evolutie van het cluster scheduling system
Kubernetes is de de facto standaard geworden op het gebied van container orchestratie. Alle toepassingen zullen worden ontwikkeld en draaien op Kubernetes in de toekomst. Het doel van deze serie artikelen is om de onderliggende implementatieprincipes van Kubernetes op een diepgaande en eenvoudige manier te introduceren.
Kubernetes is een clusterplanningssysteem. Dit artikel introduceert voornamelijk een aantal eerdere cluster scheduling systeem architectuur van Kubernetes. Door hun ontwerpideeën en de architectuurkenmerken te analyseren, kunnen we het evolutieproces van cluster scheduling systeemarchitectuur bestuderen, en het belangrijkste probleem dat in het architectuurontwerp moet worden overwogen. Dat zal zeer nuttig zijn bij het begrijpen Kubernetes architectuur.
we moeten enkele basisconcepten van cluster scheduling system begrijpen, om het duidelijk te maken, zal ik het concept uitleggen door middel van een voorbeeld, laten we aannemen dat we een gedistribueerde Cron willen implementeren. Het systeem beheert een set Linux hosts. De gebruiker definieert de taak via de API die door het systeem wordt geleverd. het systeem zal periodiek de overeenkomstige taak uitvoeren op basis van de taakdefinitie, in dit voorbeeld zijn de basisconcepten hieronder:
- Cluster: de Linux-hosts die door dit systeem worden beheerd, vormen een resourcepool om taken uit te voeren. Deze bronpool heet Cluster.
- taak: het bepaalt hoe het cluster zijn taken uitvoert. In dit voorbeeld is Crontab precies een eenvoudige taak die duidelijk laat zien wat er moet gebeuren (uitvoeringsscript) op welk tijdstip(tijdsinterval).De definitie van sommige taken is complexer, zoals de definitie van een taak die in meerdere taken moet worden voltooid, en de afhankelijkheden tussen taken, evenals de resourcevereisten van elke taak.
- taak: een taak moet worden gepland in specifieke prestatietaken. Als we een taak definiëren om een script uit te voeren om 1am elke nacht, dan is het script proces dat elke dag om 1am wordt uitgevoerd een taak.
bij het ontwerpen van het clusterplanningssysteem zijn de kerntaken van het systeem twee:
- taakplanning: Nadat de taken naar het clusterplanningssysteem zijn verzonden, moeten de ingediende taken worden onderverdeeld in specifieke uitvoeringstaken en moeten de uitvoeringsresultaten van de taken worden bijgehouden en gecontroleerd. In het voorbeeld van de gedistribueerde Cron moet het planningssysteem het proces tijdig starten in overeenstemming met de vereisten van de operatie. Als het proces niet presteert, is het opnieuw proberen noodzakelijk etc. Sommige complexe scenario ‘ s, zoals Hadoop Map verminderen, het scheduling systeem moet de Map te verminderen taak te verdelen in de bijbehorende meerdere kaart en taken te verminderen, en uiteindelijk krijgen de taak uitvoering resultaatgegevens.
- Resource scheduling: wordt voornamelijk gebruikt om taken en resources te matchen, en de juiste resources worden toegewezen om taken uit te voeren volgens het resourcegebruik van hosts in het cluster. Het is vergelijkbaar met het proces van het plannen algoritme van het besturingssysteem, het belangrijkste doel van resource scheduling is om het gebruik van resources zoveel mogelijk te verbeteren en de wachttijd voor taken te verminderen onder de voorwaarde van de vaste levering van middelen ,en de vertraging van de taak of responstijd te verminderen( als het batch-taak is, verwijst het naar de tijd van begin tot einde van taakbewerkingen, als het online responstype taken is, zoals webapplicaties, die verwijst naar de elke responstijd op het verzoek), moet de Taakprioriteit in overweging worden genomen terwijl het zo eerlijk is als mogelijk (middelen zijn eerlijk toegewezen aan alle taken). Sommige van deze doelstellingen zijn tegenstrijdig en moeten in evenwicht zijn, zoals het gebruik van middelen, reactietijd, eerlijkheid en prioriteiten.
