_ID).
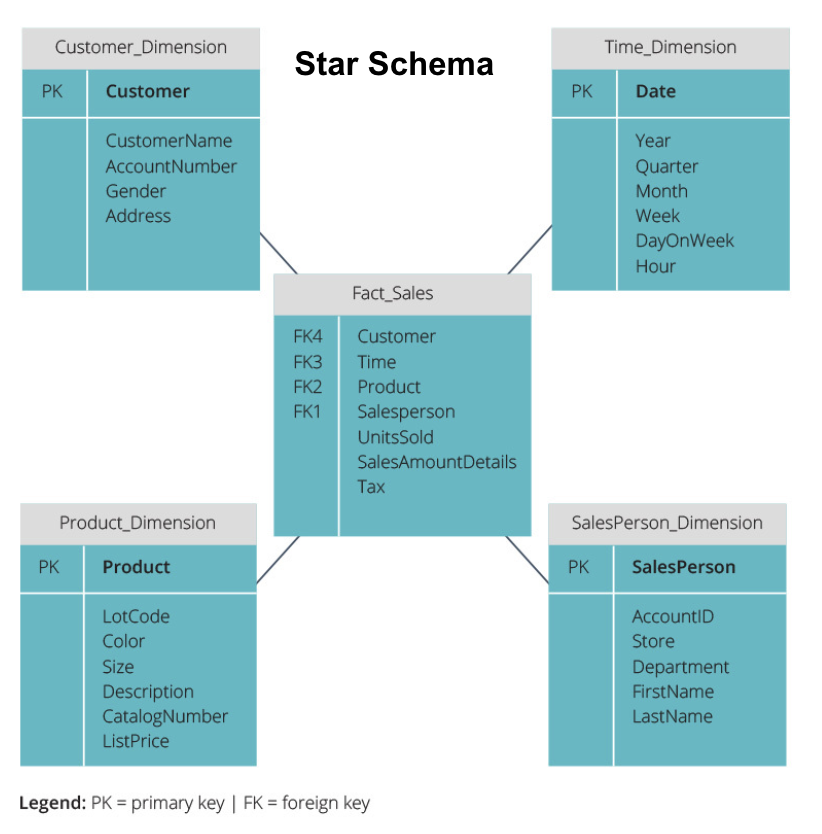
Stjerneskema vs. snefnugskema
ovenstående datalagre har alle haft et lignende layout. Dette er dog ikke den eneste måde at arrangere dem på.
de to mest almindelige skemaer, der bruges til at organisere datalagre, er stjerne og snefnug. Begge metoder bruger dimensionstabeller, der beskriver oplysningerne i en faktatabel.
stjerneskemaet tager informationen fra faktatabellen og opdeler den i denormaliserede dimensionstabeller. Vægten for stjerneskemaet er på forespørgselshastighed. Kun en join er nødvendig for at linke faktatabeller til hver dimension, så det er nemt at spørge hver tabel. Men da tabellerne er denormaliserede, indeholder de ofte gentagne og overflødige data.
