fælles søgning: open source-projektet bringer PageRank tilbage
Tilmeld dig vores daglige resumeer af det stadigt skiftende søgemarkedsføringslandskab.
Bemærk: ved at indsende denne formular accepterer du Third Door Medias vilkår. Vi respekterer dit privatliv.

i løbet af de sidste mange år har Google langsomt reduceret mængden af data, der er tilgængelige for SEO-udøvere. Først var det søgeord data, så PageRank score. Nu er det specifikt søgevolumen fra Google Ads (medmindre du bruger noget moola). Du kan læse mere om dette i Russ Jones fremragende artikel, der beskriver virkningen af hans virksomheds forskning og indsigt i clickstream-data for volumendisambiguation.
et element, som vi har fået virkelig involveret i for nylig er fælles kravle data. Der er flere hold i vores branche, der har brugt disse data i nogen tid, så jeg følte mig lidt sent til spillet. Fælles Gennemsøgningsdata er et open source-projekt, der skraber hele internettet med jævne mellemrum. Heldigvis, da det er det store firma, det er, slog ind for at gemme dataene for at gøre dem tilgængelige for mange uden de høje lageromkostninger.
ud over almindelige Gennemsøgningsdata er der en non-profit kaldet Common Search, hvis mission er at skabe en alternativ open source og gennemsigtig søgemaskine — det modsatte i mange henseender af Google. Dette vakte min interesse, fordi det betyder, at vi alle kan spille, finjustere og mangle signalerne for at lære, hvordan søgemaskiner fungerer uden den enorme tidsinvestering ved at starte fra jorden nul.
almindelige søgedata
i øjeblikket bruger Common Search følgende datakilder til beregning af deres søgeplacering (dette er taget direkte fra deres hjemmeside):
- almindelig gennemgang: det største åbne lager af internetgennemsøgningsdata. Dette er i øjeblikket vores unikke kilde til rå sidedata.
- : En gratis, sammenkædet database, der fungerer som central lagring af strukturerede data fra mange projekter som f.eks.
- UT1 sortliste: vedligeholdt af Fabrice Prigent fra Universit Christ Toulouse 1 Capitole, kategoriserer denne sortliste domæner og URL ‘ er i flere kategorier, herunder “voksen” og “phishing.”
- DMOSE: også kendt som Open Directory-projektet, er det den ældste og største internetkatalog, der stadig er i live. Selvom dens data ikke er så pålidelige som tidligere, bruger vi dem stadig som en signal-og metadatakilde.
- data Commons Hyperlink grafer: grafer over alle hyperlinks fra et 2012 fælles Gennemsøgningsarkiv. Vi bruger i øjeblikket sin harmoniske Centralitetsfil som et midlertidigt rangeringssignal på domæner. Vi planlægger at udføre vores egen analyse af netgrafen i den nærmeste fremtid.
- Aleksa top 1m sites: Aleksa rangerer hjemmesider baseret på en kombineret måling af sidevisninger og unikke site brugere. Det er kendt for at være demografisk forudindtaget. Vi bruger det som et midlertidigt ranking signal på domæner.
Common Search ranking
ud over disse datakilder bruger den også URL-længde, stilængde og domæne PageRank som rangeringssignaler i sin algoritme. Se og se, siden juli, Common Search har haft sine egne data på PageRank på værtsniveau, og vi gik alle glip af det.
jeg kommer til PageRank (PR) om et øjeblik, men det er interessant at gennemgå koden for almindelig gennemgang, især ranker.Py del placeret her, fordi du virkelig kan komme ind i førersædet med at tilpasse vægten af de signaler, den bruger til at rangere siderne:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
af særlig note er det også, at almindelig søgning bruger BM25 som lighedsmål for nøgleord til at dokumentere krops-og metadata. BM25 er et bedre mål end TF-IDF, fordi det tager højde for dokumentlængde, hvilket betyder, at et dokument på 200 ord, der har dit søgeord fem gange, sandsynligvis er mere relevant end et dokument på 1.500 ord, der har det samme antal gange.
det er også værd at sige, at antallet af signaler her er meget rudimentært og åbenbart mangler mange af de forbedringer (og data), som Google har integreret i deres søgerangeringsalgoritme. En af de vigtigste ting, vi arbejder på, er at bruge de tilgængelige data til fælles gennemgang og infrastrukturen til fælles søgning til at udføre emnevektorsøgning efter indhold, der er relevant baseret på semantik, ikke kun søgeordsmatchning.
videre til PageRank
på siden her kan du finde links til host-level PageRank for Juni 2016 fælles gennemgang. Jeg bruger den med titlen pagerank-top1m.txt.1 million), fordi den anden fil er 3 GB og over 112 millioner domæner. Selv i R har jeg ikke nok maskine til at indlæse den uden at lukke ud.
når du har hentet, skal du bringe filen ind i din arbejdsmappe i R. PageRank-dataene fra Common Search er ikke normaliseret og er heller ikke i det rene 0-10-format, som vi alle er vant til at se det i. Almindelig søgning bruger ” maks(0, min(1, flyde (rang) / 244660.58))” — dybest set et domænes rang divideret med Facebook ‘ s rang — som metoden til at oversætte dataene til en fordeling mellem 0 og 1. Men dette efterlader nogle klare huller, idet dette ville forlade Linkedin ‘ s PageRank som en 1.4, når den skaleres med 10.

