Entrepôt de Données en nuage vs Concepts d’entrepôt de Données traditionnels
Les entrepôts de données en nuage sont la nouvelle norme. Il est révolu le temps où votre entreprise devait acheter du matériel, créer des salles de serveurs et embaucher, former et maintenir une équipe de personnel dédiée pour l’exécuter. Maintenant, en quelques clics sur votre ordinateur portable et une carte de crédit, vous pouvez accéder à une puissance de calcul et à un espace de stockage pratiquement illimités.
Cependant, cela ne signifie pas que les idées traditionnelles d’entrepôt de données sont mortes. La théorie classique de l’entrepôt de données sous-tend la plupart de ce que font les entrepôts de données basés sur le cloud.
Dans cet article, nous vous expliquerons les concepts traditionnels d’entrepôt de données que vous devez connaître et les plus importants de cloud parmi une sélection des meilleurs fournisseurs: Amazon, Google et Panoply. Enfin, nous terminerons par une analyse coûts-avantages des entrepôts de données traditionnels par rapport aux entrepôts de données cloud, afin que vous sachiez lequel vous convient le mieux.
Commençons.
- Concepts traditionnels d’entrepôt de données
- Faits, dimensions et mesures
- Normalisation et dénormalisation
- Modèles de données
- Tableau des faits
- Schéma Star vs Schéma Snowflake
- OLAP vs OLTP
- Architecture à trois niveaux
- Entrepôt de données virtuel /Data Mart
- Kimball vs. Inmon
- ETL vs ELT
- Entrepôt de données d’entreprise
- Concepts d’entrepôt de données en nuage
- Concepts d’entrepôt de données Cloud – Amazon Redshift
- Clusters
- Nœuds
- Partitions/ Tranches
- Stockage en colonnes
- Compression
- Chargement des données
- Entrepôt de données Cloud – Google BigQuery
- Service sans serveur
- Système de fichiers Colossus
- Moteur d’exécution Dremel
- Partage de données
- Diffusion en continu et ingestion par lots
- Concepts d’entrepôt de données Cloud – Panoply
- Clés primaires
- Clés incrémentales
- Données imbriquées
- Tables d’historique
- Transformations
- Formats de chaîne
- Protection des données
- Contrôle d’accès
- Liste blanche IP
- Conclusion: Concepts d’entrepôt de données traditionnels en bref
- Concepts traditionnels d’entrepôt de données
- Concepts d’entrepôt de données dans le Cloud – Amazon Redshift à titre d’exemple
- Concepts d’entrepôt de données dans le Cloud – BigQuery par exemple
- Analyse Coûts-avantages traditionnelle vs Cloud
- En savoir plus sur les Entrepôts de données
Concepts traditionnels d’entrepôt de données
Un entrepôt de données est un système qui rassemble des données provenant d’un large éventail de sources au sein d’une organisation. Les entrepôts de données sont utilisés comme dépôts de données centralisés à des fins d’analyse et de reporting.
Un entrepôt de données traditionnel est situé sur place dans vos bureaux. Vous achetez le matériel, les salles de serveurs et embauchez le personnel pour l’exécuter. Ils sont également appelés entrepôts de données sur site, sur site ou (grammaticalement incorrects) sur site.
Faits, dimensions et mesures
Les éléments de base de l’information dans un entrepôt de données sont les faits, les dimensions et les mesures.
Un fait est la partie de vos données qui indique une occurrence ou une transaction spécifique. Par exemple, si votre entreprise vend des fleurs, certains faits que vous verrez dans votre entrepôt de données sont:
- Vendu 30 roses en magasin pour 19 $.99
- Commandé 500 nouveaux pots de fleurs de Chine pour 1500
- Salaire de caissier payé pour ce mois-ci $1000
Plusieurs chiffres peuvent décrire chaque fait, et nous appelons ces chiffres des mesures. Certaines mesures pour décrire le fait “commandé 500 nouveaux pots de fleurs de Chine pour 1500 $” sont:
- Quantité commandée – 500
- Coût – $1500
Lorsque les analystes travaillent avec des données, ils effectuent des calculs sur des mesures (par exemple, somme, maximum, moyenne) pour obtenir des informations. Par exemple, vous voudrez peut-être connaître le nombre moyen de pots de fleurs que vous commandez chaque mois.
Une dimension catégorise les faits et les mesures et fournit des informations d’étiquetage structurées pour eux – sinon, ils ne seraient qu’une collection de nombres non ordonnés! Certaines dimensions pour décrire le fait “commandé 500 nouveaux pots de fleurs de Chine pour 1500 $” sont:
- Pays acheté – Chine
- Heure achetée – 13h
- Date d’arrivée prévue – 6 juin
Vous ne pouvez pas effectuer de calculs sur les dimensions explicitement, et cela ne serait probablement pas très utile – comment pouvez-vous trouver la “date d’arrivée moyenne des commandes”? Cependant, il est possible de créer de nouvelles mesures à partir de dimensions, et celles-ci sont utiles. Par exemple, si vous connaissez le nombre moyen de jours entre la date de commande et la date d’arrivée, vous pouvez mieux planifier les achats de stock.
Normalisation et dénormalisation
La normalisation est le processus d’organisation efficace des données dans un entrepôt de données (ou tout autre endroit qui stocke des données). Les principaux objectifs sont de réduire la redondance des données – c’est-à-dire de supprimer les données en double – et d’améliorer l’intégrité des données – c’est-à-dire d’améliorer la précision des données. Il existe différents niveaux de normalisation et aucun consensus pour la “meilleure” méthode. Cependant, toutes les méthodes impliquent de stocker des informations distinctes mais liées dans des tableaux différents.
La normalisation présente de nombreux avantages, tels que:
- Recherche et tri plus rapides sur chaque table
- Des tables plus simples accélèrent l’écriture et l’exécution des commandes de modification des données
- Moins de données redondantes signifie que vous économisez de l’espace disque et que vous pouvez donc collecter et stocker plus de données
La dénormalisation consiste à ajouter délibérément des copies ou des groupes de données redondants à des données déjà normalisées. Ce n’est pas la même chose que les données non normalisées. La dénormalisation améliore les performances de lecture et facilite la manipulation des tables dans les formulaires souhaités. Lorsque les analystes travaillent avec des entrepôts de données, ils n’effectuent généralement que des lectures sur les données. Ainsi, les données dénormalisées peuvent leur faire économiser beaucoup de temps et des maux de tête.
