skalerbar, distribueret sekundær indeksering i Scylla

datamodellen i Scylla og Apache Cassandra partitioner data mellem klyngenoder ved hjælp af en partitionsnøgle, som er defineret af databaseskemaet. Brug af en partitionstast giver en effektiv måde at slå rækker op ved hjælp af partitionstasten, fordi du kan finde den knude, der ejer rækken, ved at hashing partitionstasten. Desværre betyder det også, at det at finde en række ved hjælp af en ikke-partitionsnøgle kræver en fuld tabelscanning, som er ineffektiv. Sekundære indekser er en mekanisme i Apache Cassandra, der tillader effektive søgninger på ikke-partitionstaster ved at oprette et indeks.
i dette blogindlæg vil du lære:
- hvordan Apache Cassandra implementerer sekundære indekser ved hjælp af lokal indeksering
- hvorfor vi besluttede at tage en anden implementeringsstrategi for Scylla ved hjælp af global indeksering
- hvordan global indeksering påvirker, hvordan du skal bruge sekundær indeksering
- Sådan opretter du dine egne sekundære indekser og bruger dem i din ansøgning
baggrund
størrelsen af et indeks er proportional med størrelsen af de indekserede data. Da data i Scylla og Apache Cassandra distribueres til flere noder, er det upraktisk at gemme hele indekset på en enkelt node. Apache Cassandra implementerer sekundære indekser som lokale indekser, hvilket betyder, at indekset er gemt på den samme node som de data, der indekseres fra den node. Fordelen ved et lokalt indeks er, at skrivninger er meget hurtige, men ulempen er, at læsninger potentielt skal forespørge hver node for at finde indekset til at udføre et opslag på, hvilket gør lokale indekser ikke skalerbare for store klynger. Ud over de oprindelige sekundære indekser har Apache Cassandra også et andet lokalt indekseringsskema, SSTable Attached Secondary indeks (SASI), som understøtter komplekse forespørgsler og søgning. Fra et skalerbart synspunkt har det imidlertid nøjagtigt de samme egenskaber som de originale sekundære indekser.
materialiserede visninger i Scylla og Apache Cassandra er en mekanisme til automatisk at denormalisere data fra en basistabel til en visningstabel ved hjælp af en anden partitionstast. Dette løser skalerbarhedsproblemet med lokale indekser, men har en lageromkostning, fordi du i værste fald skal duplikere hele tabellen. Materialiserede synspunkter er derfor ikke en erstatning for sekundære indekser for alle brugssager. Imidlertid giver materialiserede synspunkter den nødvendige infrastruktur til implementering af sekundære indekser ved hjælp af global indeksering, hvilket er implementeringsmetoden for Scylla.
Global indeksering
Scylla tager en anden tilgang end Apache Cassandra og implementerer sekundære indekser ved hjælp af global indeksering. Med global indeksering oprettes en materialiseret visning for hvert indeks. Den materialiserede visning har den indekserede kolonne som partitionstast og primær nøgle (partitionstast og klyngetaster) i den indekserede række som klyngetaster. Scylla opdeler indekserede forespørgsler i to dele: (1) en forespørgsel på indekstabellen for at hente partitionstaster til den indekserede tabel og (2) en forespørgsel til den indekserede tabel ved hjælp af de hentede partitionstaster. Fordelen ved denne tilgang er, at vi kan bruge værdien af den indekserede kolonne til at finde den tilsvarende indekstabelrække i klyngen, så læsninger er skalerbare. Ulempen ved fremgangsmåden er, at skrivninger er langsommere end med lokal indeksering på grund af al overhead fra at holde indeksvisningen opdateret.
