La coque concave
Création d’une bordure de cluster à l’aide d’une approche K-voisins les plus proches
Il y a quelques mois, j’ai écrit ici sur Medium un article sur la cartographie des points chauds des accidents de la route au Royaume-Uni. J’étais surtout préoccupé par l’illustration de l’utilisation de l’algorithme de clustering DBSCAN sur des données géographiques. Dans l’article, j’ai utilisé des informations géographiques publiées par le gouvernement britannique sur les accidents de la circulation signalés. Mon but était d’exécuter un processus de regroupement basé sur la densité pour trouver les zones où les accidents de la circulation sont les plus fréquemment signalés. Le résultat final a été la création d’un ensemble de géo-clôtures représentant ces points chauds de l’accident.
En collectant tous les points d’un cluster donné, vous pouvez avoir une idée de l’apparence du cluster sur une carte, mais il vous manquera une information importante: la forme extérieure du cluster. Dans ce cas, nous parlons d’un polygone fermé qui peut être représenté sur une carte comme une géo-clôture. Tout point à l’intérieur de la géo-clôture peut être supposé appartenir au cluster, ce qui fait de cette forme une information intéressante: vous pouvez l’utiliser comme fonction discriminatrice. Tous les points nouvellement échantillonnés qui se trouvent à l’intérieur du polygone peuvent être supposés appartenir au cluster correspondant. Comme je l’ai laissé entendre dans l’article, vous pouvez utiliser de tels polygones pour affirmer votre risque de conduite, en les utilisant pour classer votre propre position GPS échantillonnée.
La question est maintenant de savoir comment créer un polygone significatif à partir d’un nuage de points qui composent un cluster spécifique. Mon approche dans le premier article était quelque peu naïve et reflétait une solution que j’avais déjà utilisée dans le code de production. Cette solution consistait à placer un cercle centré sur chacun des points du cluster, puis à fusionner tous les cercles pour former un polygone en forme de nuage. Le résultat n’est pas très joli, ni réaliste. De plus, en utilisant des cercles comme forme de base pour la construction du polygone final, ceux-ci auront plus de points qu’une forme plus profilée, augmentant ainsi les coûts de stockage et rendant les algorithmes de détection d’inclusion plus lents à exécuter.

D’autre part, cette approche a l’avantage d’être simple sur le plan des calculs (du moins du point de vue du développeur), car elle utilise la fonction cascaded_union de Shapely pour fusionner tous les cercles ensemble. Un autre avantage est que la forme du polygone est implicitement définie en utilisant tous les points du cluster.
Pour des approches plus sophistiquées, nous devons en quelque sorte identifier les points de bordure du cluster, ceux qui semblent définir la forme du nuage de points. Fait intéressant, avec certaines implémentations DBSCAN, vous pouvez réellement récupérer les points de bordure en tant que sous-produit du processus de clustering. Malheureusement, ces informations ne sont (apparemment) pas disponibles sur la mise en œuvre de SciKit Learn, nous devons donc nous débrouiller.
La première approche qui m’est venue à l’esprit a été de calculer la coque convexe de l’ensemble des points. C’est un algorithme bien compris mais qui souffre du problème de ne pas gérer les formes concaves, comme celui-ci:

Cette forme ne capture pas correctement l’essence des points sous-jacents. S’il était utilisé comme discriminateur, certains points seraient incorrectement classés comme étant à l’intérieur du cluster alors qu’ils ne le sont pas. Nous avons besoin d’une autre approche.
L’Alternative à la coque Concave
Heureusement, il existe des alternatives à cet état de fait : on peut calculer une coque concave. Voici à quoi ressemble la coque concave lorsqu’elle est appliquée au même ensemble de points que dans l’image précédente:

Ou peut-être celle-ci:
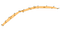
Comme vous pouvez le voir, et contrairement à la coque convexe, il n’y a pas de définition unique de ce qu’est la coque concave d’un ensemble de points. Avec l’algorithme que je présente ici, le choix de la concave que vous souhaitez que vos coques soient se fait à travers un seul paramètre: k — le nombre de voisins les plus proches pris en compte lors du calcul de la coque. Voyons comment cela fonctionne.
