Cloud Data Warehouse vs Tradisjonelle Datalager Konsepter
Skybaserte datalager er den nye normen. Borte er de dagene hvor bedriften måtte kjøpe maskinvare, opprette serverrom og leie, trene og vedlikeholde et dedikert team av ansatte for å kjøre den. Nå, med noen få klikk på den bærbare datamaskinen og et kredittkort, kan du få tilgang til praktisk talt ubegrenset datakraft og lagringsplass.
dette betyr imidlertid ikke at tradisjonelle datavarehusideer er døde. Klassisk datavarehus teori underbygger det meste av hva skybaserte datavarehus gjør.
i denne artikkelen vil vi forklare de tradisjonelle datavarehuskonseptene du trenger å vite og de viktigste skyen fra et utvalg av de beste leverandørene: Amazon, Google og Panoply. Til slutt vil vi avslutte med en kost-nytte-analyse av tradisjonelle vs. cloud data warehouses, slik at du vet hvilken som er riktig for deg.
La oss komme i gang.
- Tradisjonelle Datavarehus Konsepter
- Fakta, Dimensjoner Og Tiltak
- Normalisering Og Denormalisering
- Datamodeller
- Faktatabell
- Star Schema vs Snowflake Schema
- OLAP vs OLTP
- Tre Lags Arkitektur
- Virtuelt Datalager / Data Mart
- Kimball vs Inmon
- ETL vs ELT
- Enterprise Data Warehouse
- Konsepter For Datalager I Skyen
- Cloud Data Warehouse Concepts-Amazon Redshift
- Klynger
- Noder
- Partisjoner/Skiver
- Kolonnelagring
- Komprimering
- Data Lasting
- Cloud Database Warehouse – Google BigQuery
- Serverløs Tjeneste
- Colossus File System
- Dremel Execution Engine
- Datadeling
- Streaming Og Batch Inntak
- Cloud Data Warehouse Concepts – Panoply
- Primærnøkler
- Inkrementelle Taster
- Nestede Data
- Historikktabeller
- Transformasjoner
- Strengformater
- Databeskyttelse
- Tilgangskontroll
- Ip-Hvitelisting
- Konklusjon: Tradisjonelle vs. Datavarehus Konsepter I Korte Trekk
- Tradisjonelle Datavarehus Konsepter
- Cloud Data Warehouse Concepts-Amazon Redshift som Eksempel
- Cloud Data Warehouse Concepts-BigQuery Som Eksempel
- Tradisjonell vs Sky Kost-Nytte Analyse
- Lær Mer Om Datalager
Tradisjonelle Datavarehus Konsepter
et datavarehus er et system som samler data fra en rekke kilder i en organisasjon. Datalagre brukes som sentraliserte datalagre for analyse-og rapporteringsformål.
et tradisjonelt datalager ligger på stedet på kontorene dine. Du kjøper maskinvaren, serverrommene og ansetter de ansatte til å kjøre den. De kalles også lokale, lokale eller (grammatisk feil) lokale datalager.
Fakta, Dimensjoner Og Tiltak
kjernebyggeblokkene for informasjon i et datalager er fakta, dimensjoner og tiltak.
et faktum er den delen av dataene som angir en bestemt forekomst eller transaksjon. For eksempel, hvis bedriften selger blomster, noen fakta du vil se i datalager er:
- Solgt 30 roser i butikken for $19.99
- Bestilte 500 nye blomsterpotter Fra Kina for $1500
- Betalt lønn kasserer for denne måneden $1000
Flere tall kan beskrive hvert faktum, og vi kaller disse tallene tiltak. Noen tiltak for å beskrive det faktum ‘bestilt 500 nye blomsterpotter Fra Kina for $1500’ er:
- antall bestilt-500
- Kostnad – $1500
når analytikere jobber med data, utfører de beregninger på tiltak (f.eks. sum, maksimum, gjennomsnitt) for å få innsikt. For eksempel vil du kanskje vite det gjennomsnittlige antall blomsterpotter du bestiller hver måned.
en dimensjon kategoriserer fakta og tiltak og gir strukturert merkingsinformasjon for dem – ellers ville de bare være en samling uordnede tall! Noen dimensjoner for å beskrive det faktum ‘bestilt 500 nye blomsterpotter Fra Kina for $1500’ er:
- Land kjøpt Fra-Kina
- tid kjøpt-1 pm
- Forventet ankomstdato – 6. juni
du kan ikke utføre beregninger på dimensjoner eksplisitt, og det vil sannsynligvis ikke være veldig nyttig-hvordan kan du finne ‘gjennomsnittlig ankomstdato for bestillinger’? Det er imidlertid mulig å lage nye tiltak fra dimensjoner, og disse er nyttige. Hvis du for eksempel vet gjennomsnittlig antall dager mellom ordredato og ankomstdato, kan du bedre planlegge lagerkjøp.
Normalisering Og Denormalisering
Normalisering Er prosessen med effektivt å organisere data i et datalager (eller et annet sted som lagrer data). Hovedmålet er å redusere dataredundans-dvs. fjerne dupliserte data – og forbedre dataintegritet-dvs. forbedre nøyaktigheten av data. Det er forskjellige nivåer av normalisering og ingen konsensus for den ‘beste’ metoden. Alle metoder innebærer imidlertid lagring av separate, men relaterte opplysninger i forskjellige tabeller.
det er mange fordeler med normalisering, for eksempel:
- Raskere søking og sortering på hver tabell
- Enklere tabeller gjør data modifikasjonskommandoer raskere for å skrive og utføre
- Mindre redundante data betyr at du sparer på diskplass, og slik at du kan samle inn og lagre flere data
Denormalisering er prosessen med bevisst å legge til overflødige kopier eller grupper av data til allerede normaliserte data. Det er ikke det samme som ikke-normaliserte data. Denormalisering forbedrer leseytelsen og gjør det mye enklere å manipulere tabeller i skjemaer du vil ha. Når analytikere jobber med datalager, utfører de vanligvis bare leser på dataene. Dermed kan denormaliserte data spare dem store mengder tid og hodepine.
