Évolution du système de planification de cluster
Kubernetes est devenu la norme de facto dans le domaine de l’orchestration de conteneurs. Toutes les applications seront développées et exécutées sur Kubernetes à l’avenir. Le but de cette série d’articles est d’introduire les principes d’implémentation sous-jacents de Kubernetes d’une manière profonde et simple.
Kubernetes est un système de planification de cluster. Cet article présente principalement une architecture de système de planification de cluster antérieure de Kubernetes. En analysant leurs idées de conception et les caractéristiques de l’architecture, nous pouvons étudier le processus d’évolution de l’architecture du système de planification de cluster, et le principal problème à prendre en compte dans la conception de l’architecture. Cela sera très utile pour comprendre l’architecture Kubernetes.
Nous devons comprendre certains des concepts de base du système de planification de cluster, afin de le rendre clair, je vais expliquer le concept à travers un exemple, supposons que nous voulons implémenter un Cron distribué. Le système gère un ensemble d’hôtes Linux. L’utilisateur définit la tâche via l’API fournie par le système. le système effectuera périodiquement la tâche correspondante en fonction de la définition de la tâche, dans cet exemple, les concepts de base sont ci-dessous:
- Cluster : les hôtes Linux gérés par ce système forment un pool de ressources pour exécuter des tâches. Ce pool de ressources est appelé Cluster.
- Job : Il définit comment le cluster exécute ses tâches. Dans cet exemple, Crontab est exactement un travail simple qui montre clairement ce qu’il faut faire (script d’exécution) à quelle heure (intervalle de temps).La définition de certaines tâches est plus complexe, comme la définition d’une tâche à accomplir dans plusieurs tâches, et les dépendances entre les tâches, ainsi que les besoins en ressources de chaque tâche.
- Tâche : Une tâche doit être planifiée en tâches d’exécution spécifiques. Si nous définissons une tâche pour exécuter un script à 1h du matin tous les soirs, alors le processus de script effectué à 1h du matin tous les jours est une tâche.
Lors de la conception du système de planification de cluster, les tâches principales du système sont deux:
- Planification des tâches: Une fois les tâches soumises au système de planification de cluster, les tâches soumises doivent être divisées en tâches d’exécution spécifiques et les résultats d’exécution des tâches doivent être suivis et surveillés. Dans l’exemple du Cron distribué, le système de planification doit démarrer le processus en temps opportun conformément aux exigences de l’opération. Si le processus échoue, la nouvelle tentative est nécessaire, etc. Dans certains scénarios complexes, tels que Hadoop Map Reduce, le système de planification doit diviser la tâche Map Reduce en plusieurs tâches Map et Reduce correspondantes, et finalement obtenir les données de résultat d’exécution de la tâche.
- Planification des ressources : est essentiellement utilisé pour faire correspondre les tâches et les ressources, et les ressources appropriées sont allouées pour exécuter les tâches en fonction de l’utilisation des ressources des hôtes du cluster. Il est similaire au processus d’algorithme de planification du système d’exploitation, l’objectif principal de la planification des ressources est d’améliorer l’utilisation des ressources dans la mesure du possible et de réduire le temps d’attente pour les tâches sous condition de fourniture fixe de ressources, et de réduire le délai de la tâche ou du temps de réponse (s’il s’agit d’une tâche par lots, il se réfère au temps du début à la fin des opérations de tâche, s’il s’agit de tâches de type réponse en ligne, telles que les applications Web, qui se réfère à chaque temps de réponse à la demande), la priorité de tâche doit être prise en considération tout en étant aussi juste que possible (les ressources sont équitablement allouées à toutes les tâches). Certains de ces objectifs sont contradictoires et doivent être équilibrés, comme l’utilisation des ressources, le temps de réponse, l’équité et les priorités.
