Clustering en K betekent: definitie & clusteranalyse in Excel
statistieken definities > Clustering / clusteranalyse
Wat is Clustering?
Clustering in statistieken verwijst naar hoe gegevens worden verzameld (“geclusterd”) door factoren zoals:
- leeftijd.
- gezinsgrootte.
- inkomen.
- of opleidingsniveau.
het sorteren van gegevens in clusters leidt soms tot meer onderzoek naar de gegevens. Kankerclusters kunnen bijvoorbeeld wijzen op een probleem in het milieu. Of, ze kunnen gewoon een gevolg zijn van de natuur willekeurig. Clusteranalyse neigt in veel gevallen subjectief te zijn; het hangt af van wat u als gemeenschappelijke threads in de gegevens waarneemt. De techniek is niet echt iets nieuws in de statistieken; als je ooit een staafdiagram hebt gemaakt, heb je waarschijnlijk al clusters gemaakt (zelfs als je het niet zo noemde). Bijvoorbeeld, een staafdiagram met hondenrassen vereist dat u cluster per ras (Siberische Husky, Border Collie, Duitse herder…) of een grafiek van inkomensniveaus kan worden geclusterd door lage, midden en hoge inkomensniveaus.
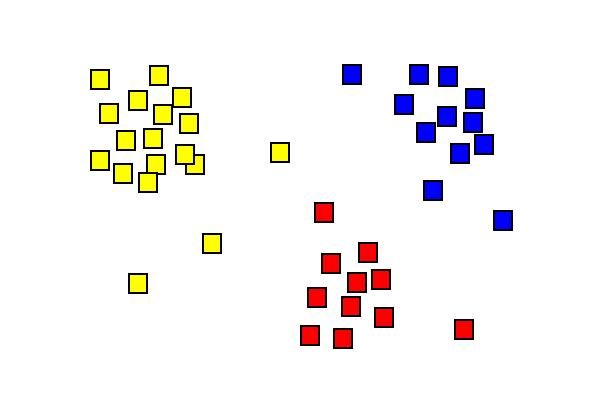
de resultaten van de clusteranalyse tonen drie verschillende gekleurde clusters.
Clusters kunnen gebaseerd zijn op factoren zoals:
- op afstand gebaseerde clustering. Items worden gesorteerd op basis van hun nabijheid (of afstand). Kankergevallen kunnen bijvoorbeeld samen worden geclusterd als ze zich op dezelfde geografische locatie bevinden.
- conceptuele clustering. Items worden gegroepeerd op factoren die items gemeen hebben. Bijvoorbeeld, kankerclusters kunnen worden gegroepeerd door ” mensen die werken in de industrie.”
Clustering Types
- Exclusieve Clustering. Elk item kan slechts in één cluster thuishoren. Het kan niet in een andere cluster thuishoren.
- Fuzzy clustering: gegevenspunten krijgen de kans dat ze tot een of meer clusters behoren.
- Overlappende Clustering. Elk item kan tot meer dan één cluster behoren.
- Hiërarchische Clustering. Dit is een meer complexe benadering van clustering gebruikt in datamining. Kortom, elk item krijgt zijn eigen cluster. Een paar clusters wordt samengevoegd op basis van overeenkomsten, waardoor een cluster minder. Dit proces wordt herhaald totdat alle items zijn geclusterd. Het dendrogram is een grafiek die hiërarchische clusters toont.
- Probabilistische Clustering. Gegevens worden geclusterd met behulp van algoritmen die items verbinden met behulp van afstanden of dichtheden. Dit wordt meestal uitgevoerd door een computer.
- Ward ‘ s methode: gebruikt minimale variantie in elke stap om relatief kleine, even grote clusters te creëren.