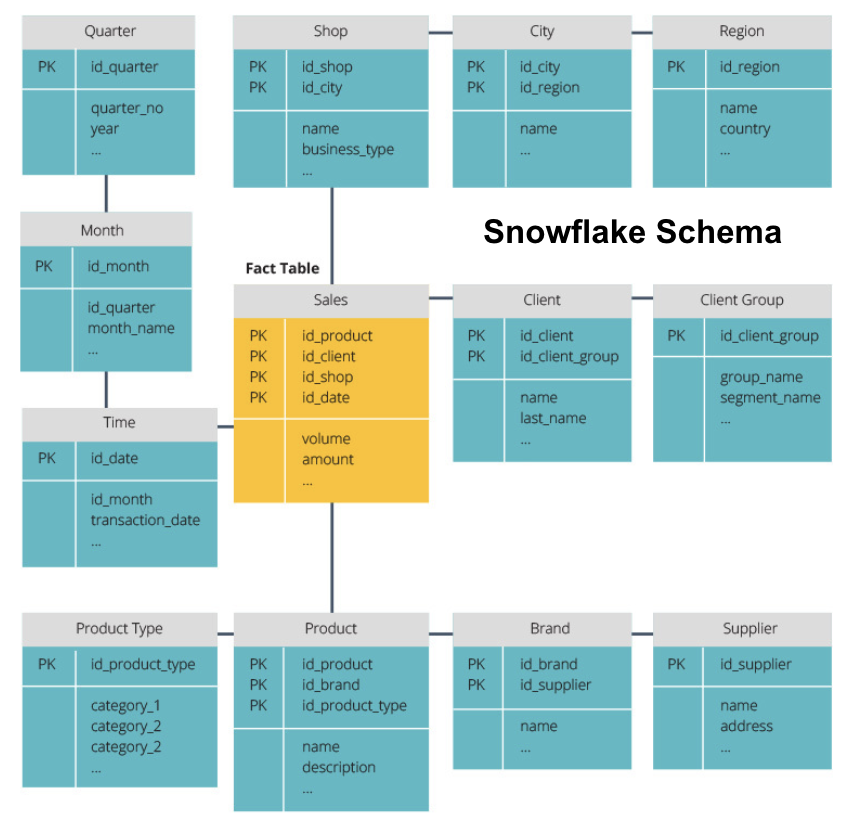
snefnugskemaet opdeler faktatabellen i en række normaliserede dimensionstabeller. Normalisering skaber flere dimensionstabeller og reducerer dermed dataintegritetsproblemer. Forespørgsel er dog mere udfordrende ved hjælp af snefnugskemaet, fordi du har brug for flere tabelforbindelser for at få adgang til de relevante data. Så du har mindre overflødige data, men det er sværere at få adgang til.
nu forklarer vi nogle mere grundlæggende datalagerkoncepter.
OLAP vs. OLTP
online transaktionsbehandling (OLTP) er kendetegnet ved korte skrivetransaktioner, der involverer front-end-applikationer i en virksomheds dataarkitektur. OLTP databaser understrege hurtig forespørgsel behandling og kun beskæftige sig med aktuelle data. Virksomheder bruger disse til at indsamle oplysninger til forretningsprocesser og levere kildedata til datalageret.
Online analytical processing (OLAP) giver dig mulighed for at køre komplekse læseforespørgsler og dermed udføre en detaljeret analyse af historiske transaktionsdata. OLAP-systemer hjælper med at analysere dataene i datalageret.
tre Tier arkitektur
traditionelle datalagre er typisk struktureret i tre niveauer:
- bundniveau: en databaseserver, typisk en RDBMS, der udtrækker data fra forskellige kilder ved hjælp af en port. Datakilder, der føres ind i dette niveau, inkluderer operationelle databaser og andre typer frontend-data såsom CSV-og JSON-filer.
- Middle Tier: en OLAP-server, der enten
- direkte implementerer operationerne, eller
- kortlægger operationerne på flerdimensionelle data til standard relationelle operationer, f.eks.
- Top Tier: forespørgnings-og rapporteringsværktøjerne til dataanalyse og business intelligence.
virtuelt datalager / Data Mart
virtuel datalagring bruger distribuerede forespørgsler på flere databaser uden at integrere dataene i et fysisk datalager.
Datamarts er undergrupper af datalagre, der er orienteret til specifikke forretningsfunktioner, såsom salg eller finansiering. Et datalager kombinerer typisk information fra flere datamarts i flere forretningsfunktioner. Endnu, en data mart indeholder data fra et sæt kildesystemer til en forretningsfunktion.
Kimball vs. Inmon
der er to tilgange til datalager design, foreslået af Bill Inmon og Ralph Kimball. Bill Inmon er en amerikansk computerforsker, der er anerkendt som far til datalageret. Ralph Kimball er en af de originale arkitekter inden for datalagring og har skrevet flere bøger om emnet.
de to eksperter havde modstridende meninger om, hvordan datalagre skulle struktureres. Denne konflikt har givet anledning til to tankeskoler.
inmon-tilgangen er et ovenfra og ned design. Med Inmon-metoden oprettes datalageret først og ses som den centrale komponent i det analytiske miljø. Data opsummeres og distribueres derefter fra det centraliserede lager til en eller flere afhængige datamarts.
Kimball-tilgangen tager et bottom-up billede af datalagerdesign. I denne arkitektur opretter en organisation separate datamarts, der giver visninger i enkelte afdelinger i en organisation. Datalageret er kombinationen af disse datamarts.