Avantages de la dénormalisation:
- Moins de tables minimisent le besoin de jointures de tables, ce qui accélère le flux de travail des analystes de données et leur permet de découvrir des informations plus utiles dans les données
- Moins de tables simplifient les requêtes, entraînant moins de bogues
Modèles de données
Il serait extrêmement inefficace de stocker toutes vos données dans une seule table massive. Ainsi, votre entrepôt de données contient de nombreuses tables que vous pouvez assembler pour obtenir des informations spécifiques. La table principale s’appelle une table de faits et des tables de dimensions l’entourent.
La première étape de la conception d’un entrepôt de données consiste à créer un modèle de données conceptuel qui définit les données que vous souhaitez et les relations de haut niveau entre elles.
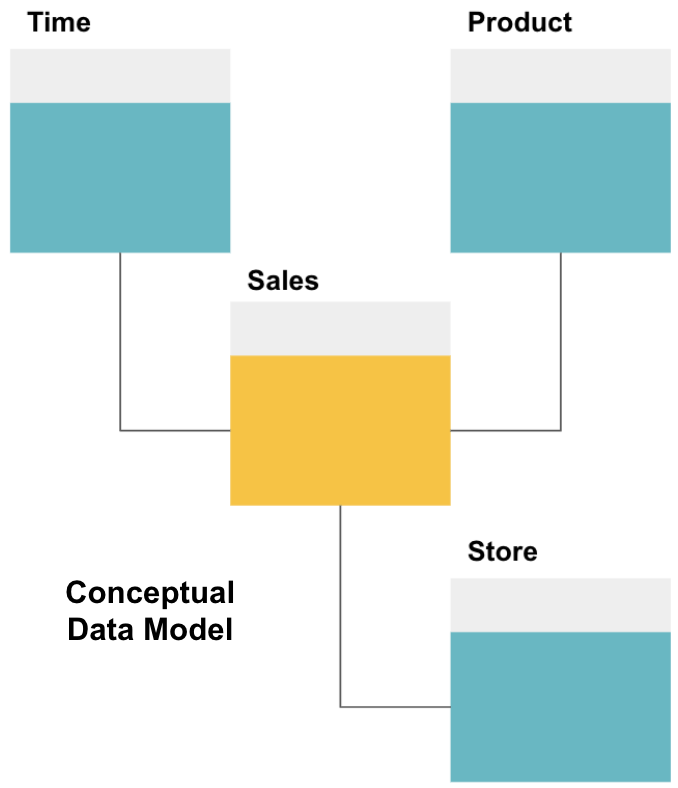
Ici, nous avons défini le modèle conceptuel. Nous stockons des données sur les ventes et disposons de trois tableaux supplémentaires – Heure, Produit et Magasin – qui fournissent des informations supplémentaires et plus granulaires sur chaque vente. La table des faits est des ventes, et les autres sont des tables de dimension.
L’étape suivante consiste à définir un modèle de données logique. Ce modèle décrit les données en détail en anglais sans se soucier de la façon de les implémenter dans le code.
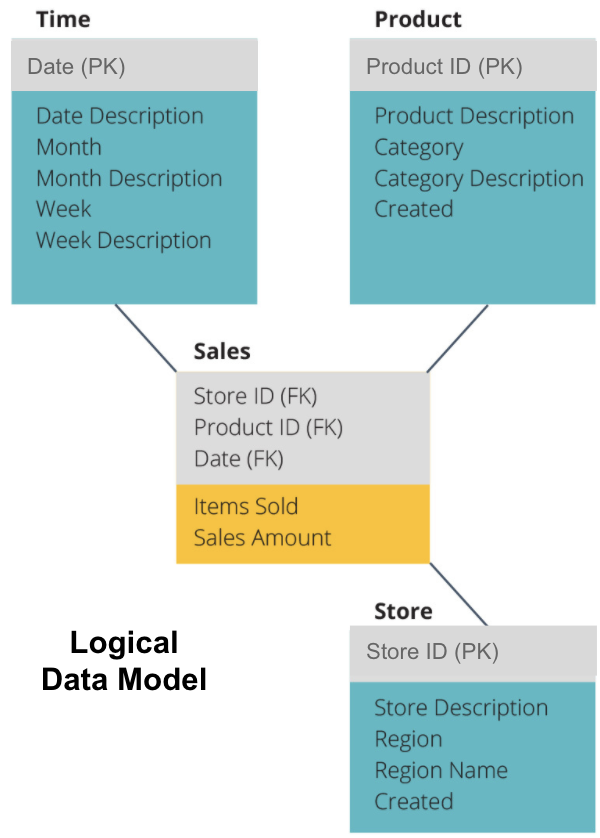
Nous avons maintenant rempli les informations que chaque tableau contient en anglais clair. Chacune des tables de dimension de temps, de produit et de magasin affiche la Clé primaire (PK) dans la boîte grise et les données correspondantes dans les boîtes bleues. La table de vente contient trois clés étrangères (FK) afin qu’elle puisse rapidement se joindre aux autres tables.
La dernière étape consiste à créer un modèle de données physiques. Ce modèle vous indique comment implémenter l’entrepôt de données dans le code. Il définit les tables, leur structure et la relation entre elles. Il spécifie également les types de données pour les colonnes, et tout est nommé tel qu’il sera dans l’entrepôt de données final, c’est-à-dire toutes les majuscules et connecté avec des traits de soulignement. Enfin, chaque table de dimension commence par DIM_ et chaque table de faits commence par FACT_.
