Recherche commune : Le projet open source qui ramène PageRank
Inscrivez-vous à nos récapitulatifs quotidiens du paysage du marketing de recherche en constante évolution.
Remarque: En soumettant ce formulaire, vous acceptez les conditions de Third Door Media. Nous respectons votre vie privée.

Au cours des dernières années, Google a lentement réduit la quantité de données disponibles pour les praticiens du référencement. D’abord, il s’agissait de données de mots clés, puis de score PageRank. Maintenant, il s’agit d’un volume de recherche spécifique d’AdWords (sauf si vous dépensez un peu de moola). Vous pouvez en savoir plus à ce sujet dans l’excellent article de Russ Jones qui détaille l’impact des recherches de son entreprise et des informations sur les données de parcours de clics pour la désambiguïsation du volume.
Un élément dans lequel nous nous sommes vraiment impliqués récemment est les données d’analyse courantes. Il y a plusieurs équipes dans notre industrie qui utilisent ces données depuis un certain temps, alors je me suis senti un peu en retard au jeu. Common Crawl data est un projet open source qui gratte l’ensemble d’Internet à intervalles réguliers. Heureusement, Amazon, étant la grande entreprise qu’il est, s’est lancé pour stocker les données afin de les rendre accessibles à beaucoup sans les coûts de stockage élevés.
En plus des données d’exploration communes, il existe un organisme à but non lucratif appelé Common Search dont la mission est de créer un moteur de recherche alternatif open source et transparent — le contraire, à bien des égards, de Google. Cela a suscité mon intérêt car cela signifie que nous pouvons tous jouer, modifier et modifier les signaux pour apprendre comment les moteurs de recherche fonctionnent sans l’énorme investissement en temps de partir de zéro.
Données de recherche communes
Actuellement, Common Search utilise les sources de données suivantes pour calculer son classement de recherche (celles-ci proviennent directement de son site Web):
- Common Crawl: Le plus grand référentiel ouvert de données d’analyse Web. Il s’agit actuellement de notre source unique de données de page brutes.
- Wikidata: Une base de données gratuite et liée qui sert de stockage central pour les données structurées de nombreux projets Wikimédia comme Wikipédia, Wikivoyage et Wikisource.
- Liste noire UT1 : Tenue par Fabrice Prigent de l’Université Toulouse 1 Capitole, cette liste noire classe les domaines et URL en plusieurs catégories, dont ” adulte ” et ” phishing “.”
- DMOZ: Également connu sous le nom de projet Open Directory, c’est le plus ancien et le plus grand répertoire Web encore en vie. Bien que ses données ne soient pas aussi fiables que par le passé, nous les utilisons toujours comme source de signaux et de métadonnées.
- Graphiques d’hyperliens Web Data Commons : Graphiques de tous les hyperliens d’une archive d’analyse commune de 2012. Nous utilisons actuellement son fichier de centralité harmonique comme signal de classement temporaire sur les domaines. Nous prévoyons d’effectuer notre propre analyse du graphique Web dans un proche avenir.
- Alexa top 1M sites: Alexa classe les sites Web en fonction d’une mesure combinée des pages vues et des utilisateurs uniques du site. Il est connu pour être biaisé sur le plan démographique. Nous l’utilisons comme signal de classement temporaire sur les domaines.
Classement de recherche commun
En plus de ces sources de données, pour étudier le code, il utilise également la longueur d’URL, la longueur de chemin et le PageRank de domaine comme signaux de classement dans son algorithme. Voilà, depuis juillet, Common Search a ses propres données sur le PageRank au niveau de l’hôte, et nous l’avons tous manqué.
J’arriverai au PageRank (PR) dans un instant, mais il est intéressant de revoir le code de Common Crawl, en particulier le ranker.partie py située ici, car vous pouvez vraiment entrer dans le siège du conducteur en modifiant le poids des signaux qu’il utilise pour classer les pages:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
Il convient également de noter que la recherche courante utilise BM25 comme mesure de similarité du mot-clé avec le corps du document et les métadonnées. BM25 est une meilleure mesure que TF-IDF car il prend en compte la longueur du document, ce qui signifie qu’un document de 200 mots qui a votre mot-clé cinq fois est probablement plus pertinent qu’un document de 1 500 mots qui l’a le même nombre de fois.
Il est également intéressant de dire que le nombre de signaux ici est très rudimentaire et manque évidemment de nombreux raffinements (et données) que Google a intégrés dans leur algorithme de classement de recherche. L’une des choses clés sur lesquelles nous travaillons est d’utiliser les données disponibles dans Common Crawl et l’infrastructure de Recherche commune pour effectuer une recherche vectorielle par sujet pour un contenu pertinent basé sur la sémantique, pas seulement la correspondance de mots clés.
Sur le PageRank
Sur la page ici, vous pouvez trouver des liens vers le PageRank au niveau de l’hôte pour l’analyse commune de juin 2016. J’utilise celui intitulé pagerank-top1m.txt .gz (top 1 million) car l’autre fichier fait 3 Go et plus de 112 millions de domaines. Même en R, je n’ai pas assez de machine pour la charger sans la fermer.
Après le téléchargement, vous devrez apporter le fichier dans votre répertoire de travail dans R. Les données du PageRank de Common Search ne sont pas normalisées et ne sont pas non plus dans le format 0-10 propre dans lequel nous sommes tous habitués à le voir. La recherche courante utilise “max(0, min(1, float(rank) / 244660.58)) ” — fondamentalement, le rang d’un domaine divisé par le rang de Facebook — comme méthode de traduction des données en une distribution comprise entre 0 et 1. Mais cela laisse des lacunes certaines, en ce sens que cela laisserait le PageRank de Linkedin comme un 1.4 lorsqu’il est mis à l’échelle par 10.

