udvikling af klyngeplanlægningssystem
Kubernetes er blevet de facto standard inden for containerorkestrering. Alle applikationer vil blive udviklet og kørt på Kubernetes i fremtiden. Formålet med denne artikelserie er at introducere de underliggende implementeringsprincipper for Kubernetes på en dybtgående og enkel måde.
Kubernetes er et klyngeplanlægningssystem. Denne artikel introducerer hovedsageligt nogle tidligere klyngeplanlægningssystem arkitektur af Kubernetes. Ved at analysere deres designideer og arkitekturegenskaberne kan vi studere udviklingsprocessen for klyngeplanlægningssystem arkitektur og det største problem, der skal overvejes i arkitekturdesignet. Det vil være meget nyttigt at forstå Kubernetes arkitektur.
vi er nødt til at forstå nogle af de grundlæggende begreber i klyngeplanlægningssystemet, for at gøre det klart, vil jeg forklare konceptet gennem et eksempel, lad os antage, at vi ønsker at implementere en distribueret Cron. Systemet administrerer et sæt af værter. Brugeren definerer jobbet gennem API ‘ en, der leveres af systemet. systemet udfører med jævne mellemrum den tilsvarende opgave baseret på opgavedefinitionen, i dette eksempel er de grundlæggende begreber nedenfor:
- Cluster: de hosts, der administreres af dette system, danner en ressourcepulje til at køre opgaver. Denne ressource pulje kaldes klynge.
- Job: det definerer, hvordan klyngen udfører sine opgaver. I dette eksempel er Crontab nøjagtigt et simpelt Job, der tydeligt viser, hvad der skal gøres (eksekveringsskript) på hvilket tidspunkt(tidsinterval).Definitionen af nogle job er mere kompleks, såsom definitionen af et job, der skal udføres i flere opgaver, og afhængighederne mellem opgaver samt ressourcekravene for hver opgave.
- opgave: et job skal planlægges i specifikke præstationsopgaver. Hvis vi definerer et job til at udføre et script klokken 1 hver aften, er scriptprocessen, der udføres klokken 1 hver dag, en opgave.
ved design af klyngeplanlægningssystemet er systemets kerneopgaver to:
- Opgaveplanlægning: Når opgaverne er sendt til klyngeplanlægningssystemet, skal de indsendte job opdeles i specifikke eksekveringsopgaver, og eksekveringsresultaterne af opgaverne skal spores og overvåges. I eksemplet med den distribuerede Cron skal planlægningssystemet rettidigt starte processen i overensstemmelse med operationens krav. Hvis processen ikke udføres, er det nødvendigt at prøve igen osv. Nogle komplekse scenarier, såsom Hadoop kort reducere, planlægning systemet skal opdele kortet reducere opgaven i den tilsvarende flere kort og reducere opgaver, og i sidste ende få opgaven udførelse resultatdata.
- ressourceplanlægning: bruges i det væsentlige til at matche opgaver og ressourcer, og passende ressourcer tildeles til at køre opgaver i henhold til ressourceforbrug af værter i klyngen. Det vigtigste mål med ressourceplanlægning er at forbedre ressourceudnyttelsen så vidt muligt og reducere ventetiden for opgaver under betingelse af den faste ressourceforsyning og reducere forsinkelsen af opgaven eller responstiden (hvis det er batchopgave, henviser det til tiden fra start til slut af opgaveoperationer, hvis det er online responstype opgaver, såsom internetapplikationer, der henviser til hver responstid på anmodningen), skal Opgaveprioriteten tages i betragtning, mens den er lige så retfærdig som den, der er muligt (ressourcer er ret allokeret til alle opgaver). Nogle af disse mål er modstridende og skal afbalanceres, såsom ressourceudnyttelse, responstid, retfærdighed og prioriteter.