Hadoop MRv1
Map Reduce est une sorte de modèle de calcul parallèle. Hadoop peut exécuter ce type de plate-forme de gestion de cluster de calcul parallèle. MRv1 est la version de première génération du moteur de planification des tâches Map Reduce de la plate-forme Hadoop. En bref, MRv1 est responsable de la planification et de l’exécution du travail sur le cluster, et revient aux résultats de calcul lorsqu’un utilisateur définit un calcul de réduction de carte et le soumet à Hadoop. Voici à quoi ressemble l’architecture de MRv1:
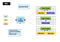
L’architecture est relativement simple, l’architecture Maître /esclave standard comporte deux composants principaux:
- Job Tracker est le principal composant de gestion du cluster, responsable à la fois de la planification des ressources et de la planification des tâches.
- Le tracker de tâches s’exécute sur chaque machine du cluster, qui est responsable de l’exécution de tâches spécifiques sur l’hôte et de l’état des rapports.
Avec la popularité de Hadoop et l’augmentation des demandes diverses, MRv1 a les problèmes suivants à améliorer:
- La performance a un certain goulot d’étranglement: le nombre maximum de nœuds prenant en charge la gestion est de 5 000 et le nombre maximum de tâches de prise en charge est de 40 000. Il y a encore une marge d’amélioration.
- Il n’est pas assez flexible pour étendre ou prendre en charge d’autres types de tâches. En plus des tâches de type réduction de carte, il existe de nombreux autres types de tâches dans l’écosystème Hadoop qui doivent être planifiés, tels que Spark, Hive, HBase, Storm, Oozie, etc. Par conséquent, un système de planification plus général est nécessaire, qui peut prendre en charge et étendre davantage de types de tâches
- Faible utilisation des ressources: MRv1 configure statiquement un nombre fixe d’emplacements pour chaque nœud, et chaque emplacement ne peut être utilisé que pour le type de tâche spécifique (Map ou Reduce), ce qui entraîne le problème d’utilisation des ressources. Par exemple, un grand nombre de tâches de carte font la queue pour les ressources inactives, mais en fait, un grand nombre d’emplacements de réduction sont inactifs pour les machines.
- Problèmes de location multiple et de versions multiples. Par exemple, différents départements exécutent des tâches dans le même cluster, mais ils sont logiquement isolés les uns des autres, ou exécutent différentes versions de Hadoop dans le même cluster.
FIL
Le FIL (Encore un autre négociateur de ressources) est une deuxième génération de Hadoop, le but principal est de résoudre toutes sortes de problèmes dans MRv1. L’architecture YARN ressemble à ceci:

La compréhension simple de YARN est que la principale amélioration par rapport à MRv1 consiste à diviser les responsabilités du JobTrack d’origine en deux composants différents: Gestionnaire de ressources et Maître d’application
- Gestionnaire de ressources: Il est responsable de la planification des ressources, gère toutes les ressources, attribue des ressources à différents types de tâches et étend facilement l’algorithme de planification des ressources via une architecture enfichable.
- Maître d’application: Il est responsable de la planification des tâches. Chaque tâche (appelée Application dans YARN) démarre un Maître d’application correspondant, qui est chargé de diviser la tâche en tâches spécifiques, et de demander des ressources à partir du Gestionnaire de ressources, de démarrer la tâche, de suivre l’état de la tâche et de rapporter les résultats.
Voyons comment ce changement d’architecture a résolu les différents problèmes de MRv1:
- Répartissez les responsabilités de planification des tâches d’origine de Job Tracker, ce qui entraîne des améliorations significatives des performances. Les responsabilités de planification des tâches du Traqueur de tâches d’origine ont été divisées pour être assumées par le Maître d’Application, et le Maître d’Application a été distribué, chaque instance ne traitant que la demande d’une Tâche, ce qui a favorisé le nombre maximum de nœuds de cluster de 5 000 à 10 000.
- Les composants de la planification des tâches, du Maître d’application et de la planification des ressources sont découplés et créés dynamiquement en fonction des demandes de travail. Une instance maître d’application est responsable d’une seule tâche de planification, ce qui facilite la prise en charge de différents types de tâches.