Fordeler med denormalisering:
- Færre tabeller minimerer behovet for tabellkoblinger, noe som øker dataanalytikernes arbeidsflyt og fører dem til å oppdage mer nyttig innsikt i dataene
- Færre tabeller forenkler spørringer som fører til færre feil
Datamodeller
Det ville være svært ineffektivt å lagre alle dataene dine i en massiv tabell. Datalageret ditt inneholder derfor mange tabeller som du kan slå sammen for å få spesifikk informasjon. Hovedtabellen kalles et faktatabell, og dimensjonstabeller omgir den.
det første trinnet i å designe et datalager er å bygge en konseptuell datamodell som definerer dataene du vil ha, og relasjonene på høyt nivå mellom dem.
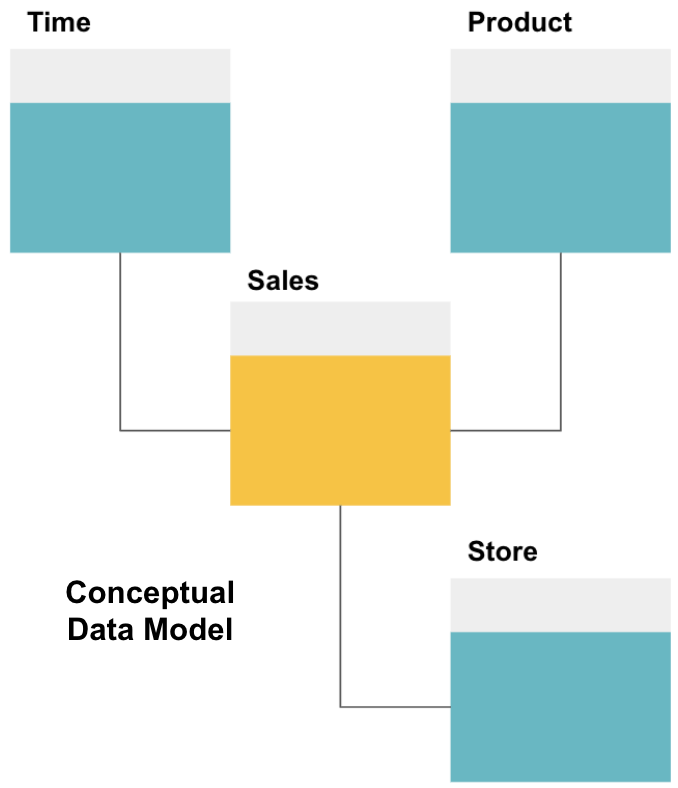
Her har vi definert den konseptuelle modellen. Vi lagrer Salgsdata og har tre ekstra tabeller-Tid, Produkt Og Butikk – som gir ekstra, mer detaljert informasjon om hvert salg. Faktatabellen er Salg, og de andre er dimensjonstabeller.
det neste trinnet er å definere en logisk datamodell. Denne modellen beskriver dataene i detalj på vanlig engelsk uten å bekymre deg for hvordan du implementerer det i kode.
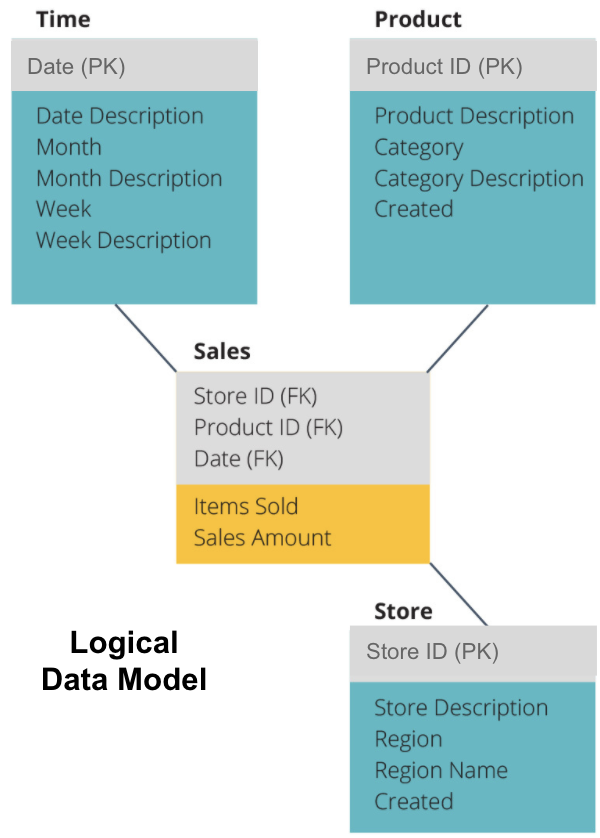
Nå har vi fylt ut hvilken informasjon hver tabell inneholder på vanlig engelsk. Hver dimensjonstabell For tid, Produkt Og Butikk viser Primærnøkkelen (PK) i den grå boksen og de tilsvarende dataene i de blå boksene. Salgstabellen inneholder tre Utenlandske Nøkler (FK) slik at den raskt kan bli med de andre tabellene.
det siste trinnet er å lage en fysisk datamodell. Denne modellen forteller deg hvordan du implementerer datalageret i kode. Det definerer tabeller, deres struktur og forholdet mellom dem. Det spesifiserer også datatyper for kolonner, og alt er oppkalt som det vil være i det endelige datalageret, dvs.alle caps og forbundet med understreker. Til slutt starter hver dimensjonstabell MED DIM_, og hver faktatabell starter MED FACT_.