Hadoop MRv1
Kortreduktion er en slags parallel computermodel. Hadoop kan køre denne form for cluster management platform af parallel computing. MRv1 er den første generation af kort reducere opgave planlægning motor Hadoop platform. Kort sagt, MRv1 er ansvarlig for planlægning og udførelse af jobbet på klyngen, og vende tilbage til beregningsresultaterne, når en bruger definerer et kort reducere beregning og indsende det til Hadoop. Sådan ser arkitekturen i MRv1 ud:
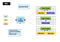
arkitekturen er relativt enkel, standard Master / Slave arkitektur har to kernekomponenter:
- Job Tracker er den vigtigste ledelseskomponent i cluster, som er ansvarlig for både ressourceplanlægning og Opgaveplanlægning.
- Task Tracker kører på hver maskine i klyngen, som er ansvarlig for at køre specifikke opgaver på værten og rapporteringsstatus.
med populariteten af Hadoop og stigningen i forskellige krav har MRv1 følgende problemer, der skal forbedres:
- forestillingen har en vis flaskehals: det maksimale antal noder, der understøtter ledelsen, er 5.000, og det maksimale antal opgaver til understøttende drift er 40.000. Der er stadig plads til forbedringer.
- det er ikke fleksibelt nok til at udvide eller understøtte andre opgavetyper. Ud over Kortreducerende opgaver er der mange andre opgavetyper i Hadoop-økosystemet, der skal planlægges, f.eks. Derfor er der brug for et mere generelt planlægningssystem, som kan understøtte og udvide flere opgavetyper
- lav ressourceudnyttelse: MRv1 konfigurerer statisk et fast antal slots for hver node, og hver slot kan kun bruges til den specifikke opgavetype (kort eller reducer), hvilket fører til problemet med ressourceudnyttelse. For eksempel står et stort antal Kortopgaver i kø for ledige ressourcer, men faktisk er et stort antal reducer slots inaktiv for maskiner.
- multi-tenancy og multi-version spørgsmål. For eksempel kører forskellige afdelinger opgaver i samme klynge, men de er logisk isoleret fra hinanden, eller de kører forskellige versioner af Hadoop i samme klynge.
garn
garn(endnu en Ressourceforhandler) er en anden generation af Hadoop ,hovedformålet er at løse alle slags problemer i MRv1. GARNARKITEKTUR ser sådan ud:

den enkle forståelse af garn er, at den vigtigste forbedring i forhold til MRv1 er at opdele ansvaret for den oprindelige JobTrack i to forskellige komponenter: Resource Manager og Application Master
- Resource Manager: Det er ansvarligt for ressourceplanlægning, administrerer alle ressourcer, tildeler ressourcer til forskellige typer opgaver og udvider let Ressourceplanlægningsalgoritmen gennem en pluggbar arkitektur.
- Application Master: Det er ansvarligt for Opgaveplanlægning. Hvert job (kaldet ansøgning i garn) starter en tilsvarende Application Master, som er ansvarlig for at opdele jobbet i specifikke opgaver og ansøge om ressourcer fra Resource Manager, starte opgaven, spore status for opgaven og rapportere resultaterne.
lad os se på, hvordan denne arkitekturændring løste Mrv1s forskellige problemer:
- opdel den oprindelige opgave planlægning ansvar Job Tracker, og resulterer i betydelige forbedringer ydeevne. Opgaveplanlægningsansvaret for den oprindelige JobTracker blev opdelt for at blive udført af Applikationsmesteren,og Applikationsmesteren blev distribueret, hver instans håndterede kun anmodningen om et Job, og det fremmede således det maksimale antal klyngeknuder fra 5.000 til 10.000.
- komponenterne i Opgaveplanlægning, Applikationsmaster og ressourceplanlægning afkobles og oprettes dynamisk baseret på jobanmodninger. En Applikationsmasterinstans er kun ansvarlig for et planlægningsjob, hvilket gør det lettere at understøtte forskellige typer job.
