クラウドデータウェアハウスと従来のデータウェアハウスの概念
クラウドベースのデータウェアハウスは新しい標準です。 あなたのビジネスがハードウェアを購入し、サーバールームを作成し、それを実行するためにスタッフの専用チームを雇い、訓練し、維持しなければならなかった日 今、あなたのラップトップおよびクレジットカードの少数のかちりと言う音と、事実上無制限の計算力および記憶空間にアクセスできる。
しかし、これは伝統的なデータウェアハウスのアイデアが死んでいることを意味するものではありません。 古典的なデータウェアハウス理論は、クラウドベースのデータウェアハウスが何をすべきかの大部分を支えています。
この記事では、知っておく必要がある従来のデータウェアハウスの概念と、Amazon、Google、Panoplyのトッププロバイダーの選択から最も重要なクラウドの概念を説明します。 最後に、従来のデータウェアハウスとクラウドデータウェアハウスの費用便益分析をまとめて、どちらがあなたに適しているかを知ることができます。
始めましょう。
- 従来のデータウェアハウスの概念
- ファクト、ディメンション、およびメジャー
- 正規化と非正規化
- データモデル
- ファクトテーブル
- スタースキーマとスノーフレークスキーマ
- OLAPとOLTP
- 三層アーキテクチャ
- 仮想データウェアハウス/データマート
- Kimball vs.Inmon
- ETL vs.ELT
- エンタープライズデータウェアハウス
- クラウドデータウェアハウスの概念
- クラウドデータウェアハウスの概念-Amazon Redshift
- クラスター
- ノード
- Partitions/Slices
- Columnar Storage
- 圧縮
- データのロード
- Cloud Database Warehouse-Google BigQuery
- サーバーレスサービス
- Colossusファイルシステム
- Dremel実行エンジン
- データ共有
- ストリーミングとバッチ取り込み
- クラウドデータウェアハウスの概念-Panoply
- 主キー
- 増分キー
- ネストされたデータ
- 履歴テーブル
- 変換
- 文字列形式
- データ保護
- アクセス制御
- IPホワイトリスト
- 結論:従来の概念とデータウェアハウスの概念を簡単に
- 従来のデータウェアハウスの概念
- クラウドデータウェアハウスの概念-例としてのAmazon Redshift
- クラウドデータウェアハウスの概念-例としてのBigQuery
- 従来型対クラウド費用便益分析
- データウェアハウスの詳細
従来のデータウェアハウスの概念
データウェアハウスは、組織内の幅広いソースからのデータを照合するシステムです。 データウェアハウスは、分析およびレポートの目的で集中化されたデータリポジトリとして使用されます。
従来のデータウェアハウスは、オフィスの敷地内にあります。 あなたは、ハードウェア、サーバールームを購入し、それを実行するためにスタッフを雇います。 これらは、オンプレミス、オンプレミス、または(文法的に間違った)オンプレミスのデータウェアハウスとも呼ばれます。
ファクト、ディメンション、およびメジャー
データウェアハウスの情報の中核となる構成要素は、ファクト、ディメンション、およびメジャーです。
ファクトとは、特定の発生またはトランザクションを示すデータの一部です。 たとえば、ビジネスが花を販売している場合、データウェアハウスに表示されるいくつかの事実は次のとおりです:
- 販売30roses19のための店舗内のバラ.99
- 中国からの新しい植木鉢500を注文しました$1500
- 今月のレジ係の給与を支払いました$1000
いくつかの数字は、それぞれの事実を記述することができ、我々はこれらの数字の尺度を呼びます。 事実を記述するある手段は”ordered1500のための中国からの500の新しい植木鉢を発注しました”あります:
- 注文数量-500
- コスト- $1500
アナリストがデータを操作しているときは、指標(合計、最大値、平均など)の計算を実行して洞察を収集します。 たとえば、毎月注文する植木鉢の平均数を知りたい場合があります。
次元は事実と尺度を分類し、それらのための構造化されたラベリング情報を提供します-そうでなければ、それらは単なる順序付けられていない数の集 事実を記述するある次元は”ordered1500のための中国からの500の新しい植木鉢を発注しました”次のとおりです:
- 購入した国-中国
- 購入した時間-午後1時
- 到着予定日-June6th
寸法の計算を明示的に実行することはできません。 ただし、ディメンションから新しいメジャーを作成することは可能であり、これらは便利です。 たとえば、注文日から到着日までの平均日数がわかっている場合は、在庫購入をより適切に計画することができます。
正規化と非正規化
正規化は、データウェアハウス(またはデータを格納する他の場所)でデータを効率的に整理するプロセスです。 主な目標は、データの冗長性を減らすこと、つまり重複するデータを削除すること、およびデータの整合性を向上させること、つまりデータの精度を向上させるこ さまざまなレベルの正規化があり、「最良の」方法についてのコンセンサスはありません。 ただし、すべてのメソッドには、別々の関連する情報を異なるテーブルに格納する必要があります。
正規化には、次のような多くの利点があります:
- 各テーブルの検索とソートの高速化
- テーブルの単純化により、データ変更コマンドの書き込みと実行が高速化
- 冗長性の低いデータは、ディスク領域を節約し、より多くのデータを収集して保存できることを意味します
非正規化とは、すでに正規化されたデータに冗長なコピーまたはデータグループを意図的に追加するプロセスです。 正規化されていないデータと同じではありません。 非正規化は、読み取りパフォーマンスを向上させ、必要なフォームにテーブルを操作することをはるかに容易にします。 アナリストがデータウェアハウスを操作する場合、通常はデータの読み取りのみを実行します。 したがって、非正規化されたデータは、膨大な時間と頭痛を救うことができます。
非正規化の利点:
- テーブルが少なくなると、データアナリストのワークフローが高速化され、データでより有用な洞察を発見するテーブル結合の必要性が最小限に抑えられます。
- テーブルが少なくなると、クエリが簡素化され、バグが少なくなります。
データモデル
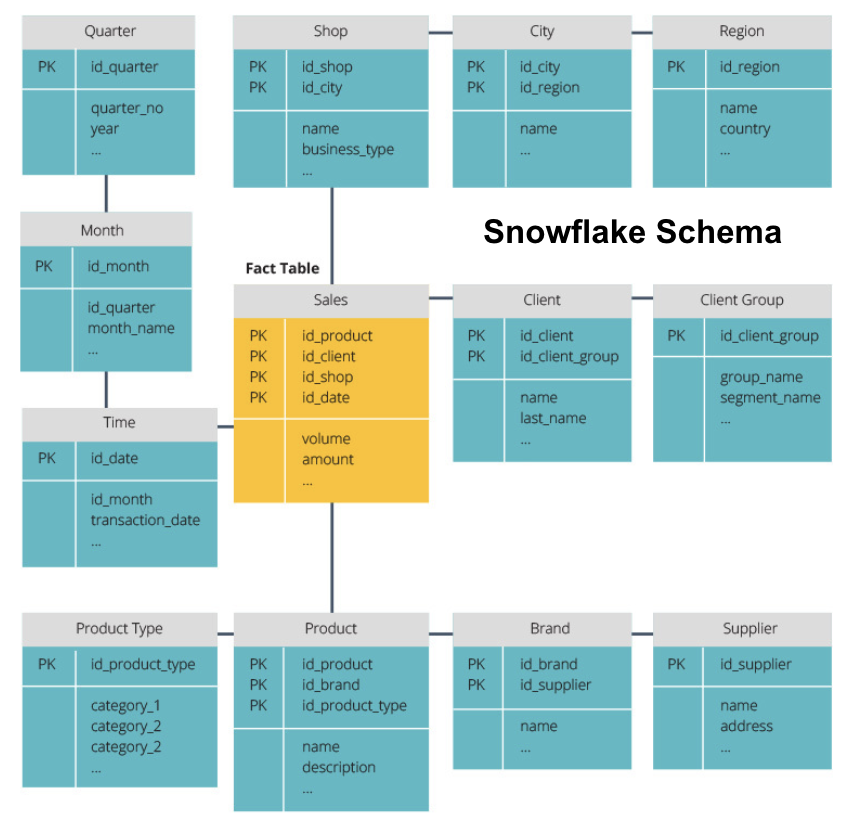
すべてのデータを一つの大規模なテーブルに格納するのは非常に非効率的です。 そのため、データウェアハウスには、特定の情報を取得するために結合できる多くのテーブルが含まれています。 メインテーブルはファクトテーブルと呼ばれ、ディメンションテーブルがそれを取り囲んでいます。
データウェアハウスを設計する最初のステップは、必要なデータとそれらの間の高レベルの関係を定義する概念データモデルを構築することです。
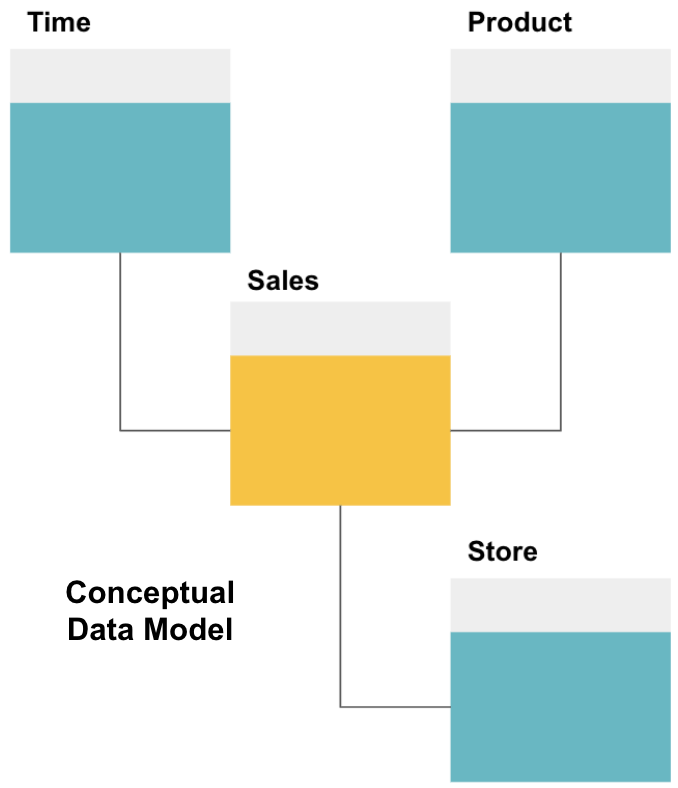
ここでは、概念モデルを定義しました。 販売データを格納しており、各販売に関するより詳細な情報を提供する3つの追加のテーブル(時間、製品、および店舗)があります。 ファクトテーブルはSalesで、その他はディメンションテーブルです。
次のステップは、論理データモデルを定義することです。 このモデルは、コードでの実装方法を気にせずに、データを平易な英語で詳細に記述します。
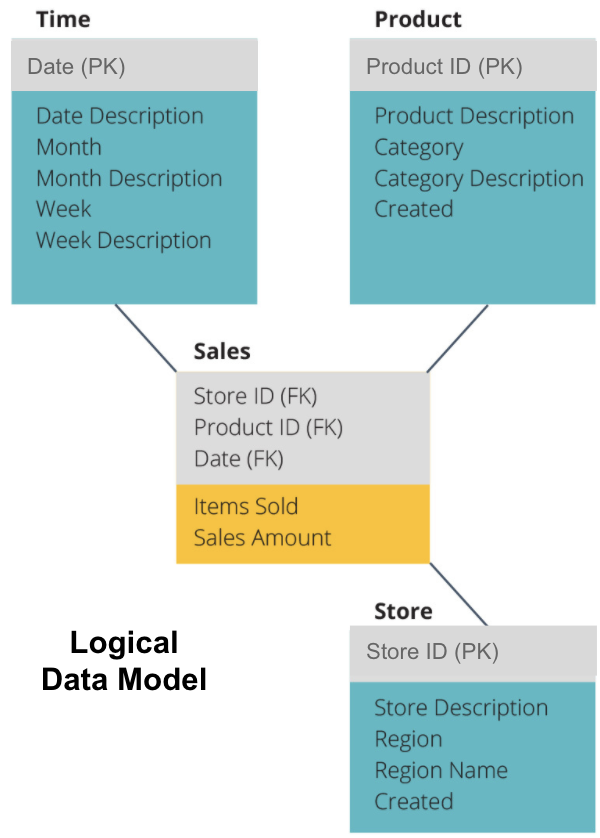
今、私たちは、各テーブルが平易な英語で含まれている情報を記入しています。 時間、製品、および店舗の各ディメンションテーブルには、主キー(PK)が灰色のボックスに表示され、対応するデータが青色のボックスに表示されます。 Salesテーブルには3つの外部キー(FK)が含まれているため、他のテーブルとすばやく結合できます。
最後の段階は、物理データモデルを作成することです。 このモデルでは、データウェアハウスをコードで実装する方法を説明します。 これは、テーブル、それらの構造、およびそれらの間の関係を定義します。 また、列のデータ型を指定し、すべてが最終的なデータウェアハウスにあるように名前が付けられ、すべての大文字とアンダースコアに接続されます。 最後に、各ディメンションテーブルはDIM_で始まり、各ファクトテーブルはFACT_で始まります。
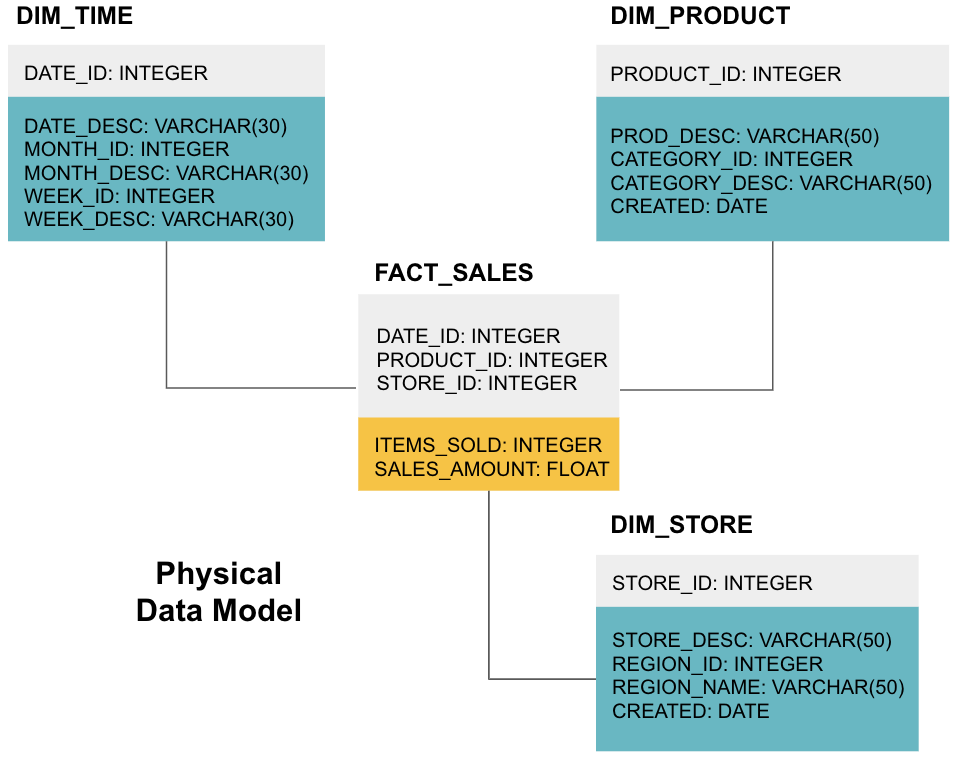
これで、データウェアハウスの設計方法がわかりましたが、次に説明するファクトテーブルとディメンションテーブルにはいくつかのニュアンスが
ファクトテーブル
営業、マーケティング、財務などの各ビジネス機能には、対応するファクトテーブルがあります。
