Indexation Secondaire distribuée évolutive dans Scylla

Le modèle de données dans Scylla et Apache Cassandra partitionne les données entre les nœuds de cluster à l’aide d’une clé de partition, définie par le schéma de base de données. L’utilisation d’une clé de partition fournit un moyen efficace de rechercher des lignes à l’aide de la clé de partition, car vous pouvez trouver le nœud propriétaire de la ligne en hachant la clé de partition. Malheureusement, cela signifie également que la recherche d’une ligne à l’aide d’une clé non-partition nécessite une analyse complète de la table, ce qui est inefficace. Les index secondaires sont un mécanisme dans Apache Cassandra qui permet des recherches efficaces sur des clés non-partition en créant un index.
Dans cet article de blog, vous apprendrez:
- Comment Apache Cassandra implémente les Index secondaires en utilisant l’indexation locale
- Pourquoi nous avons décidé d’adopter une stratégie d’implémentation différente pour Scylla en utilisant l’indexation globale
- Comment l’indexation globale affecte la façon dont vous devez utiliser l’Indexation Secondaire
- Comment créer vos propres Index Secondaires et les utiliser dans vos requêtes CQL d’application
Contexte
La taille d’un index est proportionnelle à la taille des données indexées. Comme les données dans Scylla et Apache Cassandra sont distribuées à plusieurs nœuds, il n’est pas pratique de stocker l’index entier sur un seul nœud. Apache Cassandra implémente des index secondaires en tant qu’index locaux, ce qui signifie que l’index est stocké sur le même nœud que les données indexées à partir de ce nœud. L’avantage d’un index local est que les écritures sont très rapides, mais l’inconvénient est que les lectures doivent potentiellement interroger chaque nœud pour trouver l’index sur lequel effectuer une recherche, ce qui rend les index locaux non scalables pour les grands clusters. En plus des index secondaires natifs, Apache Cassandra dispose également d’un autre schéma d’indexation local, SSTABLE Attached Secondary Index (SASI), qui prend en charge les requêtes et les recherches complexes. Cependant, du point de vue de l’évolutivité, il présente exactement les mêmes caractéristiques que les index secondaires d’origine.
Les vues matérialisées dans Scylla et Apache Cassandra sont un mécanisme permettant de dénormaliser automatiquement les données d’une table de base vers une table de vue à l’aide d’une clé de partition différente. Cela résout le problème d’évolutivité des index locaux, mais a un coût de stockage car vous devez dupliquer la table entière dans le pire des cas. Les vues matérialisées ne remplacent donc pas les index secondaires pour tous les cas d’utilisation. Cependant, les vues matérialisées fournissent l’infrastructure nécessaire pour implémenter des index secondaires en utilisant l’indexation globale, qui est l’approche de mise en œuvre adoptée pour Scylla.
Indexation globale
Scylla adopte une approche différente d’Apache Cassandra et implémente des index secondaires à l’aide d’une indexation globale. Avec l’indexation globale, une vue matérialisée est créée pour chaque index. La vue matérialisée a la colonne indexée comme clé de partition et la clé primaire (clé de partition et clés de clustering) de la ligne indexée comme clés de clustering. Scylla divise les requêtes indexées en deux parties : (1) une requête sur la table d’index pour récupérer les clés de partition de la table indexée et (2) une requête sur la table indexée à l’aide des clés de partition récupérées. L’avantage de cette approche est que nous pouvons utiliser la valeur de la colonne indexée pour trouver la ligne de table d’index correspondante dans le cluster afin que les lectures soient évolutives. L’inconvénient de l’approche est que les écritures sont plus lentes qu’avec l’indexation locale en raison de toute la surcharge liée à la mise à jour de la vue d’index.
