Felles Søk: open source-prosjektet bringing Back PageRank
Registrer deg for våre daglige oppsummeringer av den stadig skiftende søk markedsføring landskapet.
Merk: ved å sende inn dette skjemaet, godtar Du Third Door Medias vilkår. Vi respekterer ditt privatliv.

I Løpet Av De siste årene Har Google sakte redusert mengden data tilgjengelig FOR SEO-utøvere. Først var det søkeorddata, Deretter PageRank score. Nå er det bestemt søkevolum Fra AdWords (med mindre du bruker litt moola). Du kan lese mer Om Dette I Russ Jones utmerkede artikkel som beskriver virkningen av selskapets forskning og innsikt i clickstream data for volum disambiguation.
Ett element som vi har fått virkelig involvert i nylig Er Vanlige Kravlesøk data. Det er flere lag i vår bransje som har brukt disse dataene i noen tid, så jeg følte meg litt sent til spillet. Common Crawl data er en åpen kildekode-prosjekt som skraper hele internett med jevne mellomrom. Heldigvis, Amazon, å være det store selskapet det er, pitched i å lagre data for å gjøre den tilgjengelig for mange uten de høye lagringskostnader.
i Tillegg Til Vanlige Gjennomsøkingsdata, er Det et non-profit Kalt Common Search hvis oppdrag er å skape en alternativ åpen kildekode og gjennomsiktig søkemotor — det motsatte, i Mange henseender, Av Google. Dette pirret min interesse fordi det betyr at vi alle kan spille, finpusse og mangle signaler for å lære hvordan søkemotorer operere uten den enorme tid investering for å starte fra ground zero.
Vanlige søkedata
For Øyeblikket Bruker Vanlige Søk følgende datakilder for å beregne søkerangeringen (dette er hentet direkte fra nettstedet deres):
- Felles Crawl: det største åpne depotet av web crawl data. Dette er for tiden vår unike kilde til rå sidedata.
- Wikidata: En gratis, lenket database som fungerer som sentral lagring for strukturerte data fra Mange Wikimedia-prosjekter som Wikipedia, Wikivoyage og Wikisource.
- Ut1 Blacklist: Vedlikeholdt Av Fabrice Prigent fra Université Toulouse 1 Capitole, kategoriserer denne svartelisten domener og Nettadresser i flere kategorier, inkludert ” voksen “og” phishing.”
- DMOZ: OGSÅ Kjent Som Open Directory Project, DET er den eldste og største web-katalogen fortsatt i live. Selv om dataene ikke er like pålitelige som de var tidligere, bruker vi det fortsatt som en signal-og metadatakilde.
- Web Data Commons Hyperkobling Grafer: Grafer av alle hyperkoblinger fra En 2012 Felles Gjennomgang arkiv. Vi bruker for tiden Sin Harmoniske Sentralitet fil som en midlertidig rangering signal på domener. Vi planlegger å utføre vår egen analyse av webgrafen i nær fremtid.
- Alexa topp 1m nettsteder: Alexa rangerer nettsteder basert på en kombinert måling av sidevisninger og unike brukere. Det er kjent for å være demografisk partisk. Vi bruker det som et midlertidig rangeringssignal på domener.
Felles søkerangering
i tillegg til disse datakildene bruker koden OGSÅ URL-lengde, banelengde og domenepagerank som rangeringssignaler i algoritmen. Lo og se, Siden juli Har Common Search hatt egne data På vertsnivå PageRank,og vi savnet det alle.
Jeg kommer til PageRank (PR) om et øyeblikk, men det er interessant å se gjennom Koden For Vanlig Kryp, spesielt ranker.py del ligger her, fordi du virkelig kan komme inn i førersetet med tweaking vekter av signalene som den bruker til å rangere sidene:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
Spesielt er Det Også At Common Search bruker BM25 som likhetsmål for søkeord til dokumentlegeme og metadata. BM25 er et bedre mål enn TF-IDF fordi det tar hensyn til dokumentlengde, noe som betyr at et dokument på 200 ord som har søkeordet ditt fem ganger, sannsynligvis er mer relevant enn et dokument på 1500 ord som har det samme antall ganger.
det er også verdt å si at antall signaler her er veldig rudimentære og åpenbart mangler mange av forbedringene (og dataene) Som Google har integrert i deres rangeringsalgoritme. En av de viktigste tingene vi jobber med er å bruke dataene som er tilgjengelige I Common Crawl og Infrastrukturen Til Common Search for å gjøre emnevektorsøk etter innhold som er relevant basert på semantikk, ikke bare søkeordsammenligning.
På PageRank
på siden her finner du lenker til pagerank På Vertsnivå for Juni 2016 Common Crawl. Jeg bruker den som har rett pagerank-top1m.txt.gz (topp 1 million) fordi den andre filen ER 3GB og over 112 millioner domener. Selv I R har jeg ikke nok maskin til å laste den uten å lukke ut.
etter nedlasting må du ta filen inn i arbeidskatalogen Din I R. PageRank-dataene Fra Common Search er ikke normalisert og er heller ikke i det rene 0-10-formatet som vi alle er vant til å se det i. Vanlig Søk bruker ” maks(0, min (1, float (rang)/ 244660.58))” – i utgangspunktet, et domene rang dividert Med Facebook rang — som metode for å oversette data til en fordeling mellom 0 og 1. Men dette etterlater noen klare hull, ved at Dette ville forlate Linkedins PageRank som en 1.4 når skalert av 10.