ファクトテーブルには、ディメンション列とファクト列の二つのタイプの列があります。 この例では灰色のディメンション列には、ファクトテーブルとディメンションテーブルを結合するために使用する外部キー(FK)が含まれています。 これらの外部キーは、各ディメンションテーブルの主キー(PK)です。 ファクト列-例では黄色に着色されています-には、販売されたアイテムの数や販売の合計ドル価値など、分析される実際のデータと測定値が含まれています。
ファクトレスファクトテーブルは、ディメンション列のみを持つ特定のタイプのファクトテーブルです。 このようなテーブルは、ディメンションがイベントについて知る必要があるすべてを示すため、学生の出欠や従業員の休暇などのイベントを追跡する
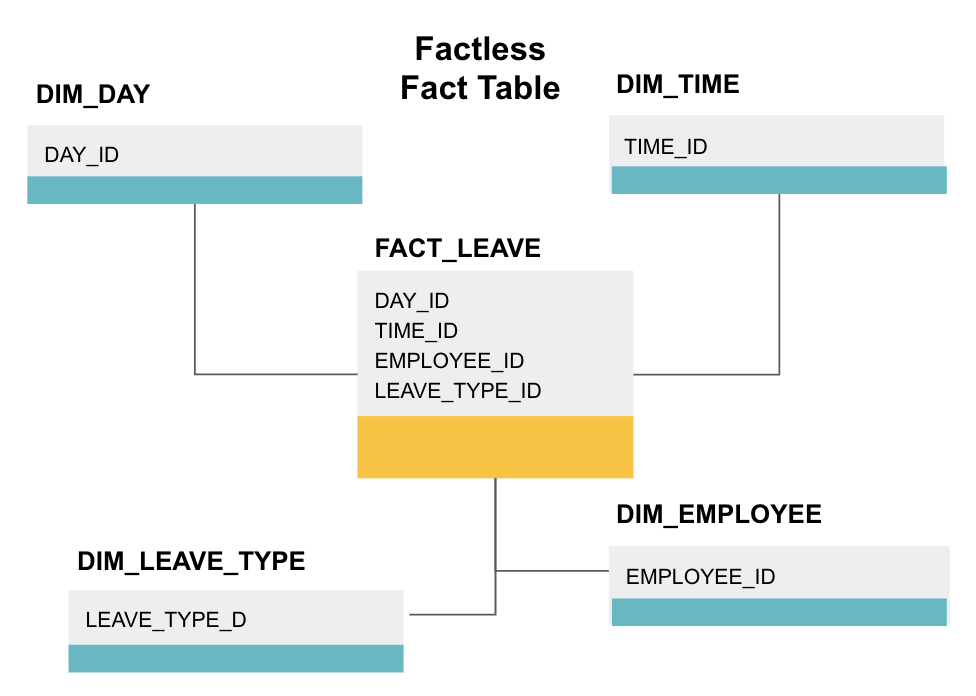
上記の事実上のファクトテーブルは、従業員の休暇を追跡します。 あなたが知る必要があるだけなので事実はありません:
- 彼らが休みだった日(DAY_ID)。
- どのくらいオフになっていたか(TIME_ID)。
- 休暇中だった人(EMPLOYEE_ID)。
- 彼らの休暇の理由、例えば、病気、休日、医者の任命、等。 (LEAVE_TYPE_ID)。
スタースキーマとスノーフレークスキーマ
上記のデータウェアハウスはすべて同様のレイアウトを持っています。 しかし、これはそれらを配置する唯一の方法ではありません。
データウェアハウスを編成するために使用される最も一般的な2つのスキーマは、starとsnowflakeです。 どちらのメソッドも、ファクトテーブルに含まれる情報を記述するディメンションテーブルを使用します。
スタースキーマは、ファクトテーブルから情報を取得し、非正規化ディメンションテーブルに分割します。 スタースキーマの重点は、クエリの速度にあります。 ファクトテーブルを各ディメンションにリンクするために必要な結合は1つだけなので、各テーブルのクエリは簡単です。 ただし、テーブルは非正規化されているため、多くの場合、重複したデータが含まれています。
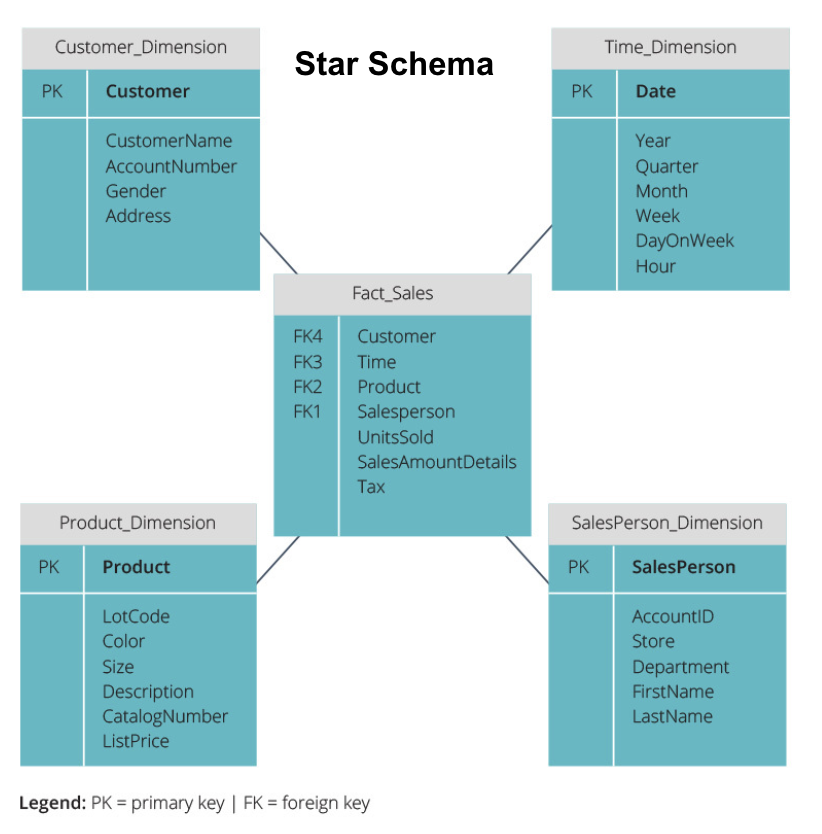
snowflakeスキーマは、ファクトテーブルを一連の正規化されたディメンションテーブルに分割します。 正規化すると、より多くのディメンションテーブルが作成されるため、データの整合性の問題が軽減されます。 ただし、snowflakeスキーマを使用すると、関連するデータにアクセスするためにより多くのテーブル結合が必要になるため、クエリはより困難になります。 したがって、冗長なデータは少なくなりますが、アクセスするのは困難です。
ここでは、より基本的なデータウェアハウスの概念について説明します。
OLAPとOLTP
オンライントランザクション処理(OLTP)は、企業のデータアーキテクチャのフロントエンドアプリケーションを含む短い書き込みトランザクション OLTPデータベースは、高速なクエリ処理を重視し、現在のデータのみを処理します。 企業はこれらを使用して、ビジネスプロセスの情報を取得し、データウェアハウスのソースデータを提供します。
オンライン分析処理(OLAP)を使用すると、複雑な読み取りクエリを実行し、履歴トランザクションデータの詳細な分析を実行できます。 OLAPシステムは、データウェアハウス内のデータを分析するのに役立ちます。
三層アーキテクチャ
従来のデータウェアハウスは、通常、三層で構成されています:
- 下層:ゲートウェイを使用して異なるソースからデータを抽出するデータベースサーバー、通常はRDBMS。 この層に供給されるデータソースには、運用データベースや、CSVファイルやJSONファイルなどの他の種類のフロントエンドデータが含まれます。
- 中間層:
- が操作を直接実装するOLAPサーバー、または
- が多次元データの操作を標準のリレーショナル操作にマップするOLAPサーバー(XMLまたはJSONデータを表内の行に
- 最上位層:データ分析とビジネスインテリジェンスのためのクエリおよびレポートツール。
仮想データウェアハウス/データマート
仮想データウェアハウスでは、データを1つの物理データウェアハウスに統合することなく、複数のデータベースで分散クエ
データマートは、販売や財務などの特定のビジネス機能を対象としたデータウェアハウスのサブセットです。 データウェアハウスは、通常、複数のデータマートからの情報を複数のビジネス機能で結合します。 しかし、データマートには、1つのビジネス機能のソースシステムのセットからのデータが含まれています。