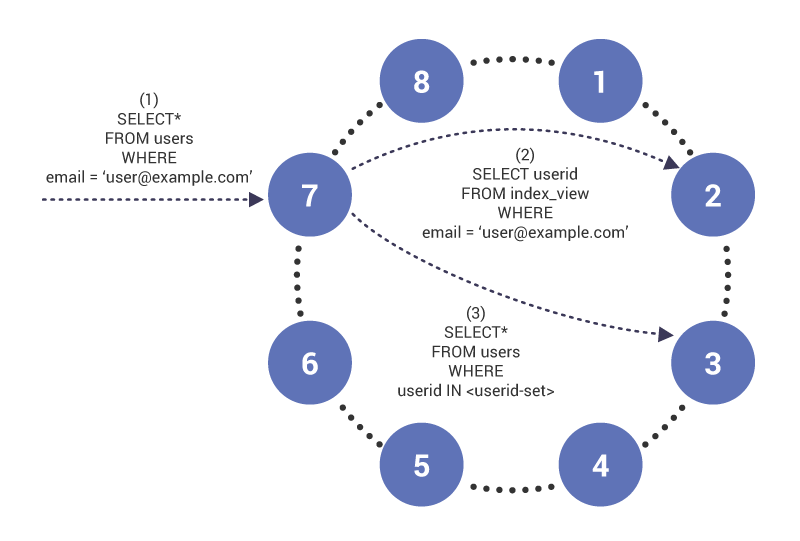
L’interrogation sur une colonne indexée se présente comme suit. Supposons une table qui ressemble à ceci:
Et une requête sur la colonne email, qui n’est pas une clé de partition, mais a un index:
Dans la phase (1), la requête arrive sur le noeud 7, qui joue le rôle de coordinateur de la requête. Le nœud remarque que nous interrogeons sur une colonne indexée et, par conséquent, en phase (2), émet une table d’index de lecture sur le nœud 2, qui a la ligne de la table d’index pour “”. La requête renvoie un ensemble d’ID utilisateur qui sont utilisés dans la phase (3) pour récupérer le contenu de la table indexée.
Exemple
Nous devons d’abord créer un schéma. Dans cet exemple, nous avons une table qui représente les informations utilisateur avec l’ID utilisateur comme clé de partition et le nom, l’e-mail et le pays comme colonnes régulières :
Nous remplissons ensuite la table avec des données de test générées avec Mockaroo:Les index secondaires
sont conçus pour permettre une interrogation efficace des colonnes de clés non-partition. Bien qu’Apache Cassandra prenne également en charge les requêtes sur des colonnes de clé non-partition en utilisant ALLOW FILTERING, cela est très inefficace (nécessitant une analyse de la table entière) et n’est actuellement pas pris en charge par Scylla (voir le numéro #2200 pour plus de détails).
Vous pouvez indexer des colonnes de table à l’aide de l’instruction CREATE INDEX. Par exemple, pour créer des index pour les colonnes email et country, exécutez les instructions CQL suivantes:
Scylla crée automatiquement une vue matérialisée qui a la colonne indexée comme clé de partition et la clé primaire de la table cible (clé de partition et clés de clustering) comme clés de clustering.
Par exemple, la vue matérialisée pour l’index de la colonne email se présente comme suit :
Si la vue ci-dessus était créée en tant que table régulière, elle se présenterait effectivement comme suit:
La colonne email est utilisée comme clé de partition pour la table d’index et userid est incluse comme clé de clustering, ce qui nous permet de trouver efficacement les clés de partition pour la table cible en utilisant seulement email.
Vous pouvez utiliser la commande DESCRIBE pour voir l’ensemble du schéma de la table ks.users, y compris les index et les vues créés:
Maintenant que l’index secondaire est en place, vous pouvez interroger les colonnes indexées comme s’il s’agissait de clés de partition:
Nous avons terminé avec l’exemple!
Quand utiliser des index secondaires ?
Les index secondaires sont (pour la plupart) transparents pour l’application. Les requêtes ont accès à toutes les colonnes de la table et vous pouvez ajouter et supprimer des index sans modifier l’application. Les index secondaires peuvent également avoir moins de surcharge de stockage que les Vues Matérialisées, car les index secondaires n’ont besoin que de dupliquer la colonne indexée et la clé primaire, pas les colonnes interrogées comme avec une Vue matérialisée. De plus, pour la même raison, les mises à jour peuvent être plus efficaces avec les index secondaires car seules les modifications de la clé primaire et de la colonne indexée provoquent une mise à jour dans la vue d’index. Dans le cas d’une vue matérialisée, une mise à jour de l’une des colonnes qui apparaissent dans la vue nécessite que la vue de sauvegarde soit mise à jour.
Comme toujours, la décision d’utiliser des Index secondaires ou des Vues Matérialisées dépend vraiment des exigences de votre application. Si vous avez besoin de performances maximales et que vous êtes susceptible d’interroger un ensemble spécifique de colonnes, vous devez utiliser des vues matérialisées. Cependant, si l’application doit interroger différents ensembles de colonnes, les index secondaires sont un meilleur choix car ils peuvent être ajoutés et supprimés avec moins de surcharge de stockage en fonction des besoins de l’application.
Vous voulez en savoir plus sur les index secondaires ? Découvrez ma présentation du Scylla Summit 2017 sur SlideShare. Si vous souhaitez essayer cette fonctionnalité, elle devrait figurer dans la prochaine version de Scylla 2.2.