分散システムでの時刻同期
あなたが次のようなウェブサイトに精通している場合facebook.com またはgoogle。comは、多分一度よりも少なくないあなたは、これらのウェブサイトは、毎秒数百万または数千万の要求を処理する方法を疑問に思っています。 各要求がエンドユーザーのためにタイムリーに提供できるように、この膨大な量の要求に耐えることができる単一の商用サーバーがありますか?
この問題を深く掘り下げると、私たちは分散システムの概念、すなわち独立したコンピュータ(またはノード)の集まりに到達し、そのユーザーには単一のコヒーレントシステムとして見えます。 ユーザーにとってのこの一貫性の概念は、一度に要求のバッチを処理するために並行して実行される複数のプロセスの形をとる単一の巨大なマシンを しかし、システムインフラストラクチャを理解している人にとって、物事はそれほど簡単ではありません。
複数のタイムゾーンや大陸にまたがる何千もの独立したマシンが同時に実行されている場合、これらのマシンが互いに効率的に協力するためには、(それらが一つに見えるように)いくつかのタイプの同期または調整が与えられなければならない。 このブログでは、時間の同期と、それがイベントの順序と因果関係に関するマシン間の一貫性をどのように達成するかについて説明します。
このブログの内容は以下のように整理されます:
- クロック同期
- 論理クロック
- テイクアウェイ
- 次は何ですか?
物理クロック
集中型システムでは、時間は明確です。 ほぼすべてのコンピュータは、通常、正確に機械加工された水晶と同期して、時間を追跡するための”リアルタイム時計”を持っています。 この水晶の明確に定義された周波数振動に基づいて、コンピュータのOSは正確に内部時間を監視することができます。 コンピュータが遮断されたり、充電が切れたりしても、マザーボードに内蔵されている小さな発電所であるCMOSバッテリーのために、クォーツはダニを続けます。 コンピュータがネットワーク(インターネット)に接続すると、OSはUTC受信機または正確な時計を備えたタイマーサーバーに接続し、NTPとも呼ばれるネットワーク時間
水晶振動子のこの周波数はかなり安定していますが、異なるコンピュータのすべての水晶がまったく同じ周波数で動作することを保証することは すべての水晶がわずかに異なる速度で実行され、時計が徐々に同期しなくなり、読み出し時に異なる値を与えるn台のコンピュータを持つシステムを想像してみてください。 これによって引き起こされる時間値の差は、クロックスキューと呼ばれます。
この状況下では、複数の空間的に分離されたマシンを持つために物事が乱雑になりました。 複数の内部物理クロックの使用が望ましい場合、それらを実世界のクロックとどのように同期させるのですか? どのように我々はお互いにそれらを同期させるのですか?
ネットワークタイムプロトコル
コンピュータ間のペアワイズ同期の一般的なアプローチは、クライアント-サーバー-モデルを使用することです。 2台のマシンAとBを使った次の例を考えてみましょう:
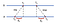
まず、aは値T₀でタイムスタンプされた要求をBに送信します。 Bは、メッセージが到着すると、それ自身のローカルクロックからの受信時刻T₁と応答をt₂でタイムスタンプされたメッセージで記録し、以前に記録された値T₁をピギーバックします。 最後に、Aは、bからの応答を受信すると、到着時間T Βを記録する。 の時間遅れを届けるメッセージを算出Δ₁=T₁-T₀,Δ₂=T₃-T₂. ここで、Bに対するAの推定オフセットは次のようになります:

θに基づいて、aのクロックを遅くするか、二つのマシンが互いに同期できるように固定することができます。
NTPはペア単位で適用可能であるため、Bの時計もAの時計に調整することができます。 ただし、より正確であることがわかっている場合は、Bで時計を調整するのは賢明ではありません。 この問題を解決するために、NTPはサーバーを階層、つまりランク付けサーバーに分割して、ランクの小さいサーバーからのクロックが、ランクの高いサーバーからのクロックに同期されるようにします。
Berkeley Algorithm
正確な時刻同期のためにタイムサーバーに定期的に接続するクライアントとは対照的に、GusellaとZattiは1989年のBerkeley Unix paperで、タイムサーバー(デーモン)が定期的にすべてのマシンをポーリングして何時にあるかを尋ねるクライアントサーバモデルを提案した。 応答に基づいて、メッセージの往復時間を計算し、時間値の外れ値を無視して現在の時刻を平均化し、”他のすべてのマシンに、新しい時刻に時計を進めるか、指定された減少hawが達成されるまで時計を遅くするように指示します”。