Kimball vs.Inmon
データウェアハウスの設計には、Bill InmonとRalph Kimballによって提案された2つのアプローチがあります。 Bill Inmonは、データウェアハウスの父として認識されているアメリカのコンピュータ科学者です。 Ralph Kimballは、データウェアハウスの元の建築家の一人であり、このトピックに関するいくつかの本を書いています。
二人の専門家は、データウェアハウスをどのように構造化すべきかについて相反する意見を持っていました。 この対立は、二つの思想の学校を生じさせています。
Inmonアプローチはトップダウン設計です。 Inmonの方法論では、データウェアハウスが最初に作成され、分析環境の中心的なコンポーネントと見なされます。 次に、データが集約され、集中型倉庫から1つ以上の依存データマートに分散されます。
Kimballアプローチは、データウェアハウスの設計のボトムアップビューを取ります。 このアーキテクチャでは、組織は個別のデータマートを作成し、組織内の単一の部門にビューを提供します。 データウェアハウスは、これらのデータマートの組み合わせです。
ETL vs.ELT
Extract,Transform,Load(ETL)は、ソースシステム(通常はトランザクションシステム)からデータを抽出し、データをクエリや分析に適した形式または構造に変換し、最終的にデータウェアハウスにロードするプロセスを説明します。 ETLは、別のステージングデータベースを活用し、ロードする前に抽出されたデータに一連のルールまたは関数を適用します。
Extract,Load,Transform(ELT)は、データをロードするための別のアプローチです。 ELTは、異なるソースからデータを取得し、データウェアハウスなどのターゲットシステムに直接ロードします。 次に、ロードされたデータをオンデマンドで変換して分析を可能にします。
ELTはETLよりも高速な読み込みを提供しますが、オンデマンドでデータ変換を実行するには強力なシステムが必要です。
エンタープライズデータウェアハウス
エンタープライズデータウェアハウスは、現在および履歴の両方の組織内のすべてのトランザクション情報を含 エンタープライズデータウェアハウスは、マーケティング、販売、財務、人事など、ビジネスに関連するすべての主題分野のデータを組み込む必要があります。
これらは、従来のデータウェアハウスを構成する中核的なアイデアです。 次に、クラウドデータウェアハウスがその上に追加したものを見てみましょう。
クラウドデータウェアハウスの概念
クラウドデータウェアハウスは新しく、常に変化しています。 彼らの基本的な概念を最もよく理解するためには、主要なクラウドデータウェアハウスソリューションについて学ぶことが最善です。
クラウドデータウェアハウスの主要なソリューションは、Amazon Redshift、Google BigQuery、Panoplyです。 以下では、最新のデータウェアハウスがどのように機能するかを一般的に理解するために、これらの各サービスの基本的な概念を説明します。
クラウドデータウェアハウスの概念-Amazon Redshift
以下の概念はAmazon Redshiftクラウドデータウェアハウスで明示的に使用されていますが、将来的にはAmazonインフラストラ
クラスター
Amazon Redshiftはクラスターにアーキテクチャをベースにしています。 クラスターとは、ノードと呼ばれる共有コンピューティングリソースのグループです。
ノード
ノードは、CPU、RAM、およびハードディスク領域を持つコンピューティングリソースです。 複数のノードを含むクラスターは、リーダーノードと計算ノードで構成されます。
リーダーノードはクライアントプログラムと通信し、コードをコンパイルしてクエリを実行し、計算ノードに割り当てます。 計算ノードはクエリを実行し、結果をリーダーノードに返します。 計算ノードは、そのノードに格納されているテーブルを参照するクエリのみを実行します。
Partitions/Slices
Amazonは各コンピューティングノードをスライスに分割します。 スライスは、ノード上のメモリとディスク領域の割り当てを受け取ります。 複数のスライスが並列に動作し、クエリの実行時間を短縮します。
Columnar Storage
Redshiftはcolumnar storageを使用し、分析クエリのパフォーマンスを向上させます。 レコードを行に格納する代わりに、複数の行の単一の列の値を格納します。 次の図は、これをより明確にします:
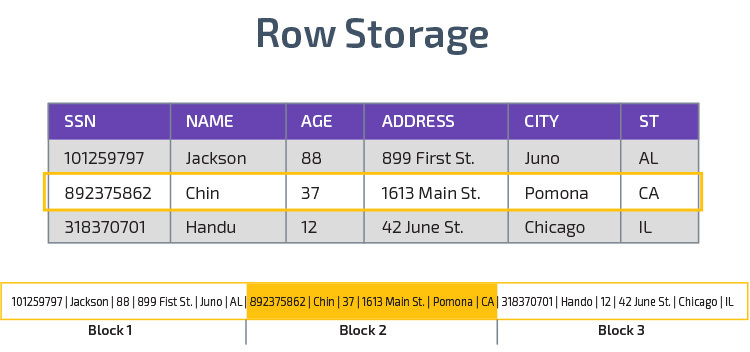
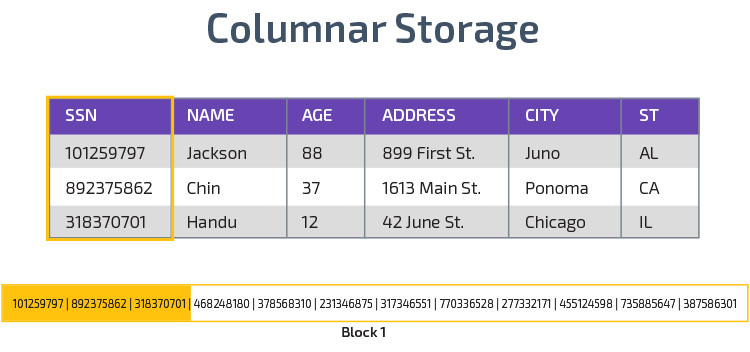
列ストレージを使用すると、データをより高速に読み取ることができ、データセット内の多くの列にまたがる分析クエリに不可欠です。 各ブロックには同じタイプのデータが含まれているため、特定の形式に圧縮できるため、列ストレージのディスク領域も少なくなります。
圧縮
圧縮は、格納されているデータのサイズを縮小します。 Redshiftでは、データの格納方法のために、列レベルで圧縮が発生します。 Redshiftを使用すると、テーブルの作成時に手動で情報を圧縮したり、COPYコマンドを使用して自動的に情報を圧縮したりすることができます。
データのロード
RedshiftのCOPYコマンドを使用して、大量のデータをデータウェアハウスにロードできます。 COPYコマンドは、RedshiftのMPPアーキテクチャを利用して、Amazon S3上のファイル、DynamoDBテーブル、または1つ以上のリモートホストからのテキスト出力からデータを並行しAmazon Kinesis Firehoseサービスを使用して、Redshiftにデータをストリーミングすることもできます。
Cloud Database Warehouse-Google BigQuery
次の概念はGoogle BigQuery cloud data warehouseで明示的に使用されていますが、将来、Googleインフラストラクチャに基づく追加のソリューションに適用される可能性
サーバーレスサービス
BigQueryはサーバーレスアーキテクチャを使用します。 BigQueryを使用すると、企業はデータウェアハウスを実行するために物理サーバーユニットを管理する必要はありません。 代わりに、BigQueryはコンピューティングリソースの割り当てを動的に管理します。 このサービスを使用している企業は、ギガバイトあたりのデータストレージとテラバイトあたりのクエ
Colossusファイルシステム
BigQueryは、Googleの分散ファイルシステムの最新バージョン、コードネームColossusを使用しています。 Colossusファイルシステムは、列ストレージと圧縮アルゴリズムを使用して、分析目的のためにデータを最適に格納します。
Dremel実行エンジン
Dremel実行エンジンは、列型レイアウトを使用して、膨大なデータストアを迅速に照会します。 Dremelの実行エンジンは、ツリーアーキテクチャの形で超並列処理を使用するため、数十億行に対してアドホッククエリを数秒で実行できます。
ツリーアーキテクチャは、ルートサーバーから複数の中間サーバー間でクエリを分散します。 中間サーバーは、クエリをリーフサーバー(格納されたデータを含む)にプッシュし、データを並行してスキャンします。 ツリーのバックアップの途中で、各リーフサーバーはクエリ結果を送信し、中間サーバーは部分的な結果の並列集計を実行します。
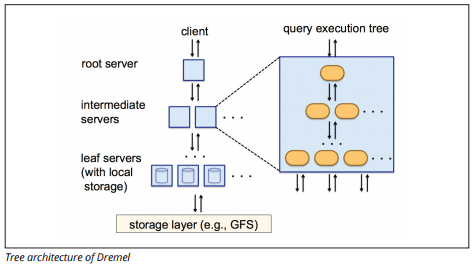
イメージソース
Dremelを使用すると、組織は最大数万台のサーバーで同時にクエリを実行できます。 Googleによると、Dremelは数十秒でインデックスなしで350億行をスキャンできます。
データ共有
Google BigQueryのサーバーレスアーキテクチャを使用すると、企業は他の組織と簡単にデータを共有でき、組織が独自のストレージに投資する必要はありません。
共有データを照会したい組織は照会を行うことができ、照会に対してのみ料金を支払うことになります。 組織のデータインフラストラクチャの外部に高価な共有データサイロを作成し、それらのサイロにデータをコピーする必要はありません。
ストリーミングとバッチ取り込み
CSV、JSON(改行区切り)、Avroファイル、Google Cloud Datastoreバックアップなど、Google Cloud StorageからBigQueryにデータをロードすることができます。 読み取り可能なデータソースから直接データを読み込むこともできます。
BigQueryは、ロードを実行せずに毎秒数百万行の速度でシステムにデータをロードするストリーミングAPIも提供しています。 データは分析のためにほとんどすぐに利用できる。