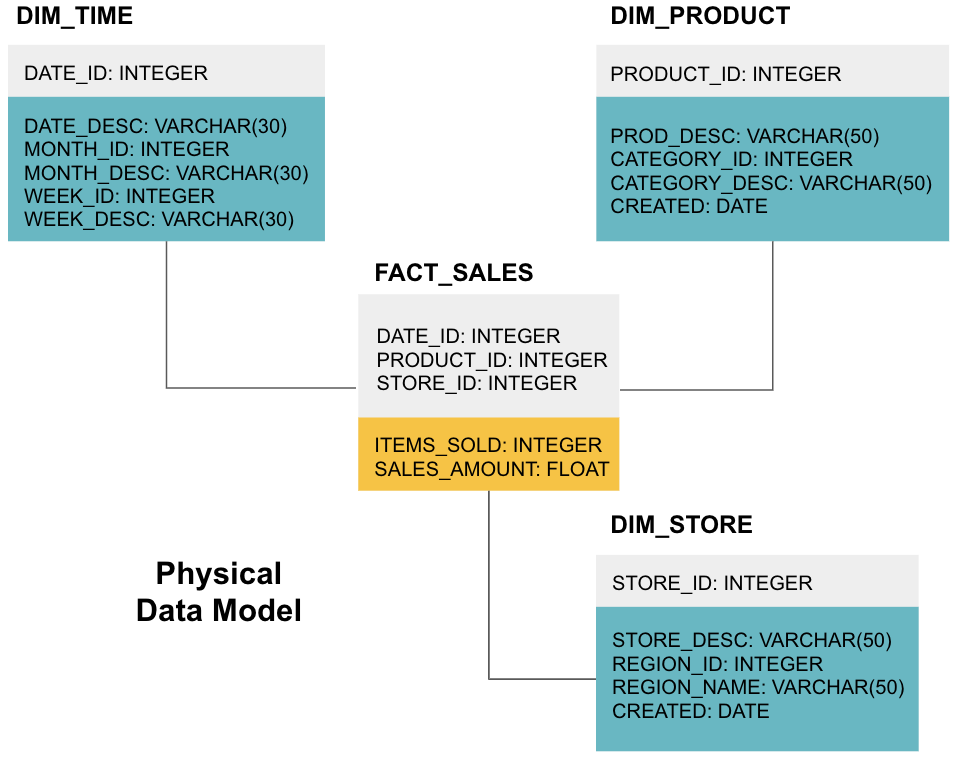
Nå vet du hvordan du skal designe et datalager, men det er noen nyanser til fakta og dimensjonstabeller som vi skal forklare neste.
Faktatabell
Hver forretningsfunksjon – for eksempel salg, markedsføring, økonomi – har en tilsvarende faktatabell.
Faktatabeller har to typer kolonner: dimensjonskolonner og faktakolonner. Dimensjonskolonner-farget grå i eksemplene våre – inneholder Fremmednøkler (FK) som du bruker til å bli med i en faktatabell med en dimensjonstabell. Disse fremmednøkler er Primærnøkler (PK) for hver av dimensjonstabellene. Faktakolonner-farget gul i eksemplene våre – inneholder de faktiske dataene og tiltakene som skal analyseres, for eksempel antall solgte varer og den totale dollarverdien av salget.
en faktatabell er en bestemt type faktatabell som bare har dimensjonskolonner. Slike tabeller er nyttige for å spore hendelser, for eksempel studentoppmøte eller permisjon fra ansatte, da dimensjonene forteller deg alt du trenger å vite om hendelsene.
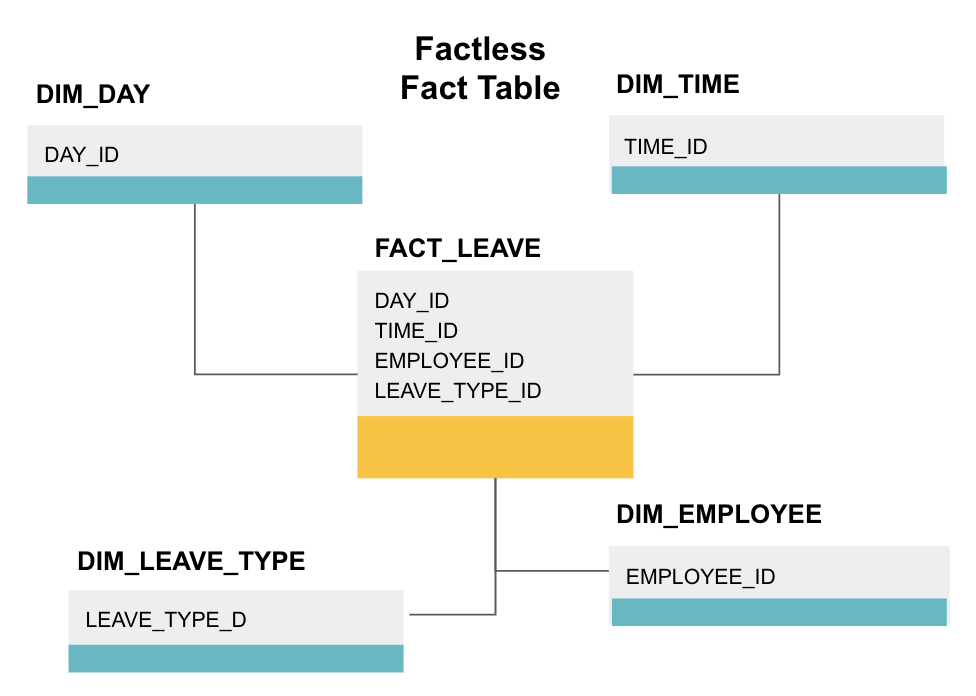
ovennevnte factless faktabord sporer ansattes permisjon. Det er ingen fakta siden du bare trenger å vite:
- Hvilken dag de var av (DAY_ID).
- hvor lenge de var av (TIME_ID).
- hvem var i permisjon(EMPLOYEE_ID).
- grunnen Til at De er i permisjon, f. eks., sykdom, ferie, legeavtale, etc. (LEAVE_TYPE_ID).
