공통 검색:페이지 랭크를 되 찾는 오픈 소스 프로젝트
끊임없이 변화하는 검색 마케팅 풍경의 우리의 일상 요점의 반복에 가입.
참고:이 양식을 제출하면 세 번째 문 미디어의 약관에 동의하게됩니다. 우리는 귀하의 개인 정보를 존중합니다.

지난 몇 년 동안,구글은 천천히 현서 실무자에 사용할 수있는 데이터의 양을 감소시켰다. 먼저 키워드 데이터 였고 페이지 랭크 점수였습니다. (일부 물라 지출하지 않는 한)지금은 애드워즈에서 특정 검색 볼륨입니다. 당신은 볼륨 명확성에 대한 클릭 스트림 데이터에 대한 자신의 회사의 연구와 통찰력의 영향을 자세히 러스 존스의 우수한 기사에서이에 대한 자세한 내용을보실 수 있습니다.
최근에 우리가 실제로 참여한 항목 중 하나는 일반적인 크롤링 데이터입니다. 이 몇 시간 동안이 데이터를 사용하고 우리 업계에서 여러 팀이있다,그래서 나는 게임에 조금 늦게 느꼈다. 일반적인 크롤링 데이터는 정기적으로 전체 인터넷을 긁는 오픈 소스 프로젝트입니다. 고맙게도,아마존,그것이 위대한 회사 인,높은 스토리지 비용없이 많은 사람들이 사용할 수 있도록 데이터를 저장하기 위해 투구.
일반적인 크롤링 데이터뿐만 아니라,누구의 임무 대안 오픈 소스와 투명한 검색 엔진을 만드는 것입니다 일반 검색이라는 비영리 단체가 있습니다-반대,여러면에서,구글의. 이것은 우리 모두가 재생 조정할 및 검색 엔진이 그라운드 제로에서 시작의 거대한 시간 투자없이 작동하는 방법을 배울 수있는 신호를 난도질 할 수 있다는 것을 의미하기 때문에 내 관심을 감정을 상하게.
일반 검색 데이터
현재 일반 검색은 검색 순위를 계산하기 위해 다음 데이터 소스를 사용합니다(이는 웹 사이트에서 직접 가져옵니다):
- 공통 크롤링:웹 크롤링 데이터의 가장 큰 오픈 리포지토리입니다. 이것은 현재 원시 페이지 데이터의 고유 한 소스입니다.
- 위키데이터: 위키 백과,위키 여행 및 위키 소스와 같은 많은 위키 미디어 프로젝트의 구조화 된 데이터를위한 중앙 저장소 역할을하는 무료 연결된 데이터베이스입니다.이 블랙리스트는 도메인과 사이트를”성인”및”피싱”과 같은 여러 범주로 분류합니다.”
- 디모즈:또한 오픈 디렉토리 프로젝트로 알려진,그것은 아직 살아 가장 오래되고 가장 큰 웹 디렉토리입니다. 그 데이터는 과거만큼 신뢰할 수는 없지만,우리는 여전히 신호 및 메타 데이터 소스로 사용합니다.
- 웹 데이터 커먼즈 하이퍼 링크 그래프:2012 공통 크롤링 아카이브의 모든 하이퍼 링크의 그래프. 우리는 현재 도메인에 임시 순위 신호로 고조파 중심성 파일을 사용하고 있습니다. 우리는 가까운 장래에 웹 그래프에 대한 자체 분석을 수행 할 계획입니다.
- 알렉사 상위 100 만 사이트:알렉사는 페이지 뷰와 고유 사이트 사용자의 결합 측정을 기반으로 웹 사이트 순위. 인구 통계적으로 편향된 것으로 알려져 있습니다. 우리는 도메인에 임시 순위 신호로 사용하고 있습니다.
일반적인 검색 순위
이러한 데이터 소스 외에도 코드를 조사 할 때 알고리즘에서 순위 신호로 주소 길이,경로 길이 및 도메인 페이지 랭크를 사용합니다. 보라,7 월 이후,일반적인 검색은 호스트 수준의 페이지 랭크에 대한 자체 데이터를 가지고 있으며,우리 모두는 그것을 놓쳤다.
나는 잠시 페이지 랭크(홍보)에 도착합니다,하지만 일반적인 크롤링의 코드를 검토하는 것이 재미있다,특히 랭커.당신이 정말로 페이지 순위를 사용하는 신호의 무게를 조정과 운전석에 들어갈 수 있기 때문에 평 부분은,여기에 있습니다:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
특히 참고,뿐만 아니라,일반적인 검색은 문서 본문 및 메타 데이터에 키워드의 유사성 측정으로 비엠 25 를 사용한다는 것입니다. 즉,키워드가 5 배인 200 단어 문서는 동일한 횟수를 갖는 1,500 단어 문서보다 관련성이 높다는 의미입니다.
그것은 여기에 신호의 수는 매우 기초적이고 분명히 구글이 검색 순위 알고리즘에 통합 한 개선(데이터)의 많은 누락 말할 가치가있다. 우리가 작업하고 있는 핵심 사항 중 하나는 공통 크롤링 및 공통 검색의 인프라에서 사용할 수 있는 데이터를 사용하여 키워드 일치뿐 아니라 의미 체계를 기반으로 관련된 콘텐츠에 대한 주제 벡터 검색을 수행하는 것입니다.
페이지 랭크에
여기 페이지에서 2016 년 6 월 공통 크롤링에 대한 호스트 수준 페이지 랭크에 대한 링크를 찾을 수 있습니다. 나는 자격이 하나를 사용하고 있습니다 pagerank-top1m.txt.지즈(최고 1 백만)다른 파일은 3 기가 바이트 이상 112,000,000 도메인이기 때문에. 심지어 연구에서,나는 밖으로 모자를 씌우지 않고 그것을로드 할 수있는 충분한 기계가 없습니다.일반적인 검색에서 페이지 랭크 데이터는 정규화되지 않으며 또한 우리 모두가 그것을 보는 데 사용되는 깨끗한 0-10 형식이 아닙니다. 일반적인 검색은”최대(0,최소(1,플로트(순위)/244660.58))”—기본적으로,도메인의 순위는 페이스 북의 순위로 나눈—0 과 1 사이의 분포로 데이터를 변환하는 방법으로.. 그러나 이것은 링크드 인의 페이지 랭크를 10 으로 확장 할 때 1.4 로 남겨 둘 것이라는 점에서 명확한 격차를 남깁니다.