クラウドデータウェアハウスの概念-Panoply
Panoplyは、ETLと強力なデータウェアハウスを組み合わせたオールインワンウェアハウスです。 これは、ビッグデータの変換、統合、および管理に関連する開発とコーディングを排除することにより、企業のデータを同期、保存、およびアクセスする最も簡単
以下は、データモデリングとデータ保護に関連するPanoplyデータウェアハウスの主な概念の一部です。
主キー
主キーは、テーブル内のすべての行が一意であることを確認します。 各テーブルには、データベース内の単一の一意の行を表すものを定義する1つ以上の主キーがあります。 すべてのApiには、テーブルのデフォルトの主キーがあります。
増分キー
Panoplyは、何かが変更されるたびにデータセット全体をリロードするのではなく、ソースからデータウェアハウスに増分ロードするための属性を制御するために、増分キーを使用しています。 この機能は、ほとんど変更されていないデータを読み取るのに長い時間がかかる場合がある、より大きなデータセットに役立ちます。 増分キーは、そのデータソース内の行の最後の更新ポイントを示します。
ネストされたデータ
ネストされたデータは、BIスイートや標準SQLクエリと完全に互換性がありません—Panoplyは、ネストされた値を許可しない強力なリレーショ Panoplyはネストされたデータを次の方法で変換します:
- サブテーブル:デフォルトでは、Panoplyはネストされたデータを多対多または一対多のリレーションシップテーブルのセットに変換します。
- フラット化:このモードを有効にすると、Panoplyはネストされた構造をそれを含むレコードにフラット化します。
履歴テーブル
時には、データがどのように変化するかを正確に確認するために、時間の経過とともにデータが変化することを追跡してデータを分析する必
このような分析を実行するために、Panoplyは、元の静的テーブル内のすべての行の履歴スナップショットを含む時系列テーブルである履歴テーブルを使用します。 その後、任意の時点に巻き戻すことによって、元のテーブルまたはテーブルのリビジョンの簡単なクエリを実行できます。
変換
Panoplyは、元のETLデータ統合プロセスのバリエーションであるELTを使用します。 ソースからデータウェアハウスにデータを注入すると、Panoplyはすぐにデータを変換します。 このプロセスは、標準のETLプロセスと比較して、リアルタイムのデータ分析と最適なパフォーマンスを提供します。
文字列形式
Panoplyは文字列形式を解析し、元のデータ内のネストされたオブジェクトであるかのように処理します。 サポートされている文字列形式は、CSV、TSV、JSON、JSON-Line、Rubyオブジェクト形式、URLクエリ文字列、およびweb配布ログです。
データ保護
PanoplyはAWS上に構築されているため、ハードウェアによるRSA暗号化やAmazon Redshiftの特定のセキュリティ機能セットなど、AWSが提供する最新のセキ
追加の保護は、panoplyのサーバーに保存されていない秘密鍵を使用できるcolumnar encryptionから来ています。
アクセス制御
Panoplyは2段階認証を使用して不正アクセスを防止し、権限システムを使用すると、特定のテーブル、ビュー、または列へのアクセスを制限 異常検出は、新しいコンピュータまたは別の国からのクエリを識別し、手動で承認を受けない限り、それらのクエリをブロックできます。
IPホワイトリスト
ファイアウォールまたはAWSセキュリティグループを使用して認識されないソースからの接続をブロックし、Panoplyのデータソースがデータベース
結論:従来の概念とデータウェアハウスの概念を簡単に
まとめるために、このドキュメントで導入された概念を要約します。
従来のデータウェアハウスの概念
- ファクトとメジャー:メジャーは、計算を行うことができるプロパティです。 私たちは、事実としての措置のコレクションを参照してくださいが、時には用語が交換可能に使用されています。
- 正規化:重複するデータの量を減らすプロセスで、クエリが遅くなるメモリ効率の高いデータウェアハウスにつながります。
- ディメンション:事実と措置を分類および文脈化し、それらの措置の分析と報告を可能にするために使用されます。
- 概念的データモデル:重要な高レベルのデータエンティティとそれらの間の関係を定義します。