følgende kode indlæser datasættet og tilføjer en pr-kolonne med en bedre tilnærmet PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
vi var nødt til at lege lidt med tallene for at få det et sted tæt (for flere eksempler på domæner, som jeg huskede PR for) til den gamle Google PR. Nedenfor er et par eksempel PageRank resultater:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
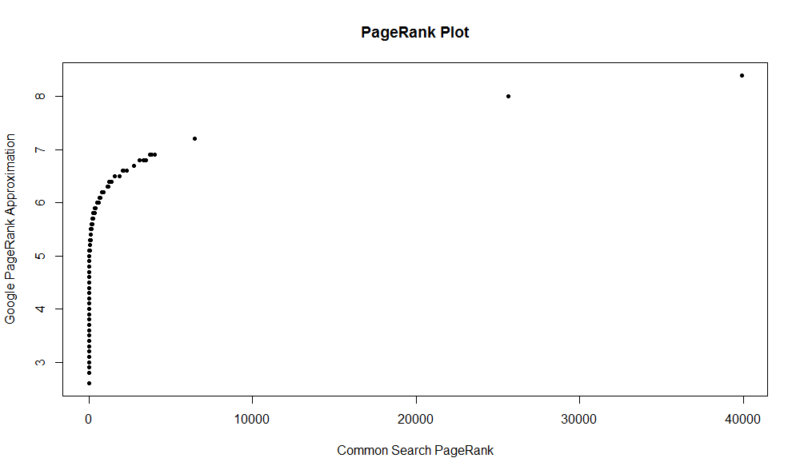
her er et plot af 100.000 tilfældige prøver. Den beregnede PageRank score er langs Y-aksen, og den oprindelige fælles søgning score er langs h-aksen.
for at få fat i dine egne resultater kan du køre følgende kommando i R (bare erstatte dit eget domæne):
df

Husk, at dette datasæt kun har de øverste en million domæner af PageRank, så ud af 112 millioner domæner, der er indekseret med almindelig søgning, er der en god chance for, at dit sted muligvis ikke er der, hvis det ikke har en ret god linkprofil. Også, denne metric indeholder ingen indikation af skadeligheden af links, kun en tilnærmelse af din hjemmeside popularitet med hensyn til links.
fælles søgning er et fantastisk værktøj og et godt fundament. Jeg ser frem til at blive mere involveret i samfundet der og forhåbentlig lære at forstå møtrikkerne og boltene bag søgemaskinerne bedre ved faktisk at arbejde på en. Med R og en lille kode kan du få en hurtig måde at kontrollere PR for en million domæner på få sekunder. Håber du nød!
Tilmeld dig vores daglige resumeer af det stadigt skiftende søgemarkedsføringslandskab.
Bemærk: ved at indsende denne formular accepterer du Third Door Medias vilkår. Vi respekterer dit privatliv.
om forfatteren

JR Oakes er senior direktør for teknisk SEO forskning på Lokomotiv. Han var tidligere direktør for teknisk SEO hos Adapt Partners agency. Han arbejder med klienter på en lang række fronter, herunder tekniske problemer, ydeevne, CTR, gennemsøgningsevne, indhold og dataanalyse. JR elsker test, kodning og prototypeløsninger til vanskelige søgemarkedsføringsproblemer. Når han ikke arbejder, han nyder at læse om nye teknologier, spiller basguitar, ser college basketball, madlavning og tilbringe tid sammen med sine venner og familie. Han er også en af medarrangørerne af Raleigh SEO Meetup, Raleigh SEO Conference, og RTP SEO Meetup.