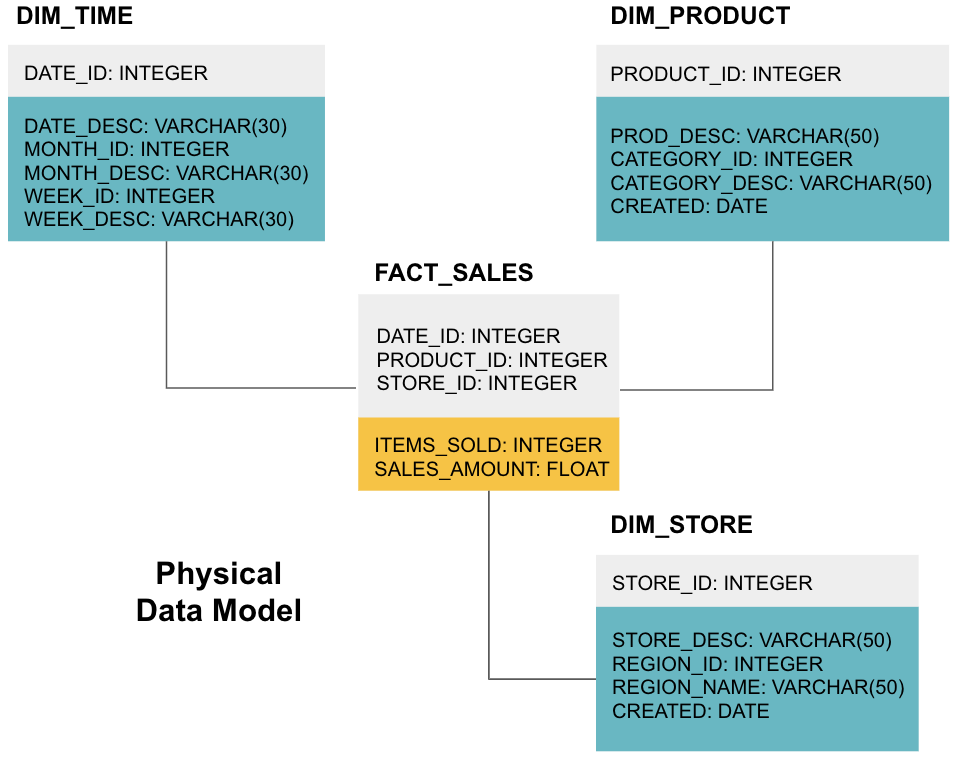
Vous savez maintenant comment concevoir un entrepôt de données, mais il y a quelques nuances aux tables de faits et de dimensions que nous expliquerons ensuite.
Tableau des faits
Chaque fonction commerciale – par exemple, ventes, marketing, finances – a une table des faits correspondante.
Les tables de faits ont deux types de colonnes : les colonnes de dimension et les colonnes de faits. Les colonnes de dimension – de couleur grise dans nos exemples – contiennent des clés étrangères (FK) que vous utilisez pour joindre une table de faits à une table de dimension. Ces clés étrangères sont les clés primaires (PK) de chacune des tables de dimensions. Les colonnes de faits – de couleur jaune dans nos exemples – contiennent les données et les mesures réelles à analyser, par exemple le nombre d’articles vendus et la valeur totale des ventes.
Une table de faits sans facteur est un type particulier de table de faits qui ne comporte que des colonnes de dimension. Ces tableaux sont utiles pour suivre les événements, tels que la présence des étudiants ou les congés des employés, car les dimensions vous indiquent tout ce que vous devez savoir sur les événements.
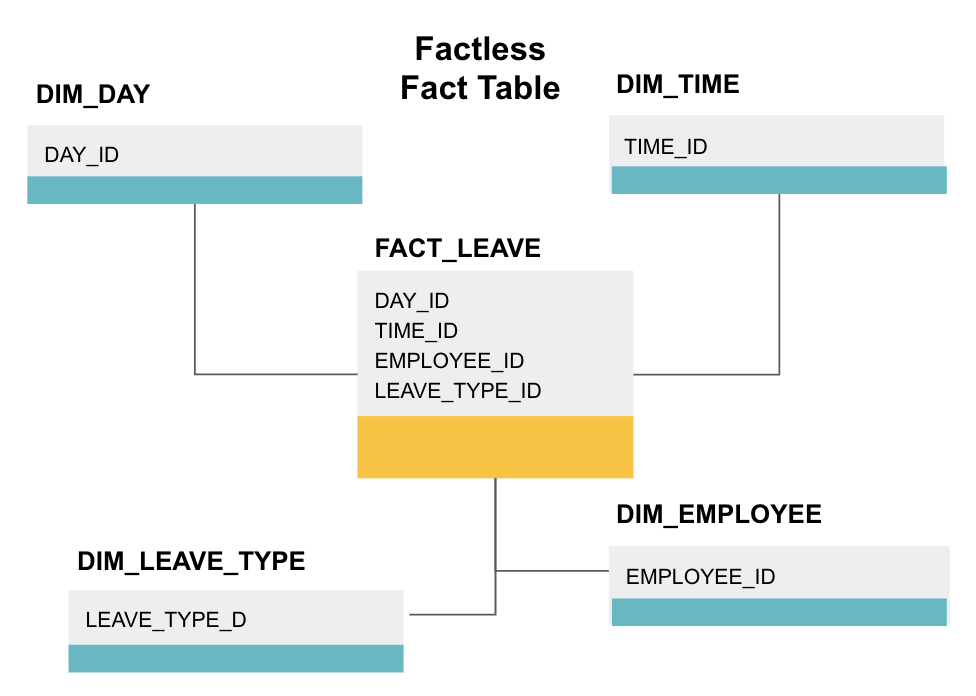
Le tableau de faits sans faits ci-dessus suit les congés des employés. Il n’y a pas de faits puisque vous avez juste besoin de savoir:
- Quel jour ils étaient en congé (DAY_ID).
- Combien de temps ils étaient hors service (TIME_ID).
- Qui était en congé (EMPLOYEE_ID).
- Leur raison d’être en congé, p.ex., maladie, vacances, rendez-vous chez le médecin, etc. (LEAVE_TYPE_ID).
Schéma Star vs Schéma Snowflake
Les entrepôts de données ci-dessus ont tous une disposition similaire. Cependant, ce n’est pas le seul moyen de les organiser.
Les deux schémas les plus couramment utilisés pour organiser les entrepôts de données sont star et snowflake. Les deux méthodes utilisent des tables de dimensions qui décrivent les informations contenues dans une table de faits.
Le schéma en étoile prend les informations de la table de faits et les divise en tables de dimensions dénormalisées. L’accent mis sur le schéma en étoile est mis sur la vitesse de requête. Une seule jointure est nécessaire pour lier les tables de faits à chaque dimension, il est donc facile d’interroger chaque table. Cependant, comme les tables sont dénormalisées, elles contiennent souvent des données répétées et redondantes.
