クラスタスケジューリングシステムの進化
Kubernetesはコンテナオーケストレーションの分野で事実上の標準となっています。 すべてのアプリケーションは、将来的にKubernetes上で開発および実行される予定です。 この一連の記事の目的は、Kubernetesの基本的な実装原則を深く簡単な方法で紹介することです。
Kubernetesはクラスタースケジューリングシステムです。 この記事では、主にKubernetesのいくつかの以前のクラスタスケジューリングシステムアーキテクチャを紹介します。 それらの設計思想とアーキテクチャ特性を分析することにより,クラスタスケジューリングシステムアーキテクチャの進化過程とアーキテクチャ設計において考慮すべき主な問題を研究することができる。 それはKubernetesアーキテクチャを理解するのに非常に役立ちます。
我々は、それを明確にするために、クラスタスケジューリングシステムの基本的な概念のいくつかを理解する必要があり、私は例を通して概念を説明し、のは、我々は分散Cronを実装したいと仮定しましょう。 システムは一連のLinuxホストを管理します。 ユーザーは、システムによって提供されるAPIを介してジョブを定義します。 この例では、基本的な概念を以下に示します:
- クラスタ:このシステムによって管理されるLinuxホストは、タスクを実行するためのリソースプールを形成します。 このリソースプールはクラスターと呼ばれます。
- Job:クラスターがタスクを実行する方法を定義します。 この例では、Crontabは正確に何時(時間間隔)に何をする必要があるか(実行スクリプト)を明確に示す単純なジョブです。いくつかのジョブの定義は、いくつかのタスクで完了するジョブの定義、タスク間の依存関係、各タスクのリソース要件など、より複雑です。
- タスク:ジョブを特定のパフォーマンスタスクにスケジュールする必要があります。 毎晩午前1時にスクリプトを実行するジョブを定義すると、毎日午前1時に実行されるスクリプトプロセスがタスクになります。
クラスタスケジューリングシステムを設計する場合、システムのコアタスクは二つです:
- タスクのスケジューリング: ジョブがクラスタスケジューリングシステムに送信された後、送信されたジョブを特定の実行タスクに分割し、タスクの実行結果を追跡および監視す 分散Cronの例では、スケジューリングシステムは、操作の要件に従ってプロセスを適時に開始する必要があります。 プロセスの実行に失敗した場合は、再試行などが必要です。 このようなHadoopのマップ削減などのいくつかの複雑なシナリオは、スケジューリングシステムは、対応する複数のマップにマップ削減タスクを分割し、タ
- Resource scheduling:基本的にタスクとリソースを一致させるために使用され、クラスタ内のホストのリソース使用量に応じて適切なリソースがタスクを実行するために割 これは、オペレーティングシステムのスケジューリングアルゴリズムのプロセスに似ていますが、リソーススケジューリングの主な目標は、可能な限りリソー 可能(リソースはすべてのタスクに公平に割り当てられます)。 これらの目標のいくつかは矛盾しており、リソースの使用率、応答時間、公平性、優先順位など、バランスをとる必要があります。
Hadoop Mrv1
Map Reduceは並列計算モデルの一種です。 Hadoopは、並列コンピューティングのクラスタ管理プラットフォームのこの種を実行することができます。 Mrv1は、HadoopプラットフォームのMap Reduce task scheduling engineの第一世代バージョンです。 要するに、Mrv1は、クラスター上のジョブのスケジューリングと実行を担当し、ユーザーがMap Reduce計算を定義してHadoopに送信するときに計算結果に戻ります。 ここでは、Mrv1のアーキテクチャがどのように見えるかです:
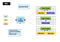
アーキテクチャは比較的単純で、標準のマスター/スレーブアーキテクチャには二つのコアコンポーネントがあります:
- ジョブトラッカーはクラスタの主要な管理コンポーネントであり、リソーススケジューリングとタスクスケジューリングの両方を担当します。
- タスクトラッカーはクラスター内の各マシンで実行され、ホスト上で特定のタスクを実行し、ステータスを報告します。
Hadoopの普及と様々な要求の増加に伴い、Mrv1には以下のような改善すべき問題があります:
- パフォーマンスには一定のボトルネックがあります: 管理をサポートするノードの最大数は5,000であり、操作をサポートするタスクの最大数は40,000です。 まだ改善の余地があります。
- 他のタスクタイプを拡張したりサポートしたりするのに十分な柔軟性はありません。 Map reduceタイプのタスクに加えて、Spark、Hive、HBase、Storm、Oozieなど、スケジュールする必要がある他の多くのタスクタイプがhadoopエコシステムにあります。 したがって、より一般的なスケジューリングシステムが必要であり、より多くのタスクタイプ