- containerisoleringsteknologien introduceres, hver opgave køres i en isoleret container, hvilket i høj grad forbedrer ressourceudnyttelsen i henhold til opgavens efterspørgsel efter ressourcer, der kan tildeles dynamisk. Ulempen ved dette er YARN ‘ s ressourcestyring, og allokering har kun en dimension af hukommelse.
Mesos arkitektur
DESIGNMÅLET med garn er stadig at tjene planlægningen af Hadoop-økosystemet. Mesos mål kommer tættere på, det er designet til at være et generelt planlægningssystem, som kan styre driften af hele datacentret. Som vi ser, brugte mesos arkitektoniske design meget garn til reference, jobplanlægningen og Ressourceplanlægningen bæres af de forskellige moduler separat. Men den største forskel mellem Mesos og garn er måden at planlægge ressourcer på, en unik mekanisme kaldet Ressourcetilbud er designet. Presset fra ressourceplanlægningen frigives yderligere, og jobplanlægningens skalerbarhed øges også.

de vigtigste komponenter i Mesos er:
- Mesos Master: Det er en komponent, der alene er ansvarlig for ressourceallokering og ledelseskomponenter, som er ressourceadministratoren svarende til det indvendige garn. Men driftsmåden er lidt anderledes, hvis det vil blive diskuteret senere.
- ramme: er ansvarlig for jobplanlægning, vil forskellige jobtyper have en tilsvarende ramme, såsom den Gnistramme, der er ansvarlig for Gnistjob.
Ressourcetilbud af Mesos
det kan virke som om Mesos – og GARNARKITEKTURERNE er ret ens, men i virkeligheden har Mesos Master en meget unik (og noget bisarr) Ressourcetilbudsmekanisme, når det gælder ressourcestyring:
- garn er Pull: Ressourcerne leveret af Resource Manager i garn er passive,når forbrugerne af resource (Application Master) har brug for ressourcer, kan det kalde grænsefladen til Resource Manager for at få ressourcer, og Resource Manager reagerer kun passivt på Application Master ‘ s behov.
- Mesos er Push: ressourcerne leveret af Master of Mesos er proaktive. Master of Mesos vil regelmæssigt tage initiativ til at skubbe alle de nuværende tilgængelige ressourcer (de såkaldte Ressourcetilbud, jeg vil kalde det tilbud fra nu af) til rammen. Hvis der er opgaver, som rammen skal udføre, kan den ikke aktivt ansøge om ressourcer, medmindre tilbudene modtages. Ramme vælger en kvalificeret ressource fra tilbuddet om at acceptere (denne bevægelse kaldes Accept i Mesos,) og afvise de resterende tilbud (denne bevægelse kaldes Afvis). Hvis der ikke er nok kvalificerede ressourcer i denne runde af tilbud, vi er nødt til at vente på den næste runde af Master til at give tilbud.
jeg tror, at når du ser denne aktive Tilbudsmekanisme, vil du have den samme følelse med mig. Det vil sige, effektiviteten er relativt lav, og følgende problemer vil opstå:
- beslutningseffektiviteten af enhver ramme påvirker den samlede effektivitet. For konsistens kan Master kun give tilbud til en ramme ad gangen og vente på, at rammen vælger tilbuddet, før resten leveres til den næste ramme. På denne måde vil beslutningstagningseffektiviteten af enhver ramme påvirke den samlede effektivitet.
- “spilder” meget tid på rammer, der ikke kræver ressourcer. Mesos ved ikke rigtig, hvilken ramme der har brug for ressourcer. Så der vil være Rammer med ressourcekrav, der står i kø for tilbud, men rammen uden ressourcekrav modtager ofte tilbud.
som svar på ovenstående problemer har Mesos leveret nogle mekanismer til at afbøde problemerne, såsom at indstille en timeout for rammen til at træffe beslutninger eller lade rammen afvise tilbud ved at indstille den til at være undertrykke tilstand. Da det ikke er fokus for denne diskussion, forsømmes detaljerne her.