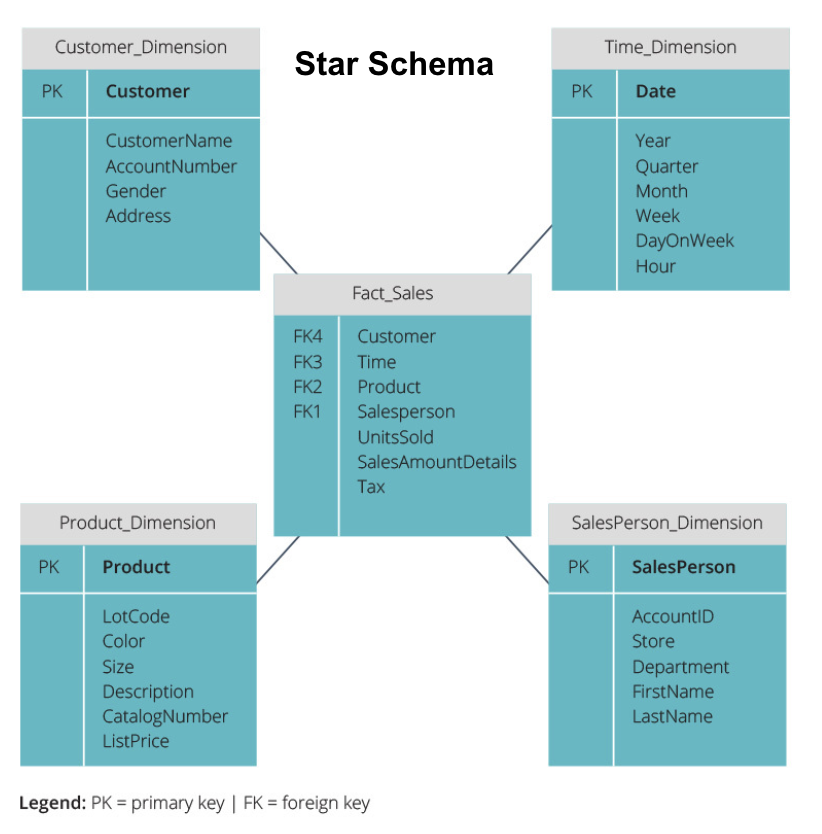
Le schéma snowflake divise la table de faits en une série de tables de dimensions normalisées. La normalisation crée plus de tables de dimensions et réduit ainsi les problèmes d’intégrité des données. Cependant, l’interrogation est plus difficile à l’aide du schéma Snowflake car vous avez besoin de plus de jointures de table pour accéder aux données pertinentes. Ainsi, vous avez moins de données redondantes, mais elles sont plus difficiles d’accès.
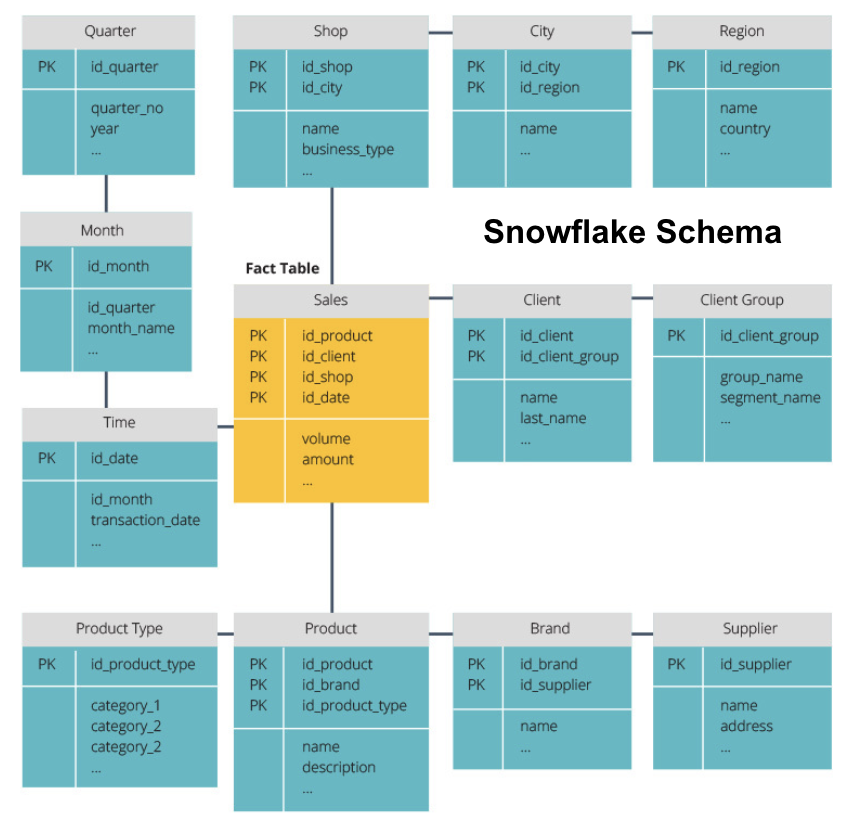
Nous allons maintenant expliquer quelques concepts plus fondamentaux d’entrepôt de données.
OLAP vs OLTP
Le traitement des transactions en ligne (OLTP) se caractérise par des transactions en écriture courte qui impliquent les applications frontales de l’architecture de données d’une entreprise. Les bases de données OLTP mettent l’accent sur le traitement rapide des requêtes et ne traitent que les données actuelles. Les entreprises les utilisent pour capturer des informations pour les processus métier et fournir des données source pour l’entrepôt de données.
Le traitement analytique en ligne (OLAP) vous permet d’exécuter des requêtes de lecture complexes et d’effectuer ainsi une analyse détaillée des données transactionnelles historiques. Les systèmes OLAP aident à analyser les données dans l’entrepôt de données.
Architecture à trois niveaux
Les entrepôts de données traditionnels sont généralement structurés en trois niveaux:
- Niveau inférieur : Un serveur de base de données, généralement un SGBDR, qui extrait des données de différentes sources à l’aide d’une passerelle. Les sources de données introduites dans ce niveau comprennent les bases de données opérationnelles et d’autres types de données frontales telles que les fichiers CSV et JSON.
- Niveau intermédiaire : Un serveur OLAP qui
- implémente directement les opérations, ou
- Mappe les opérations sur des données multidimensionnelles aux opérations relationnelles standard, par exemple, aplatir des données XML ou JSON en lignes dans des tables.
- Niveau supérieur : Les outils d’interrogation et de reporting pour l’analyse des données et la business intelligence.
