gemeenschappelijk zoeken: het open source-project brengt PageRank terug
meld je aan voor onze dagelijkse samenvattingen van het steeds veranderende search marketing landschap.
opmerking: door dit formulier in te dienen, gaat u akkoord met de voorwaarden van Third Door Media. Wij respecteren uw privacy.

in de afgelopen jaren, Google heeft langzaam verminderd de hoeveelheid gegevens beschikbaar voor SEO beoefenaars. Eerst was het trefwoord gegevens, dan pagerank score. Nu is het specifieke zoekvolume van AdWords (tenzij je wat geld uitgeeft). U kunt meer over dit lezen in Russ Jones ‘ s uitstekende artikel dat de impact van het onderzoek van zijn bedrijf en inzichten in clickstream gegevens voor volume disambiguation detailleert.
een item waar we recentelijk echt bij betrokken zijn geraakt is gemeenschappelijke Crawl data. Er zijn verschillende teams in onze industrie die deze gegevens al enige tijd gebruiken, dus ik voelde me een beetje laat bij het spel. Common Crawl data is een open source project dat het hele internet met regelmatige tussenpozen schraapt. Gelukkig, Amazon, zijnde het grote bedrijf dat het is, gooide in om de gegevens op te slaan om het beschikbaar te maken voor velen zonder de hoge opslagkosten.
naast gemeenschappelijke Crawl-gegevens is er een non-profit genaamd Common Search, die tot taak heeft een alternatieve open source en transparante zoekmachine te creëren — in veel opzichten het tegenovergestelde van Google. Dit wekte mijn interesse omdat het betekent dat we allemaal kunnen spelen, tweaken en mangle de signalen om te leren hoe zoekmachines werken zonder de enorme investering van de tijd vanaf ground zero.
gemeenschappelijke zoekgegevens
momenteel gebruikt Common Search De volgende gegevensbronnen voor het berekenen van hun zoekranglijsten (dit is rechtstreeks afkomstig van hun website):
- Common Crawl: de grootste open repository van web crawl data. Dit is momenteel onze unieke bron van ruwe paginagegevens.
- Wikidata: Een gratis, gelinkte database die fungeert als centrale opslag voor de gestructureerde gegevens van vele Wikimedia-projecten zoals Wikipedia, Wikivoyage en Wikisource.
- UT1 Blacklist: deze blacklist wordt onderhouden door Fabrice Prigent van de Université Toulouse 1 Capitole en categoriseert domeinen en URL ‘ s in verschillende categorieën, waaronder “adult” en “phishing”.”
- DMOZ: ook bekend als het Open Directory Project, het is de oudste en grootste web directory nog in leven. Hoewel de gegevens niet zo betrouwbaar zijn als in het verleden, gebruiken we ze nog steeds als signaal-en metadatabron.
- Web Data Commons Hyperlink Graphs: Graphs of all hyperlinks from a 2012 Common Crawl archive. Momenteel gebruiken we het harmonische Centraliteitsbestand als tijdelijk ranking signaal op domeinen. We zijn van plan om onze eigen analyse van de webgrafiek in de nabije toekomst uit te voeren.
- Alexa Top 1m sites: Alexa rangschikt websites op basis van een gecombineerde meting van paginaweergaven en unieke sitegebruikers. Het is bekend dat het demografisch bevooroordeeld is. We gebruiken het als een tijdelijk ranking signaal op domeinen.
Common Search ranking
naast deze gegevensbronnen gebruikt het bij het onderzoeken van de code ook URL-lengte, padlengte en domeinpagerank als ranking-signalen in zijn algoritme. Ziedaar, sinds juli heeft Common Search zijn eigen gegevens op host-Level PageRank, en we hebben het allemaal gemist.
ik kom zo bij de PageRank (PR), maar het is interessant om de code van Common Crawl te bekijken, vooral de ranker.py gedeelte zich hier, omdat je echt kunt krijgen in de bestuurdersstoel met het tweaken van de gewichten van de signalen die het gebruikt om de pagina ‘ s rangschikken:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
van bijzonder belang, ook, is dat Common Search BM25 gebruikt als de gelijkenis maatregel van trefwoord document lichaam en metadata. BM25 is een betere maat dan TF-IDF omdat er rekening wordt gehouden met de lengte van het document, wat betekent dat een document van 200 woorden dat uw trefwoord vijf keer heeft waarschijnlijk relevanter is dan een document van 1500 woorden dat hetzelfde Aantal keer heeft.
het is ook de moeite waard om te zeggen dat het aantal signalen hier zeer rudimentair is en duidelijk mist veel van de verfijningen (en gegevens) die Google heeft geïntegreerd in hun zoekranglijst algoritme. Een van de belangrijkste dingen waar we aan werken is om de beschikbare gegevens in Common Crawl en de infrastructuur van Common Search te gebruiken om topic Vector search te doen voor inhoud die relevant is op basis van semantiek, niet alleen trefwoord matching.
naar PageRank
op de pagina Hier kunt u links vinden naar de host-level PageRank voor de juni 2016 Common Crawl. Ik gebruik de ene genaamd pagerank-top1m.txt.gz (top 1 miljoen) omdat het andere bestand is 3GB en meer dan 112 miljoen domeinen. Zelfs in R heb ik niet genoeg machine om het te laden zonder af te sluiten.
na het downloaden moet u het bestand in uw werkmap in R. brengen.de pagerank-gegevens van Common Search zijn niet genormaliseerd en zijn ook niet in het schone 0-10-formaat waarin we het allemaal gewend zijn te zien. Algemene zoekopdracht gebruikt ” max (0, min (1, float ( rank) / 244660.58)) — – in principe, rang van een domein gedeeld door Facebook ‘ s rang – als de methode van het vertalen van de gegevens in een verdeling tussen 0 en 1. Maar dit laat een aantal duidelijke hiaten, in die zin dat dit zou Linkedin ‘ s PageRank verlaten als een 1.4 wanneer geschaald door 10.

