Clustering et K Signifie: Définition et Analyse de cluster dans Excel
Définitions statistiques > Clustering / Analyse de clusters
Qu’est-ce que le Clustering ?
Le regroupement dans les statistiques fait référence à la façon dont les données sont collectées (“regroupées”) par des facteurs tels que:
- L’âge.
- Taille du ménage.
- Revenu.
- Ou niveau d’éducation.
Le tri des données en clusters conduit parfois à une investigation plus approfondie des données. Par exemple, les grappes de cancer peuvent indiquer un problème dans l’environnement. Ou, ils peuvent simplement être le résultat de la nature aléatoire. L’analyse de cluster a tendance à être subjective dans de nombreux cas; cela dépend de ce que vous percevez comme des fils communs dans les données. La technique n’est pas vraiment nouvelle dans les statistiques; si vous avez déjà créé un graphique à barres, vous avez probablement déjà créé des clusters (même si vous ne l’avez pas appelé ainsi). Par exemple, un graphique à barres montrant les races de chiens vous oblige à regrouper par race (Husky sibérien, Border Collie, Berger allemand…) ou un graphique des niveaux de revenus peut être regroupé par niveaux de revenus faibles, moyens et élevés.
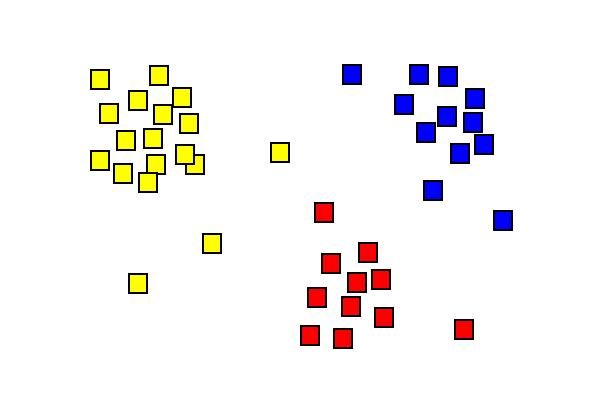
Résultats de l’analyse des grappes montrant trois grappes de couleurs différentes.
Les clusters peuvent être basés sur des facteurs tels que:
- Clustering basé sur la distance. Les éléments sont triés en fonction de leur proximité (ou distance). Par exemple, les cas de cancer peuvent être regroupés s’ils se trouvent au même endroit géographique.
- Clustering conceptuel. Les éléments sont regroupés par facteurs que les éléments ont en commun. Par exemple, les grappes de cancers pourraient être regroupées par “personnes qui travaillent dans le secteur manufacturier.”
Types de clustering
- Clustering exclusif. Chaque élément ne peut appartenir qu’à un seul cluster. Il ne peut pas appartenir à un autre cluster.
- Clusters flous : Les points de données se voient attribuer une probabilité d’appartenance à un ou plusieurs clusters.
- Clustering superposé. Chaque élément peut appartenir à plus d’un cluster.
- Clustering hiérarchique. Il s’agit d’une approche plus complexe du clustering utilisée dans l’exploration de données. Fondamentalement, chaque élément reçoit son propre cluster. Une paire de clusters est jointe en fonction des similitudes, ce qui donne un cluster de moins. Ce processus est répété jusqu’à ce que tous les éléments soient regroupés. Le dendrogramme est un graphique qui montre des clusters hiérarchiques.
- Clustering probabiliste. Les données sont regroupées à l’aide d’algorithmes qui connectent des éléments à l’aide de distances ou de densités. Ceci est généralement effectué par un ordinateur.
- Méthode de Ward: utilise la variance minimale à chaque étape pour créer des grappes relativement petites et de taille uniforme.