Entrepôt de données virtuel /Data Mart
L’entrepôt de données virtuel utilise des requêtes distribuées sur plusieurs bases de données, sans intégrer les données dans un entrepôt de données physique.
Les Data marts sont des sous-ensembles d’entrepôts de données orientés pour des fonctions commerciales spécifiques, telles que les ventes ou la finance. Un entrepôt de données combine généralement des informations provenant de plusieurs data marts dans plusieurs fonctions métier. Pourtant, un data mart contient des données provenant d’un ensemble de systèmes sources pour une fonction métier.
Kimball vs. Inmon
Il existe deux approches de conception d’entrepôt de données, proposées par Bill Inmon et Ralph Kimball. Bill Inmon est un informaticien américain reconnu comme le père de l’entrepôt de données. Ralph Kimball est l’un des architectes originaux de l’entreposage de données et a écrit plusieurs livres sur le sujet.
Les deux experts avaient des opinions contradictoires sur la manière dont les entrepôts de données devaient être structurés. Ce conflit a donné naissance à deux écoles de pensée.
L’approche Inmon est une conception descendante. Avec la méthodologie Inmon, l’entrepôt de données est créé en premier et est considéré comme la composante centrale de l’environnement analytique. Les données sont ensuite résumées et distribuées de l’entrepôt centralisé à un ou plusieurs magasins de données dépendants.
L’approche Kimball prend une vue ascendante de la conception de l’entrepôt de données. Dans cette architecture, une organisation crée des magasins de données distincts, qui fournissent des vues sur des départements uniques au sein d’une organisation. L’entrepôt de données est la combinaison de ces data marts.
ETL vs ELT
Extraire, transformer, charger (ETL) décrit le processus d’extraction des données des systèmes sources (généralement des systèmes transactionnels), de conversion des données dans un format ou une structure adapté à l’interrogation et à l’analyse, et enfin de les charger dans l’entrepôt de données. ETL exploite une base de données intermédiaire distincte et applique une série de règles ou de fonctions aux données extraites avant le chargement.
Extraire, Charger, Transformer (ELT) est une approche différente du chargement de données. ELT prend les données de sources disparates et les charge directement dans le système cible, tel que l’entrepôt de données. Le système transforme ensuite les données chargées à la demande pour permettre l’analyse.
ELT offre un chargement plus rapide que l’ETL, mais il nécessite un système puissant pour effectuer les transformations de données à la demande.
Entrepôt de données d’entreprise
Un entrepôt de données d’entreprise est conçu comme un entrepôt unifié et centralisé contenant toutes les informations transactionnelles de l’organisation, à la fois actuelles et historiques. Un entrepôt de données d’entreprise doit intégrer des données de tous les domaines liés à l’entreprise, tels que le marketing, les ventes, les finances et les ressources humaines.
Ce sont les idées fondamentales qui composent les entrepôts de données traditionnels. Maintenant, regardons ce que les entrepôts de données en nuage ont ajouté en plus d’eux.
Concepts d’entrepôt de données en nuage
Les entrepôts de données en nuage sont nouveaux et en constante évolution. Pour mieux comprendre leurs concepts fondamentaux, il est préférable de se renseigner sur les principales solutions d’entrepôt de données dans le cloud.
Amazon Redshift, Google BigQuery et Panoply sont les trois principales solutions d’entrepôt de données dans le cloud. Ci-dessous, nous expliquons les concepts fondamentaux de chacun de ces services pour vous fournir une compréhension générale du fonctionnement des entrepôts de données modernes.
Concepts d’entrepôt de données Cloud – Amazon Redshift
Les concepts suivants sont explicitement utilisés dans l’entrepôt de données Amazon Redshift cloud, mais peuvent s’appliquer à d’autres solutions d’entrepôt de données à l’avenir basées sur l’infrastructure Amazon.
Clusters
Amazon Redshift base son architecture sur des clusters. Un cluster est simplement un groupe de ressources informatiques partagées, appelées nœuds.
Nœuds
Les nœuds sont des ressources informatiques dotées d’un processeur, d’une RAM et d’un espace disque dur. Un cluster contenant deux nœuds ou plus est composé d’un nœud leader et de nœuds de calcul.
Les nœuds leaders communiquent avec les programmes clients et compilent du code pour exécuter des requêtes, en l’affectant aux nœuds de calcul. Les nœuds de calcul exécutent les requêtes et renvoient les résultats au nœud leader. Un nœud de calcul exécute uniquement les requêtes qui référencent les tables stockées sur ce nœud.
Partitions/ Tranches
Amazon divise chaque nœud de calcul en tranches. Une tranche reçoit une allocation de mémoire et d’espace disque sur le nœud. Plusieurs tranches fonctionnent en parallèle pour accélérer le temps d’exécution des requêtes.
Stockage en colonnes
Redshift utilise le stockage en colonnes, permettant de meilleures performances de requête analytique. Au lieu de stocker les enregistrements dans des lignes, il stocke les valeurs d’une seule colonne pour plusieurs lignes. Les diagrammes suivants rendent cela plus clair:
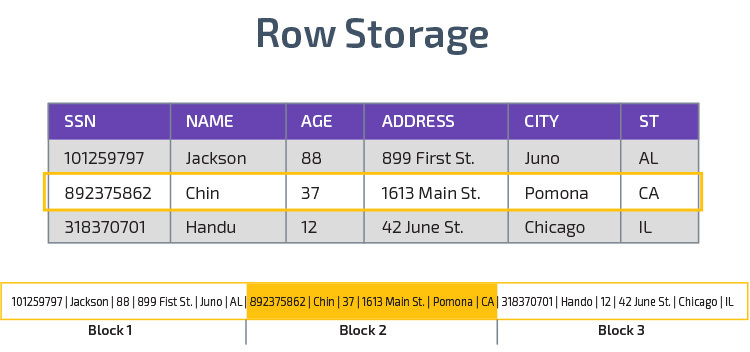
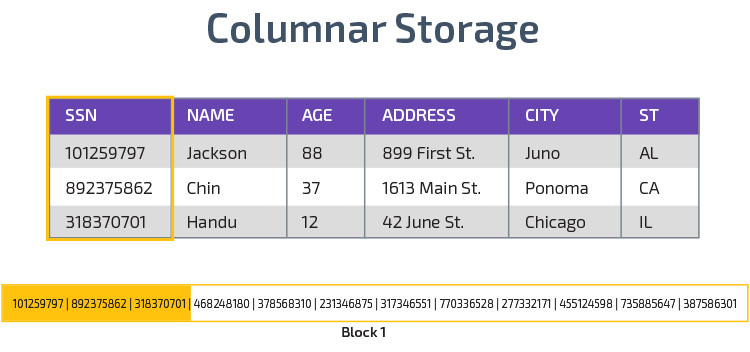
Le stockage en colonnes permet de lire les données plus rapidement, ce qui est crucial pour les requêtes analytiques couvrant plusieurs colonnes d’un ensemble de données. Le stockage en colonnes prend également moins d’espace disque, car chaque bloc contient le même type de données, ce qui signifie qu’il peut être compressé dans un format spécifique.