de volgende code laadt de dataset en voegt een PR-kolom toe met een beter benaderde PR:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
We moesten spelen rond een beetje met de nummers om het ergens in de buurt (voor een aantal voorbeelden van domeinen die ik herinnerde de PR voor) om de oude Google PR. Hieronder staan een paar voorbeelden van PageRank resultaten:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
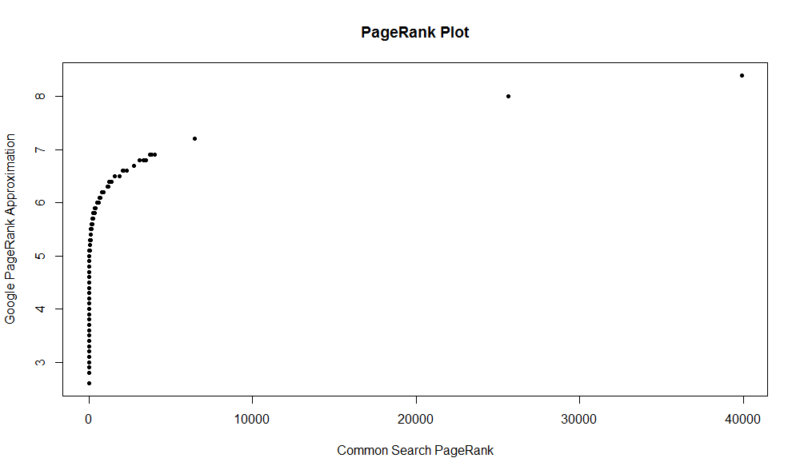
hier is een plot van 100.000 willekeurige monsters. De berekende pagerank score is langs de Y-as, en de oorspronkelijke gemeenschappelijke zoek score is langs de X-as.
om uw eigen resultaten te verkrijgen, kunt u het volgende commando uitvoeren in R (vervang gewoon uw eigen domein):
df

houd in gedachten dat deze dataset heeft alleen de top een miljoen domeinen door PageRank, dus van de 112 miljoen domeinen die Common Search geïndexeerd, is er een goede kans dat uw site kan er niet zijn als het niet beschikt over een vrij goede link profiel. Ook bevat deze maatstaf geen indicatie van de schadelijkheid van links, alleen een benadering van de populariteit van uw site met betrekking tot links.
gemeenschappelijk zoeken is een geweldig hulpmiddel en een geweldige basis. Ik kijk ernaar uit om meer betrokken te raken bij de gemeenschap daar en hopelijk leren om de moeren en bouten achter zoekmachines beter te begrijpen door daadwerkelijk te werken aan een. Met R en een beetje code, kunt u een snelle manier om te controleren PR voor een miljoen domeinen in een kwestie van seconden. Ik hoop dat je genoten hebt!
meld je aan voor onze dagelijkse samenvattingen van het steeds veranderende search marketing landschap.
opmerking: door dit formulier in te dienen, gaat u akkoord met de voorwaarden van Third Door Media. Wij respecteren uw privacy.
over de auteur

JR Oakes is de senior director van technisch SEO onderzoek bij Locomotive. Hij was voorheen directeur van technical SEO bij het agentschap Adapt Partners. Hij werkt met klanten op een breed scala aan fronten, waaronder technische problemen, prestaties, CTR, crawl-ability, content en data-analyse. JR houdt van testen, coderen en prototyping oplossingen voor moeilijke zoek marketing problemen. Als hij niet werkt, leest hij graag over opkomende technologieën, speelt basgitaar, kijkt naar college basketbal, kookt en brengt tijd door met zijn vrienden en familie. Hij is ook een van de medeorganisatoren van de Raleigh SEO Meetup, Raleigh SEO Conference en RTP SEO Meetup.