Clustering Og K Betyr: Definisjon Og Klyngeanalyse I Excel
Statistikk Definisjoner > Clustering / Clustering Analysis
Hva Er Clustering?
Clustering i statistikk refererer til hvordan data samles (“gruppert”) av faktorer som:
- Alder.
- Husholdningsstørrelse.
- Inntekt.
- eller utdanningsnivå.
Sortering av data i klynger fører noen ganger til mer undersøkelse av dataene. For eksempel kan kreftklynger indikere noe problem i miljøet. Eller de kan bare være et resultat av at naturen er tilfeldig. Klyngeanalyse har en tendens til å være subjektiv i mange tilfeller; det avhenger av hva du oppfatter som vanlige tråder i dataene. Teknikken er egentlig ikke noe nytt i statistikk; hvis du noen gang har laget et stolpediagram, har du sannsynligvis allerede laget klynger (selv om du ikke kalte det det). For eksempel, et søylediagram som viser hunderaser krever at du klynger etter rase (Siberian Husky, Border Collie, tysk Shepherd…) eller et diagram over inntektsnivåer kan være gruppert av lave, mellomstore og høye inntektsnivåer.
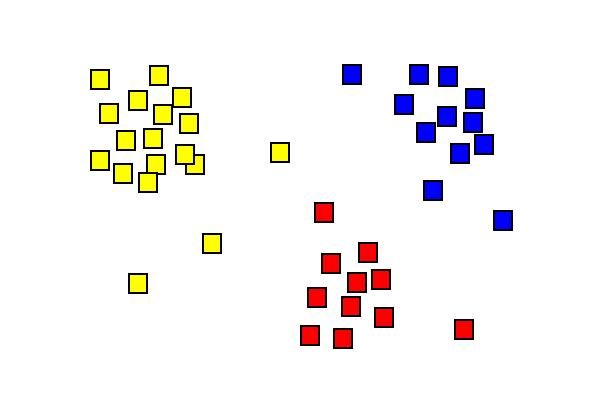
Cluster analyseresultater som viser tre forskjellige fargede klynger.
Klynger kan være basert på faktorer som:
- Avstandsbasert clustering. Elementer er sortert basert på deres nærhet (eller avstand). For eksempel kan kreft tilfeller være gruppert sammen hvis de er i samme geografiske plassering.
- Konseptuell gruppering. Elementer er gruppert etter faktorer som elementer har til felles. For eksempel kan kreftklynger grupperes av ” folk som jobber i produksjonen.”
Clustering Typer
- Eksklusiv Clustering. Hvert element kan bare tilhøre en enkelt klynge. Det kan ikke tilhøre en annen klynge.
- Fuzzy clustering: datapunkter tildeles en sannsynlighet for å tilhøre en eller flere klynger.
- Overlappende Klynger. Hvert element kan tilhøre mer enn en klynge.
- Hierarkisk Clustering. Dette er en mer kompleks tilnærming til clustering brukt i data mining. I utgangspunktet er hvert element gitt sin egen klynge. Et par klynger er sammenføyet basert på likheter, noe som gir en mindre klynge. Denne prosessen gjentas til alle elementene er gruppert. Dendrogrammet er en graf som viser hierarkiske klynger.
- Probabilistisk Klynging. Data er gruppert ved hjelp av algoritmer som kobler elementer ved hjelp av avstander eller tettheter. Dette utføres vanligvis av en datamaskin.
- Wards metode: bruker minimal varians i hvert trinn for å skape relativt små, jevne klynger.
K Betyr Clustering
Clustering er bare en måte å gruppere et sett med data i mindre sett. De to måtene du kan gruppere et sett med data er kvantitativt (ved hjelp av tall) og kvalitativt (ved hjelp av kategorier). For eksempel bøker på Amazon.com er oppført både etter kategori (kvalitativ) og etter bestselger (kvantitativ). K-Means clustering er en av de enkleste uovervåkede læringsalgoritmer som løser clustering problemer ved hjelp av en kvantitativ metode: du forhåndsdefinerer en rekke klynger og bruker en enkel algoritme for å sortere dataene dine. Når det er sagt, er” enkelt ” i databehandlingsverdenen ikke likestilt med enkelt i det virkelige liv. Dette er faktisk ET NP-hardt problem, så du vil bruke programvare For K-means clustering. Noen programmer som vil utføre dette for deg (klikk på linken for prosedyren) er:
- SPSS.
- r
- MATLAB
de generelle trinnene bak k-means clustering-algoritmen er:
- Bestem hvor mange klynger (k).
- Plasser k sentrale punkter på forskjellige steder (vanligvis langt fra hverandre).
- Ta hvert datapunkt og plasser det nær det aktuelle sentrale punktet. Gjenta til alle datapunkter er tildelt.
- re-beregne k nye sentrale punkter som barycenters.
- Gjenta tildelingen av datapunkter, denne gangen til det nye sentrale punktet (barycenteret).
- Gjenta 4 og 5 til de sentrale punktene (barycenters) ikke beveger seg lenger.
K-Betyr Clustering: En Mer Formell Definisjon
en mer formell måte å definere K-Betyr clustering er å kategorisere n objekter i k (k>1) forhåndsdefinerte grupper. Målet er å minimere avstanden fra hvert datapunkt til klyngen. Med andre ord, for å finne:
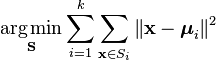
hvor:
X Er et datapunkt
k er antall klynger
ui er gjennomsnittet av punktene I Si.
Klyngeanalyse vs. Diskriminantanalyse
Klyngeanalyse er svært lik diskriminantanalyse. Begge metodene innebærer separasjon i grupper. Klyngeanalyse er imidlertid en måte å identifisere gruppene på, mens diskriminantanalyse krever at du kjenner gruppene før du begynner analysen. For eksempel, la oss si at du hadde en gruppe psykiatriske pasienter med unormal atferd. Cluster analyse kan hjelpe deg med å finne forskjellige grupper, som pasienter med en historie med misbruk, DE MED PTSD, eller de som opplever hallusinasjoner. Hvis du skal kjøre diskriminantanalyse på samme gruppe mennesker, må du kjenne pasientenes diagnoser før du begynner å plassere dem i grupper.
Klynger I Excel
Microsoft Excel har et tillegg for datautvinning for å lage klynger. Du finner instruksjoner her. Veiviseren fungerer med Excel-tabeller, områder eller Analyseundersøkelsesspørringer. Dette tillegget kan tilpasses, i motsetning Til Detect Kategorier verktøyet. I Tillegg Er Detect Categories-verktøyet begrenset til data fra tabeller.
å bruke:
- Last ned Og installer Data Mining-Tillegget.
- Klikk På “Data Mining”, og klikk deretter På “Cluster” og Deretter ” Next.”
- Fortell Excel hvor dataene dine er. Velg for eksempel et område med data. Clustering siden vil bli tilgjengelig.
- Clustering: la som er for automatisk gruppering, eller du kan angi et antall grupper.
- Segmenter: la som er for automatisk gruppering, eller angi et antall kategorier.
Stephanie Glen. “Clustering Og K Betyr: Definisjon & Klyngeanalyse I Excel” Fra StatisticsHowTo.com: Elementær Statistikk for resten av oss! https://www.statisticshowto.com/clustering/
——————————————————————————
Trenger du hjelp med lekser eller testspørsmål? Med Chegg Study kan du få trinnvise løsninger på dine spørsmål fra en ekspert på feltet. Din første 30 minutter med En Chegg veileder er gratis!