Scyllaでのスケーラブルな分散セカンダリインデックス

ScyllaおよびApache Cassandraのデータモデルは、データベース-スキーマで定義されているパーティションキーを使用してクラスタ-ノード間でデータを分割します。 パーティションキーを使用すると、パーティションキーをハッシュすることで行を所有するノードを見つけることができるため、パーティションキーを使用して行を検索する効率的な方法が提供されます。 残念ながら、これはまた、非パーティションキーを使用して行を検索するには、非効率的なフルテーブルスキャンが必要であることを意味します。 セカンダリインデックスはApache Cassandraのメカニズムで、インデックスを作成することによってパーティションキー以外を効率的に検索できます。このブログ記事を参照しているブログ一覧:
:
- Apache Cassandraがローカルインデックスを使用してセカンダリインデックスを実装する方法
- グローバルインデックスを使用してScyllaの別の実装戦略を取ることにした理由
- グローバルインデックスを使用する方法セカンダリインデックスを使用する方法
- 独自のセカンダリインデックスを作成し、アプリケーションCQLクエリで使用する方法
背景
インデックスのサイズは、インデックス付きデータのサイズに比例します。 ScyllaとApache Cassandraのデータは複数のノードに分散されているため、インデックス全体を単一のノードに格納することは現実的ではありません。 Apache Cassandraはセカンダリインデックスをローカルインデックスとして実装しています。 ローカルインデックスの利点は、書き込みが非常に高速であることですが、欠点は、読み取りが潜在的にすべてのノードを照会して、ルックアップを実行す ネイティブのセカンダリインデックスに加えて、Apache Cassandraには、複雑なクエリと検索をサポートする別のローカルインデックススキームSSTable Attached Secondary Index(SASI)もあります。 しかし、スケーラビリティの観点からは、元のセカンダリインデックスとまったく同じ特性を持っています。
ScyllaとApache Cassandraのマテリアライズドビューは、別のパーティションキーを使用してベーステーブルからビューテーブルにデータを自動的に非正規化するメカニズムです。 これにより、ローカルインデックスのスケーラビリティの問題は解決されますが、最悪の場合にはテーブル全体を複製する必要があるため、ストレー したがって、マテリアライズドビューは、すべてのユースケースでセカンダリインデックスに代わるものではありません。 しかし、マテリアライズドビューは、Scyllaの実装アプローチであるグローバルインデックスを使用してセカンダリインデックスを実装するために必要な
Global Indexing
ScyllaはApache Cassandraとは異なるアプローチをとり、global indexingを使用してセカンダリインデックスを実装します。 グローバルインデックスを使用すると、インデックスごとにマテリアライズドビューが作成されます。 マテリアライズドビューには、インデックス付き列がパーティションキーとして、インデックス付き行の主キー(パーティションキーとクラスタリングキー)がクラスタリングキーとして設定されています。 Scyllaは、インデックス付きクエリを二つの部分に分割します:(1)インデックス付きテーブルのパーティションキーを取得するためのインデックステーブル上のクエリと、(2)取得されたパーティションキーを使用してインデックス付きテーブルへのクエリです。 このアプローチの利点は、インデックス付き列の値を使用して、クラスター内の対応するインデックステーブル行を見つけることができるため、読み取りがス このアプローチの欠点は、インデックスビューを最新の状態に保つことによるすべてのオーバーヘッドのために、ローカルインデックスの場合よりも書
