Ceph
Benchmark Ceph Cluster Performance¶
L’une des questions les plus courantes que nous entendons est ” Comment vérifier si mon cluster fonctionne à des performances maximales ?”. Ne vous demandez plus – dans ce guide, nous vous expliquerons certains outils que vous pouvez utiliser pour comparer votre cluster Ceph.
REMARQUE: Les idées de cet article sont basées sur le billet de blog de Sebastian Han, le billet de blog de TelekomCloud et les contributions des développeurs et ingénieurs Ceph.
Obtenir des statistiques de performance de base¶
Fondamentalement, l’analyse comparative est une question de comparaison. Vous ne saurez pas si votre cluster Ceph fonctionne en dessous du pair, sauf si vous identifiez d’abord ses performances maximales possibles. Ainsi, avant de commencer à comparer votre cluster, vous devez obtenir des statistiques de performances de base pour les deux principaux composants de votre infrastructure Ceph : vos disques et votre réseau.
Benchmark de vos disques¶
Le moyen le plus simple de benchmark de votre disque est avec dd. Utilisez la commande suivante pour lire et écrire un fichier, en vous rappelant d’ajouter le paramètre oflag pour contourner le cache de la page disque:shell> dd if=/dev/zero of=here bs=1G count=1 oflag=direct
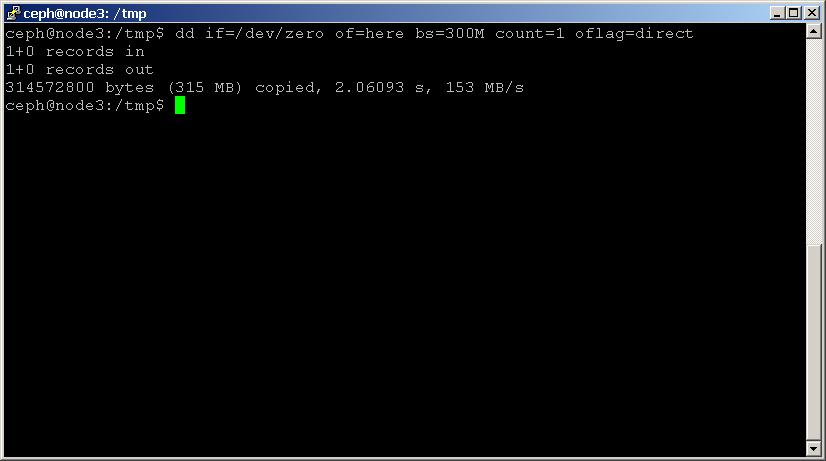
Notez la dernière statistique fournie, qui indique les performances du disque en Mo/s. Effectuez ce test pour chaque disque de votre cluster, en notant les résultats.
Benchmark de votre réseau¶
Un autre facteur clé affectant les performances du cluster Ceph est le débit du réseau. Un bon outil pour cela est iperf, qui utilise une connexion client-serveur pour mesurer la bande passante TCP et UDP.
Vous pouvez installer iperf en utilisant apt-get install iperf ou yum install iperf.
iperf doit être installé sur au moins deux nœuds de votre cluster. Ensuite, sur l’un des nœuds, démarrez le serveur iperf à l’aide de la commande suivante:
shell> iperf -s
Sur un autre nœud, démarrez le client avec la commande suivante, en n’oubliant pas d’utiliser l’adresse IP du nœud hébergeant le serveur iperf:
shell> iperf -c 192.168.1.1
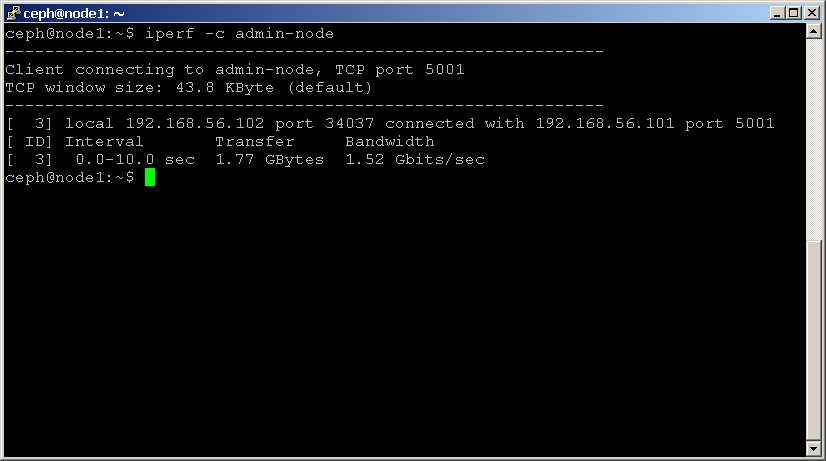
Notez la statistique de bande passante en Mbits/s, car elle indique le débit maximal pris en charge par votre réseau.
