クラスタリングとKは、Excelでの定義とクラスター分析を意味します
統計定義>クラスタリング/クラスター分析
クラスタリングとは何ですか?
統計におけるクラスタリングとは、以下のような要因によってデータがどのように収集されるか(”クラスタリング”)を指します:
- 年齢…<6871><8063>
- または教育レベル。
データをクラスターにソートすると、データの調査がより多く行われることがあります。 例えば、癌クラスターは、環境内のいくつかの問題を示すことができます。 または、それらは自然がランダムであることの結果である可能性があります。 クラスター分析は、多くの場合主観的である傾向があり、データ内の一般的なスレッドとして認識されるものに依存します。 棒グラフを作成したことがある場合は、すでにクラスターを作成している可能性があります(たとえそれを呼び出さなかったとしても)。 たとえば、犬の品種を示す棒グラフでは、品種別にクラスター化する必要があります(シベリアンハスキー、ボーダーコリー、ジャーマン-シェパード…)または所得水準のグラフは、低、中、高所得水準によってクラスター化される可能性があります。
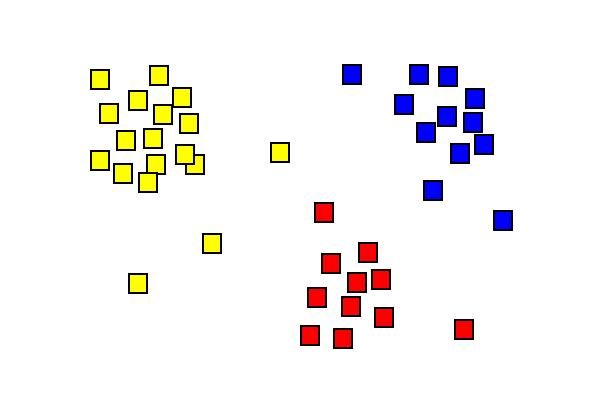
三つの異なる色のクラスタを示すクラスタ解析結果。
クラスターは次のような要因に基づくことができます:
- 距離ベースのクラスタリング。 アイテムは、その近接度(または距離)に基づいてソートされます。 たとえば、がんの症例が同じ地理的位置にある場合は、一緒にクラスター化される可能性があります。
- 項目は、項目に共通する要素によってグループ化されます。 例えば、がんクラスターは、”製造業で働く人々”によってグループ化することができます。”
クラスタリングタイプ
- 排他クラスタリング。 各項目は、単一のクラスターにのみ属することができます。 別のクラスターに属することはできません。
- ファジィクラスタリング:データポイントには、一つ以上のクラスターに属する確率が割り当てられます。
- 各項目は、複数のクラスターに属することができます。
- これは、データマイニングで使用されるクラスタリングに対するより複雑なアプローチです。 基本的に、各アイテムには独自のクラスターが与えられます。 クラスタのペアは、類似性に基づいて結合され、一つのクラスタが少なくなります。 このプロセスは、すべてのアイテムがクラスター化されるまで繰り返されます。 樹枝図は、階層的なクラスターを示すグラフです。
- 確率クラスタリング。 データは、距離または密度を使用して項目を接続するアルゴリズムを使用してクラスター化されます。 これは通常、コンピュータによって実行されます。
- Wardの方法:各ステップで最小分散を使用して、比較的小さな偶数サイズのクラスターを作成します。
Kは、クラスタリング
クラスタリングは、データのセットをより小さなセットにグループ化する単なる方法です。 一連のデータをグループ化するには、定量的(数値を使用)と定性的(カテゴリを使用)の2つの方法があります。 例えば、上の本Amazon.com カテゴリ別(定性的)とベストセラー(定量的)の両方に記載されています。 K-Meansクラスタリングは、定量的な方法を使用してクラスタリングの問題を解決する最も簡単な教師なし学習アルゴリズムの一つです。 それは、コンピューティングの世界では”シンプル”は、実際の生活の中でシンプルに一致していません。 これは実際にはNP困難な問題なので、K-meansクラスタリングにはソフトウェアを使用する必要があります。 あなたのためにこれを実行するいくつかのプログラム(手順のリンクをクリックしてください)は次のとおりです:
- SPSS.
- R
- MATLAB
K-meansクラスタリングアルゴリズムの背後にある一般的な手順は次のとおりです:
- どのように多くのクラスター(k)を決定します。
- kの中心点を異なる場所(通常は互いに離れている場所)に配置します。
- 各データ点をとり、適切な中心点の近くに配置します。 すべてのデータポイントが割り当てられるまで繰り返します。
- k個の新しい中心点をbarycentersとして再計算します。
- 今回は新しい中心点(重心)にデータ点の割り当てを繰り返します。
- 中心点(重心)が動かなくなるまで4と5を繰り返します。
K-Meansクラスタリング:より正式な定義
K-Meansクラスタリングをより正式に定義する方法は、n個のオブジェクトをk(k>1)事前定義されたグループに分類することです。 目標は、各データポイントからクラスターまでの距離を最小限に抑えることです。 つまり、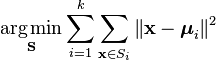
を意味します。:
Xはデータ点
kはクラスター数
uiはSiにおける点の平均です。
クラスター分析と判別分析
クラスター分析は判別分析と非常によく似ています。 両方の方法は、グループに分離することを含む。 ただし、クラスタ分析はグループを識別する方法ですが、判別分析では、分析を開始する前にグループを知る必要があります。 たとえば、異常な行動を持つ精神科患者のグループがあったとしましょう。 クラスター分析は、虐待の歴史を持つ患者、PTSDを持つ患者、または幻覚を経験している患者のような別個のグループを見つけるのに役立ちます。 同じグループの人々に対して判別分析を実行する場合は、グループに配置する前に患者の診断を知っておく必要があります。
Excelでのクラスタリング
Microsoft Excelには、クラスターを作成するためのデータマイニングアドインがあります。 あなたはここで指示を見つけることができます。 ウィザードは、Excelのテーブル、範囲、または分析調査クエリで動作します。 このアドインは、カテゴリの検出ツールとは異なり、カスタマイズできます。 さらに、カテゴリの検出ツールは、テーブルからのデータに限定されます。
を使用するには:
- データマイニングアドインをダウンロードしてインストールします。
- “データマイニング”をクリックし、”クラスター”をクリックし、”次へ”をクリックします。”
- データがどこにあるかをExcelに伝えます。 たとえば、データの範囲を選択します。 クラスタリングページが利用可能になります。
- クラスタリング:自動グループ化のためにそのままにするか、グループの数を指定することができます。
- セグメント:自動グループ化のためにそのままにするか、カテゴリの数を指定します。
Stephanie Glen。 “クラスタリングとKの意味:定義&Excelでのクラスター分析”からStatisticsHowTo.com: 私たちの残りのための基本的な統計! https://www.statisticshowto.com/clustering/
——————————————————————————
宿題やテストの質問の助けが必要ですか? Cheggの調査を使うと、分野の専門家からのあなたの質問に段階的な解決を得ることができます。 Cheggの家庭教師とのあなたの最初の30分は無料です!