Skalerbar, Distribuert Sekundær Indeksering I Scylla

datamodellen i Scylla og Apache Cassandra partisjonerer data mellom klyngenoder ved hjelp av en partisjonsnøkkel, som er definert av databaseskjemaet. Bruk av en partisjonsnøkkel gir en effektiv måte å slå opp rader ved hjelp av partisjonsnøkkelen fordi du kan finne noden som eier raden ved å hashe partisjonsnøkkelen. Dessverre betyr dette også at å finne en rad ved hjelp av en ikke-partisjonsnøkkel krever en full tabellskanning som er ineffektiv. Sekundære Indekser er en mekanisme I Apache Cassandra som tillater effektive søk på ikke-partisjonstaster ved å opprette en indeks.
I dette blogginnlegget vil du lære:
- Hvordan Apache Cassandra implementerer Sekundære Indekser ved hjelp av lokal indeksering
- Hvorfor vi bestemte Oss For å ta en annen implementeringsstrategi For Scylla ved hjelp av global indeksering
- hvordan global indeksering påvirker hvordan du bør bruke Sekundær Indeksering
- hvordan lage Dine Egne Sekundære Indekser Og bruke dem i dine cql-spørringer
bakgrunn
Størrelsen På En Indeks Er Proporsjonal med størrelsen på de indekserte dataene. Da data i Scylla og Apache Cassandra distribueres til flere noder, er det upraktisk å lagre hele indeksen på en enkelt node. Apache Cassandra implementerer Sekundære Indekser som lokale indekser, noe som betyr at indeksen er lagret på samme node som dataene som blir indeksert fra den noden. Fordelen med en lokal indeks er at skriver er veldig raske, men ulempen er at leser må potensielt spørre hver node for å finne indeksen for å utføre et oppslag på, noe som gjør lokale indekser uskalerbare for store klynger. I Tillegg til de opprinnelige sekundære indeksene Har Apache Cassandra også en annen lokal indekseringsordning, SSTable Attached Secondary Index (SASI), som støtter komplekse spørringer og søk. Men fra et skalerbart synspunkt har det nøyaktig de samme egenskapene som de opprinnelige Sekundære Indeksene.
Materialiserte visninger I Scylla og Apache Cassandra er en mekanisme for automatisk denormalisering av data fra en basetabell til en visningstabell ved hjelp av en annen partisjonstast. Dette løser skalerbarhet problemet med lokale indekser, men kommer til en lagringskostnad fordi du må duplisere hele tabellen i verste fall. Materialiserte Visninger er derfor ikke en erstatning For Sekundære Indekser for alle brukstilfeller. Imidlertid Gir Materialiserte Synspunkter den nødvendige infrastrukturen for å implementere Sekundære Indekser ved hjelp av global indeksering, som er implementeringsmetoden Tatt For Scylla.
Global Indeksering
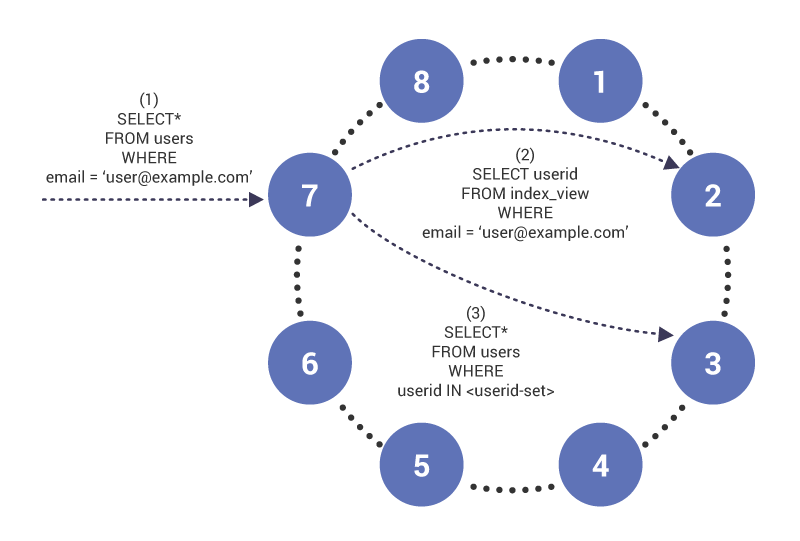
Scylla tar en annen tilnærming Enn Apache Cassandra og implementerer Sekundære Indekser ved hjelp av global indeksering. Med global indeksering opprettes En Materialisert Visning for hver indeks. Den Materialiserte Visningen har den indekserte kolonnen som partisjonsnøkkel og primærnøkkel (partisjonsnøkkel og klyngetaster) i den indekserte raden som klyngetaster. Scylla bryter indekserte spørringer i to deler: (1) en spørring i indekstabellen for å hente partisjonstaster for indeksert tabell og (2) en spørring til indeksert tabell ved hjelp av de hentede partisjonstastene. Fordelen med denne tilnærmingen er at vi kan bruke verdien av den indekserte kolonnen for å finne den tilsvarende indeks tabellraden i klyngen, slik at lesene er skalerbare. Ulempen med tilnærmingen er at skriver er tregere enn med lokal indeksering på grunn av all overhead fra å holde indeksvisningen oppdatert.