Maintenant que vous avez des numéros de référence, vous pouvez commencer à comparer votre cluster Ceph pour voir s’il vous donne des performances similaires. L’analyse comparative peut être effectuée à différents niveaux : vous pouvez effectuer une analyse comparative de bas niveau du cluster de stockage lui-même, ou vous pouvez effectuer une analyse comparative de plus haut niveau des interfaces clés, telles que les périphériques de bloc et les passerelles d’objets. Les sections suivantes traitent de chacune de ces approches.
REMARQUE : Avant d’exécuter l’un des benchmarks dans les sections suivantes, supprimez tous les caches à l’aide d’une commande comme celle-ci:shell> sudo echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
Comparer un cluster de stockage Ceph¶
Ceph inclut la commande rados bench, conçue spécifiquement pour comparer un cluster de stockage RADOS. Pour l’utiliser, créez un pool de stockage, puis utilisez rados bench pour effectuer un benchmark d’écriture, comme indiqué ci-dessous.
La commande rados est incluse avec Ceph.
shell> ceph osd pool create scbench 128 128
shell> rados bench -p scbench 10 write --no-cleanup
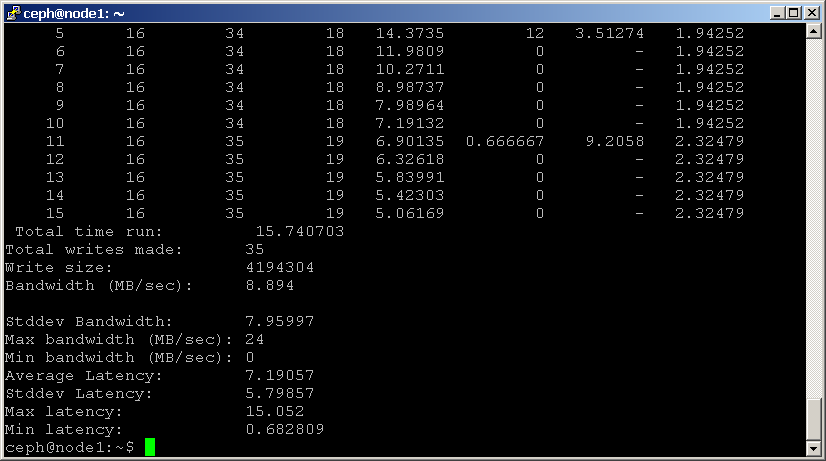
Cela crée un nouveau pool nommé “scbench”, puis effectue un benchmark d’écriture pendant 10 secondes. Notez l’optionnono-cleanup, qui laisse derrière elle certaines données. La sortie vous donne un bon indicateur de la vitesse à laquelle votre cluster peut écrire des données.
Deux types de benchmarks de lecture sont disponibles : seq pour les lectures séquentielles et rand pour les lectures aléatoires. Pour effectuer un benchmark de lecture, utilisez les commandes ci-dessous:shell> rados bench -p scbench 10 seq
shell> rados bench -p scbench 10 rand
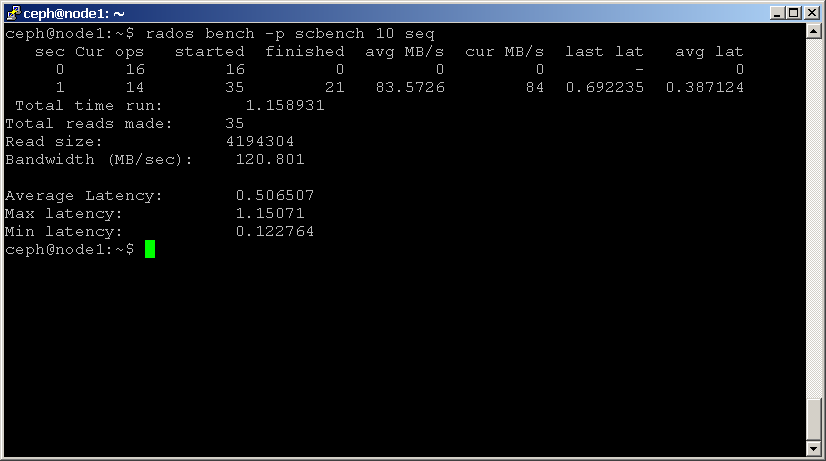
Vous pouvez également ajouter le paramètre -t pour augmenter la simultanéité des lectures et des écritures (par défaut 16 threads), ou le paramètre -b pour modifier la taille de l’objet en cours d’écriture (par défaut 4 Mo). C’est également une bonne idée d’exécuter plusieurs copies de ce benchmark sur différents pools, pour voir comment les performances changent avec plusieurs clients.