faktisk er der nogle åbenlyse fordele for Mesos ved hjælp af denne mekanisme for aktivt tilbud:
- ydelsen er åbenbart forbedret. En klynge kan understøtte op til 100.000 noder i henhold til simuleringstesten, for kvidres produktionsmiljø kan den største klynge understøtte 80.000 noder. hovedårsagen er, at det aktive tilbud om Mesos Master mechanism yderligere forenkler Mesos ansvar. processen med ressourceplanlægning, ressource til opgave matching, i Mesos er opdelt i to faser: ressourcer at tilbyde, og tilbud til opgave. Mesos Master er kun ansvarlig for at gennemføre den første fase, og matchningen af den anden fase overlades til rammen.
- mere fleksibel og i stand til at opfylde mere ansvarlige politikker for Opgaveplanlægning. For eksempel ressourceforbrugsstrategien for alt eller intet.
Planlægningsalgoritme for Mesos DRF (Dominant Resource Fairness)
hvad angår DRF-algoritmen, har det faktisk intet at gøre med vores forståelse af Mesos-arkitektur, men det er meget kerne og vigtigt i Mesos, så jeg vil forklare lidt mere her.
som nævnt ovenfor giver Mesos tilbud til rammen igen, så hvilken ramme skal vælges for at give tilbud hver gang? Dette er kerneproblemet, der skal løses af DRF-algoritmen. Det grundlæggende princip er at tage hensyn til både retfærdighed og effektivitet. Mens det opfylder alle ressourcekrav i rammen, bør det være så retfærdigt som muligt at undgå, at en ramme bruger for mange ressourcer og sulter andre rammer ihjel.
DRF er en variant af min-maks fairness algoritme. Enkelt sagt er det at vælge rammen med den laveste dominerende ressourceforbrug for at give tilbuddet hver gang. Hvordan beregnes den dominerende ressourceforbrug af rammen? Fra alle de ressourcetyper, der er optaget af rammen, vælges ressourcetypen med den laveste Ressourcebesættelseshastighed som den dominerende ressource. Dens Ressourcebesættelsesgrad er nøjagtigt den dominerende ressourceforbrug af rammen. For eksempel optager en CPU af rammer 20% af den samlede ressource, 30% af hukommelsen og 10% af disken. Så den dominerende ressourceforbrug af rammen vil være 10%, det officielle udtryk kalder en disk som dominerende ressource, og denne 10% kaldes dominerende ressourceforbrug.
det ultimative mål med DRF er at fordele ressourcer ligeligt mellem alle rammerne. Hvis en ramme accepterer for mange ressourcer i denne runde af tilbud, vil det tage meget længere tid at få mulighed for den næste runde af tilbud. Imidlertid vil omhyggelige læsere opdage, at der er en antagelse i denne algoritme, det vil sige, efter at rammen accepterer ressourcer, frigiver den dem hurtigt, ellers vil der være to konsekvenser:
- andre rammer sulter ihjel. En ramme a accepterer de fleste ressourcer i klyngen ad gangen, og opgaven fortsætter med at køre uden at holde op, så de fleste ressourcer besættes af ramme A hele tiden, og andre rammer får ikke længere ressourcerne.
- sulte dig selv ihjel. Fordi den dominerende ressourceforbrug af denne ramme altid er meget høj, så er der ingen chance for at få tilbud i lang tid, så flere opgaver kan ikke køres.
så Mesos er kun egnet til planlægning af korte opgaver, og Mesos blev oprindeligt designet til korte opgaver af datacentre.
opsummering
fra den store arkitektur er al planlægningssystemet arkitektur Master/Slave arkitektur, Slave end er installeret på hver maskine med krav om ledelse, som bruges til at indsamle værtsoplysninger og udføre opgaver på værten. Master er primært ansvarlig for ressourceplanlægning og Opgaveplanlægning. Ressourceplanlægning har højere krav til ydeevne, og Opgaveplanlægning har højere krav til skalerbarhed. Den generelle tendens er at diskutere de to former for toldafkobling og fuldføre dem med forskellige komponenter.