ETL vs. ELT
Uddrag, Transform, Load (ETL) beskriver processen med at udtrække dataene fra kildesystemer (typisk transaktionssystemer), konvertere dataene til et format eller en struktur, der er egnet til forespørgsel og analyse, og til sidst indlæse dem i datalageret. ETL udnytter en separat iscenesættelsesdatabase og anvender en række regler eller funktioner på de udpakkede data inden indlæsning.
Uddrag, belastning, transformation (ELT) er en anden tilgang til indlæsning af data. ELT tager dataene fra forskellige kilder og indlæser dem direkte i målsystemet, såsom datalageret. Systemet transformerer derefter de indlæste data on-demand for at muliggøre analyse.
ELT tilbyder hurtigere indlæsning end ETL, men det kræver et kraftfuldt system til at udføre datatransformationerne on-demand.
Enterprise Data lager
et enterprise data lager er beregnet som et samlet, centraliseret lager, der indeholder alle transaktionsoplysninger i organisationen, både nuværende og historiske. Et virksomhedsdatalager skal inkorporere data fra alle fagområder relateret til virksomheden, såsom marketing, salg, økonomi og menneskelige ressourcer.
dette er de centrale ideer, der udgør traditionelle datalagre. Lad os nu se på, hvilke cloud data-lagre der er tilføjet oven på dem.
Cloud Data lager koncepter
Cloud data lagre er nye og konstant skiftende. For bedst at forstå deres grundlæggende begreber er det bedst at lære om de førende cloud-datalagerløsninger.
tre førende cloud-datalagerløsninger er Google Bigforespørgsel og Panoply. Nedenfor forklarer vi grundlæggende begreber fra hver af disse tjenester for at give dig en generel forståelse af, hvordan moderne datalagre fungerer.
Cloud Data lager koncepter –
følgende begreber anvendes eksplicit i
klynger
noder
noder er computerressourcer, der har CPU, RAM og harddiskplads. En klynge, der indeholder to eller flere noder er sammensat af en leder node og beregne noder.
Leader noder kommunikerer med klientprogrammer og kompilerer kode for at udføre forespørgsler, tildele den til at beregne noder. Beregn noder Kør forespørgsler og returnere resultaterne til leder node. En compute node udfører kun forespørgsler, der refererer til tabeller, der er gemt på den node.
partitioner/skiver
Columnar Storage
Redshift bruger columnar storage, muliggør bedre analytisk forespørgsel ydeevne. I stedet for at gemme poster i rækker gemmer den værdier fra en enkelt kolonne for flere rækker. Følgende diagrammer gør dette klarere:
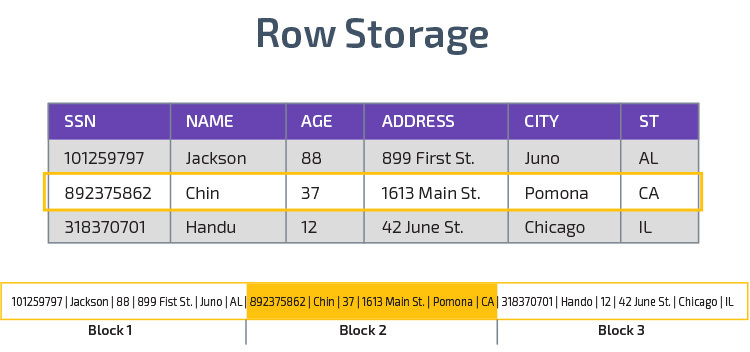
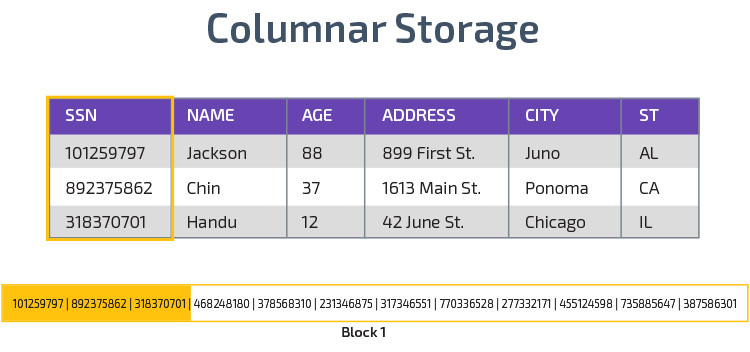
Kolonnelagring gør det muligt at læse data hurtigere, hvilket er afgørende for analytiske forespørgsler, der spænder over mange kolonner i et datasæt. Kolonnelagring tager også mindre diskplads, fordi hver blok indeholder den samme type data, hvilket betyder, at den kan komprimeres til et bestemt format.