Une fois que vous avez les données, vous pouvez commencer à comparer les statistiques de lecture et d’écriture du cluster avec les benchmarks uniquement sur disque effectués précédemment, identifier l’écart de performance existant (le cas échéant) et commencer à rechercher des raisons.
Vous pouvez nettoyer les données de benchmark laissées par le benchmark d’écriture avec cette commande:
shell> rados -p scbench cleanup
Benchmark d’un périphérique bloc Ceph¶
Si vous êtes un fan des périphériques bloc Ceph, vous pouvez utiliser deux outils pour évaluer leurs performances. Ceph inclut déjà la commande rbd bench, mais vous pouvez également utiliser le populaire outil d’analyse comparative d’E /S fio, qui prend désormais en charge les périphériques de bloc RADOS.
La commande rbd est incluse avec Ceph. Le support RBD dans fio est relativement nouveau, vous devrez donc le télécharger à partir de son référentiel, puis le compiler et l’installer en utilisant_ configure & & make & & make install_. Notez que vous devez installer le package de développement librbd-dev avec apt-get install librbd-dev ou yum install librbd-dev avant de compiler fio afin d’activer son support RBD.
Avant d’utiliser l’un de ces deux outils, cependant, créez un périphérique de blocage à l’aide des commandes ci-dessous:shell> ceph osd pool create rbdbench 128 128
shell> rbd create image01 --size 1024 --pool rbdbench
shell> sudo rbd map image01 --pool rbdbench --name client.admin
shell> sudo /sbin/mkfs.ext4 -m0 /dev/rbd/rbdbench/image01
shell> sudo mkdir /mnt/ceph-block-device
shell> sudo mount /dev/rbd/rbdbench/image01 /mnt/ceph-block-device
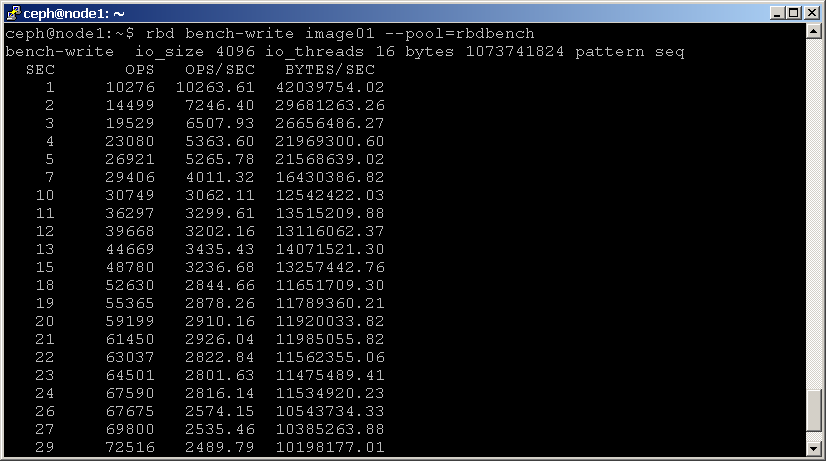
La commande rbd bench-write génère une série d’écritures séquentielles sur l’image et mesure le débit d’écriture et la latence. Voici un exemple:
shell> rbd bench-write image01 --pool=rbdbench
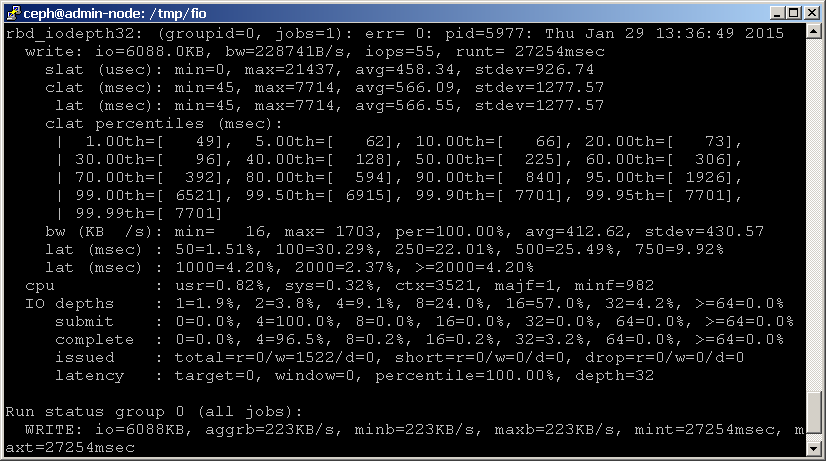
Vous pouvez également utiliser fio pour comparer votre périphérique de blocage. Un exemple rbd.le modèle fio est inclus avec le code source fio, qui effectue un test d’écriture aléatoire 4K contre un périphérique de bloc RADOS via librbd. Notez que vous devrez mettre à jour le modèle avec les noms corrects pour votre pool et votre appareil, comme indiqué ci-dessous.