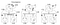
論理クロック
一歩後退し、同期タイムスタンプのベースを再考しましょう。 前のセクションでは、参加しているすべてのマシンのクロックに具体的な値を割り当てますが、今後はシステムの実行中にイベントが発生するグロー しかし、タイムライン全体で本当に重要なのは、関連するイベントが発生する順序です。 例えば、何とかしてみを知る必要のあるイベントが起こる前にイベントBでは、問いませんがTₐ=2のときTᵦ=6以Tₐ=4,Tᵦ=10とTₐ<Tᵦ. これは、同期がLeslie Lamportの”happens-before”関係の定義によって影響される論理クロックの領域に注意を移します。
Lamportの論理クロック
彼の驚異的な1978年の論文Time,Clocks,and The Ordering of Events in A Distributed Systemでは、Lamportは”happens-before”関係”→”を次のように定義しました:
1. Aとbが同じプロセス内のイベントであり、aがbの前に来る場合、a→b。
2。 Aがあるプロセスによるメッセージの送信であり、bが別のプロセスによる同じメッセージの受信である場合、a→b.
3。 A→bとb→cの場合、a→cは次のようになります。.
イベントx,yがメッセージを交換しない異なるプロセスで発生し、x→yもy→xも真でない場合、xとyは同時であると言われます。 すべてのプロセスが一致するイベントに時間値C(a)を割り当てるC関数が与えられたとき、aとbが同じプロセス内のイベントであり、aがbの前に発生する場合、C(a)<C(b)*。 同様に、aがあるプロセスによるメッセージの送信であり、bが別のプロセスによるそのメッセージの受信である場合、C(a)<C(b)**。
ここで、Lamportがイベントに時間を割り当てるために提案したアルゴリズムを見てみましょう。 3つのプロセスA、B、Cのクラスターを持つ次の例を考えてみましょう:

これらの3つのプロセスのクロックは独自のタイミングで動作し、最初は同期していません。 各クロックは、T時間単位ごとに特定の値だけ増分された単純なソフトウェアカウンタで実装することができます。
時刻1では、Aはメッセージm1をBに送信します。到着時に、Bのクロックは内部クロックで10を読み取ります。 メッセージが送信されたのは時間1でタイムスタンプされていたので、プロセスBの値10は確かに可能です(AからBに到着するのに9ティックを要したと推測することができます)。
メッセージm2を考えてみましょう。 15時にBを出発し、8時にCに到着する。 時間が後方に行くことができないので、Cでのこのクロック値は明らかに不可能です。 **とm2が15時に出発するという事実から、16時以降に到着する必要があります。 したがって、Cの現在の時刻値を15より大きく更新する必要があります(簡単にするために時間に+1を追加します)。 つまり、メッセージが到着し、受信者の時計がメッセージの出発を特定するタイムスタンプの前に値を示すと、受信者はその時計を出発時刻よりも1単位の時間に早送りします。 図6では、m2がcでのクロック値を16に補正していることがわかります。 同様に、m3とm4はそれぞれ30と36に到着します。
上記の例から、Maarten van Steen et alはLamportのアルゴリズムを次のように定式化します:
1. イベントを実行する前に(つまり、ネットワーク経由でメッセージを送信する前に、…)、Pᵢはcᵢ:Cᵢ<-Cᵢ+1を増分します。
2. プロセスP∞がプロセスPjにメッセージmを送信すると、プロセスP∞は前のステップを実行した後、mのタイムスタンプts(m)をC∞に設定します。
3. メッセージmを受信すると、プロセスPjは自身のローカルカウンタをCj<-max{Cj,ts(m)}として調整し、その後、最初のステップを実行してメッセージをアプリケーシ
ベクトルクロック
Lamportの”happens-before”関係の定義に戻って、aがbの前に発生するような二つのイベントaとbがある場合、aはbの前の順序、つまりC(a)<C(b)にも配置されます。 しかし、c(a)とC(b)の値を比較するだけでaがbの前に行くと推論することはできないので、これは逆の因果関係を意味するものではありません(証
