共通検索:オープンソースプロジェクトがPageRankを復活させる
刻々と変化する検索マーケティングの風景の私たちの毎日の要約にサインアップします。
注:このフォームを送信することにより、Third Door Mediaの規約に同意したことになります。 私たちはあなたのプライバシーを尊重します。

過去数年間で、GoogleはゆっくりとSEOの専門家に利用可能なデータの量を削減しています。 最初にそれはキーワードデータ、そしてPageRankのスコアだった。 今では(あなたはいくつかのmoolaを費やしている場合を除き)アドワーズ広告から特定の検索量です。 これについての詳細は、Russ Jonesの優れた記事で読むことができます彼の会社の研究の影響と、ボリュームの曖昧さ回避のためのクリックストリームデータへの洞察を詳しく説明しています。
私たちが最近本当に関わってきた項目の一つは、共通のクロールデータです。 私たちの業界には、このデータをしばらく使用しているチームがいくつかありますので、私はゲームに少し遅れていました。 Common Crawl dataは、インターネット全体を一定の間隔で掻き集めるオープンソースプロジェクトです。 ありがたいことに、Amazonは、それがある偉大な会社であること、高いストレージコストなしで多くの人にそれを利用できるようにデータを格納するために
共通のクロールデータに加えて、共通検索と呼ばれる非営利団体があり、その使命は、代替のオープンソースと透明な検索エンジンを作成することです-多くの点 これは、私たち全員が信号を再生し、微調整し、検索エンジンがグラウンドゼロから始めるという膨大な時間の投資なしにどのように動作するかを学
Common Search data
現在、Common Searchでは以下のデータソースを使用して検索ランキングを計算しています(これはウェブサイトから直接取得されています):
- 共通クロール:webクロールデータの最大のオープンリポジトリ。 これは現在、生のページデータのユニークなソースです。
- ウィキデータ: Wikipedia、Wikivoyage、Wikisourceのような多くのウィキメディアプロジェクトの構造化データの中央ストレージとして機能する無料のリンクされたデータベース。
- UT1ブラックリスト:トゥールーズ大学1キャピトルのFabrice Prigentによって管理されているこのブラックリストは、ドメインとUrlを”アダルト”と”フィッシング”を含むいくつかのカテゴリに分類している。”
- DMOZ:Open Directoryプロジェクトとしても知られており、まだ生きている最も古く、最大のwebディレクトリです。 そのデータは、それが過去にあったように信頼性がありませんが、我々はまだ信号やメタデータソースとしてそれを使用しています。
- Web Data Commons Hyperlink Graphs:2012年のCommon Crawl archiveからのすべてのハイパーリンクのグラフ。 現在、ドメイン上の一時的なランキング信号としてその高調波中心性ファイルを使用しています。 私たちは、近い将来にwebグラフの独自の分析を実行する予定です。
- Alexa top1M sites:Alexaは、ページビューとユニークなサイトユーザーの組み合わせの尺度に基づいてwebサイトをランク付けします。 それは人口統計学的に偏っていることが知られています。 私たちは、ドメイン上の一時的なランキング信号としてそれを使用しています。
Common Search ranking
これらのデータソースに加えて、コードを調査する際には、URL長、パス長、ドメインPageRankもアルゴリズムのランキング信号として使用します。 見よ、7月以来、Common SearchはホストレベルのPageRankに独自のデータを持っていましたが、私たちは皆それを見逃していました。
一瞬でPageRank(PR)に到達しますが、一般的なクロール、特にランカーのコードを見直すのは面白いです。ここにあるpyの部分は、あなたが本当にそれがページをランク付けするために使用する信号の重みを微調整して運転席に入ることができるので:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
特に注目すべきことは、Common Searchでは、文書本文およびメタデータに対するキーワードの類似度尺度としてBM25を使用することです。 つまり、キーワードが5回ある200ワードの文書は、同じ回数の1,500ワードの文書よりも関連性が高い可能性があります。
ここでの信号の数は非常に初歩的であり、Googleが検索ランキングアルゴリズムに統合した改良(およびデータ)の多くが明らかに欠けていると言うこと 私たちが取り組んでいる重要なことの1つは、Common CrawlとCommon Searchのインフラストラクチャで利用可能なデータを使用して、キーワードのマッチングだけでなく、セマンティクスに基づいて関連性のあるコンテンツのトピックベクトル検索を行うことです。
On to PageRank
ここのページでは、2016年6月の共通クロールのホストレベルのPageRankへのリンクを見つけることができます。 私は権利を与えられたものを使用していますpagerank-top1m.txt…..gz(トップ100万)他のファイルは3GBで、11200万以上のドメインです。 Rでも、私はキャッピングアウトせずにそれをロードするのに十分なマシンを持っていません。
ダウンロードした後、Rの作業ディレクトリにファイルを持って来る必要があります。Common SearchのPageRankデータは正規化されておらず、私たちが見慣れているクリーンな0-10形式でもありません。 一般的な検索では、”max(0,min(1,float(rank)/244660.58))”—基本的には、ドメインのランクをFacebookのランクで割ったもので、データを0と1の間の分布に変換する方法です。 しかし、これはLinkedinのPageRankを1.4として10でスケーリングしたままにするという点で、いくつかの明確なギャップを残します。