følgende kode vil laste datasettet og legge TIL EN pr-kolonne med en bedre tilnærmet PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
Vi måtte leke litt med tallene for å få det et sted i nærheten (for flere prøver av domener som jeg husket PR for) til den gamle Google PR. Nedenfor er noen eksempler PageRank resultater:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
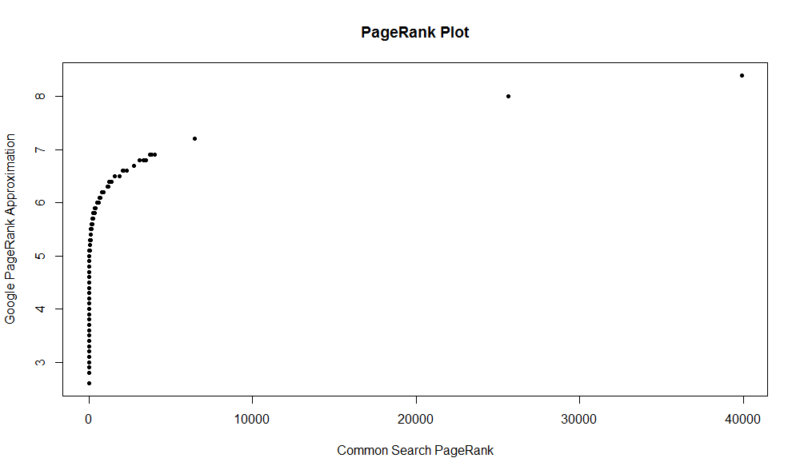
Her er et plott av 100.000 tilfeldige prøver. Den beregnede PageRank-poengsummen er langs Y-aksen, og den opprinnelige Common Search-poengsummen er langs X-aksen.
for å få tak i dine egne resultater, kan du kjøre følgende kommando I R (bare erstatt ditt eget domene):
df

Husk at Dette datasettet bare har De øverste en million domenene Av PageRank, så ut av 112 millioner domener Som Vanlig søk indeksert, er det en god sjanse for at nettstedet ditt kanskje ikke er der hvis det ikke har en ganske god linkprofil. Også denne beregningen inneholder ingen indikasjon på skadelighet av koblinger, bare en tilnærming av nettstedets popularitet med hensyn til koblinger.
Felles Søk er et flott verktøy og et godt fundament. Jeg ser frem til å bli mer involvert med samfunnet der og forhåpentligvis lære å forstå muttere og bolter bak søkemotorer bedre ved å faktisk jobbe med en. Med R og litt kode, kan du ha en rask måte å sjekke PR for en million domener i løpet av sekunder. Håper du likte!
Registrer deg for våre daglige oppsummeringer av den stadig skiftende søk markedsføring landskapet.
Merk: ved å sende inn dette skjemaet, godtar Du Third Door Medias vilkår. Vi respekterer ditt privatliv.
Om Forfatteren

JR OAKES er senior direktør for teknisk SEO forskning På Locomotive. Han var tidligere direktør for teknisk SEO ved Adapt Partners agency. Han jobber med klienter på en rekke fronter, inkludert tekniske problemer, ytelse, CTR, gjennomsøkingsevne, innhold og dataanalyse. JR elsker testing, koding og prototyping løsninger på vanskelige søk markedsføring problemer. Når han ikke jobber, han liker å lese om nye teknologier, spille bassgitar, se college basketball, matlaging og tilbringe tid med sine venner og familie. Han er også en av de medarrangører Av Raleigh SEO Meetup, Raleigh SEO Conference, OG RTP SEO Meetup.