K Signifie Clustering
Le clustering n’est qu’un moyen de regrouper un ensemble de données en ensembles plus petits. Les deux façons de regrouper un ensemble de données sont quantitatives (en utilisant des nombres) et qualitatives (en utilisant des catégories). Par exemple, des livres sur Amazon.com sont répertoriés à la fois par catégorie (qualitative) et par best-seller (quantitative). Le clustering K-Means est l’un des algorithmes d’apprentissage non supervisé les plus simples qui résout les problèmes de clustering à l’aide d’une méthode quantitative: vous prédéfinissez un certain nombre de clusters et utilisez un algorithme simple pour trier vos données. Cela dit, “simple” dans le monde de l’informatique n’équivaut pas à simple dans la vie réelle. C’est en fait un problème NP-dur, vous voudrez donc utiliser un logiciel pour le clustering K-means. Certains programmes qui effectueront cela pour vous (cliquez sur le lien pour la procédure) sont:
- SPS.
- r
- MATLAB
Les étapes générales derrière l’algorithme de clustering K-means sont:
- Décidez du nombre de clusters (k).
- Placez k points centraux à différents endroits (généralement éloignés les uns des autres).
- Prenez chaque point de données et placez-le près du point central approprié. Répétez jusqu’à ce que tous les points de données aient été attribués.
- Recalculer k nouveaux points centraux en tant que barycentres.
- Répétez l’attribution des points de données, cette fois au nouveau point central (le barycentre).
- Répétez 4 et 5 jusqu’à ce que les points centraux (barycentres) ne bougent plus.
Clustering K-Means : Une définition plus formelle
Une façon plus formelle de définir le clustering K-Means consiste à catégoriser n objets en k (k > 1) groupes prédéfinis. L’objectif est de minimiser la distance entre chaque point de données et le cluster. En d’autres termes, pour trouver:
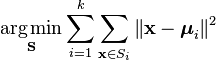
où:
X est un point de données
k est le nombre de clusters
ui est la moyenne des points dans Si.
Analyse en grappes par rapport à l’analyse discriminante
L’analyse en grappes est très similaire à l’analyse discriminante. Les deux méthodes impliquent la séparation en groupes. Cependant, l’analyse de cluster est un moyen d’identifier les groupes, tandis que l’analyse discriminante vous oblige à connaître les groupes avant de commencer l’analyse. Par exemple, disons que vous aviez un groupe de patients psychiatriques avec des comportements anormaux. L’analyse en grappes pourrait vous aider à trouver des groupes distincts, comme les patients ayant des antécédents d’abus, ceux atteints de SSPT ou ceux souffrant d’hallucinations. Si vous deviez effectuer une analyse discriminante sur le même groupe de personnes, vous devez connaître les diagnostics des patients avant de commencer à les placer dans des groupes.
Clustering dans Excel
Microsoft Excel dispose d’un complément d’exploration de données pour créer des clusters. Vous pouvez trouver des instructions ici. L’assistant fonctionne avec des tableaux Excel, des plages ou des requêtes d’enquête d’analyse. Ce complément peut être personnalisé, contrairement à l’outil Détecter les catégories. De plus, l’outil Détecter les catégories est limité aux données des tables.
À utiliser:
- Téléchargez et installez le complément d’exploration de données.
- Cliquez sur “Exploration de données”, puis sur “Cluster”, puis sur ” Suivant”.”
- Indiquez à Excel où se trouvent vos données. Par exemple, sélectionnez une plage de données. La page de regroupement sera disponible.
- Clustering : laissez tel quel pour le regroupement automatique, ou vous pouvez spécifier un certain nombre de groupes.
- Segments : laissez tels quels pour le regroupement automatique ou spécifiez un certain nombre de catégories.
Stephanie Glen. “Clustering et K Signifie: Définition & Analyse de cluster dans Excel” De StatisticsHowTo.com: Statistiques élémentaires pour le reste d’entre nous! https://www.statisticshowto.com/clustering/
——————————————————————————
Besoin d’aide pour une question de devoirs ou de test? Avec Chegg Study, vous pouvez obtenir des solutions étape par étape à vos questions d’un expert dans le domaine. Vos 30 premières minutes avec un tuteur Chegg sont gratuites!