- 論理データモデル: データ関係、エンティティ、および属性をコードで実装する方法を心配することなく、平易な英語で説明します。
- 物理データモデル:特定のデータベース管理システムにデータ設計を実装する方法の表現。
- Star schema:ファクトテーブルを取得し、その情報を非正規化ディメンションテーブルに分割します。
- Snowflakeスキーマ:ファクトテーブルを正規化されたディメンションテーブルに分割します。 正規化すると、データの冗長性の問題が軽減され、データの整合性が向上しますが、クエリはより複雑になります。
- : オンライントランザクション処理システムは、簡単なクエリで高速でトランザクション指向の処理を容易にします。
- OLAP:オンライン分析処理を使用すると、複雑な読み取りクエリを実行し、履歴トランザクションデータの詳細な分析を実行できます。
- データマート:組織内の特定の主題または部門に焦点を当てたデータのアーカイブ。
- Inmonアプローチ:Bill Inmonのデータウェアハウスアプローチでは、データウェアハウスを企業全体の集中型データリポジトリとして定義しています。 データマートは、さまざまな部門の分析ニーズに対応するために、データウェアハウスから構築できます。
- Kimballアプローチ:Ralph Kimballは、データウェアハウスを、さまざまな部門の分析ニーズに応えるために最初に作成されるミッションクリティカルなデータマートのマージと
- ETL:さまざまなトランザクションソースからデータを抽出し、分析用に最適化するためにデータを変換し、最終的にデータウェアハウスにロードすることによ
- : 組織のデータソースから生データを抽出し、データウェアハウスにロードするETLのバリエーション。 必要に応じて、分析目的のために変換されます。
- エンタープライズデータウェアハウス:EDWは、企業に関連するすべての主題領域からのデータを統合します。
クラウドデータウェアハウスの概念-例としてのAmazon Redshift
- クラスター:クラウドに基づく共有コンピューティングリソースのグループ。
- ノード:クラスター内に含まれるコンピューティングリソース。 各ノードには、独自のCPU、RAM、およびハードディスク領域があります。
- : これにより、テーブルの値が行ではなく列に格納され、集計されたクエリのデータが最適化されます。
- 圧縮:格納されたデータのサイズを小さくする技術。
- データの読み込み:ソースからクラウドベースのデータウェアハウスにデータを取得します。 Redshiftでは、COPYコマンドまたはデータストリーミングサービスを使用できます。
クラウドデータウェアハウスの概念-例としてのBigQuery
- サーバーレスサービス:クラウドプロバイダーは、ユーザーが消費する量に基づいてマシンリソースの割 クラウドプロバイダーは、サービスのユーザーからサーバー管理と容量計画の決定を非表示にします。
- Colossusファイルシステム:列ストレージとデータ圧縮アルゴリズムを使用して分析用にデータを最適化する分散ファイルシステム。
- Dremel実行エンジン:超並列処理と列ストレージを使用してクエリを迅速に実行するクエリエンジン。
- データ共有:サーバーレスサービスでは、データストレージに投資せずに別の組織の共有データを照会することが実用的です。
- ストリーミングデータ:ロードを実行せずにデータウェアハウスにリアルタイムでデータを挿入します。 バッチ要求では、複数のAPI呼び出しを1つのHTTP要求に結合してデータをストリームすることができます。
従来型対クラウド費用便益分析
| コスト/ベネフィット | トラディショナル | クラウド |
| コスト | オンプレミスシステムを購入してインストールするための大きな前払いコスト。 ハードウェア、サーバールーム、専門スタッフ(継続的に支払う)が必要です。 どのくらいのストレージスペースが必要かわからない場合は、回収が困難な沈没コストが高いリスクがあります。 |
ハードウェア、サーバールーム、または専門家を雇う必要はありません。 沈没コストのリスクなし-将来的にはより多くのストレージを購入するのは簡単です。 さらに、ストレージのコストと計算能力は時間の経過とともに減少しています。 |
| スケーラビリティ | 現在のサーバールームやハードウェア容量を最大化したら、新しいハードウェアを購入し、それを収容する場所をさらに構築/購入する必要が さらに、ピーク時に対処するのに十分なストレージを購入する必要があります; したがって、ほとんどの場合、ほとんどのストレージは使用されません。 |