komprimering
komprimering reducerer størrelsen på de lagrede data. I Redshift opstår komprimering på kolonneniveau på grund af den måde, data gemmes på. Redshift giver dig mulighed for at komprimere oplysninger manuelt, når du opretter en tabel eller automatisk ved hjælp af kommandoen Kopier.
indlæsning af Data
du kan bruge redshifts KOPIKOMMANDO til at indlæse store mængder data i datalageret. COPY-kommandoen udnytter redshifts MPP-arkitektur til at læse og indlæse data parallelt fra filer på
det er også muligt at streame data til Redshift ved hjælp af tjenesten.
Cloud Database lager – Google Storforespørgsel
følgende begreber bruges eksplicit i Google Storforespørgsel cloud data lager, men kan gælde for yderligere løsninger i fremtiden baseret på Google infrastruktur.
Serverløs Service
Storforespørgsel bruger serverløs arkitektur. Med Storforespørgsel behøver virksomheder ikke at administrere fysiske serverenheder for at køre deres datalager. I stedet styrer Bigforce dynamisk tildelingen af sine computerressourcer. Virksomheder, der bruger tjenesten, betaler simpelthen for datalagring pr.
Colossus filsystem
Storforespørgsel bruger den nyeste version af Googles distribuerede filsystem, kodenavnet Colossus. Colossus-filsystemet bruger kolonnelagrings-og komprimeringsalgoritmer til at gemme data til analytiske formål optimalt.
Dremel Eksekveringsmotor
Dremel eksekveringsmotor bruger et søjleformet layout til hurtigt at forespørge store datalagre. Dremels eksekveringsmotor kan køre ad hoc-forespørgsler på milliarder af rækker på få sekunder, fordi den bruger massivt parallel behandling i form af en træarkitektur.
træarkitekturen distribuerer forespørgsler mellem flere mellemliggende servere fra en rodserver. De mellemliggende servere skubber forespørgslen ned til leaf-servere (indeholdende lagrede data), som scanner dataene parallelt. På vej tilbage op i træet, hver leaf-server sender forespørgselsresultater, og de mellemliggende servere udfører en parallel sammenlægning af delvise resultater.
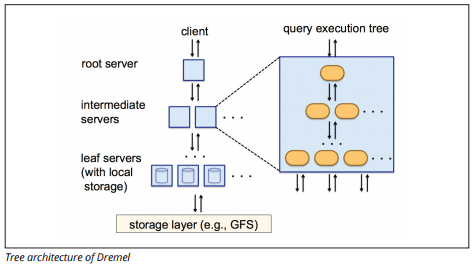
Billedkilde
Dremel gør det muligt for organisationer at køre forespørgsler på op til titusinder af servere samtidigt. Ifølge Google kan Dremel scanne 35 milliarder rækker uden et indeks på titusinder af sekunder.
datadeling
Googles serverløse arkitektur giver virksomheder mulighed for nemt at dele data med andre organisationer uden at kræve, at disse organisationer investerer i deres egen lagring.
organisationer, der ønsker at forespørge delte data, kan gøre det, og de betaler kun for forespørgslerne. Det er ikke nødvendigt at oprette dyre delte datasiloer uden for organisationens datainfrastruktur og kopiere dataene til disse siloer.
Streaming og Batchindtagelse
det er muligt at indlæse data til Storforespørgsel fra Google Cloud Storage, herunder CSV, JSON og Avro-filer samt Google Cloud Datastore-sikkerhedskopier. Du kan også indlæse data direkte fra en læsbar datakilde.