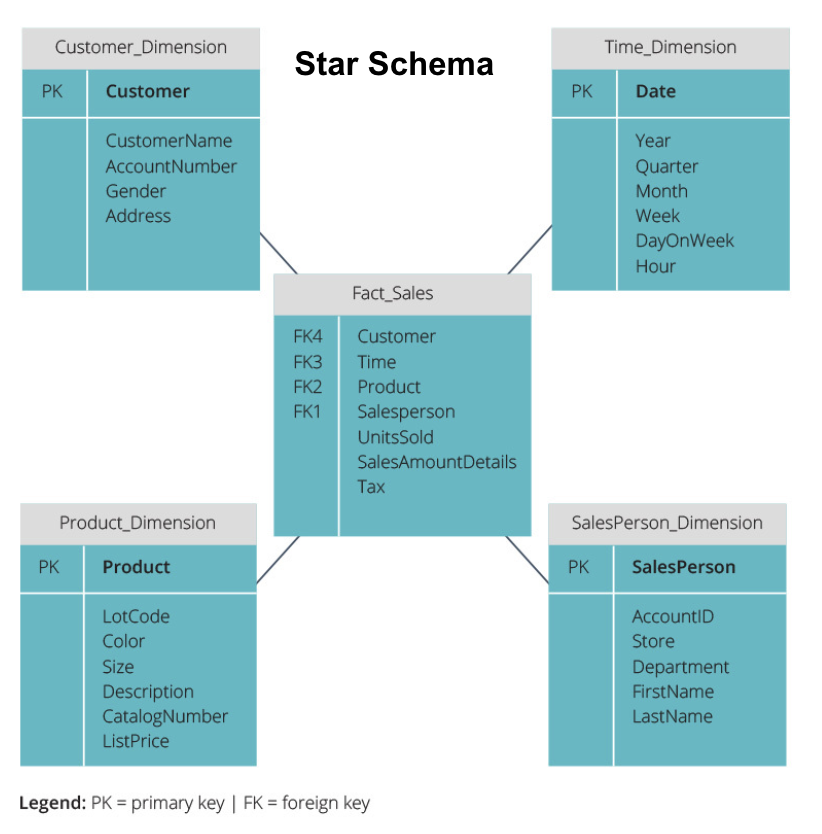
Star Schema vs Snowflake Schema
ovennevnte datalager har alle hatt en lignende layout. Dette er imidlertid ikke den eneste måten å ordne dem på.
de to vanligste skjemaene som brukes til å organisere datalager er star og snowflake. Begge metodene bruker dimensjonstabeller som beskriver informasjonen i en faktatabell.
stjerneskjemaet tar informasjonen fra faktatabellen og deler den i denormaliserte dimensjonstabeller. Hovedvekten for stjerneskjemaet er på spørringshastighet. Bare en sammenføyning er nødvendig for å koble faktatabeller til hver dimensjon, så det er enkelt å spørre hvert bord. Men siden tabellene er denormalisert, inneholder de ofte gjentatte og overflødige data.
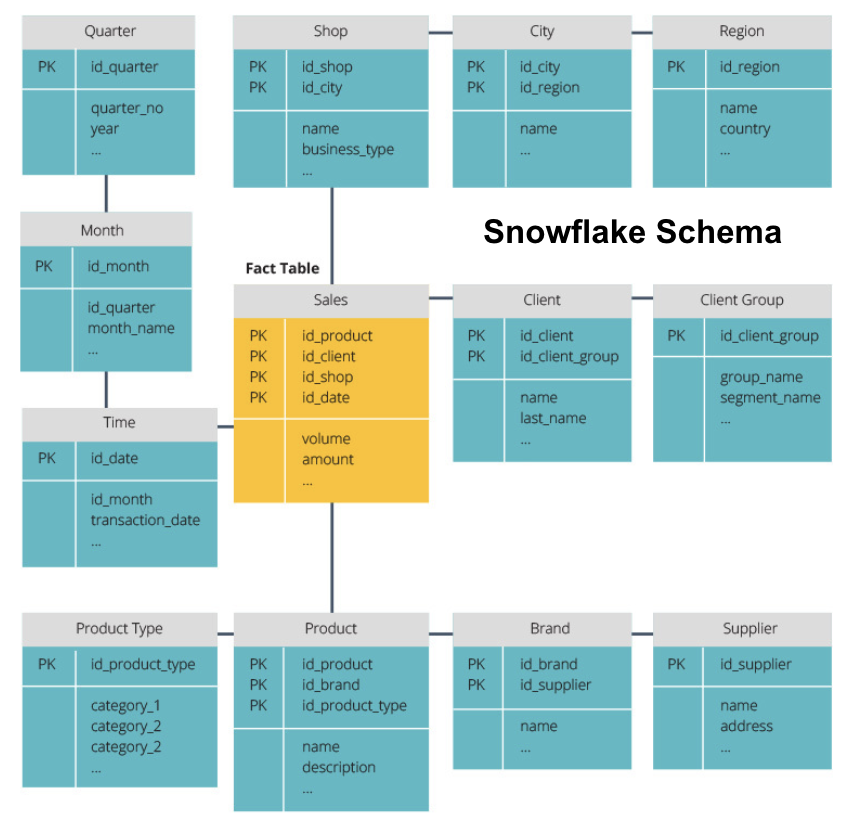
snowflake-skjemaet deler faktatabellen i en serie normaliserte dimensjonstabeller. Normalisering skaper flere dimensjonstabeller, og reduserer dermed dataintegritetsproblemer. Spørring er imidlertid mer utfordrende ved hjelp av snowflake-skjemaet fordi du trenger flere tabellkoblinger for å få tilgang til relevante data. Så, du har mindre overflødige data, men det er vanskeligere å få tilgang til.
Nå skal vi forklare noen mer grunnleggende datavarehus konsepter.
OLAP vs OLTP
ONLINE transaksjonsbehandling (OLTP) er preget av korte skrivetransaksjoner som involverer front-end applikasjoner av en virksomhets dataarkitektur. OLTP databaser understreke rask spørring behandling og bare håndtere gjeldende data. Bedrifter bruker disse til å fange opp informasjon for forretningsprosesser og gi kildedata for datalageret.
OLAP (online analytical processing) lar deg kjøre komplekse lesespørringer og dermed utføre en detaljert analyse av historiske transaksjonsdata. OLAP-systemer bidrar til å analysere dataene i datalageret.
