클러스터링 및 케이 의미:엑셀의 정의 및 클러스터 분석
통계 정의>클러스터링/클러스터 분석
클러스터링이란?
통계의 클러스터링은 다음과 같은 요인에 의해 데이터가 수집되는 방법(“클러스터링”)을 나타냅니다:
- 나이.
- 가구 크기.
- 수입.
- 또는 교육 수준.
데이터를 클러스터로 정렬하면 데이터를 더 자세히 조사할 수 있습니다. 예를 들어,암 클러스터는 환경의 일부 문제를 나타낼 수 있습니다. 또는,그들은 단지 무작위 인 자연의 결과 일 수 있습니다. 클러스터 분석은 대부분의 경우 주관적인 경향이 있으며,데이터에서 공통 스레드로 인식되는 내용에 따라 다릅니다. 이 기술은 통계의 새로운 정말 아무것도 아니다;혹시 막대 그래프를 만든 적이 있다면,당신은 아마 이미(당신이 그것을 호출하지 않은 경우에도)클러스터를 만들었습니다. 예를 들어,강아지의 품종을 보여주는 막대 그래프는 품종(시베리안 허스키,보더 콜리,독일 셰퍼드…)에 의해 클러스터에 당신을 필요로하거나 소득 수준의 차트는 낮은 중간 및 높은 소득 수준에 의해 클러스터 될 수 있습니다.
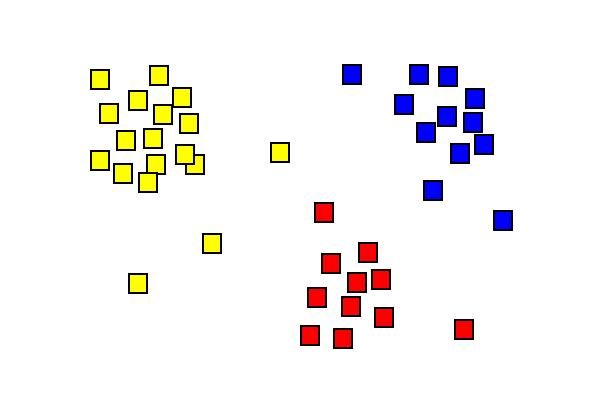
세 가지 다른 색깔의 클러스터를 보여주는 클러스터 분석 결과.
클러스터는 다음과 같은 요소를 기반으로 할 수 있습니다:
- 거리 기반 클러스터링. 항목은 근접(또는 거리)에 따라 정렬됩니다. 예를 들어,동일한 지리적 위치에 있는 경우 암 사례가 함께 클러스터될 수 있습니다.
- 개념적 클러스터링. 항목은 항목에 공통적인 요소별로 그룹화됩니다. 예를 들어,암 클러스터는”제조 분야에서 일하는 사람들”에 의해 그룹화 될 수 있습니다.”
클러스터링 유형
- 단독 클러스터링. 각 항목은 단일 클러스터에만 속할 수 있습니다. 다른 클러스터에 속할 수 없습니다.
- 퍼지 클러스터링:데이터 포인트에는 하나 이상의 클러스터에 속할 확률이 할당됩니다.
- 겹치는 클러스터링. 각 항목은 둘 이상의 클러스터에 속할 수 있습니다.
- 계층적 클러스터링. 이는 데이터 마이닝에 사용되는 클러스터링에 대한보다 복잡한 접근 방식입니다. 기본적으로 각 항목에는 자체 클러스터가 제공됩니다. 한 쌍의 클러스터는 유사성을 기반으로 결합되어 하나의 클러스터를 줄입니다. 이 프로세스는 모든 항목이 클러스터될 때까지 반복됩니다. 덴드로그램은 계층적 클러스터를 보여주는 그래프입니다.
- 확률 적 클러스터링. 데이터는 거리 또는 밀도를 사용하여 항목을 연결하는 알고리즘을 사용하여 클러스터됩니다. 이것은 일반적으로 컴퓨터에 의해 수행됩니다.
- 워드의 방법:각 단계에서 최소 분산을 사용하여 비교적 작고 균일 한 크기의 클러스터를 만듭니다.