Le code suivant chargera l’ensemble de données et ajoutera une colonne PR avec un PR mieux approximé:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
Nous avons dû jouer un peu avec les chiffres pour le rapprocher (pour plusieurs échantillons de domaines pour lesquels je me suis souvenu des relations publiques) de l’ancien Google PR. Voici quelques exemples de résultats PageRank:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Voici une parcelle de 100 000 échantillons aléatoires. Le score de PageRank calculé est le long de l’axe des ordonnées et le score de recherche commun d’origine est le long de l’axe des abscisses.
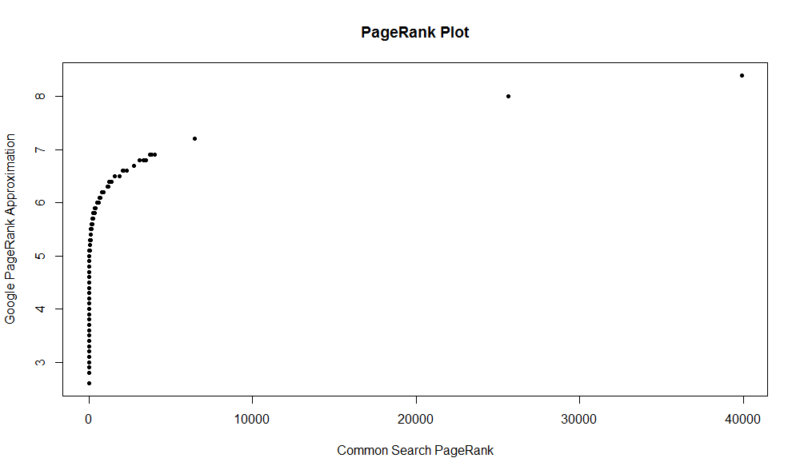
Pour saisir vos propres résultats, vous pouvez exécuter la commande suivante dans R (remplacez simplement votre propre domaine):
df

Gardez à l’esprit que cet ensemble de données ne contient que le premier million de domaines par PageRank, donc sur les 112 millions de domaines indexés par Common Search, il y a de fortes chances que votre site ne soit pas là s’il n’a pas un très bon profil de lien. De plus, cette mesure n’inclut aucune indication de la nocivité des liens, seulement une approximation de la popularité de votre site en ce qui concerne les liens.
La recherche commune est un excellent outil et une excellente base. J’ai hâte de m’impliquer davantage dans la communauté et, espérons-le, d’apprendre à mieux comprendre les rouages des moteurs de recherche en travaillant sur un. Avec R et un peu de code, vous pouvez avoir un moyen rapide de vérifier les relations publiques pour un million de domaines en quelques secondes. J’espère que vous avez apprécié!
Inscrivez-vous à nos résumés quotidiens du paysage du marketing de recherche en constante évolution.
Remarque: En soumettant ce formulaire, vous acceptez les conditions de Third Door Media. Nous respectons votre vie privée.
À Propos De L’Auteur

JR Oakes est directeur principal de la recherche SEO technique chez Locomotive. Il était auparavant directeur du référencement technique de l’agence Adapt Partners. Il travaille avec des clients sur un large éventail de fronts, y compris les problèmes techniques, les performances, le CTR, la capacité d’analyse, le contenu et l’analyse des données. JR aime tester, coder et prototyper des solutions aux problèmes de marketing de recherche difficiles. Quand il ne travaille pas, il aime lire sur les technologies émergentes, jouer de la guitare basse, regarder le basket-ball universitaire, cuisiner et passer du temps avec ses amis et sa famille. Il est également l’un des co-organisateurs du Raleigh SEO Meetup, de la Raleigh SEO Conference et du RTP SEO Meetup.