Tre Lags Arkitektur
Tradisjonelle datalager er vanligvis strukturert i tre nivåer:
- Bunnlinjen: en databaseserver, vanligvis EN RDBMS, som trekker ut data fra forskjellige kilder ved hjelp av en gateway. Datakilder som er matet inn i dette nivået, inkluderer operasjonelle databaser og andre typer frontenddata, FOR eksempel CSV-og JSON-filer.
- Mellomnivå: EN OLAP-server som enten
- implementerer operasjonene Direkte, eller
- Tilordner operasjonene på flerdimensjonale data til standard relasjonelle operasjoner, for eksempel sammenslåing AV XML-eller json-data i rader i tabeller.
- Toppnivå: spørre-og rapporteringsverktøyene for dataanalyse og forretningsintelligens.
Virtuelt Datalager / Data Mart
Virtuelt datalager bruker distribuerte spørringer på flere databaser, uten å integrere dataene i ett fysisk datalager.
datamart er delsett av datalagre rettet mot bestemte forretningsfunksjoner, for eksempel salg eller finans. Et datavarehus kombinerer vanligvis informasjon fra flere datamart i flere forretningsfunksjoner. Likevel inneholder en data mart data fra et sett med kildesystemer for en forretningsfunksjon.
Kimball vs Inmon
det er to tilnærminger til datavarehus design, foreslått Av Bill Inmon og Ralph Kimball. Bill Inmon Er En Amerikansk datavitenskapsmann som er anerkjent som datavarehusets far. Ralph Kimball er en av de opprinnelige arkitektene for datavarehus og har skrevet flere bøker om emnet.
de to ekspertene hadde motstridende meninger om hvordan datavarehus skulle struktureres. Denne konflikten har gitt opphav til to tankeskoler.
Inmon-tilnærmingen er et topp-ned-design. Med inmon-metoden opprettes datavarehuset først og ses som den sentrale komponenten i det analytiske miljøet. Data blir deretter oppsummert og distribuert fra sentralisert lager til en eller flere avhengige datamart.
Kimball-tilnærmingen tar en nedenfra-opp-visning av datavarehusdesign. I denne arkitekturen oppretter en organisasjon separate datamart, som gir visninger i enkeltavdelinger i en organisasjon. Datavarehuset er kombinasjonen av disse datamartene.
ETL vs ELT
Extract, Transform, Load (etl) beskriver prosessen med å trekke ut data fra kildesystemer (typisk transaksjonssystemer), konvertere dataene til et format eller struktur som er egnet for spørring og analyse, og til slutt laste den inn i datalageret. ETL utnytter en egen staging database og bruker en rekke regler eller funksjoner til de utpakkede data før lasting.
Utdrag, Last, Transform (ELT) er en annen tilnærming til lasting av data. ELT tar dataene fra ulike kilder og laster dem direkte inn i målsystemet, for eksempel datalageret. Systemet forvandler deretter de lastede dataene på forespørsel for å muliggjøre analyse.
ELT tilbyr raskere lasting enn ETL, men det krever et kraftig system for å utføre datatransformasjonene på forespørsel.
Enterprise Data Warehouse
et enterprise data warehouse er ment som et enhetlig, sentralisert lager som inneholder all transaksjonsinformasjon i organisasjonen, både nåværende og historisk. Et bedriftsdatalager bør inkludere data fra alle fagområder relatert til virksomheten, for eksempel markedsføring, salg, økonomi og menneskelige ressurser.
dette er kjerneideene som utgjør tradisjonelle datalager. Nå, la oss se på hva cloud data warehouses har lagt på toppen av dem.
Konsepter For Datalager I Skyen
datalagre I Skyen er nye og i stadig endring. For best å forstå deres grunnleggende konsepter, er det best å lære om de ledende cloud data warehouse-løsningene.
Tre ledende løsninger for datalager i skyen er Amazon Redshift, Google BigQuery og Panoply. Nedenfor forklarer vi grunnleggende begreper fra hver av disse tjenestene for å gi deg en generell forståelse av hvordan moderne datavarehus fungerer.
Cloud Data Warehouse Concepts-Amazon Redshift
følgende konsepter brukes eksplisitt i Amazon Redshift cloud data warehouse, men kan gjelde for flere datalagerløsninger i fremtiden basert På Amazon-infrastruktur.
Klynger
Amazon Redshift baserer sin arkitektur på klynger. En klynge er bare en gruppe delte dataressurser, kalt noder.
Noder
Noder er databehandlingsressurser som har CPU, RAM og harddiskplass. En klynge som inneholder to eller flere noder består av en leder node og beregne noder.
Ledernoder kommuniserer med klientprogrammer og kompilerer kode for å utføre spørringer, og tilordner den til beregningsnoder. Beregne noder kjøre spørringene og returnere resultatene til leder-noden. En beregningsnode utfører bare spørringer som refererer til tabeller som er lagret på noden.
Partisjoner/Skiver
Amazon partisjoner hver beregne node i skiver. Et stykke mottar en tildeling av minne og diskplass på noden. Flere skiver operere parallelt for å øke hastigheten på spørringen kjøretid.