- La technologie d’isolation des conteneurs est introduite, chaque tâche est exécutée dans un conteneur isolé, ce qui améliore considérablement l’utilisation des ressources en fonction de la demande de ressources pouvant être allouées dynamiquement. L’inconvénient est que la gestion et l’allocation des ressources de YARN n’ont qu’une seule dimension de mémoire.
Architecture Mesos
L’objectif de conception de YARN est toujours de servir la planification de l’écosystème Hadoop. L’objectif de Mesos se rapproche, il est conçu pour être un système de planification général, capable de gérer le fonctionnement de l’ensemble du centre de données. Comme nous le voyons, la conception architecturale de Mesos a utilisé beaucoup de FIL pour référence, la planification des tâches et la planification des ressources sont supportées séparément par les différents modules. Mais la plus grande différence entre Mesos et YARN est la façon de planifier les ressources, un mécanisme unique appelé Offre de ressources est conçu. La pression de la planification des ressources est également relâchée et l’évolutivité de la planification des tâches est également augmentée.

Les principaux composants de Mesos sont:
- Mesos Master: C’est un composant seul responsable de l’allocation des Ressources et des composants de gestion, qui est le Gestionnaire de ressources correspondant au FIL intérieur. Mais le mode de fonctionnement est légèrement différent si sera discuté plus tard.
- Framework : est responsable de la planification des tâches, différents types de tâches auront un framework correspondant, tel que le framework Spark qui est responsable des tâches Spark.
Offre de ressources de Mesos
Il peut sembler que les architectures Mesos et YARN sont assez similaires, mais, en fait, du point de vue de la gestion des ressources, le Maître de Mesos a un mécanisme d’Offre de ressources très unique (et quelque peu bizarre:
- LE FIL est tiré: Les ressources fournies par le Gestionnaire de ressources dans YARN sont passives, lorsque les consommateurs de ressources (Maître d’application) ont besoin de ressources, il peut appeler l’interface du Gestionnaire de ressources pour obtenir des ressources, et le Gestionnaire de ressources ne répond que passivement aux besoins du Maître d’application.
- Mesos est Push: Les ressources fournies par Master of Mesos sont proactives. Master of Mesos prendra régulièrement l’initiative de pousser toutes les ressources actuellement disponibles (les soi-disant offres de ressources, je l’appellerai désormais Offre) vers le Cadre. S’il y a des tâches à exécuter pour le Framework, il ne peut pas demander activement des ressources, à moins que les offres ne soient reçues. Framework sélectionne une ressource qualifiée parmi l’Offre à accepter (cette motion est appelée Accepter dans Mesos) et rejette les offres restantes (cette motion est appelée Rejeter). S’il n’y a pas assez de ressources qualifiées dans ce cycle d’offre, nous devons attendre le prochain cycle de Master pour fournir une offre.
Je crois que lorsque vous verrez ce mécanisme d’offre active, vous aurez le même sentiment avec moi. Autrement dit, l’efficacité est relativement faible et les problèmes suivants se poseront:
- l’efficacité décisionnelle de tout cadre affecte l’efficacité globale. Par souci de cohérence, Master ne peut fournir d’Offre qu’à un Cadre à la fois et attendre que le Cadre sélectionne l’Offre avant de fournir le reste au Cadre suivant. De cette façon, l’efficacité décisionnelle de tout cadre affectera l’efficacité globale.
- “perdre” beaucoup de temps sur des frameworks qui ne nécessitent pas de ressources. Mesos ne sait pas vraiment quel cadre a besoin de ressources. Il y aura donc un Cadre avec des besoins en ressources en attente d’offre, mais le Cadre sans besoins en ressources reçoit fréquemment une offre.
En réponse aux problèmes ci-dessus, Mesos a fourni certains mécanismes pour atténuer les problèmes, tels que la définition d’un délai d’attente pour que le Framework prenne des décisions, ou permettre au Framework de rejeter les offres en le définissant comme État de suppression. Comme ce n’est pas l’objet de cette discussion, les détails sont négligés ici.