タイムスタンプに基づいてイベントの順序に関するより多くの情報を導出するために、Lamportの論理クロックのより高度なバージョンであるVector Clocksが提案されている。 システムの各プロセスP∞について、アルゴリズムは、
1の属性を持つベクトルVC∞を維持します。 VCᵢ:Pᵢのローカル論理クロック、または現在のタイムスタンプの前に発生したイベントの数。
2. VC Θ=kの場合、P ΘはkイベントがPjで発生したことを知っています。
ベクトルクロックのアルゴリズムは次のようになります:
1. イベントを実行する前に、PᵢはVCᵢ<-VCᵢ+1を実行することによって、新しいイベントが発生したことを記録します。
2. P∞がメッセージmをPjに送信すると、p∞は前のステップを実行した後、testamp t s(m)をVC∞に等しく設定する。
3. メッセージmが受信されると、プロセスPjは、それ自身のベクトルクロックの各kを更新する:VCj≤max{VCj,ts(m)}。 その後、最初のステップの実行を続行し、メッセージをアプリケーションに配信します。
これらのステップにより、プロセスPjがプロセスpᵢからタイムスタンプts(m)のメッセージmを受信すると、プロセスpjはmの送信に先立ってpᵢで発生したイベントの数を知っています。さらに、Pjはmを送信する前に他のプロセスについてPᵢに知られていたイベントについても知っています(このアルゴリズムをゴシッププロトコル🙂に関連させている場合はそうです)。
うまくいけば、説明はあなたがあまりにも長い間あなたの頭を傷つけないようにします。 のは、概念を習得するための例に飛び込むしてみましょう:

この例では、三つのプロセスP₁、P₂、P₃があり、代わりにメッセージを交換してクロックを一緒に同期させます。 P∞は、論理時間VC∞=(1,0,0)のメッセージm1をP∞に送信する(ステップ1)。 P₂、タイムスタンプts(m1)でm1を受信すると) = (1, 0, 0), 論理時間VC Θを(1,1,0)に調整し(ステップ3)、メッセージm2をtimestamp(1,2,0)でP Θに戻します(ステップ1)。 同様に、プロセスP∞は、p∞からメッセージm2を受け取り、その論理クロックを(2,2,0)に変更し(ステップ3)、その後、メッセージm3を(3,2,0)でP∞に送 P∞は、p∞からメッセージm3を受信した後、そのクロックを(3,2,1)に調整する(ステップ1)。 その後、(1,4,0)でP∞によって送信されたメッセージm4を取り込み、それにより、そのクロックを(3,4,2)に調整する(ステップ3)。
同期のために内部クロックをどのように早送りするかに基づいて、すべてのkについてts(a)≤ts(b)であり、ts(a)<ts(b)であるインデックスk’が少な (2,2,0)が(3,2,1)の前にあることを確認するのは難しくありませんが、(1,4,0)と(3,2,0)は互いに競合する可能性があります。 したがって、ベクトルクロックを使用すると、2つのイベントの間に因果関係があるかどうかを検出できます。
Take away
分散システムにおける時間の概念に関しては、主な目標はイベントの正しい順序を達成することです。 イベントは、物理クロックを使用して時系列順に配置するか、Lamtportの論理クロックと実行タイムラインに沿ったベクトルクロックを使用して論理順に配置することができます。
次は何ですか?
次のシリーズでは、時間同期が分散システムのいくつかの古典的な問題に対する驚くほど簡単な答えを提供する方法について説明します。
Leslie Lamport:分散システムにおける時刻、時計、およびイベントの順序。 1978.
Barbara Liskov:分散システムにおける同期クロックの実用的な使用。 1993.
Maarten van Steen,Andrew S.Tanenbaum:分散システム。 2017.
Barbara Liskov,Liuba Shrira,John Wroclawski: 同期されたクロックに基づく効率的な最大一度のメッセージ。 1991.
Cary G.Gray,David R.Cheriton:リース:分散ファイルキャッシュの一貫性のための効率的なフォールトトレラントなメカニズム。 1989.
Ricardo Gusella,Stefano Zatti:Berkeley UNIX4.3BSDのTEMPOによって達成されたクロック同期の精度。 1989.