Compression
La compression réduit la taille des données stockées. En décalage vers le rouge, en raison de la façon dont les données sont stockées, la compression se produit au niveau de la colonne. Redshift vous permet de compresser les informations manuellement lors de la création d’une table, ou automatiquement à l’aide de la commande COPIER.
Chargement des données
Vous pouvez utiliser la commande COPY de Redshift pour charger de grandes quantités de données dans l’entrepôt de données. La commande COPY tire parti de l’architecture MPP de Redshift pour lire et charger des données en parallèle à partir de fichiers sur Amazon S3, d’une table DynamoDB ou d’une sortie de texte à partir d’un ou plusieurs hôtes distants.
Il est également possible de diffuser des données dans Redshift à l’aide du service Amazon Kinesis Firehose.
Entrepôt de données Cloud – Google BigQuery
Les concepts suivants sont explicitement utilisés dans l’entrepôt de données cloud de Google BigQuery, mais peuvent s’appliquer à d’autres solutions à l’avenir basées sur l’infrastructure Google.
Service sans serveur
BigQuery utilise une architecture sans serveur. Avec BigQuery, les entreprises n’ont pas besoin de gérer des unités de serveur physiques pour exécuter leurs entrepôts de données. Au lieu de cela, BigQuery gère dynamiquement l’allocation de ses ressources informatiques. Les entreprises utilisant le service paient simplement le stockage de données par gigaoctet et les requêtes par téraoctet.
Système de fichiers Colossus
BigQuery utilise la dernière version du système de fichiers distribué de Google, nom de code Colossus. Le système de fichiers Colossus utilise des algorithmes de stockage et de compression en colonnes pour stocker de manière optimale les données à des fins d’analyse.
Moteur d’exécution Dremel
Le moteur d’exécution Dremel utilise une disposition en colonnes pour interroger rapidement de vastes magasins de données. Le moteur d’exécution de Dremel peut exécuter des requêtes ad hoc sur des milliards de lignes en quelques secondes car il utilise un traitement massivement parallèle sous la forme d’une architecture arborescente.
L’architecture arborescente distribue les requêtes entre plusieurs serveurs intermédiaires à partir d’un serveur racine. Les serveurs intermédiaires poussent la requête vers des serveurs feuilles (contenant des données stockées), qui analysent les données en parallèle. Sur le chemin du retour dans l’arborescence, chaque serveur feuille envoie des résultats de requête et les serveurs intermédiaires effectuent une agrégation parallèle de résultats partiels.
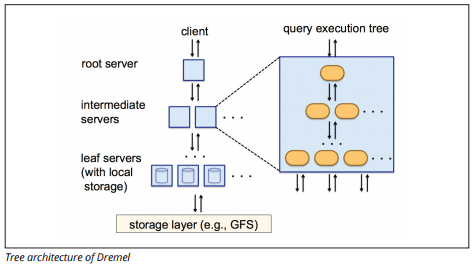
Source d’image
Dremel permet aux organisations d’exécuter des requêtes sur des dizaines de milliers de serveurs simultanément. Selon Google, Dremel peut scanner 35 milliards de lignes sans index en quelques dizaines de secondes.
Partage de données
L’architecture sans serveur de Google BigQuery permet aux entreprises de partager facilement des données avec d’autres organisations sans obliger ces organisations à investir dans leur propre stockage.
Les organisations qui souhaitent interroger des données partagées peuvent le faire, et elles ne paieront que pour les requêtes. Il n’est pas nécessaire de créer des silos de données partagés coûteux, externes à l’infrastructure de données de l’organisation, et de copier les données dans ces silos.
Diffusion en continu et ingestion par lots
Il est possible de charger des données dans BigQuery à partir du stockage Google Cloud, y compris des fichiers CSV, JSON (délimités par une nouvelle ligne) et Avro, ainsi que des sauvegardes de banques de données Google Cloud. Vous pouvez également charger des données directement à partir d’une source de données lisible.
BigQuery propose également une API de streaming pour charger des données dans le système à une vitesse de millions de lignes par seconde sans effectuer de chargement. Les données sont disponibles pour analyse presque immédiatement.
Concepts d’entrepôt de données Cloud – Panoply
Panoply est un entrepôt tout-en-un qui combine ETL avec un entrepôt de données puissant. C’est le moyen le plus simple de synchroniser, de stocker et d’accéder aux données d’une entreprise en éliminant le développement et le codage associés à la transformation, à l’intégration et à la gestion des mégadonnées.
Voici quelques-uns des principaux concepts de l’entrepôt de données Panoply liés à la modélisation des données et à la protection des données.
Clés primaires
Les clés primaires garantissent que toutes les lignes de vos tables sont uniques. Chaque table possède une ou plusieurs clés primaires qui définissent ce qui représente une seule ligne unique dans la base de données. Toutes les API ont une clé primaire par défaut pour les tables.
Clés incrémentales
Panoply utilise une clé incrémentale pour contrôler les attributs permettant de charger progressivement des données dans l’entrepôt de données à partir de sources plutôt que de recharger l’ensemble de données entier chaque fois que quelque chose change. Cette fonctionnalité est utile pour les ensembles de données plus volumineux, qui peuvent prendre beaucoup de temps à lire des données principalement inchangées. La clé incrémentale indique le dernier point de mise à jour des lignes de cette source de données.
Données imbriquées
Les données imbriquées ne sont pas entièrement compatibles avec les suites BI et les requêtes SQL standard – Panoply traite les données imbriquées en utilisant un modèle fortement relationnel qui n’autorise pas les valeurs imbriquées. Panoply transforme les données imbriquées de ces manières:
- Sous-tables : Par défaut, Panoply transforme les données imbriquées en un ensemble de tables de relations plusieurs à plusieurs ou un à plusieurs, qui sont des tables relationnelles plates.