次のコードは、データセットをロードし、pr列をより適切に近似したPRを追加します:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
私たちは、古いGoogleのPRに(私はのためのPRを思い出したドメインのいくつかのサンプルのために)どこかに近いそれを得るために数字で少し遊んでいた。 以下は、PageRankの結果の例です:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
ここに100,000個のランダムサンプルのプロットがあります。 計算されたPageRankスコアはY軸に沿っており、元の共通検索スコアはX軸に沿っています。
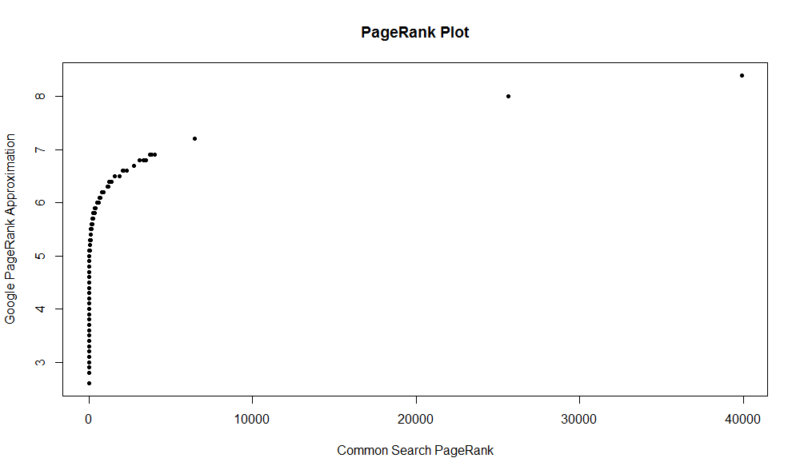
あなた自身の結果をつかむために、あなたはRで次のコマンドを実行することができます(あなた自身のドメインを置き換えるだけです):
df

このデータセットにPageRankによって上の百万の範囲があるだけ、従って共通の調査が指示した112百万の範囲から、かなりよいリンクプロフィールがなければ また、この指標には、リンクの有害性を示すものは含まれておらず、リンクに関するサイトの人気の近似値のみが含まれています。
共通検索は素晴らしいツールであり、素晴らしい基盤です。 私はそこにコミュニティとのより多くの関与を得ることを楽しみにしていますし、うまくいけば、実際に一つに取り組んで、より良い検索エンジン Rと少しのコードを使用すると、数秒で100万ドメインのPRを簡単に確認できます。 あなたが楽しんだことを願っています!
刻々と変化する検索マーケティングの風景の私たちの毎日の要約にサインアップします。
注:このフォームを送信することにより、Third Door Mediaの規約に同意したことになります。 私たちはあなたのプライバシーを尊重します。
著者について

JRオークスは機関車の技術的なSEOの研究のシニアディレクターです。 彼はAdapt Partners agencyのテクニカルSEOのディレクターを務めていました。 彼は、技術的な問題、パフォーマンス、CTR、クロール能力、コンテンツ、およびデータ分析を含む面の広い範囲でクライアントと連携しています。 JRは、困難な検索マーケティングの問題に対するテスト、コーディング、プロトタイピングソリューションを愛しています。 彼が働いていないとき、彼は新興技術について読んで、ベースギターを演奏し、大学バスケットボールを見て、料理をし、彼の友人や家族と時間を過ごすのを楽 また、Raleigh SEO Meetup、Raleigh SEO Conference、およびRTP SEO Meetupの共同主催者の1人でもあります。