En fait, il existe des avantages évidents pour Mesos utilisant ce mécanisme d’offre active:
- Les performances sont évidemment améliorées. Un cluster peut prendre en charge jusqu’à 100 000 nœuds selon les tests de simulation, pour l’environnement de production de Twitter, le plus grand cluster peut prendre en charge 80 000 nœuds. la raison principale est que l’offre active de Mesos Master mechanism simplifie davantage les responsabilités de Mesos. le processus de planification des ressources, d’appariement des ressources à la tâche, dans Mesos est divisé en deux étapes: les ressources à offrir et l’Offre à la tâche. Le maître Mesos n’est responsable que de l’achèvement de la première phase, et l’appariement de la deuxième phase est laissé au Framework.
- Plus flexible et capable de répondre à des politiques de planification des tâches plus responsables. Par exemple, la stratégie d’utilisation des ressources de Tout ou Rien.
Algorithme de planification de Mesos DRF (Équité dominante des ressources)
Quant à l’algorithme DRF, il n’a en fait rien à voir avec notre compréhension de l’architecture Mesos, mais il est très fondamental et important dans Mesos, donc je vais vous expliquer un peu plus ici.
Comme mentionné ci-dessus, Mesos fournit une offre au Framework à son tour, alors quel Framework doit être sélectionné pour fournir une offre à chaque fois? C’est le problème principal à résoudre par l’algorithme DRF. Le principe de base est de tenir compte à la fois de l’équité et de l’efficacité. Tout en répondant à tous les besoins en ressources du Cadre, il devrait être aussi juste que possible d’éviter qu’un Cadre ne consomme trop de ressources et que d’autres cadres ne meurent de faim.
DRF est une variante de l’algorithme d’équité min-max. En termes simples, il s’agit de sélectionner le Framework avec l’utilisation de ressources dominante la plus faible pour fournir l’Offre à chaque fois. Comment calculer l’utilisation dominante des ressources du Framework? Parmi tous les types de ressources occupés par le Cadre, le type de ressource avec le taux d’occupation des ressources le plus bas est sélectionné comme ressource dominante. Son taux d’occupation des ressources est exactement l’Utilisation dominante des ressources du Cadre. Par exemple, une CPU de Framework occupe 20% de la Ressource globale, 30% de la mémoire et 10% du disque. Ainsi, l’utilisation dominante des ressources du Framework sera de 10%, le terme officiel appelle un disque comme ressource dominante, et ce 10% est appelé Utilisation dominante des ressources.
Le but ultime de DRF est de répartir les ressources de manière égale entre tous les cadres. Si un Framework X accepte trop de ressources dans ce cycle d’Offre, il faudra alors beaucoup plus de temps pour obtenir l’opportunité du prochain cycle d’offre. Cependant, les lecteurs attentifs constateront qu’il existe une hypothèse dans cet algorithme, c’est-à-dire qu’une fois que le framework aura accepté les ressources, il les libérera rapidement, sinon il y aura deux conséquences:
- D’autres cadres meurent de faim. Un framework A accepte la plupart des ressources du cluster à la fois, et la tâche continue de s’exécuter sans quitter, de sorte que la plupart des ressources sont occupées par le framework A tout le temps, et d’autres frameworks n’obtiendront plus les ressources.
- Mourez de faim. Parce que l’utilisation dominante des ressources de ce framework est toujours très élevée, il n’y a donc aucune chance d’obtenir une offre pendant une longue période, donc plus de tâches ne peuvent pas être exécutées.
Mesos est donc uniquement adapté à la planification de tâches courtes, et Mesos ont été conçus à l’origine pour les tâches courtes des centres de données.
Résumé
De la grande architecture, toute l’architecture du système de planification est une architecture maître / esclave, l’extrémité esclave est installée sur chaque machine avec une exigence de gestion, qui est utilisée pour collecter des informations sur l’hôte et effectuer des tâches sur l’hôte. Master est principalement responsable de la planification des ressources et de la planification des tâches. La planification des ressources a des exigences plus élevées en matière de performances et la planification des tâches a des exigences plus élevées en matière d’évolutivité. La tendance générale est de discuter des deux types de découplage des fonctions et de les compléter par différents composants.