Hadoop MRv1
Map Reduce is een soort parallel computermodel. Hadoop kan dit soort cluster management platform van parallelle computing draaien. MRv1 is de eerste generatie versie van Map verminderen taakplanning engine van Hadoop platform. In het kort, MRv1 is verantwoordelijk voor het plannen en uitvoeren van de taak op het cluster, en terug te keren naar de berekeningsresultaten wanneer een gebruiker definieert een kaart te verminderen berekening en deze aan de Hadoop. Hier is hoe de architectuur van MRv1 eruit ziet:
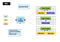
de architectuur is relatief eenvoudig, de standaard Master / Slave architectuur heeft twee kerncomponenten:
- Job Tracker is de belangrijkste beheerscomponent van cluster, die verantwoordelijk is voor zowel resource scheduling als task scheduling.
- Taakvolger draait op elke machine in het cluster, die verantwoordelijk is voor het uitvoeren van specifieke taken op de host en de rapportagestatus.
door de populariteit van Hadoop en de toename van verschillende eisen heeft MRv1 de volgende problemen die moeten worden verbeterd:
- de performance heeft een zeker knelpunt: het maximale aantal knooppunten dat het beheer ondersteunt is 5.000, en het maximale aantal taken van het ondersteunen van de operatie is 40.000. Er is nog ruimte voor verbetering.
- het is niet flexibel genoeg om andere taken uit te breiden of te ondersteunen. Naast Map reduce-type taken, zijn er vele andere taaktypen in het Hadoop-ecosysteem die moeten worden gepland, zoals Spark, Hive, HBase, Storm, Oozie, enz. Daarom is een algemener planningssysteem nodig, dat meer taaktypen
- kan ondersteunen en uitbreiden: MRv1 configureert statisch een vast aantal slots voor elk knooppunt, en elke sleuf kan alleen worden gebruikt voor het specifieke taaktype (Kaart of verminderen), wat leidt tot het probleem van het gebruik van bronnen. Een groot aantal Toewijzingstaken staat bijvoorbeeld in de wachtrij voor niet-actieve bronnen, maar in feite is een groot aantal minder slots inactief voor machines.
- multi-tenancy en multi-version issues. Bijvoorbeeld, verschillende afdelingen draaien taken in hetzelfde cluster, maar ze zijn logisch geïsoleerd van elkaar, of ze draaien verschillende versies van Hadoop in hetzelfde cluster.
garen
garen (nog een andere onderhandelaar) is een tweede generatie van Hadoop ,het belangrijkste doel is om allerlei problemen in MRv1 op te lossen. Garen architectuur ziet er als volgt uit:

het eenvoudige begrip van garen is dat de belangrijkste verbetering ten opzichte van MRv1 is om de verantwoordelijkheden van de oorspronkelijke baan in twee verschillende componenten te verdelen: Resource Manager en Application Master
- Resource Manager: Het is verantwoordelijk voor Resource scheduling, beheert alle resources, wijst resources toe aan verschillende soorten taken en breidt het Resource scheduling-algoritme eenvoudig uit via een pluggable architectuur.
- Toepassingsmaster: het is verantwoordelijk voor de taakplanning. Elke taak (genaamd toepassing in garen) Start een overeenkomstige toepassing Master, die verantwoordelijk is voor het splitsen van de taak in specifieke taken, en het aanvragen van bronnen van Resource Manager, het starten van de taak, het bijhouden van de status van de taak en het rapporteren van de resultaten.
laten we eens kijken hoe deze architectuurverandering de verschillende problemen van MRv1 oploste:
- splits de oorspronkelijke taakplanning verantwoordelijkheden van Job Tracker, en resulteert in aanzienlijke prestatieverbeteringen. De taakplanning verantwoordelijkheden van de oorspronkelijke Job Tracker werden opgesplitst om te worden uitgevoerd door de Application Master,en de Application Master werd gedistribueerd, elke instantie behandeld slechts het verzoek van een taak, dus het bevorderde het maximum aantal clusterknooppunten van 5.000 naar 10.000.
- de componenten van taakplanning, Toepassingsmaster en resourceplanning worden ontkoppeld en dynamisch gemaakt op basis van taakverzoeken. Eén Application Master instance is verantwoordelijk voor slechts één taak van planning, wat het gemakkelijker maakt om verschillende soorten taken te ondersteunen.