Kolonnelagring
Redshift bruker kolonnelagring, noe som gir bedre analytisk spørringsytelse. I stedet for å lagre poster i rader, lagrer den verdier fra en enkelt kolonne for flere rader. Følgende diagrammer gjør dette tydeligere:
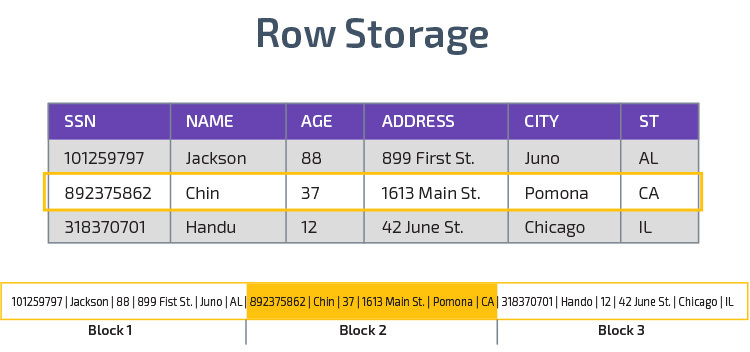
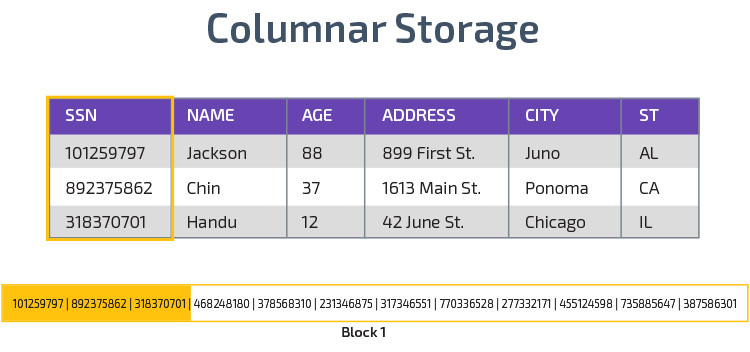
Columnar lagring gjør det mulig å lese data raskere, noe som er avgjørende for analytiske spørringer som spenner over mange kolonner i et datasett. Columnar lagring tar også opp mindre diskplass, fordi hver blokk inneholder samme type data, noe som betyr at den kan komprimeres til et bestemt format.
Komprimering
Komprimering reduserer størrelsen på de lagrede dataene. I Redshift, på grunn av måten data lagres på, oppstår komprimering på kolonnenivå. Redshift lar deg komprimere informasjon manuelt når du lager et bord, eller automatisk ved HJELP AV KOPIER-kommandoen.
Data Lasting
DU kan bruke REDSHIFT KOPI kommando for å laste store mengder data inn i datalageret. COPY-kommandoen utnytter Redshift ‘ S MPP-arkitektur for å lese og laste data parallelt fra filer På Amazon S3, Fra Et DynamoDB-bord eller tekstutgang fra en eller flere eksterne verter.
det er også mulig å streame data til Redshift, ved Hjelp Av Amazon Kinesis Firehose-tjenesten.
Cloud Database Warehouse – Google BigQuery
følgende konsepter brukes eksplisitt i Google BigQuery cloud data warehouse, men kan gjelde for ytterligere løsninger i fremtiden basert På google-infrastruktur.
Serverløs Tjeneste
BigQuery bruker serverløs arkitektur. Med BigQuery trenger ikke bedrifter å administrere fysiske serverenheter for å kjøre datalagrene sine. I stedet styrer BigQuery dynamisk allokering av sine databehandlingsressurser. Bedrifter som bruker tjenesten betaler bare for datalagring per gigabyte og spørringer per terabyte.
Colossus File System
BigQuery bruker den nyeste versjonen Av Googles distribuerte filsystem, Kodenavnet Colossus. Colossus-filsystemet bruker columnar lagrings-og komprimeringsalgoritmer for å lagre data for analytiske formål optimalt.
Dremel Execution Engine
dremel execution engine bruker et kolonneoppsett for å spørre store lagre med data raskt. Dremels eksekveringsmotor kan kjøre ad hoc-spørringer på milliarder av rader i løpet av sekunder fordi den bruker massivt parallell behandling i form av en trearkitektur.
trearkitekturen distribuerer spørringer mellom flere mellomliggende servere fra en rotserver. De mellomliggende serverne skyver spørringen ned til leaf-servere( som inneholder lagrede data), som skanner dataene parallelt. På vei opp igjen i treet sender hver leaf-server spørringsresultater, og de mellomliggende serverne utfører en parallell aggregering av delvise resultater.
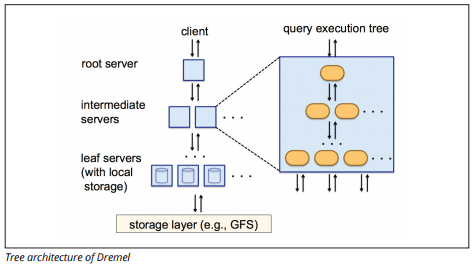
Image source
Dremel gjør det mulig for organisasjoner å kjøre spørringer på opptil titusenvis av servere samtidig. Ifølge Google kan Dremel skanne 35 milliarder rader uten en indeks i titalls sekunder.
Datadeling
Google Bigquerys serverløse arkitektur gjør at bedrifter enkelt kan dele data med andre organisasjoner uten å kreve at disse organisasjonene investerer i egen lagring.
Organisasjoner som vil spørre delte data, kan gjøre det, og de betaler bare for spørringene. Det er ikke nødvendig å lage dyre delte datasiloer, utenfor organisasjonens datainfrastruktur, og kopiere dataene til disse siloene.
Streaming Og Batch Inntak
det er mulig å laste data Til BigQuery Fra Google Cloud Storage, inkludert CSV, JSON (newline-avgrenset), og Avro-filer, Samt Google Cloud Datastore backup. Du kan også laste inn data direkte fra en lesbar datakilde.
BigQuery tilbyr også En Streaming API for å laste data inn i systemet med en hastighet på millioner av rader per sekund uten å utføre en belastning. Dataene er tilgjengelige for analyse nesten umiddelbart.
Cloud Data Warehouse Concepts – Panoply
Panoply Er et alt-i-ett-lager som kombinerer ETL med et kraftig datalager. Det er den enkleste måten å synkronisere, lagre og få tilgang til selskapets data ved å eliminere utviklingen og kodingen forbundet med å transformere, integrere og administrere store data.
nedenfor er noen av hovedkonseptene I Panoply datalager relatert til datamodellering og databeskyttelse.
Primærnøkler
Primærnøkler kontroller at alle rader i tabellene er unike. Hver tabell har en eller flere primærnøkler som definerer hva som representerer en enkelt unik rad i databasen. Alle Apier har en standard primærnøkkel for tabeller.
Inkrementelle Taster
Panoply bruker en inkrementell nøkkel til å kontrollere attributter for trinnvis lasting av data til datalageret fra kilder i stedet for å laste hele datasettet hver gang noe endres. Denne funksjonen er nyttig for større datasett, noe som kan ta lang tid å lese stort sett uendret data. Inkrementell-tasten angir siste oppdateringspunkt for radene i datakilden.
