Clustering og K betyder: Definition og klyngeanalyse
statistik definitioner > klyngedannelse / klyngeanalyse
Hvad er klyngedannelse?
klyngedannelse i statistik refererer til, hvordan data indsamles (“grupperet”) af faktorer som:
- alder.
- husstand størrelse.
- indkomst.
- eller uddannelsesniveau.
sortering af data i klynger fører undertiden til mere undersøgelse af dataene. For eksempel kan kræftklynger indikere noget problem i miljøet. Eller de kan bare være et resultat af, at naturen er tilfældig. Klyngeanalyse har tendens til at være subjektiv i mange tilfælde; Det afhænger af, hvad du opfatter som almindelige tråde i dataene. Teknikken er ikke rigtig noget nyt i statistikken; hvis du nogensinde har lavet en søjlediagram, har du sikkert allerede lavet klynger (selvom du ikke kaldte det det). For eksempel kræver en søjlediagram, der viser hunderacer, at du klynger dig efter race (Siberian Husky, Border Collie, German Shepherd…), eller et diagram over indkomstniveauer kan være grupperet af lave, mellemste og høje indkomstniveauer.
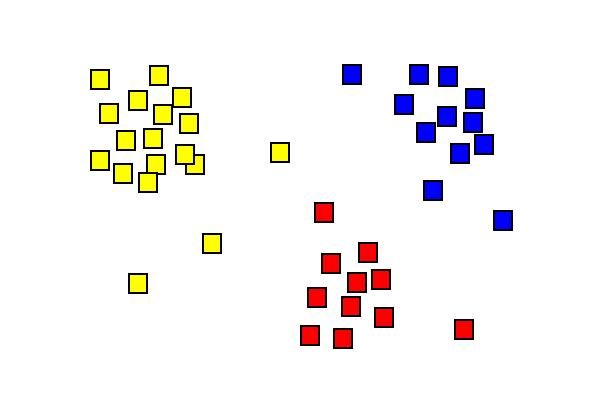
Klyngeanalyseresultater, der viser tre forskellige farvede klynger.
klynger kan baseres på faktorer som:
- Afstandsbaseret klyngedannelse. Elementer sorteres ud fra deres nærhed (eller afstand). For eksempel kan kræfttilfælde være grupperet sammen, hvis de er i samme geografiske placering.
- konceptuel klyngedannelse. Elementer er grupperet efter faktorer, som elementer har til fælles. For eksempel kunne kræftklynger grupperes af “mennesker, der arbejder inden for fremstilling.”
Clustering Typer
- Eksklusiv Clustering. Hvert element kan kun høre hjemme i en enkelt klynge. Det kan ikke høre hjemme i en anden klynge.
- uklar klyngedannelse: datapunkter tildeles en sandsynlighed for at tilhøre en eller flere klynger.
- Overlappende Klyngedannelse. Hvert element kan tilhøre mere end en klynge.
- Hierarkisk Klyngedannelse. Dette er en mere kompleks tilgang til klyngedannelse, der anvendes i data mining. Dybest set får hver vare sin egen klynge. Et par klynger er forbundet baseret på ligheder, hvilket giver en mindre klynge. Denne proces gentages, indtil alle elementer er grupperet. Dendrogrammet er en graf, der viser hierarkiske klynger.
- Probabilistisk Klyngedannelse. Data grupperes ved hjælp af algoritmer, der forbinder elementer ved hjælp af afstande eller tætheder. Dette udføres normalt af en computer.
- Menighedens metode: bruger minimum varians i hvert trin til at skabe relativt små, lige store klynger.
K betyder Clustering
Clustering er bare en måde at gruppere et sæt data i mindre sæt. De to måder, du kan gruppere et sæt data på, er kvantitativt (ved hjælp af tal) og kvalitativt (ved hjælp af kategorier). For eksempel bøger om Amazon.com er opført både efter kategori (kvalitativ) og efter bestseller (kvantitativ). K-betyder clustering er en af de enkleste uovervåget læring algoritmer, der løser clustering problemer ved hjælp af en kvantitativ metode: du pre-definere en række klynger og anvende en simpel algoritme til at sortere dine data. Når det er sagt, svarer “simpelt” i computerverdenen ikke til simpelt i det virkelige liv. Dette er faktisk et NP-hårdt problem, så du vil gerne bruge programmer til K-betyder clustering. Nogle programmer, der udfører dette for dig (klik på linket til proceduren) er:
- SPSS.
- r
- MATLAB
de generelle trin bag k-midler clustering algoritme er:
- Bestem, hvor mange klynger (k).
- Placer k centrale punkter forskellige steder (normalt langt fra hinanden).
- Tag hvert datapunkt og placer det tæt på det relevante centrale punkt. Gentag, indtil alle datapunkter er tildelt.
- Genberegn k nye centrale punkter som barycentre.
- gentag tildelingen af datapunkter, denne gang til det nye centrale punkt (barycenteret).
- gentag 4 og 5, indtil de centrale punkter (barycentre) ikke bevæger sig mere.
K-betyder klyngedannelse: en mere formel Definition
en mere formel måde at definere K-betyder klyngedannelse er at kategorisere n objekter i k(k > 1) foruddefinerede grupper. Målet er at minimere afstanden fra hvert datapunkt til klyngen. Med andre ord at finde:
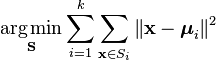
hvor:
K er et datapunkt
k er antallet af klynger
ui er gennemsnittet af punkterne i Si.
klyngeanalyse vs. Diskriminantanalyse
klyngeanalyse ligner meget diskriminantanalyse. Begge metoder indebærer adskillelse i grupper. Klyngeanalyse er dog en måde at identificere grupperne på, mens diskriminerende analyse kræver, at du kender grupperne, før du begynder analysen. Lad os for eksempel sige, at du havde en gruppe psykiatriske patienter med unormal adfærd. Klyngeanalyse kan hjælpe dig med at finde forskellige grupper, som patienter med en historie med misbrug, dem med PTSD eller dem, der oplever hallucinationer. Hvis du skulle køre diskriminerende analyse på den samme gruppe af mennesker, skal du kende patienternes diagnoser, før du begynder at placere dem i grupper.
klyngedannelse
Microsoft har et tilføjelsesprogram til data mining til at lave klynger. Du kan finde instruktioner her. Guiden arbejder med f.eks. tabeller, intervaller eller Analyseundersøgelsesforespørgsler. Denne tilføjelse kan tilpasses, i modsætning til værktøjet registrer kategorier. Derudover er værktøjet registrer kategorier begrænset til data fra tabeller.
at bruge:
- Hent og Installer tilføjelsesprogrammet Data Mining.
- Klik på “Data Mining”, klik derefter på “Cluster” og derefter “Næste.”
- fortæl os, hvor dine data er. Vælg f.eks. en række data. Klyngesiden bliver tilgængelig.
- Clustering: forlad som for automatisk gruppering, eller du kan angive et antal grupper.
- segmenter: forlad som det er for automatisk gruppering, eller angiv et antal kategorier.
Stephanie Glen. “Clustering og K betyder: Definition & klyngeanalyse i udmærke sig” fra StatisticsHowTo.com: Grundlæggende statistik for resten af os! https://www.statisticshowto.com/clustering/
——————————————————————————
brug for hjælp til et hjemmearbejde eller test spørgsmål? Med Chegg Study kan du få trinvise løsninger på dine spørgsmål fra en ekspert på området. Dine første 30 minutter med en Chegg tutor er gratis!