L’algorithme
L’algorithme que je présente ici a été décrit il y a plus de dix ans par Adriano Moreira et Maribel Yasmina Santos de l’Université du Minho, au Portugal. Extrait du résumé:
Cet article décrit un algorithme pour calculer l’enveloppe d’un ensemble de points dans un plan, qui génère des coques convexes sur des coques non convexes qui représentent l’aire occupée par les points donnés. L’algorithme proposé est basé sur une approche k-voisins les plus proches, où la valeur de k, le seul paramètre de l’algorithme, est utilisée pour contrôler la “douceur” de la solution finale.
Parce que je vais appliquer cet algorithme à l’information géographique, certaines modifications ont dû être apportées, notamment lors du calcul des angles et des distances. Mais ceux-ci ne modifient en rien l’essentiel de l’algorithme, qui peut être décrit de manière générale par les étapes suivantes:
- Trouvez le point avec la coordonnée y (latitude) la plus basse et faites-en le point actuel.
- Trouvez les points k-les plus proches du point actuel.
- Parmi les points k les plus proches, sélectionnez celui qui correspond au plus grand virage à droite de l’angle précédent. Ici, nous utiliserons le concept de roulement et commencerons par un angle de 270 degrés (plein Ouest).
- Vérifiez si en ajoutant le nouveau point à la chaîne de ligne croissante, il ne se croise pas lui-même. Si c’est le cas, sélectionnez un autre point dans le k-le plus proche ou redémarrez avec une valeur plus grande de k.
- Faites du nouveau point le point actuel et supprimez-le de la liste.
- Après k itérations, ajoutez le premier point à la liste.
- Boucle au numéro 2.
L’algorithme semble assez simple, mais il y a un certain nombre de détails qui doivent être pris en compte, notamment parce que nous avons affaire à des coordonnées géographiques. Les distances et les angles sont mesurés d’une manière différente.
Le Code
Que je publie ici est une version adaptée du code de l’article précédent. Vous trouverez toujours le même code de clustering et le même générateur de cluster en forme de nuage. La version mise à jour contient maintenant un paquet nommé geomath.hulls où vous pouvez trouver la classe ConcaveHull. Pour créer vos coques concaves, procédez comme suit:
Dans le code ci-dessus, points est un tableau de dimensions (N, 2), où les lignes contiennent les points observés et les colonnes contiennent les coordonnées géographiques (longitude, latitude). Le tableau résultant a exactement la même structure, mais ne contient que les points appartenant à la forme polygonale du cluster. Un filtre en quelque sorte.
Parce que nous allons gérer les tableaux, il est naturel d’amener NumPy dans la mêlée. Tous les calculs ont été dûment vectorisés, autant que possible, et des efforts ont été faits pour améliorer les performances lors de l’ajout et de la suppression d’éléments des tableaux (spoiler: ils ne sont pas du tout déplacés). L’une des améliorations manquantes est la parallélisation du code. Mais ça peut attendre.
J’ai organisé le code autour de l’algorithme tel qu’exposé dans l’article, bien que certaines optimisations aient été effectuées lors de la traduction. L’algorithme est construit autour d’un certain nombre de sous-programmes qui sont clairement identifiés par le document, alors éliminons-les maintenant. Pour votre confort de lecture, j’utiliserai les mêmes noms que ceux utilisés dans le papier.
CleanList — Le nettoyage de la liste des points est effectué dans le constructeur de classe:
Comme vous pouvez le voir, la liste des points est implémentée sous forme de tableau NumPy pour des raisons de performances. Le nettoyage de la liste est effectué sur la ligne 10, où seuls les points uniques sont conservés. Le tableau des ensembles de données est organisé avec des observations en lignes et des coordonnées géographiques dans les deux colonnes. Notez que je crée également un tableau booléen à la ligne 13 qui sera utilisé pour indexer dans le tableau principal de l’ensemble de données, facilitant la corvée de supprimer des éléments et, de temps en temps, de les ajouter. J’ai vu cette technique appelée “masque” sur la documentation NumPy, et elle est très puissante. Quant aux nombres premiers, j’en discuterai plus tard.
FindMinYPoint – Cela nécessite une petite fonction:
Cette fonction est appelée avec le tableau de jeu de données comme argument et renvoie l’indice du point avec la latitude la plus basse. Notez que les lignes sont codées avec la longitude dans la première colonne et la latitude dans la seconde.