- 低リソース使用率をサポートおよび拡張できます: Mrv1は各ノードの固定数のスロットを静的に構成し、各スロットは特定のタスクタイプ(MapまたはReduce)にのみ使用でき、リソース使用率の問題が発生します。 たとえば、多数のマップタスクがアイドル状態のリソースのキューに入っていますが、実際には多数のReduceスロットがマシンのアイドル状態になってい
- マルチテナントとマルチバージョンの問題。 たとえば、異なる部門が同じクラスター内でタスクを実行しますが、それらは互いに論理的に分離されているか、同じクラスター内で異なるバージョンのHadoop
YARN
YARN(まだ別のリソース交渉者)は、Hadoopの第二世代であり、主な目的は、Mrv1の問題のすべての種類を解決することです。 YARNアーキテクチャは次のようになります:

Yarnの簡単な理解は、Mrv1に対する主な改善点は、元のJobTrackの責任をResource ManagerとApplication Master
- Resource Managerの二つの異なるコンポーネントに分割することです: リソーススケジューリングを担当し、すべてのリソースを管理し、さまざまなタイプのタスクにリソースを割り当て、プラガブルアーキテクチャを介してリソーススケジューリングアルゴリズムを簡単に拡張します。
- アプリケーションマスター:タスクのスケジューリングを担当します。 各ジョブ(YARNではApplicationと呼ばれます)は、ジョブを特定のタスクに分割し、Resource Managerからリソースを申請し、タスクを開始し、タスクのステータスを追跡し、結果を報告す
このアーキテクチャの変更がMrv1のさまざまな問題をどのように解決したかを見てみましょう:
- Job Trackerの元のタスクスケジューリング責任を分割し、パフォーマンスを大幅に向上させます。 元のジョブトラッカーのタスクスケジューリング責任は、アプリケーションマスターによって行われるように分割され、アプリケーションマスターが分散され、各
- タスクスケジューリング、アプリケーションマスター、リソーススケジューリングのコンポーネントは、ジョブ要求に基づいて分離され、動的に作成されます。 一つのアプリケーションマスターインスタンスは、スケジューリングの一つのジョブのみを担当するため、さまざまなタイプのジョブをサポートしやすくなります。
- コンテナ分離技術が導入され、各タスクは分離されたコンテナで実行され、動的に割り当てることができるリソースに対するタスクの要求に応じてリソー これの欠点は、YARNのリソース管理と割り当てには1つの次元のメモリしかないことです。
Mesos architecture
YARNの設計目標は、Hadoopエコシステムのスケジューリングを提供することです。 Mesosの目標が近づく、それは全体のデータセンターの動作を管理することができ、一般的なスケジューリングシステムであるように設計されています。 我々が見るように、Mesosの建築設計は参照のために多くの糸を使用し、ジョブスケジューリングとリソーススケジューリングは別々のモジュールによって負担され しかし、MesosとYARNの最大の違いは、リソースのスケジューリング方法であり、Resource offerと呼ばれるユニークなメカニズムが設計されています。 リソーススケジューリングの圧力がさらに解放され、ジョブスケジューリングのスケーラビリティも向上します。

Mesosの主な構成要素は次のとおりです:
- Mesosマスター:これは、リソースの割り当てと内部YARNに対応するリソースマネージャである管理のコンポーネントを担当するコンポーネントです。 しかし、動作モードは、後で説明する場合はわずかに異なります。
- Framework:ジョブスケジューリングを担当し、異なるジョブタイプには、Sparkジョブを担当するSparkフレームワークなどの対応するフレームワークがあります。
Mesosのリソース提供
MesosとYARNのアーキテクチャは非常に似ているように見えるかもしれませんが、実際には、リソース管理の面では、Mesosのマスターは非常にユニー:
- 糸は引きです: YARNでResource Managerによって提供されるリソースは受動的であり、リソースの消費者(アプリケーションマスター)がリソースを必要とするとき、リソースマネージャのインター
- Mesosはプッシュです:Mesosのマスターが提供するリソースは積極的です。 Mesosのマスターは、現在利用可能なすべてのリソース(いわゆるリソースオファー、私は今からオファーと呼びます)をフレームワークにプッシュするためのイニシアチブ フレームワークが実行するタスクがある場合、オファーが受信されない限り、積極的にリソースを申請することはできません。 フレームワークは、オファーから受け入れ(このモーションはMesosでは受け入れと呼ばれます)、残りのオファーを拒否する(このモーションは拒否と呼ばれます)適格なリソー このラウンドのオファーに十分な資格のあるリソースがない場合は、次のラウンドのマスターがオファーを提供するのを待たなければなりません。
この積極的なオファーメカニズムを見ると、あなたは私と同じ気持ちになると信じています。 つまり、効率が比較的低く、以下の問題が発生します:
- 任意のフレームワークの意思決定効率は、全体的な効率に影響を与えます。 一貫性のために、Masterは一度に一つのフレームワークにのみオファーを提供し、フレームワークがオファーを選択するのを待ってから、残りのフレームワークを次のフ このように、任意のフレームワークの意思決定効率は、全体的な効率に影響を与えます。
- リソースを必要としないフレームワークに多くの時間を”無駄にする”。 Mesosは、どのフレームワークがリソースを必要とするかを実際には知りません。 したがって、リソース要件を持つフレームワークがオファーのキューに入っていますが、リソース要件のないフレームワークは頻繁にオファーを受け取ります。
上記の問題に対応して、Mesosは、フレームワークが決定を下すためのタイムアウトを設定したり、フレームワークが抑制状態に設定してオファーを拒否したりするなど、問題を軽減するためのメカニズムを提供しています。 この議論の焦点ではないので、ここでは詳細は無視されます。
実際には、アクティブオファーのこのメカニズムを使用してMesosのためのいくつかの明白な利点があります:
- パフォーマンスは明らかに改善されています。 シミュレーションテストによると、クラスターは最大100,000ノードをサポートでき、Twitterの本番環境では最大のクラスターは80,000ノードをサポートできます。 主な理由は、Mesosマスターメカニズムの積極的な提供がMesosの責任をさらに簡素化することです。 メソスにおける資源スケジューリング,資源からタスクへのマッチングのプロセスは,提供する資源とタスクへの提供の二つの段階に分かれている。 Mesosマスターは、最初のフェーズを完了するための唯一の責任であり、第二段階のマッチングは、フレームワークに残されています。
- より柔軟で、タスクスケジューリングのより責任あるポリシーを満たすことができます。 たとえば、すべてまたはNothingsのリソース使用戦略。
Mesos DRFのスケジューリングアルゴリズム(Dominant Resource Fairness)
DRFアルゴリズムについては、実際にはMesosアーキテクチャの理解とは関係ありませんが、Mesosでは非常にコアで重要
上記のように、Mesosは順番にフレームワークにオファーを提供するので、毎回オファーを提供するためにどのフレームワークを選択すべきですか? これはDRFアルゴリズムによって解決されるべきコア問題です。 基本的な原則は、公平性と効率性の両方を考慮することです。 フレームワークのすべてのリソース要件を満たす一方で、あるフレームワークがあまりにも多くのリソースを消費し、他のフレームワークを餓死させないようにす
DRFは、min-max公平性アルゴリズムの変種です。 簡単に言えば、毎回オファーを提供するために、最も支配的なリソース使用量が最も少ないフレームワークを選択することです。 どのようにフレームワークの支配的なリソース使用量を計算するには? フレームワークが占有するすべてのリソースタイプから、リソース占有率が最も低いリソースタイプが支配的なリソースとして選択されます。 その資源占有率はまさにフレームワークの支配的な資源使用率です。 たとえば、フレームワークのCPUは、全体のリソースの20%、メモリの30%、ディスクの10%を占めています。 したがって、フレームワークの支配的なリソース使用量は10%になり、公式の用語はディスクを支配的なリソースと呼び、この10%は支配的なリソース使用量と呼
DRFの究極の目標は、すべてのフレームワーク間で均等にリソースを配布することです。 フレームワークXがオファーのこのラウンドであまりにも多くのリソースを受け入れる場合、それはオファーの次のラウンドの機会を得るためにはるかに しかし、慎重な読者は、フレームワークがリソースを受け入れた後、それはすぐにそれらを解放し、そうでなければ二つの結果があるだろう、このアルゴリズム:
- 他のフレームワークは餓死します。 あるフレームワークAは一度にクラスター内のほとんどのリソースを受け入れ、タスクは終了せずに実行され続けるため、ほとんどのリソースはフレームワークA
- 餓死する。 このフレームワークの支配的なリソース使用量は常に非常に高いので、長い間オファーを得る機会がないので、より多くのタスクを実行することはできません。
だからMesosは短いタスクのスケジューリングにのみ適しており、Mesosはもともとデータセンターの短いタスク用に設計されていました。
要約
大規模なアーキテクチャから、すべてのスケジューリングシステムのアーキテクチャは、マスター/スレーブアーキテクチャであり、スレーブエンドは、ホスト情報を収集するために使用され、ホスト上のタスクを実行する管理の要件を持つ各マシンにインストールされています。 マスタは主にリソーススケジューリングとタスクスケジューリングを担当しています。 リソーススケジューリングはパフォーマンスに対する要求が高く、タスクスケジューリングはスケーラビリティに対する要求が高くなります。 一般的な傾向は,二つの種類のデューティデカプルを議論し,異なる成分によってそれらを完了することである。