Nestede Data
Nestede data er ikke fullt kompatibel MED bi-suiter og standard SQL-spørringer. Panoply forvandler nestede data på disse måtene:
- Deltabeller: Som standard forvandler Panoply nestede data til et sett med mange-til-mange-eller en-til-mange-relasjonstabeller, som er flate relasjonstabeller.
- Sammenslåing: Med denne modusen aktivert, flater Panoply den nestede strukturen på posten som inneholder den.
Historikktabeller
noen ganger må du analysere data ved å holde oversikt over endring av data over tid for å se nøyaktig hvordan dataene endres(for eksempel folks adresser).
For å utføre slike analyser bruker Panoply Historikktabeller, som er tidsserietabeller som inneholder historiske øyeblikksbilder av hver rad i den opprinnelige statiske tabellen. Du kan deretter utføre enkel spørring av den opprinnelige tabellen eller revisjoner av tabellen ved å spole tilbake til et tidspunkt.
Transformasjoner
Panoply bruker ELT, som er en variant av den opprinnelige ETL dataintegrasjonsprosessen. Når du har injisert data fra kilden inn i datalageret ditt, forvandler Panoply det umiddelbart. Denne prosessen gir deg dataanalyse i sanntid og optimal ytelse sammenlignet med standard ETL-prosessen.
Strengformater
Panoply analyserer strengformater og håndterer dem som om de var nestede objekter i de opprinnelige dataene. Støttede strengformater ER CSV, TSV, JSON, JSON-Line, Ruby-objektformat, URL-spørringsstrenger og webdistribusjonslogger.
Databeskyttelse
Panoply er bygget på TOPPEN AV AWS, så Den har de nyeste sikkerhetsoppdateringene og krypteringsfunksjonene SOM TILBYS AV AWS, inkludert maskinvareakselerert RSA-kryptering og Amazon Redshift spesifikke sett med sikkerhetsfunksjoner.
Ekstra beskyttelse kommer fra kolonnekryptering, som lar deg bruke dine private nøkler som ikke er lagret På Panoplys servere.
Tilgangskontroll
Panoply bruker totrinnsbekreftelse for å hindre uautorisert tilgang, og et tillatelsessystem lar deg begrense tilgangen til bestemte tabeller, visninger eller kolonner. Anomali deteksjon identifiserer spørringer som kommer fra nye datamaskiner eller et annet land, slik at du kan blokkere disse spørringene med mindre de mottar manuell godkjenning.
Ip-Hvitelisting
vi anbefaler at du blokkerer tilkoblinger fra ukjente kilder ved å bruke en brannmur eller EN AWS-sikkerhetsgruppe, og hviteliste rekkevidden AV IP-adresser Som panoplys datakilder alltid bruker når du åpner databasen.
Konklusjon: Tradisjonelle vs. Datavarehus Konsepter I Korte Trekk
for å bryte opp, oppsummerer vi konseptene introdusert i dette dokumentet.
Tradisjonelle Datavarehus Konsepter
- Fakta og tiltak: et mål er en egenskap som beregninger kan gjøres på. Vi refererer til en samling av tiltak som fakta, men noen ganger begrepene brukes om hverandre.
- Normalisering: prosessen med å redusere mengden av dupliserte data, noe som fører til en mer minne effektiv datalager som er tregere å spørre.
- Dimensjon: brukes til å kategorisere og kontekstualisere fakta og tiltak, noe som muliggjør analyse av og rapportering av disse tiltakene.
- Konseptuell datamodell: Definerer de kritiske dataenhetene på høyt nivå og relasjonene mellom dem.
- Logisk datamodell: Beskriver datarelasjoner, enheter og attributter på vanlig engelsk uten å bekymre deg for hvordan du implementerer det i kode.
- Fysisk datamodell: en representasjon av hvordan man implementerer datadesignet i et bestemt databasebehandlingssystem.
- Stjerneskjema: Tar en faktatabell og deler informasjonen i denormaliserte dimensjonstabeller.
- Snowflake schema: Deler faktatabellen i normaliserte dimensjonstabeller. Normalisering reduserer data redundans problemer og forbedrer dataintegritet, men spørringer er mer komplekse.
- OLTP: Online transaksjonsbehandling systemer lette rask, transaksjonsorientert behandling med enkle spørsmål.
- OLAP: Online analytisk behandling lar deg kjøre komplekse lesespørringer og dermed utføre en detaljert analyse av historiske transaksjonsdata.
- Data mart: et arkiv med data som fokuserer på et bestemt emne eller avdeling i en organisasjon.
- Inmon-tilnærming: Bill Inmons datavarehus-tilnærming definerer datalageret som det sentraliserte datalager for hele virksomheten. Data marts kan bygges fra datalageret for å betjene de analytiske behovene til ulike avdelinger.
- Kimball tilnærming: Ralph Kimball beskriver et datalager som sammenslåing av virksomhetskritiske data marts, som først opprettes for å betjene de analytiske behovene til ulike avdelinger.
- Etl: Integrerer data i datalageret ved å trekke det ut fra ulike transaksjonskilder, transformere dataene for å optimalisere det for analyse, og til slutt laste det inn i datalageret.
- ELT: En variant AV ETL som trekker ut rådata fra en organisasjons datakilder og laster den inn i datalageret. Når det trengs, blir det forvandlet til analytiske formål.
- Enterprise Data Warehouse: EDW konsoliderer data fra alle fagområder knyttet til virksomheten.
Cloud Data Warehouse Concepts-Amazon Redshift som Eksempel
- Klynge: en gruppe delte databehandlingsressurser basert i skyen.
- Node: en dataressurs som finnes i en klynge. Hver node har SIN EGEN CPU, RAM og harddiskplass.
- Kolonnelagring: Dette lagrer verdiene for en tabell i kolonner i stedet for rader, som optimaliserer dataene for aggregerte spørringer.
- Komprimering: Teknikker for å redusere størrelsen på lagrede data.