forespørgsel på en indekseret kolonne ser ud som følger. Lad os antage et bord, der ser sådan ud:
og en forespørgsel på kolonnen
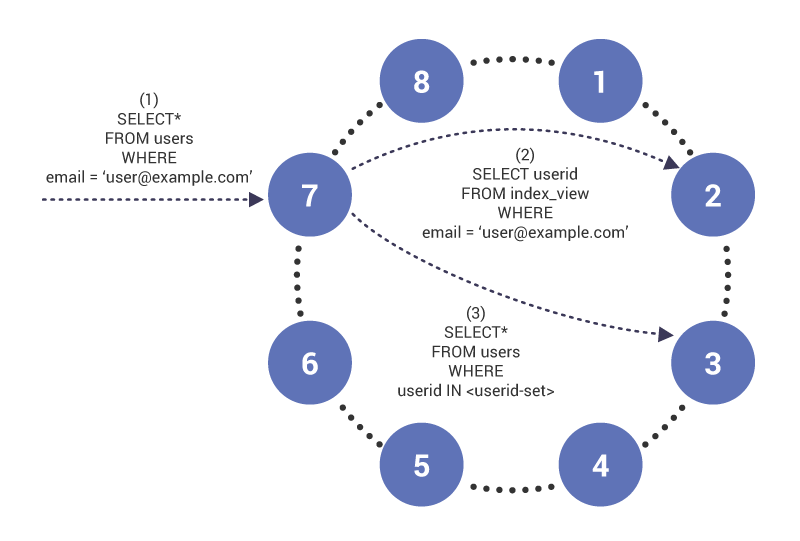
email, som ikke er en partitionsnøgle, men har et indeks:i fase (1) ankommer forespørgslen på node 7, som fungerer som koordinator for forespørgslen. Noden bemærker, at vi spørger på en indekseret kolonne og derfor i fase (2) udsteder en læsning til indekstabel på node 2, som har indekstabelrækken for “”. Forespørgslen returnerer et sæt bruger-id ‘ er, der bruges i fase (3) til at hente indholdet i den indekserede tabel.
eksempel
vi skal først oprette et skema. I dette eksempel har vi en tabel, der repræsenterer brugeroplysninger med userid som partitionsnøgle og Navn, e-mail og land som almindelige kolonner:
vi udfylder derefter tabellen med nogle testdata genereret med Mockaroo:
sekundære indekser er designet til at muliggøre effektiv forespørgsel af ikke-partitionsnøglekolonner. Mens Apache Cassandra også understøtter forespørgsler på ikke-partitionsnøglekolonner ved hjælp af
ALLOW FILTERING, er det meget ineffektivt (kræver scanning af hele tabellen) og understøttes i øjeblikket ikke af Scylla (se nummer #2200 for detaljer).du kan indeksere tabelkolonner ved hjælp af sætningen Opret indeks. Hvis du f. eks. vil oprette indekser for e-mail-og landekolonner, skal du udføre følgende:
Scylla opretter automatisk en materialiseret visning, der har den indekserede kolonne som partitionstast og måltabel primær nøgle (partitionstast og klyngetast) som klyngetast.
for eksempel ser den materialiserede visning for indekset i kolonnen
emailud som følger:hvis ovenstående visning ville blive oprettet som en almindelig tabel, ville den effektivt se ud som følger:
kolonnen
emailbruges som partitionstast for indekstabellen, oguserider inkluderet som en klyngetast, som giver os mulighed for effektivt at finde partitionstaster til måltabellen ved hjælp af bareemail.du kan bruge kommandoen
DESCRIBEtil at se hele skemaet for tabellenks.users, inklusive oprettede indekser og visninger:nu med det sekundære indeks på plads kan du forespørge indekserede kolonner, som om de var partitionstaster:
vi er færdige med eksemplet!
Hvornår skal du bruge sekundære indekser?
sekundære indekser er (for det meste) gennemsigtige for applikationen. Forespørgsler har adgang til alle kolonnerne i tabellen, og du kan tilføje og fjerne indekser uden at ændre applikationen. Sekundære indekser kan også have mindre lagringsomkostninger end materialiserede visninger, fordi sekundære indekser kun behøver at duplikere den indekserede kolonne og den primære nøgle, ikke de forespurgte kolonner som med en materialiseret visning. Af samme grund kan opdateringer desuden være mere effektive med sekundære indekser, fordi kun ændringer i den primære nøgle og den indekserede kolonne forårsager en opdatering i indeksvisningen. I tilfælde af en materialiseret visning kræver en opdatering til en af de kolonner, der vises i visningen, at backingvisningen opdateres.
som altid afhænger beslutningen om at bruge sekundære indekser eller materialiserede visninger virkelig af kravene i din ansøgning. Hvis du har brug for maksimal ydelse og sandsynligvis vil forespørge på et bestemt sæt kolonner, skal du bruge materialiserede visninger. Men hvis applikationen skal forespørge forskellige sæt kolonner, er sekundære indekser et bedre valg, fordi de kan tilføjes og fjernes med mindre lageromkostninger afhængigt af applikationsbehov.
vil du lære mere om sekundære indekser? Tjek min præsentation fra Scylla Summit 2017 på SlideShare. Hvis du vil prøve denne funktion, forventes den at være i den kommende Scylla 2.2-udgivelse.