あなたは簡単にあなたがそれを必要とするときに、より多くのストレージを購入することができます。 多くの場合、あなたが使用するもののために支払わなければならないので、過払いのリスクはほとんどありません。 |
| 統合 | クラウドコンピューティングが標準であるため、あなたが作りたいほとんどの統合はクラウドサービスになります。 カスタムデータウェアハウスをそれらに接続することは困難です。 |
クラウドデータウェアハウスはすでにクラウド内にあるため、他のクラウドサービスの範囲に接続するのは簡単です。 |
| セキュリティ | あなたはあなたのデータウェアハウスを完全に制御しています。 あなたが保管するデータの量をAmazonやGoogleと比較すると、あなたは泥棒のターゲットが小さくなります。 だから、あなたは一人で放置される可能性が高いかもしれません。 |
クラウドデータウェアハウスプロバイダーには、製品をできるだけ安全にすることを唯一の目的とする高度に熟練したセキュリティエンジニアで 世界で最も著名な企業がそれらを管理し、したがって世界クラスのセキュリティ慣行を実装しています。 |
| ガバナンス | データがどこにあるかを正確に把握し、ローカルでアクセスできます。 クラウドサーバー上で世界中を移動するなど、機密性の高いデータが誤って法律を破るリスクが少なくなります。 |
クラウドデータウェアハウスのトッププロバイダーは、GDPRなどのガバナンスおよびセキュリティ法に準拠しています。 プラス、それらはあなたのビジネスが迎合的であることを保障するのを助けます。 あなたのデータがどこにあるのか、どこに移動するのかを正確に知ることに関する問題がありました。 これらの問題は積極的に対処され、解決されています。 クラウド上に大量の機密性の高いデータを保存することは、特定の法律に違反する可能性があることに注意してください。 これは、クラウドコンピューティングがあなたのビジネスに不適切である可能性があります一つのインスタンスです。 |
| 信頼性 | オンプレミスのデータウェアハウスに障害が発生した場合、それを修正するのはお客様の責任です。 ITチームは物理ハードウェアにアクセスでき、すべてのソフトウェアレイヤーにアクセスしてトラブルシューテ この迅速なアクセスは、はるかに高速に問題を解決することができます。 ただし、倉庫の稼働時間が毎年一定になるという保証はありません。 |
クラウドデータウェアハウスプロバイダーは、Slaの信頼性と稼働時間を保証します。 彼らは世界中の大規模に分散されたシステム上で動作するので、一つに障害がある場合、それはあなたに影響を与える可能性は非常に低いです。 |
| コントロール | あなたのデータウェアハウスは、あなたのニーズに合わせてカスタムビルドされています。 理論的には、それはあなたが理解している方法で、あなたがそれをしたいときに、あなたがしたいことをします。 | データウェアハウスを完全に制御することはできません。 しかし、大部分の時間は、あなたが持っているコントロールは十分以上です。 |
| スピード | データ量が少ない地理的な場所にある小規模な会社であれば、データ処理が高速になります。 しかし、我々はいくつかのプロセスが完了するためのミリ秒対秒を話している。 複数の国で事業を展開している大企業は、オンプレムシステムで大幅な速度向上を見ることはまずありません。 |
クラウドプロバイダーは、超並列処理(MPP)、カスタムビルドアーキテクチャと実行エンジン、インテリジェントなデータ処理アルゴリズムを実装するシステ クラウドデータウェアハウスは、速度とパフォーマンスに最適化されたリソースを作成するための長年の研究とテストの結果です。 場合によってはon-premよりもわずかに遅いかもしれませんが、これらの遅延は人間にとっては無視できることがよくあります(秒対ミリ秒)。 |
Panoplyは、すべてのビジネスデータを保存、同期、およびアクセスするための安全な場所です。 Panoplyは数分でセットアップでき、継続的なメンテナンスが不要で、経験豊富なデータアーキテクトへのアクセスを含むオンラインサポートを提供します。 Panoplyを14日間無料でお試しください。
データウェアハウスの詳細
- データウェアハウスアーキテクチャ:従来型とクラウド
- データベースとデータウェアハウス
- データマートとデータウェアハウス