- datalasting: Hente data fra kilder inn i det skybaserte datalageret. I Redshift kan du bruke KOPIER-kommandoen eller en datastrømningstjeneste.
Cloud Data Warehouse Concepts-BigQuery Som Eksempel
- Serverløs tjeneste: skyleverandøren administrerer dynamisk allokering av maskinressurser basert på mengden brukeren bruker. Skyleverandøren skjuler serveradministrasjons-og kapasitetsplanleggingsbeslutninger fra brukerne av tjenesten.
- Colossus file system: et distribuert filsystem som bruker kolonnelagring og datakomprimeringsalgoritmer for å optimalisere data for analyse.
- dremel execution engine: en spørringsmotor som bruker massivt parallell behandling og kolonnelagring for å utføre spørringer raskt.
- datadeling: I en serverløs tjeneste er det praktisk å spørre en annen organisasjons delte data uten å investere i datalagring—du betaler bare for spørringene.
- Strømmedata: Sette inn data i sanntid i datalageret uten å utføre en belastning. Du kan streame data i batchforespørsler, som er flere API-kall kombinert i EN HTTP-forespørsel.
Tradisjonell vs Sky Kost-Nytte Analyse
| Kostnad / Fordel | Tradisjonell | Sky |
| Kostnad | Stor forhåndskostnad for å kjøpe og installere et on-prem-system. du trenger maskinvare, serverrom og spesialistpersonell (som du betaler på løpende basis). hvis du er usikker på hvor mye lagringsplass du trenger, er det fare for høye kostnader som er vanskelige å gjenopprette. |
Du trenger ikke å kjøpe maskinvare, serverrom eller leie spesialister. ingen risiko for reduserte kostnader-det er enkelt å kjøpe mer lagringsplass i fremtiden. i Tillegg reduseres kostnadene for lagring og datakraft over tid. |
| Skalerbarhet | når du maksimerer dine nåværende serverrom eller maskinvarekapasitet, må du kanskje kjøpe ny maskinvare og bygge/kjøpe flere steder for å huse den. I Tillegg må du kjøpe nok lagringsplass til å takle topptider; dermed, mesteparten av tiden, mesteparten av lagringen er ikke brukt. |
du kan enkelt kjøpe mer lagringsplass når og når du trenger det. må ofte bare betale for det du bruker, så det er liten eller ingen risiko for overbetaling. |
| Integrasjoner | som cloud computing er normen, vil de fleste integrasjoner du vil gjøre være til skytjenester. Å Koble ditt egendefinerte datalager til dem kan være utfordrende. |
ettersom sky datalagre allerede er i skyen, er det enkelt å koble til en rekke andre skytjenester. |
| Sikkerhet | du har full kontroll over datalageret ditt. Sammenligning av mengden data du huser Til Amazon eller Google, er du et mindre mål for tyver. Så, du kan være mer sannsynlig å være alene. |
Cloud data warehouse-leverandører har team fulle av høyt kvalifiserte sikkerhetsingeniører, hvis eneste formål er å gjøre produktet så sikkert som mulig. de mest fremtredende selskapene i verden administrerer dem og implementerer derfor sikkerhetspraksis i verdensklasse. |
| Governance | du vet nøyaktig hvor dataene dine er og kan få tilgang til dem lokalt. Mindre risiko for at svært sensitive data utilsiktet bryter loven ved for eksempel å reise over hele verden på en skyserver. |
de beste leverandørene av datalagre i skyen sikrer at de overholder lover om styring og sikkerhet, for EKSEMPEL GDPR. I tillegg hjelper de bedriften din med å sikre at du er kompatibel. det har vært spørsmål om å vite nøyaktig dine data er og hvor den beveger seg. Disse problemene blir aktivt adressert og løst. merk at lagring av store mengder svært sensitive data på skyen kan være mot spesifikke lover. Dette er en forekomst der cloud computing kan være upassende for din bedrift. |
| Pålitelighet | hvis ditt on-prem datalager mislykkes, er det ditt ansvar å fikse det. IT-teamet ditt har tilgang til den fysiske maskinvaren og kan få tilgang til alle programvarelag for å feilsøke. Denne rask tilgang kan gjøre løse problemer mye raskere. det er imidlertid ingen garanti for at lageret ditt vil ha en bestemt oppetid hvert år. |
Leverandører av skylagre garanterer pålitelighet og oppetid i Serviceavtalen. de opererer på massivt distribuerte systemer over hele verden, så hvis det er en feil på en, er det svært lite sannsynlig å påvirke deg. |
| Control | datalageret ditt er spesialbygd for å dekke dine behov. I teorien gjør det hva du vil at den skal gjøre, når du vil at den skal, på en måte du forstår. | du har ikke full kontroll over datalageret ditt. men mesteparten av tiden er kontrollen du har mer enn nok. |
| Hastighet | Hvis du er et lite selskap på ett geografisk sted med en liten mengde data, blir databehandlingen raskere. vi snakker imidlertid millisekunder vs sekunder for noen prosesser å fullføre. et stort selskap som opererer i flere land, er usannsynlig å se betydelige hastighetsgevinster med et on-prem-system. |
Skyleverandører har investert i og skapt systemer som implementerer Massively Parallel Processing (Mpp), spesialbygde arkitektur-og utførelsesmotorer og intelligente databehandlingsalgoritmer. datalagre I Skyen er resultatet av mange års forskning og testing for å skape ressurser som er optimalisert for hastighet og ytelse. det kan være litt tregere enn på prem i noen tilfeller, men disse forsinkelsene er ofte ubetydelige for mennesker (sekunder vs. millisekunder). |
Panoply er et sikkert sted å lagre, synkronisere og få tilgang til alle forretningsdataene dine. Panoply kan settes opp i løpet av minutter, krever null pågående vedlikehold, og gir online support, inkludert tilgang til erfarne data arkitekter. Prøv Panoply gratis i 14 dager.
Lær Mer Om Datalager
- Datalagerarkitektur: Tradisjonell vs Sky
- Database vs Datalager
- Data Mart vs Datalager