Spørring på en indeksert kolonne ser ut som følger. La oss anta et bord som ser slik ut:
og en spørring på kolonnen email, som ikke er en partisjonsnøkkel, men har en indeks:
i fase (1) kommer spørringen på node 7, som fungerer som koordinator for spørringen. Noden merker at vi spør på en indeksert kolonne og derfor i fase (2), utsteder en les til indeks tabell på node 2, som har indeks tabellraden for””. Spørringen returnerer et sett med bruker-Ider som brukes i fase (3) for å hente innholdet i den indekserte tabellen.
Eksempel
Vi må først opprette et skjema. I dette eksemplet har vi en tabell som representerer brukerinformasjon med userid som partisjonsnøkkel og navn, e-post og land som vanlige kolonner:
vi fyller deretter tabellen med noen testdata generert Med Mockaroo:
Sekundære Indekser er utformet for å muliggjøre effektiv spørring av nøkkelkolonner uten partisjon. Mens Apache Cassandra også støtter spørringer på ikke-partisjonstastkolonner ved hjelp av ALLOW FILTERING, er det svært ineffektivt (krever skanning av hele tabellen) og støttes for øyeblikket ikke Av Scylla (se problem #2200 for detaljer).
du kan indeksere tabellkolonner ved HJELP AV CREATE INDEX-setningen. Hvis du for eksempel vil opprette indekser for e-post-og landskolonner, utfører du FØLGENDE cql-setninger:
Scylla oppretter automatisk En Materialisert Visning som har den indekserte kolonnen som partisjonsnøkkel og måltabell primærnøkkel (partisjonsnøkkel og klyngetaster) som klyngetaster.
For Eksempel Ser Den Materialiserte Visningen for indeksen i kolonnen email ut som følger:
hvis visningen ovenfor vil bli opprettet som et vanlig bord, vil det effektivt se ut som følger:
kolonnen email brukes som partisjonsnøkkel for indekstabellen, og userid er inkludert som en klyngnøkkel, noe som gjør at vi effektivt kan finne partisjonsnøkler for måltabellen ved å bruke bare email.
du kan bruke kommandoen DESCRIBE til å se hele skjemaet for tabellen ks.users, inkludert opprettede indekser og visninger:
Nå Med Sekundærindeksen på plass, kan du spørre indekserte kolonner som om de var partisjonstaster:
Vi er ferdige med eksemplet!
Når skal Du bruke Sekundære Indekser?
Sekundære Indekser er (for det meste) gjennomsiktige for søknaden. Spørringer har tilgang til alle kolonnene i tabellen, og du kan legge til og fjerne indekser uten å endre programmet. Sekundære Indekser kan også ha mindre lagringsplass overhead enn Materialiserte Visninger fordi Sekundære Indekser trenger bare å duplisere indeksert kolonne og primærnøkkel, ikke spørres kolonner som med En Materialisert Visning. Av samme grunn kan oppdateringer være mer effektive med Sekundære Indekser fordi bare endringer i primærnøkkelen og indekserte kolonnen føre til en oppdatering i indeksvisningen. Når Det gjelder En Materialisert Visning, krever en oppdatering av noen av kolonnene som vises i visningen, at backing-visningen oppdateres.
som alltid er beslutningen om Å bruke Sekundære Indekser eller Materialiserte Visninger virkelig avhengig av kravene til søknaden din. Hvis du trenger maksimal ytelse og sannsynligvis vil spørre et bestemt sett med kolonner, bør du bruke Materialiserte Visninger. Men Hvis programmet må spørre forskjellige sett med kolonner, Sekundære Indekser er et bedre valg fordi De kan legges til og fjernes med mindre lagringsplass overhead avhengig av programbehov.
Vil du lære Mer Om Sekundære Indekser? Se presentasjonen min fra Scylla Summit 2017 På SlideShare. Hvis du vil prøve denne funksjonen, forventes Det å være i den kommende Scylla 2.2-utgivelsen.