- de containerisolatietechnologie wordt geïntroduceerd, elke taak wordt uitgevoerd in een geïsoleerde container, waardoor het gebruik van hulpbronnen aanzienlijk wordt verbeterd afhankelijk van de vraag van de taak naar hulpbronnen die dynamisch kunnen worden toegewezen. Het nadeel van dit is garen resource management en toewijzing hebben slechts één dimensie van het geheugen.
Mesos-architectuur
het ontwerpdoel van garen is nog steeds om de planning van het Hadoop-ecosysteem te dienen. Mesos ‘ doel komt dichterbij, het is ontworpen om een algemeen scheduling systeem, die de werking van het hele datacenter kan beheren. Zoals we zien, het architectonische ontwerp van Mesos gebruikt veel garen voor referentie, de job scheduling en Resource scheduling worden gedragen door de verschillende modules afzonderlijk. Maar het grootste verschil tussen Mesos en garen is de manier van planning voor middelen, een uniek mechanisme genaamd Resource aanbod is ontworpen. De druk van de resources planning wordt verder vrijgegeven, en de job scheduling schaalbaarheid wordt ook verhoogd.

de belangrijkste componenten van Mesos zijn:
- Mesos Master: Het is een component die alleen verantwoordelijk is voor de toewijzing van middelen en componenten van het beheer, dat is de Resource Manager die overeenkomt met de binnenkant garen. Maar de werkwijze is iets anders als zal later worden besproken.
- Framework: is verantwoordelijk voor taakplanning, verschillende soorten banen zullen een overeenkomstig Framework hebben, zoals het Spark Framework dat verantwoordelijk is voor Spark-banen.
Hulpbronaanbod van Mesos
het lijkt misschien alsof de Mesos-en GARENARCHITECTUREN vrij gelijkaardig zijn, maar in feite heeft de meester van Mesos op het gebied van Hulpbronbeheer een zeer uniek (en enigszins bizar) mechanisme voor Hulpbronaanbod:
- garen is Pull: De bronnen die door Resource Manager in garen worden verstrekt, zijn passief. wanneer gebruikers van resource (Application Master) bronnen nodig hebben, kan het de interface van Resource Manager aanroepen om bronnen te verkrijgen, en Resource Manager reageert alleen passief op de behoeften van Application Master.
- Mesos is Push: de middelen die Master of Mesos levert zijn proactief. Master of Mesos zal regelmatig het initiatief nemen om alle huidige beschikbare middelen (de zogenaamde Resource aanbiedingen, ik noem het aanbod van nu af aan) naar het Framework te duwen. Als er taken zijn die het Framework moet uitvoeren, kan het niet actief resources aanvragen, tenzij de aanbiedingen worden ontvangen. Framework selecteert een gekwalificeerde resource uit het aanbod om te accepteren (deze motie heet accepteren in Mesos) en de resterende aanbiedingen af te wijzen (deze motie wordt afgewezen). Als er niet genoeg gekwalificeerde middelen zijn in deze ronde van aanbod, moeten we wachten op de volgende ronde van Master Om aanbod te bieden.
ik geloof dat wanneer u dit actieve Aanbiedingsmechanisme ziet, u hetzelfde gevoel bij mij zult hebben. Dat wil zeggen, de efficiëntie is relatief laag, en de volgende problemen zullen zich voordoen:
- de beslissingsefficiëntie van elk kader beïnvloedt de algehele efficiëntie. Voor consistentie, Master kan alleen bieden aan een Framework op een moment, en wachten tot het Framework om het aanbod te selecteren voordat het verstrekken van de rest naar het volgende Framework. Op deze manier zal de efficiëntie van de besluitvorming van elk kader van invloed zijn op de algehele efficiëntie.
- veel tijd verspillen aan frameworks die geen resources nodig hebben. Mesos weet niet echt welk Framework middelen nodig heeft. Dus er zal Framework met resource requirements is queuing voor aanbod, maar het Framework zonder resource requirements krijgt vaak aanbod.
als reactie op de bovenstaande problemen heeft Mesos een aantal mechanismen verschaft om de problemen te beperken, zoals het instellen van een time-out voor het kader om beslissingen te nemen, of het toestaan van het kader om aanbiedingen af te wijzen door het in te stellen als Onderdrukkingsstatus. Aangezien dit niet het onderwerp van deze discussie is, worden de details hier verwaarloosd.