다음 코드는 데이터 집합을 로드하고 더 근사한 홍보 열을 추가합니다:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
우리는 오래된 구글 홍보에 어딘가에 가까운(내가 홍보를 기억 도메인의 여러 샘플)를 얻기 위해 숫자와 조금 놀러했다. 다음은 몇 가지 예제 페이지 랭크 결과입니다:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
여기에 100,000 개의 무작위 샘플이 있습니다. 계산된 페이지 랭크 점수는 와이-축을 따라,원래의 공통 검색 점수는 엑스-축을 따라.
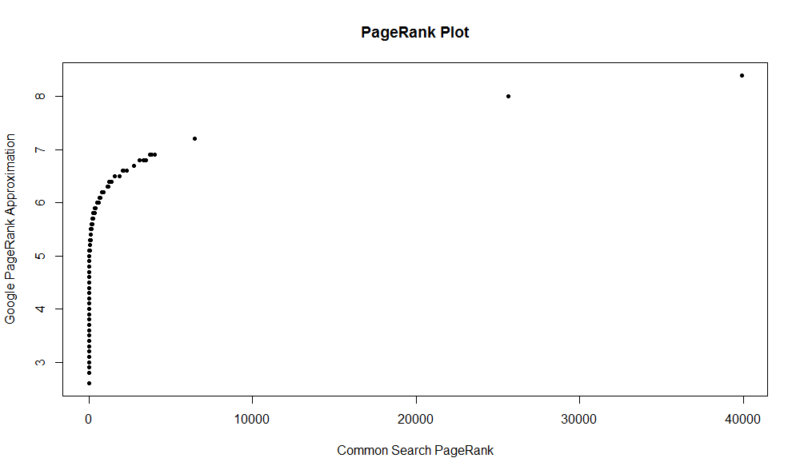
에서 다음 명령을 실행할 수 있습니다.:
df

이 데이터 세트는 페이지 랭크에 의해 상위 백만 도메인을 가지고 있음을 알아 두셔야합니다,그래서 중 112 일반적인 검색 색인 만 도메인,그것은 꽤 좋은 링크 프로파일이없는 경우 귀하의 사이트가 없을 수 있습니다 좋은 기회가있다. 또한,이 메트릭에는 링크의 유해성에 대한 표시가 없으며 링크와 관련하여 사이트의 인기도에 대한 근사치 만 포함됩니다.
일반 검색은 훌륭한 도구이자 훌륭한 기초입니다. 나는 거기에 지역 사회와 더 많은 참여를 얻고 희망 실제로 하나의 작업에 의해 더 나은 검색 엔진 뒤에 볼트와 너트를 이해하는 학습을 기대하고 있습니다. 연구 및 약간의 코드,당신은 초 만에 백만 도메인에 대한 홍보를 확인하는 빠른 방법을 가질 수 있습니다. 당신이 즐길 희망!
끊임없이 변화하는 검색 마케팅 풍경의 우리의 일상 요점의 반복에 가입.
참고:이 양식을 제출하면 세 번째 문 미디어의 약관에 동의하게됩니다. 우리는 귀하의 개인 정보를 존중합니다.
저자에 관하여