RemovePoint
AddPoint — Il s’agit d’une évidence, en raison de l’utilisation du tableau indices. Ce tableau est utilisé pour stocker les indices actifs dans le tableau principal de l’ensemble de données, de sorte que la suppression d’éléments de l’ensemble de données est un jeu d’enfant.
Bien que l’algorithme décrit dans l’article appelle à ajouter un point au tableau qui compose la coque, cela est en fait implémenté comme:
Plus tard, la variable test_hull sera assignée à hull lorsque la chaîne de ligne est considérée comme ne se croisant pas. Mais je prends de l’avance ici. La suppression d’un point du tableau d’ensembles de données est aussi simple que:
self.indices = False
L’ajouter est juste une question de retourner cette valeur de tableau au même index à true. Mais toute cette commodité vient avec le prix de devoir garder un œil sur les indices. Plus à ce sujet plus tard.
Points proches — Les choses commencent à devenir intéressantes ici parce que nous ne traitons pas de coordonnées planes, donc avec Pythagore et avec Haversine:
Notez que les deuxième et troisième paramètres sont des tableaux au format de jeu de données : longitude dans la première colonne et latitude dans la seconde. Comme vous pouvez le voir, cette fonction renvoie un tableau de distances en mètres entre le point du deuxième argument et les points du troisième argument. Une fois que nous les avons, nous pouvons obtenir facilement les k-voisins les plus proches. Mais il y a une fonction spécialisée pour cela et cela mérite quelques explications:
La fonction commence par créer un tableau avec les indices de base. Ce sont les indices des points qui n’ont pas été supprimés du tableau d’ensembles de données. Par exemple, si sur un cluster de dix points, nous commencions par supprimer le premier point, le tableau des indices de base le serait. Ensuite, nous calculons les distances et trions les indices de tableau résultants. Les premiers k sont extraits puis utilisés comme masque pour récupérer les indices de base. C’est un peu tordu mais ça marche. Comme vous pouvez le voir, la fonction ne renvoie pas un tableau de coordonnées, mais un tableau d’indices dans le tableau d’ensembles de données.
SortByAngle — Il y a plus de problèmes ici parce que nous ne calculons pas des angles simples, nous calculons des roulements. Ceux-ci sont mesurés à zéro degré plein Nord, avec des angles augmentant dans le sens des aiguilles d’une montre. Voici le cœur du code qui calcule les roulements:
La fonction renvoie un tableau de roulements mesurés à partir du point dont l’indice est dans le premier argument, aux points dont les indices sont dans le troisième argument. Le tri est simple:
À ce stade, le tableau candidats contient les indices des k points les plus proches triés par ordre décroissant de roulement.
IntersectQ – Au lieu de rouler mes propres fonctions d’intersection de lignes, je me suis tourné vers Shapely pour obtenir de l’aide. En fait, lors de la construction du polygone, nous gérons essentiellement une chaîne de lignes, ajoutant des segments qui ne se croisent pas avec les précédents. Les tests pour cela sont simples: nous récupérons le tableau de coque en construction, le convertissons en un objet de chaîne de lignes galbées et testons s’il est simple (non auto-intersectant) ou non.
En un mot, une chaîne de lignes galbées devient complexe si elle s’auto-croise, de sorte que le prédicat is_simple devient faux. Facile.
PointInPolygon — Cela s’est avéré être le plus délicat à implémenter. Permettez-moi d’expliquer en regardant le code qui effectue la validation finale du polygone de coque (vérifie si tous les points du cluster sont inclus dans le polygone):
Les fonctions de Shapely pour tester l’intersection et l’inclusion auraient dû suffire pour vérifier si le polygone de coque final chevauche tous les points du cluster, mais ce n’était pas le cas. Pourquoi? Shapely est indépendant des coordonnées, il gérera donc les coordonnées géographiques exprimées en latitudes et longitudes exactement de la même manière que les coordonnées sur un plan cartésien. Mais le monde se comporte différemment lorsque vous vivez sur une sphère, et les angles (ou paliers) ne sont pas constants le long d’une géodésique. L’exemple de référence d’une ligne géodésique reliant Bagdad à Osaka illustre parfaitement cela. Il se trouve que dans certaines circonstances, l’algorithme peut inclure un point basé sur le critère de roulement, mais plus tard, en utilisant les algorithmes planaires de Shapely, être considéré comme si légèrement en dehors du polygone. C’est ce que fait la petite correction de distance là-bas.