Bigforespørgsel tilbyder også en Streaming API til at indlæse data i systemet med en hastighed på millioner af rækker i sekundet uden at udføre en belastning. Dataene er tilgængelige til analyse næsten øjeblikkeligt.
cloud Data Lagerkoncepter – Panoply
Panoply er et alt-i-et-lager, der kombinerer ETL med et kraftfuldt datalager. Det er den nemmeste måde at synkronisere, gemme og få adgang til en virksomheds data ved at eliminere udviklingen og kodningen i forbindelse med transformation, integration og styring af big data.
nedenfor er nogle af de vigtigste begreber i Panoply datalager relateret til datamodellering og databeskyttelse.
primære nøgler
primære nøgler sørg for, at alle rækker i tabellerne er unikke. Hver tabel har en eller flere primære nøgler, der definerer, hvad der repræsenterer en enkelt unik række i databasen. Alle API ‘ er har en primær standardnøgle til tabeller.
inkrementelle nøgler
Panoply bruger en inkrementel nøgle til at styre attributter til trinvis indlæsning af data til datalageret fra kilder i stedet for at genindlæse hele datasættet hver gang noget ændres. Denne funktion er nyttig til større datasæt, hvilket kan tage lang tid at læse for det meste uændrede data. Den trinvise nøgle angiver det sidste opdateringspunkt for rækkerne i den pågældende datakilde.
indlejrede Data
indlejrede data er ikke fuldt kompatible med BI—suiter og standard forespørgsler-Panoply beskæftiger sig med indlejrede data ved hjælp af en stærkt relationel model, der ikke tillader indlejrede værdier. Panoply transformerer indlejrede data på disse måder:
- Undertabeller: som standard omdanner Panoply indlejrede data til et sæt mange-til-mange eller en-til-mange relationstabeller, som er flade relationstabeller.
- fladning: når denne tilstand er aktiveret, flader Panoply den indlejrede struktur på den post, der indeholder den.
Historiktabeller
nogle gange skal du analysere data ved at holde styr på at ændre data over tid for at se nøjagtigt, hvordan dataene ændres (for eksempel folks adresser).
for at udføre sådanne analyser bruger Panoply Historiktabeller, som er tidsserietabeller, der indeholder historiske snapshots af hver række i den oprindelige statiske tabel. Du kan derefter udføre enkel forespørgsel af den oprindelige tabel eller revisioner af tabellen ved at spole tilbage til ethvert tidspunkt.
transformationer
Panoply bruger ELT, som er en variation på den oprindelige ETL-dataintegrationsproces. Når du har injiceret data fra kilden til dit datalager, forvandler Panoply det straks. Denne proces giver dig dataanalyse i realtid og optimal ydelse sammenlignet med standard ETL-processen.
Strengformater
Panoply analyserer strengformater og håndterer dem som om de var indlejrede objekter i de originale data. Understøttede strengformater er CSV, TSV, JSON, JSON-Line, Ruby object format, URL forespørgselsstrenge og distributionslogfiler.
databeskyttelse
Panoply er bygget oven på Av, så det har de nyeste sikkerhedsrettelser og krypteringsfunktioner, der leveres af AV, herunder maskinaccelereret RSA-kryptering og redshifts specifikke sæt sikkerhedsfunktioner.
ekstra beskyttelse kommer fra kolonnekryptering, som giver dig mulighed for at bruge dine private nøgler, der ikke er gemt på Panoplys servere.
adgangskontrol
Panoply bruger totrinsbekræftelse til at forhindre uautoriseret adgang, og et tilladelsessystem giver dig mulighed for at begrænse adgangen til bestemte tabeller, visninger eller kolonner. Anomali detection identificerer forespørgsler fra nye computere eller et andet land, så du kan blokere disse forespørgsler, medmindre de modtager manuel godkendelse.
IP-hvidliste
vi anbefaler, at du blokerer forbindelser fra ukendte kilder ved hjælp af en sikkerhedsgruppe og hvidlister det interval af IP-adresser, som Panoplys datakilder altid bruger, når du får adgang til din database.
konklusion: traditionelle kontra Datalagerkoncepter i korte træk
for at afslutte opsummerer vi de begreber, der er introduceret i dette dokument.
traditionelle Datalagerkoncepter
- fakta og foranstaltninger: en foranstaltning er en egenskab, som beregninger kan foretages på. Vi henviser til en samling af foranstaltninger som fakta, men nogle gange bruges udtrykkene om hverandre.
- normalisering: processen med at reducere mængden af duplikatdata, hvilket fører til et mere hukommelseseffektivt datalager, der er langsommere at forespørge.