- Aplatissement : Lorsque ce mode est activé, Panoply aplatit la structure imbriquée sur l’enregistrement qui la contient.
Tables d’historique
Parfois, vous devez analyser les données en gardant une trace de l’évolution des données au fil du temps pour voir exactement comment les données changent (par exemple, les adresses des personnes).
Pour effectuer de telles analyses, Panoply utilise des tables d’historique, qui sont des tables de séries chronologiques contenant des instantanés historiques de chaque ligne de la table statique d’origine. Vous pouvez ensuite effectuer une interrogation simple de la table d’origine ou des révisions de la table en rembobinant à tout moment.
Transformations
Panoply utilise ELT, qui est une variante du processus d’intégration de données ETL d’origine. Une fois que vous avez injecté des données de la source dans votre entrepôt de données, Panoply les transforme immédiatement. Ce processus vous offre une analyse des données en temps réel et des performances optimales par rapport au processus ETL standard.
Formats de chaîne
Panoply analyse les formats de chaîne et les gère comme s’il s’agissait d’objets imbriqués dans les données d’origine. Les formats de chaîne pris en charge sont CSV, TSV, JSON, JSON-Line, le format d’objet Ruby, les chaînes de requête d’URL et les journaux de distribution Web.
Protection des données
Panoply est construit sur AWS, il dispose donc des derniers correctifs de sécurité et fonctionnalités de cryptage fournis par AWS, y compris le cryptage RSA accéléré par le matériel et l’ensemble spécifique de fonctionnalités de sécurité d’Amazon Redshift.
Une protection supplémentaire provient du cryptage en colonnes, qui vous permet d’utiliser vos clés privées qui ne sont pas stockées sur les serveurs de Panoply.
Contrôle d’accès
Panoply utilise une vérification en deux étapes pour empêcher les accès non autorisés, et un système d’autorisation vous permet de restreindre l’accès à des tables, des vues ou des colonnes spécifiques. La détection d’anomalies identifie les requêtes provenant de nouveaux ordinateurs ou d’un pays différent, ce qui vous permet de bloquer ces requêtes à moins qu’elles ne reçoivent une approbation manuelle.
Liste blanche IP
Nous vous recommandons de bloquer les connexions provenant de sources non reconnues à l’aide d’un pare-feu ou d’un groupe de sécurité AWS et de mettre en liste blanche la plage d’adresses IP que les sources de données de Panoply utilisent toujours lors de l’accès à votre base de données.
Conclusion: Concepts d’entrepôt de données traditionnels en bref
Pour conclure, nous résumerons les concepts introduits dans ce document.
Concepts traditionnels d’entrepôt de données
- Faits et mesures: une mesure est une propriété sur laquelle des calculs peuvent être effectués. Nous désignons un ensemble de mesures comme des faits, mais parfois les termes sont utilisés de manière interchangeable.
- Normalisation: le processus de réduction de la quantité de données en double, ce qui conduit à un entrepôt de données plus efficace en mémoire et plus lent à interroger.Dimension
- : Utilisée pour catégoriser et contextualiser les faits et les mesures, ce qui permet d’analyser et de rendre compte de ces mesures.
- Modèle de données conceptuel : Définit les entités de données critiques de haut niveau et les relations entre elles.
- Modèle de données logiques: Décrit les relations de données, les entités et les attributs en anglais clair sans se soucier de la façon de les implémenter dans le code.
- Modèle de données physiques : Représentation de la mise en œuvre de la conception de données dans un système de gestion de base de données spécifique.
- Schéma en étoile : Prend une table de faits et divise ses informations en tables de dimensions dénormalisées.
- Schéma Flocon de neige : Divise la table de faits en tables de dimensions normalisées. La normalisation réduit les problèmes de redondance des données et améliore l’intégrité des données, mais les requêtes sont plus complexes.
- OLTP: Les systèmes de traitement des transactions en ligne facilitent un traitement rapide et orienté vers les transactions avec des requêtes simples.
- OLAP: Le traitement analytique en ligne vous permet d’exécuter des requêtes de lecture complexes et ainsi d’effectuer une analyse détaillée des données transactionnelles historiques.
- Data mart: une archive de données se concentrant sur un sujet ou un département spécifique au sein d’une organisation.
- Approche Inmon: L’approche de l’entrepôt de données de Bill Inmon définit l’entrepôt de données comme le référentiel de données centralisé pour l’ensemble de l’entreprise. Les Data marts peuvent être construits à partir de l’entrepôt de données pour répondre aux besoins analytiques des différents départements.
- Approche Kimball: Ralph Kimball décrit un entrepôt de données comme la fusion de marchés de données critiques, qui sont d’abord créés pour répondre aux besoins analytiques des différents départements.
- ETL : Intègre les données dans l’entrepôt de données en les extrayant de diverses sources transactionnelles, en transformant les données pour les optimiser en vue de leur analyse, et enfin en les chargeant dans l’entrepôt de données.
- ELT: Une variante d’ETL qui extrait les données brutes des sources de données d’une organisation et les charge dans l’entrepôt de données. En cas de besoin, il est transformé à des fins d’analyse.
- Entrepôt de données d’entreprise: L’EDW consolide les données de tous les domaines liés à l’entreprise.
Concepts d’entrepôt de données dans le Cloud – Amazon Redshift à titre d’exemple
- Cluster : Un groupe de ressources informatiques partagées basées dans le cloud.Nœud
- : Ressource informatique contenue dans un cluster. Chaque nœud dispose de son propre processeur, de sa RAM et de son espace disque dur.
- Stockage en colonnes: Cela stocke les valeurs d’une table en colonnes plutôt qu’en lignes, ce qui optimise les données pour les requêtes agrégées.
- Compression: Techniques pour réduire la taille des données stockées.
- Chargement des données : Récupération des données des sources dans l’entrepôt de données basé sur le cloud. Dans Redshift, vous pouvez utiliser la commande COPIER ou un service de streaming de données.
Concepts d’entrepôt de données dans le Cloud – BigQuery par exemple
- Service sans serveur: Le fournisseur de cloud gère dynamiquement l’allocation des ressources de la machine en fonction de la quantité consommée par l’utilisateur. Le fournisseur de cloud cache aux utilisateurs du service les décisions de gestion du serveur et de planification de la capacité.