ioengine=rbd
clientname=admin
pool=rbdbench
rbdname=image01
rw=randwrite
bs=4k
iodepth=32
Ensuite, exécutez fio comme suit:shell> fio examples/rbd.fio
Benchmark d’une passerelle d’objets Ceph¶
Lorsqu’il s’agit de benchmarker la passerelle d’objets Ceph, ne cherchez pas plus loin que swift-bench, l’outil de benchmarking inclus avec OpenStack Swift. L’outil swift-bench teste les performances de votre cluster Ceph en simulant les requêtes client PUT et GET et en mesurant leurs performances.
Vous pouvez installer swift-bench en utilisant pip install swift & & pip install swift-bench.
Pour utiliser swift-bench, vous devez d’abord créer un utilisateur et un sous-utilisateur de passerelle, comme indiqué ci-dessous:shell> sudo radosgw-admin user create --uid="benchmark" --display-name="benchmark"
shell> sudo radosgw-admin subuser create --uid=benchmark --subuser=benchmark:swift
--access=full
shell> sudo radosgw-admin key create --subuser=benchmark:swift --key-type=swift
--secret=guessme
shell> radosgw-admin user modify --uid=benchmark --max-buckets=0
Ensuite, créez un fichier de configuration pour swift-bench sur un hôte client, comme ci-dessous. N’oubliez pas de mettre à jour l’URL d’authentification pour refléter celle de votre passerelle d’objets Ceph et d’utiliser le nom d’utilisateur et les informations d’identification corrects.
auth = http://gateway-node/auth/v1.0
user = benchmark:swift
key = guessme
auth_version = 1.0
Vous pouvez maintenant exécuter un benchmark comme ci-dessous. Utilisez le paramètre -c pour ajuster le nombre de connexions simultanées (cet exemple utilise 64) et le paramètre -s pour ajuster la taille de l’objet en cours d’écriture (cet exemple utilise des objets 4K). Les paramètres -n et -g contrôlent respectivement le nombre d’objets à PLACER et à OBTENIR.shell> swift-bench -c 64 -s 4096 -n 1000 -g 100 /tmp/swift.conf
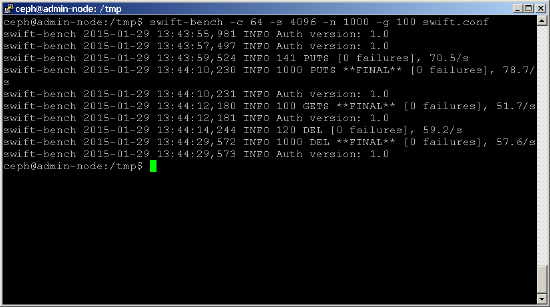
Bien que swift-bench mesure les performances en nombre d’objets / s, il est assez facile de les convertir en MO / s, en multipliant par la taille de chaque objet. Cependant, vous devez vous méfier de comparer cela directement avec les statistiques de performances de disque de base que vous avez obtenues précédemment, car un certain nombre d’autres facteurs influencent également ces statistiques, telles que:
- le niveau de réplication (et la surcharge de latence)
- écritures complètes de journaux de données (compensées dans certaines situations par la coalescence de données de journaux)
- fsync sur les OSD pour garantir la sécurité des données
- surcharge de métadonnées pour conserver les données stockées dans RADOS
- la surcharge de latence (réseau, ceph, etc.) rend la lecture plus importante
ASTUCE: En ce qui concerne les performances de la passerelle d’objets, il n’y a pas de règle dure et rapide que vous pouvez utiliser pour améliorer facilement les performances. Dans certains cas, les ingénieurs Ceph ont pu obtenir des performances supérieures à celles de base en utilisant des stratégies intelligentes de mise en cache et de coalescence, tandis que dans d’autres cas, les performances de la passerelle d’objets ont été inférieures aux performances du disque en raison de la latence, de la synchronisation automatique et de la surcharge des métadonnées.
Conclusion¶
Il existe un certain nombre d’outils disponibles pour comparer un cluster Ceph, à différents niveaux : disque, réseau, cluster, périphérique et passerelle. Vous devriez maintenant avoir un aperçu de la façon d’aborder le processus d’analyse comparative et de commencer à générer des données de performance pour votre cluster. Bonne chance!