- Dimension: bruges til at kategorisere og kontekstualisere fakta og foranstaltninger, hvilket muliggør analyse af og rapportering om disse foranstaltninger.
- konceptuel datamodel: definerer de kritiske dataenheder på højt niveau og forholdet mellem dem.
- logisk datamodel: Beskriver datarelationer, enheder og attributter på almindeligt engelsk uden at bekymre sig om, hvordan man implementerer det i kode.
- fysisk datamodel: en repræsentation af, hvordan man implementerer datadesignet i et specifikt databasestyringssystem.
- Stjerneskema: tager en faktatabel og opdeler dens information i denormaliserede dimensionstabeller.
- snefnugskema: opdeler faktatabellen i normaliserede dimensionstabeller. Normalisering reducerer problemer med dataredundans og forbedrer dataintegriteten, men forespørgsler er mere komplekse.
- OLTP: Online transaktionsbehandlingssystemer letter hurtig, transaktionsorienteret behandling med enkle forespørgsler.
- OLAP: online analytisk behandling giver dig mulighed for at køre komplekse læseforespørgsler og dermed udføre en detaljeret analyse af historiske transaktionsdata.
- Data mart: et arkiv med data med fokus på et bestemt emne eller afdeling i en organisation.
- Inmon-tilgang: Bill Inmons datalagertilgang definerer datalageret som det centraliserede datalager for hele virksomheden. Datamarts kan bygges fra datalageret for at imødekomme de forskellige afdelingers analytiske behov.
- Kimball tilgang: Ralph Kimball beskriver et datalager som sammenlægning af missionskritiske datamarts, som først oprettes for at imødekomme de forskellige afdelingers analytiske behov.
- ETL: integrerer data i datalageret ved at udtrække dem fra forskellige transaktionskilder, omdanne dataene for at optimere dem til analyse og endelig indlæse dem i datalageret.
- ELT: En variation på ETL, der udtrækker rådata fra en organisations datakilder og indlæser dem i datalageret. Når det er nødvendigt, transformeres det til analytiske formål.
- Enterprise Data lager: EDV konsoliderer data fra alle fagområder relateret til virksomheden.
cloud Data Lagerkoncepter som eksempel
- Cluster: en gruppe af delte computerressourcer baseret i skyen.
- Node: en computerressource indeholdt i en klynge. Hver node har sin egen CPU, RAM og plads på harddisken.
- Søjlelager: Dette lagrer værdierne for en tabel i kolonner i stedet for rækker, hvilket optimerer dataene for aggregerede forespørgsler.
- komprimering: teknikker til at reducere størrelsen af lagrede data.
- indlæsning af Data: Hent data fra kilder til det skybaserede datalager. I Redshift kan du bruge kommandoen Kopier eller en datastreamingtjeneste.
Cloud Data Lagerkoncepter – Storforespørgsel som eksempel
- Serverløs service: skyudbyderen styrer dynamisk tildelingen af maskinressourcer baseret på det beløb, brugeren bruger. Cloud-udbyderen skjuler beslutninger om serverstyring og kapacitetsplanlægning fra brugerne af tjenesten.
- Colossus file system: et distribueret filsystem, der bruger kolonnelagring og datakomprimeringsalgoritmer til at optimere data til analyse.
- Dremel-eksekveringsmotor: en forespørgselsmotor, der bruger massivt parallel behandling og søjlelagring til hurtigt at udføre forespørgsler.
- datadeling: i en serverløs tjeneste er det praktisk at forespørge en anden organisations delte data uden at investere i datalagring—du betaler simpelthen for forespørgslerne.
- Streaming af data: indsættelse af data i realtid i datalageret uden at udføre en belastning. Du kan streame data i batchanmodninger, som er flere API-opkald kombineret til en HTTP-anmodning.