케이 의미 클러스터링
클러스터링은 데이터 집합을 더 작은 집합으로 그룹화하는 방법 일뿐입니다. 데이터 집합을 그룹화 할 수있는 두 가지 방법은 정량적으로(숫자를 사용하여)및 질적으로(범주를 사용하여)입니다. 예를 들어,에 대한 책 Amazon.com 카테고리(질적)및 베스트 셀러(양적)로 나열됩니다. 이것은 수학적으로 정확한 유형 계층구조인,강력한 타입을 정의합니다. 즉,컴퓨팅 세계에서”단순한”것은 실제 생활에서 단순한 것과 동일하지 않습니다. 이것은 실제로 순이익-하드 문제입니다,그래서 당신은 소프트웨어를 사용하는 것이 좋습니다 케이-클러스터링을 의미. 이 작업을 수행하는 일부 프로그램(절차에 대한 링크를 클릭)은 다음과 같습니다:
- 스피.
- r
- MATLAB
일반적인 단계 뒤에 K-means clustering 알고리즘:
- 결정 얼마나 많은 클러스터(k).
- 케이 중앙 점을 다른 위치에 놓습니다(일반적으로 서로 멀리 떨어져 있음).
- 각 데이터 포인트를 가져와 적절한 중앙 지점에 가깝게 배치합니다. 모든 데이터 요소가 할당될 때까지 반복합니다.
- 케이 새로운 중앙 점을 중점 중심으로 다시 계산합니다.
- 이번에는 새 중앙 지점(중앙 중심)에 데이터 포인트 할당을 반복합니다.
- 중앙점(중점)이 더 이상 움직이지 않을 때까지 4 와 5 를 반복합니다.
케이-클러스터링을 의미합니다:보다 공식적인 정의
케이-클러스터링을 정의하는 더 공식적인 방법은 엔 객체를 케이(케이>1)미리 정의 된 그룹으로 분류하는 것입니다. 목표는 각 데이터 요소에서 클러스터까지의 거리를 최소화하는 것입니다. 즉,찾기: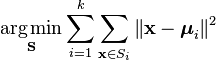
여기서:이 경우 클러스터 수를 계산하려면 클러스터 수를 계산해야합니다.
군집 분석 대 판별 분석
군집 분석은 판별 분석과 매우 유사합니다. 두 방법 모두 그룹으로 분리를 포함합니다. 그러나 군집 분석은 그룹을 식별하는 방법이지만 판별 분석은 분석을 시작하기 전에 그룹을 알아야 합니다. 예를 들어,비정상적인 행동을 가진 정신과 환자 그룹이 있다고 가정 해 봅시다. 군집 분석은 학대의 역사를 가진 환자,외상 후 스트레스 장애를 가진 사람들,또는 환각을 경험하는 사람들과 같은 별개의 그룹을 찾는 데 도움이 될 수 있습니다. 동일한 그룹의 사람들에 대해 판별 분석을 실행하려면 환자의 진단을 그룹으로 배치하기 전에 알아야 합니다.
엑셀 클러스터링
마이크로 소프트 엑셀은 클러스터를 만들기위한 데이터 마이닝 추가 기능이 있습니다. 여기에서 지침을 찾을 수 있습니다. 마법사는 엑셀 테이블,범위 또는 분석 조사 쿼리와 함께 작동합니다. 이 추가 기능은 범주 검색 도구와 달리 사용자 지정할 수 있습니다. 또한 범주 검색 도구는 테이블의 데이터로 제한됩니다.
사용:
- 데이터 마이닝 추가 기능을 다운로드하여 설치합니다.
- “데이터 마이닝”을 클릭한 후”클러스터”,”다음”을 클릭합니다.”
- 데이터가 어디에 있는지 엑셀에 알리십시오. 예를 들어 데이터 범위를 선택합니다. 클러스터링 페이지를 사용할 수 있게 됩니다.
- 클러스터링:자동 그룹화를 위해 그대로 두거나 여러 그룹을 지정할 수 있습니다.
- 세그먼트:자동 그룹화를 위해 그대로 두거나 여러 범주를 지정합니다.
스테파니 글렌. “클러스터링 및 케이 의미:정의&엑셀의 클러스터 분석”에서 StatisticsHowTo.com: 우리의 나머지 부분에 대한 초등학교 통계! https://www.statisticshowto.com/clustering/
——————————————————————————
숙제 또는 시험 문제에 도움이 필요하십니까? 체그 연구,당신은 분야의 전문가로부터 질문에 대한 단계별 솔루션을 얻을 수 있습니다. 체그 교사와 처음 30 분은 무료입니다!