- Système de fichiers Colossus: Un système de fichiers distribué qui utilise des algorithmes de stockage en colonnes et de compression de données pour optimiser les données pour l’analyse.
- Moteur d’exécution Dremel : Un moteur de requête qui utilise un traitement massivement parallèle et un stockage en colonnes pour exécuter rapidement des requêtes.
- Partage de données : Dans un service sans serveur, il est pratique d’interroger les données partagées d’une autre organisation sans investir dans le stockage de données — vous payez simplement pour les requêtes.
- Streaming de données : Insertion de données en temps réel dans l’entrepôt de données sans effectuer de chargement. Vous pouvez diffuser des données dans des requêtes par lots, qui sont plusieurs appels d’API combinés en une seule requête HTTP.
Analyse Coûts-avantages traditionnelle vs Cloud
| Coût / avantage | Traditionnel | Cloud |
| Coût | Coût initial élevé pour l’achat et l’installation d’un système sur site. Vous avez besoin de matériel, de salles de serveurs et de personnel spécialisé (que vous payez en permanence). Si vous n’êtes pas sûr de l’espace de stockage dont vous avez besoin, il existe un risque de coûts irrécupérables élevés et difficiles à récupérer. |
Pas besoin d’acheter du matériel, des salles de serveurs ou d’embaucher des spécialistes. Aucun risque de coûts irrécupérables – il est facile d’acheter plus de stockage à l’avenir. De plus, le coût du stockage et de la puissance de calcul diminuent avec le temps. |
| Évolutivité | Une fois que vous maximisez la capacité de vos salles de serveurs ou de votre matériel actuel, vous devrez peut-être acheter du nouveau matériel et construire / acheter plus d’endroits pour l’héberger. De plus, vous devez acheter suffisamment de stockage pour faire face aux heures de pointe; ainsi, la plupart du temps, la majeure partie de votre stockage n’est pas utilisée. |
Vous pouvez facilement acheter plus de stockage au fur et à mesure que vous en avez besoin. Ont souvent juste à payer pour ce que vous utilisez, donc il y a peu ou pas de risque de trop payer. |
| Intégrations | Comme le cloud computing est la norme, la plupart des intégrations que vous souhaitez effectuer concerneront des services cloud. Y connecter votre entrepôt de données personnalisé peut s’avérer difficile. |
Comme les entrepôts de données dans le cloud sont déjà dans le cloud, la connexion à une gamme d’autres services cloud est simple. |
| Sécurité | Vous avez le contrôle total de votre entrepôt de données. En comparant la quantité de données que vous hébergez à Amazon ou Google, vous êtes une cible plus petite pour les voleurs. Donc, vous risquez peut-être d’être laissé seul. |
Les fournisseurs d’entrepôts de données Cloud disposent d’équipes d’ingénieurs en sécurité hautement qualifiés dont le seul but est de rendre leur produit aussi sûr que possible. Les entreprises les plus en vue dans le monde les gèrent et mettent donc en œuvre des pratiques de sécurité de classe mondiale. |
| Gouvernance | Vous savez exactement où se trouvent vos données et pouvez y accéder localement. Moins de risques que des données hautement sensibles enfreignent la loi par inadvertance, par exemple en voyageant à travers le monde sur un serveur cloud. |
Les principaux fournisseurs d’entrepôts de données dans le cloud s’assurent qu’ils sont conformes aux lois sur la gouvernance et la sécurité, telles que le RGPD. De plus, ils aident votre entreprise à s’assurer que vous êtes conforme. Il y a eu des problèmes concernant la connaissance exacte de vos données et de leur emplacement. Ces problèmes sont activement abordés et résolus. Notez que le stockage de grandes quantités de données hautement sensibles sur le cloud peut être contraire à des lois spécifiques. Il s’agit d’un cas où le cloud computing peut être inapproprié pour votre entreprise. |
| Fiabilité | Si votre entrepôt de données sur site tombe en panne, il est de votre responsabilité de le réparer. Votre équipe informatique a accès au matériel physique et peut accéder à chaque couche logicielle pour résoudre les problèmes. Cet accès rapide peut rendre la résolution des problèmes beaucoup plus rapide. Cependant, il n’y a aucune garantie que votre entrepôt aura un temps de disponibilité particulier chaque année. |
Les fournisseurs d’entrepôts de données dans le Cloud garantissent leur fiabilité et leur disponibilité dans leurs SLA. Ils fonctionnent sur des systèmes massivement distribués dans le monde entier, donc s’il y a une défaillance sur l’un d’eux, il est très peu probable que cela vous affecte. |
| Contrôle | Votre entrepôt de données est construit sur mesure pour répondre à vos besoins. En théorie, il fait ce que vous voulez qu’il fasse, quand vous le voulez, d’une manière que vous comprenez. | Vous n’avez pas le contrôle total sur votre entrepôt de données. Cependant, la majorité du temps, le contrôle que vous avez est plus que suffisant. |
| Vitesse | Si vous êtes une petite entreprise dans un même lieu géographique avec une petite quantité de données, votre traitement des données sera plus rapide. Cependant, nous parlons de millisecondes contre secondes pour que certains processus se terminent. Il est peu probable qu’une grande entreprise opérant dans plusieurs pays enregistre des gains de vitesse significatifs avec un système sur site. |
Les fournisseurs de cloud ont investi et créé des systèmes qui implémentent un traitement massivement parallèle (MPP), des moteurs d’architecture et d’exécution personnalisés et des algorithmes de traitement de données intelligents. Les entrepôts de données cloud sont le résultat d’années de recherche et de tests pour créer des ressources optimisées pour la vitesse et les performances. Il peut être légèrement plus lent que sur site dans certains cas, mais ces retards sont souvent négligeables pour l’homme (secondes vs millisecondes). |
Panoply est un endroit sécurisé pour stocker, synchroniser et accéder à toutes vos données professionnelles. Panoply peut être configuré en quelques minutes, ne nécessite aucune maintenance continue et fournit un support en ligne, y compris l’accès à des architectes de données expérimentés. Essayez Panoply gratuitement pendant 14 jours.
En savoir plus sur les Entrepôts de données
- Architecture d’entrepôt de données : Traditionnel vs Cloud
- Base de données vs Entrepôt de données
- Data Mart vs Entrepôt de données