Il m’a fallu un certain temps pour comprendre cela. Mon aide au débogage était QGIS, un excellent logiciel libre. À chaque étape des calculs suspects, je produirais les données au format WKT dans un fichier CSV à lire en tant que couche. Une vraie bouée de sauvetage !
Enfin, si le polygone ne couvre pas tous les points du cluster, la seule option est d’augmenter k et d’essayer à nouveau. Ici, j’ai ajouté un peu de ma propre intuition.
K premier
L’article suggère que la valeur de k soit augmentée de un et que l’algorithme soit à nouveau exécuté à partir de zéro. Mes premiers tests avec cette option n’étaient pas très satisfaisants: les temps d’exécution seraient lents sur les clusters problématiques. Cela était dû à la lente augmentation de k, j’ai donc décidé d’utiliser un autre calendrier d’augmentation: une table de nombres premiers. L’algorithme commence déjà avec k = 3, c’était donc une extension facile de le faire évoluer sur une liste de nombres premiers. C’est ce que vous voyez se produire dans l’appel récursif:
J’ai un faible pour les nombres premiers, vous savez
Explosion
Les polygones de coque concaves générés par cet algorithme nécessitent encore un traitement supplémentaire, car ils ne discrimineront que les points à l’intérieur de la coque, mais pas près de celle-ci. La solution consiste à ajouter un peu de rembourrage à ces grappes maigres. Ici, j’utilise exactement la même technique qu’auparavant, et voici à quoi cela ressemble:

Ici, j’ai utilisé la fonction buffer de Shapely pour faire l’affaire.
La fonction accepte un polygone galbé et renvoie une version gonflée d’elle-même. Le deuxième paramètre est le rayon en mètres du remplissage ajouté.
Exécution du code
Commencez par extraire le code du référentiel GitHub vers votre machine locale. Le fichier que vous souhaitez exécuter est ShowHotSpots.py dans le répertoire principal. Lors de la première exécution, le code lira les données sur les accidents de la circulation au Royaume-Uni de 2013 à 2016 et les regroupera. Les résultats sont ensuite mis en cache sous forme de fichier CSV pour les exécutions suivantes.
Deux cartes vous seront alors présentées: la première est générée à l’aide des clusters en forme de nuage tandis que la seconde utilise l’algorithme de clustering concave discuté ici. Pendant que le code de génération de polygones s’exécute, vous pouvez constater que quelques échecs sont signalés. Pour aider à comprendre pourquoi l’algorithme ne parvient pas à créer une coque concave, le code écrit les clusters en fichiers CSV dans le répertoire data/out/failed/. Comme d’habitude, vous pouvez utiliser QGIS pour importer ces fichiers sous forme de calques.
Essentiellement, cet algorithme échoue lorsqu’il ne trouve pas suffisamment de points pour “contourner” la forme sans s’auto-croiser. Cela signifie que vous devez être prêt soit à jeter ces grappes, soit à leur appliquer un traitement différent (coque convexe ou bulles coalescées).
Concavité
C’est un enveloppement. Dans cet article, j’ai présenté une méthode de post-traitement des clusters géographiques générés par DBSCAN en formes concaves. Cette méthode peut fournir un polygone extérieur mieux adapté aux clusters par rapport à d’autres alternatives.
Merci d’avoir lu et amusez-vous à bricoler le code!
Kryszkiewicz M., Lasek P. (2010) TI-DBSCAN: Clustering avec DBSCAN au moyen de l’inégalité Triangulaire. Dans: Szczuka M., Kryszkiewicz M., Ramanna S., Jensen R., Hu Q. (eds) Rough Sets and Current Trends in Computing. RSCTC 2010. Notes de cours en informatique, vol 6086. Springer, Berlin, Heidelberg
Scikit-learn: Apprentissage automatique en Python, Pedregosa et al., JMLR 12, p. 2825-2830, 2011
Moreira, A. et Santos, M.Y., 2007, Coque Concave: Une approche K-voisins les plus proches pour le calcul de la région occupée par un ensemble de points
Calculer la distance, le roulement et plus encore entre les points de latitude / Longitude
Dépôt GitHub