traditionel vs. Cloud Cost-Benefit-analyse
| Cost / Benefit | traditionel | Sky |
| omkostninger | store upfront omkostninger til at købe og installere en on-prem-system. du har brug for udstyr, serverrum og specialpersonale (som du betaler løbende). hvis du er usikker på, hvor meget lagerplads du har brug for, er der risiko for høje sunkne omkostninger, der er svære at inddrive. |
ingen grund til at købe udstyr, serverrum eller ansætte specialister. ingen risiko for sunkne omkostninger – det er nemt at købe mere lagerplads i fremtiden. plus, omkostningerne ved opbevaring og computerkraft er faldende over tid. |
| skalerbarhed | når du har maksimeret dine nuværende serverrum eller udstyrskapacitet, skal du muligvis købe nyt udstyr og bygge/købe flere steder for at huse det. Plus, du skal købe nok lagerplads til at klare spidsbelastningstider; således bruges det meste af din lagerplads ikke. |
du kan nemt købe mere lagerplads, når og når du har brug for det. ofte skal du bare betale for det, du bruger, så der er ringe eller ingen risiko for overbetaling. |
| integrationer | da cloud computing er normen, vil de fleste integrationer, du vil lave, være til cloud-tjenester. tilslutning af dit brugerdefinerede datalager til dem kan vise sig udfordrende. |
da cloud-datalagre allerede findes i skyen, er det nemt at oprette forbindelse til en række andre cloud-tjenester. |
| sikkerhed | du har total kontrol over dit datalager. når du sammenligner mængden af data, du huser til Google, er du et mindre mål for tyve. Så, du kan være mere tilbøjelige til at være alene. |
cloud-datalagerudbydere har hold fulde af højt kvalificerede sikkerhedsingeniører, hvis eneste formål er at gøre deres produkt så sikkert som muligt. de mest fremtrædende virksomheder i verden administrerer dem og implementerer derfor sikkerhedspraksis i verdensklasse. |
| Governance | du ved præcis, hvor dine data er, og kan få adgang til dem lokalt. mindre risiko for, at meget følsomme data utilsigtet bryder loven ved for eksempel at rejse over hele verden på en cloud-server. |
de øverste udbydere af cloud-datalager sikrer, at de overholder governance-og sikkerhedslove, såsom GDPR. Plus, de hjælper din virksomhed med at sikre, at du overholder kravene. der har været problemer med at vide nøjagtigt, hvor dine data er, og hvor de bevæger sig. Disse problemer bliver aktivt behandlet og løst. bemærk, at lagring af store mængder af meget følsomme data på skyen kan være imod specifikke love. Dette er et tilfælde, hvor cloud computing kan være upassende for din virksomhed. |
| pålidelighed | hvis dit on-prem datalager fejler, er det dit ansvar at ordne det. dit IT-team har adgang til det fysiske udstyr og kan få adgang til alle programlag til fejlfinding. Denne hurtige adgang kan gøre løsning af problemer meget hurtigere. der er dog ingen garanti for, at dit lager vil have en bestemt oppetid hvert år. |
udbydere af Cloud-datalager garanterer deres pålidelighed og oppetid i deres SLA ‘ er. de opererer på massivt distribuerede systemer over hele verden, så hvis der er en fejl på en, er det meget usandsynligt at påvirke dig. |
| kontrol | dit datalager er specialbygget, så det passer til dine behov. I teorien gør det, hvad du vil have det til at gøre, når du vil have det, på en måde, du forstår. | du har ikke total kontrol over dit datalager. men størstedelen af tiden er den kontrol, du har, mere end nok. |
| hastighed | hvis du er en lille virksomhed på et geografisk sted med en lille mængde data, bliver din databehandling hurtigere. men vi taler millisekunder vs. sekunder for nogle processer at fuldføre. et stort firma, der opererer i flere lande, vil sandsynligvis ikke se betydelige hastighedsgevinster med et on-prem-system. |
Cloud-udbydere har investeret i og skabt systemer, der implementerer Massively Parallel Processing (MPP), specialbyggede arkitektur-og eksekveringsmotorer og intelligente databehandlingsalgoritmer. Cloud data lagre er resultatet af mange års forskning og test for at skabe ressourcer optimeret til hastighed og ydeevne. det kan være lidt langsommere end on-prem i nogle tilfælde, men disse forsinkelser er ofte ubetydelige for mennesker (sekunder vs. millisekunder). |
Panoply er et sikkert sted at gemme, synkronisere og få adgang til alle dine forretningsdata. Panoply kan konfigureres på få minutter, kræver nul løbende vedligeholdelse og giver online support, herunder adgang til erfarne dataarkitekter. Prøv Panoply gratis i 14 dage.
Lær mere om datalager
- Datalagerarkitektur: traditionel vs. Sky
- Database vs. datalager
- Data Mart vs. datalager