in feite zijn er enkele duidelijke voordelen voor Meso ‘ s die dit mechanisme van actief aanbod gebruiken:
- de prestaties zijn duidelijk verbeterd. Volgens de simulatietest kan een cluster maximaal 100.000 knooppunten ondersteunen. voor de productieomgeving van Twitter kan het grootste cluster 80.000 knooppunten ondersteunen. de belangrijkste reden is dat het actieve aanbod van Mesos Master mechanisme de verantwoordelijkheden van de Mesos verder vereenvoudigt. het proces van resource scheduling, resource to task matching, in Mesos is onderverdeeld in twee fasen: resources to Offer, en Offer to task. De Mesos Master is alleen verantwoordelijk voor het voltooien van de eerste fase, en de matching van de tweede fase wordt overgelaten aan het Framework.
- flexibeler en in staat om te voldoen aan een meer verantwoord beleid van taakplanning. Bijvoorbeeld, de strategie voor het gebruik van hulpbronnen van alle of niets.
Scheduling algorithm of Mesos DRF (Dominant Resource Fairness)
wat betreft het DRF algoritme heeft het eigenlijk niets te maken met ons begrip van Mesos architectuur, maar het is zeer kern en belangrijk in Mesos, dus Ik zal hier iets meer uitleggen.
zoals hierboven vermeld, biedt Mesos op zijn beurt het raamwerk aan, dus welk raamwerk moet worden geselecteerd om elke keer een aanbod te doen? Dit is het kernprobleem dat moet worden opgelost door het DRF-algoritme. Het basisprincipe is dat rekening wordt gehouden met zowel eerlijkheid als efficiëntie. Hoewel voldaan moet worden aan alle behoeften aan middelen van het raamwerk, moet het zo eerlijk mogelijk zijn om te voorkomen dat een raamwerk teveel middelen verbruikt en andere kaders verhongert.
DRF is een variant van het min-max fairness algoritme. In eenvoudige termen, Het is om het raamwerk met de laagste dominante gebruik van middelen te selecteren om het aanbod elke keer te bieden. Hoe bereken je het dominante gebruik van middelen van het Framework? Van alle brontypen die door het raamwerk worden bezet, wordt het brontype met de laagste brontype geselecteerd als de dominante bron. Het gebruik van hulpbronnen is precies het dominante gebruik van hulpbronnen van het Framework. Bijvoorbeeld, neemt een CPU van Kader 20% van de totale bron, 30% van het geheugen en 10% van de schijf in beslag. Dus het dominante resourcegebruik van het Framework zal 10% zijn, de officiële term noemt een schijf als dominante resource, en deze 10% wordt Dominant Resourcegebruik genoemd.
het uiteindelijke doel van DRF is om de middelen gelijkelijk over alle kaders te verdelen. Als een raamwerk X te veel middelen accepteert in deze ronde van het aanbod, zal het veel langer duren om de kans van de volgende ronde van het aanbod te krijgen. Zorgvuldige lezers zullen echter merken dat er een aanname is in dit algoritme, dat wil zeggen, nadat het raamwerk middelen accepteert, zal het ze snel vrijgeven, anders zullen er twee gevolgen zijn:
- andere kaders verhongeren. Eén Framework a accepteert de meeste resources in het cluster in één keer, en de taak blijft draaien zonder te stoppen, zodat de meeste resources worden bezet door Framework A de hele tijd, en andere frameworks zullen niet langer de resources te krijgen.
- verhonger uzelf. Omdat het dominante resourcegebruik van dit Framework altijd erg hoog is, is er dus lange tijd geen kans om een aanbod te krijgen, dus meer taken kunnen niet worden uitgevoerd.
dus Mesos is alleen geschikt voor het plannen van korte taken, en Mesos zijn oorspronkelijk ontworpen voor korte taken van datacenters.
samenvatting
uit de grote architectuur is alle scheduling systeemarchitectuur Master / Slave architectuur, Slave end wordt geïnstalleerd op elke machine met de vereiste van beheer, die wordt gebruikt om host informatie te verzamelen, en taken uit te voeren op de host. Master is voornamelijk verantwoordelijk voor resource scheduling en taakplanning. Resource scheduling heeft hogere eisen aan prestaties en taakplanning heeft hogere eisen aan schaalbaarheid. De algemene trend is om de twee soorten ontkoppelingen te bespreken en ze met verschillende componenten aan te vullen.