インデックス付き列に対するクエリは次のようになります。 次のようなテーブルを想定しましょう:
パーティションキーではなく、インデックスを持つemail列に対するクエリ:
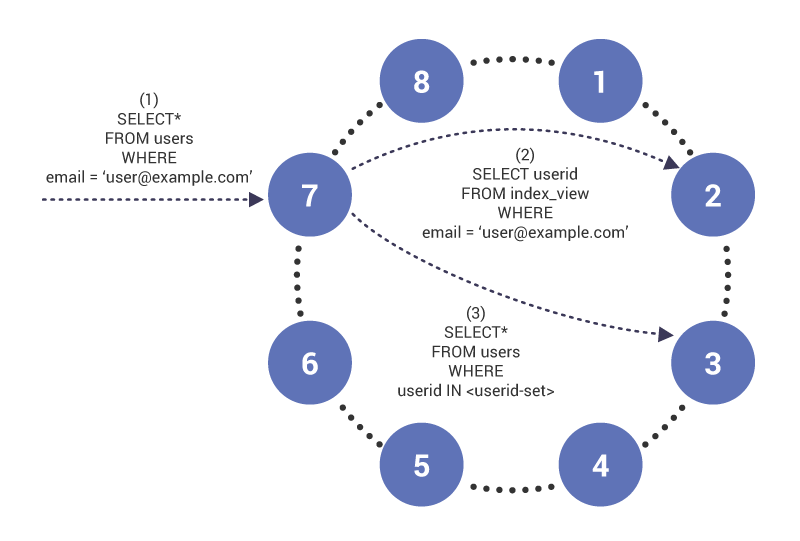
フェーズ(1)では、クエリはノード7に到着し、クエリのコーディネーターとして機能します。 ノードは、インデックス付きの列を照会していることに気付き、フェーズ(2)では、””のインデックステーブル行を持つノード2のインデックステーブルへの読み取りを発行します。 このクエリは、インデックス付きテーブルの内容を取得するためにphase(3)で使用される一連のユーザー Idを返します。
例
最初にスキーマを作成する必要があります。 この例では、useridをパーティションキーとして、name、email、countryを通常の列として持つユーザー情報を表すテーブルがあります。
次に、mockarooで生成されたテストデータをテーブルに:
セカンダリインデックスは、パーティションキー以外の列を効率的に照会できるように設計されています。 Apache CassandraはALLOW FILTERINGを使用したパーティションキー以外の列に対するクエリもサポートしていますが、これは非常に非効率的で(テーブル全体のスキャンが必要です)、現在Scylla
CREATE INDEX文を使用して、表の列に索引を付けることができます。 たとえば、email列とcountry列のインデックスを作成するには、次のCQLステートメントを実行します:
Scyllaは、インデックス付き列をパーティションキーとして、ターゲットテーブルの主キー(パーティションキーとクラスタリングキー)をクラスタリングキーとして持つマテリアライズドビューを自動的に作成します。
たとえば、email列のインデックスのマテリアライズドビューは次のようになります。
上記のビューが通常のテーブルとして作成される場合、効果的には次のよ:
email列はインデックステーブルのパーティションキーとして使用され、useridはクラスタリングキーとして含まれているため、emailだけを使用してターゲットテーブルのパーティションキーを効率的に見つけることができます。
DESCRIBEコマンドを使用すると、作成されたインデックスとビューを含むks.usersテーブルのスキーマ全体を表示できます:
これで、セカンダリインデックスを使用して、インデックス付き列をパーティションキーであるかのようにクエリできます。
この例は完了です。
セカンダリインデックスを使用する場合はどうすればよいですか?
セカンダリインデックスは、アプリケーションに対して(ほとんど)透過的です。 クエリはテーブル内のすべての列にアクセスでき、アプリケーションを変更せずにインデックスを追加および削除できます。 セカンダリインデックスは、マテリアライズドビューのようにクエリされた列ではなく、インデックス付き列と主キーのみを複製する必要があるため、 さらに、同じ理由で、主キーとインデックス付き列の変更のみがインデックスビューで更新されるため、セカンダリインデックスでの更新の方が効率的 マテリアライズドビューの場合、ビューに表示される列のいずれかを更新するには、バッキングビューを更新する必要があります。
いつものように、セカンダリインデックスまたはマテリアライズドビューを使用するかどうかの決定は、実際にはアプリケーションの要件に依存 最大のパフォーマンスが必要で、特定の列セットを照会する可能性が高い場合は、マテリアライズドビューを使用する必要があります。 ただし、アプリケーションが異なる列セットを照会する必要がある場合は、アプリケーションのニーズに応じて記憶域のオーバーヘッドを少なくして追加およ
セカンダリインデックスについてもっと知りたいですか? SlideShareのScylla Summit2017からの私のプレゼンテーションをチェックしてください。 この機能を試してみたい場合は、今後のScylla2.2リリースに予定されています。