K betekent Clustering
Clustering is gewoon een manier om een verzameling gegevens in kleinere Verzamelingen te groeperen. De twee manieren waarop u een verzameling gegevens kunt groeperen zijn kwantitatief (met behulp van getallen) en kwalitatief (met behulp van categorieën). Bijvoorbeeld boeken over Amazon.com worden zowel per categorie (kwalitatief) als per bestseller (kwantitatief) vermeld. K-Means clustering is een van de eenvoudigste unsupervised learning algoritmes die clustering problemen oplost met behulp van een kwantitatieve methode: u vooraf een aantal clusters definiëren en gebruik maken van een eenvoudig algoritme om uw gegevens te sorteren. Dat gezegd hebbende, “eenvoudig” in de computerwereld is niet gelijk aan eenvoudig in het echte leven. Dit is eigenlijk een NP-hard probleem, dus je wilt software gebruiken voor k-means clustering. Sommige programma ‘ s die dit voor u uitvoeren (klik op de link voor de procedure) zijn:
- SPSS.
- r
- MATLAB
de algemene stappen achter het k-means clustering algoritme zijn:
- bepaal hoeveel clusters (k).
- plaats K centrale punten op verschillende plaatsen (meestal ver van elkaar).
- neem elk gegevenspunt en plaats het dicht bij het juiste centrale punt. Herhaal dit totdat alle gegevenspunten zijn toegewezen.
- bereken k nieuwe centrale punten opnieuw als barycenters.
- herhaal de toewijzing van datapunten, deze keer aan het nieuwe centrale punt (het barycenter).
- herhaal 4 en 5 totdat de centrale punten (barycenters) niet meer bewegen.
K-betekent Clustering: een meer formele definitie
een meer formele manier om K-betekent clustering te definiëren is door N objecten te categoriseren in K (k>1) vooraf gedefinieerde groepen. Het doel is om de afstand van elk gegevenspunt tot het cluster te minimaliseren. Met andere woorden, vinden: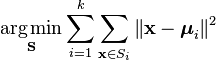
waarbij:
X is een gegevenspunt
k is het aantal clusters
ui is het gemiddelde van de punten in Si.
clusteranalyse vs. Discriminantanalyse
clusteranalyse lijkt sterk op discriminantanalyse. Beide methoden omvatten scheiding in groepen. Clusteranalyse is echter een manier om de groepen te identificeren, terwijl discriminant-analyse vereist dat u de groepen kent voordat u met de analyse begint. Stel dat je een groep psychiatrische patiënten had met abnormaal gedrag. Clusteranalyse kan je helpen om verschillende groepen te vinden, zoals patiënten met een geschiedenis van misbruik, die met PTSS, of die hallucinaties ervaren. Als je discriminant analyseert op dezelfde groep mensen, moet je de diagnoses van de patiënten kennen voordat je ze in groepen gaat plaatsen.
clusteren in Excel
Microsoft Excel heeft een datamining-invoegtoepassing voor het maken van clusters. U kunt hier de instructies vinden. De wizard werkt met Excel-tabellen, bereiken of Onderzoeksquery ‘ s voor analyses. Deze add-in kan worden aangepast, in tegenstelling tot de detectie categorieën tool. Daarnaast is het detect Categories tool beperkt tot gegevens uit tabellen.
te gebruiken:
- Download en installeer de Data Mining-invoegtoepassing.
- klik op “Data Mining”, klik vervolgens op “Cluster” en vervolgens op “Next”.”
- vertel Excel waar uw gegevens zijn. Selecteer bijvoorbeeld een gegevensbereik. De clustering pagina zal beschikbaar komen.
- Clustering: laat zoals bij automatisch groeperen, of u kunt een aantal groepen opgeven.
- segmenten: laat zoals bij automatische groepering, of Specificeer een aantal categorieën.
Stephanie Glen. “Clustering and K Means: Definition & Cluster Analysis in Excel” van StatisticsHowTo.com: Elementaire statistieken voor de rest van ons! https://www.statisticshowto.com/clustering/
——————————————————————————
hulp nodig bij een huiswerk of testvraag? Met Chegg Study krijgt u stap-voor-stap oplossingen voor uw vragen van een expert in het veld. Je eerste 30 minuten met een Chegg tutor is gratis!