schaalbare, gedistribueerde secundaire indexering in Scylla

het gegevensmodel in Scylla en Apache Cassandra partitioneert gegevens tussen clusterknooppunten met behulp van een partitiesleutel, die wordt gedefinieerd door het databaseschema. Het gebruik van een partitiesleutel biedt een efficiënte manier om rijen op te zoeken met behulp van de partitiesleutel, omdat je het knooppunt kunt vinden dat de rij bezit door de partitiesleutel te hashen. Helaas betekent dit ook dat het vinden van een rij met een niet-partitiesleutel een volledige tabelscan vereist die inefficiënt is. Secundaire indexen zijn een mechanisme in Apache Cassandra dat efficiënte zoekopdrachten op niet-partitie sleutels mogelijk maakt door het creëren van een index.
In dit blogbericht leert u:
- hoe Apache Cassandra secundaire indexen implementeert met behulp van lokale indexering
- waarom we besloten hebben een andere implementatiestrategie te volgen voor Scylla met behulp van globale indexering
- hoe globale indexering beïnvloedt hoe u secundaire indexering
- hoe u uw eigen secundaire indexen maakt en gebruikt in uw toepassing CQL-query ‘ s
Achtergrond
de grootte van een index is proportioneel aan de grootte van de geïndexeerde gegevens. Aangezien gegevens in Scylla en Apache Cassandra naar meerdere knooppunten worden gedistribueerd, is het onpraktisch om de hele index op één knooppunt op te slaan. Apache Cassandra implementeert secundaire indexen als lokale indexen, wat betekent dat de index wordt opgeslagen op hetzelfde knooppunt als de gegevens die wordt geïndexeerd van dat knooppunt. Het voordeel van een lokale index is dat schrijft zijn zeer snel, maar het nadeel is dat leest moeten potentieel query elk knooppunt om de index te vinden om een lookup uit te voeren op, waardoor lokale indexen unscalable voor grote clusters. In aanvulling op de inheemse secundaire indexen, Apache Cassandra heeft ook een andere lokale indexering schema, SSTABLE Attached secundaire Index (SASI), die complexe query ‘ s en zoeken ondersteunt. Vanuit het oogpunt van schaalbaarheid heeft het echter precies dezelfde kenmerken als de oorspronkelijke secundaire indexen.
gematerialiseerde weergaven in Scylla en Apache Cassandra zijn een mechanisme om automatisch gegevens van een basistabel naar een weergavetabel te denormaliseren met behulp van een andere partitiesleutel. Dit lost de schaalbaarheid probleem van lokale indexen, maar komt tegen een opslagkosten, omdat je nodig hebt om de hele tabel te dupliceren in het ergste geval. Materialized Views zijn daarom geen vervanging voor secundaire indexen voor alle use cases. Materialized Views bieden echter de nodige infrastructuur om secundaire indexen te implementeren met behulp van global indexing, wat de implementatiebenadering is die voor Scylla wordt gebruikt.
globale indexering
Scylla hanteert een andere aanpak dan Apache Cassandra en implementeert secundaire indexen met behulp van globale indexering. Met global indexing wordt voor elke index een gematerialiseerde weergave gemaakt. De gematerialiseerde weergave heeft de geïndexeerde kolom als de partitiesleutel en primaire sleutel (partitiesleutel en clustering toetsen) van de geïndexeerde rij als clustering toetsen. Scylla breekt geïndexeerde query ‘ s in twee delen: (1) een query op de indextabel om partitiesleutels voor de geïndexeerde tabel op te halen en (2) een query op de geïndexeerde tabel met behulp van de opgehaalde partitiesleutels. Het voordeel van deze aanpak is dat we de waarde van de geïndexeerde kolom kunnen gebruiken om de overeenkomstige rij van de indextabel in het cluster te vinden, zodat reads schaalbaar zijn. Het nadeel van de aanpak is dat schrijft langzamer zijn dan bij lokale indexering vanwege alle overhead van het houden van de indexweergave up-to-date.
vragen op een geïndexeerde kolom ziet er als volgt uit. Laten we aannemen dat een tabel er zo uitziet:
en een query op de email kolom, die geen partitiesleutel is, maar een index heeft:
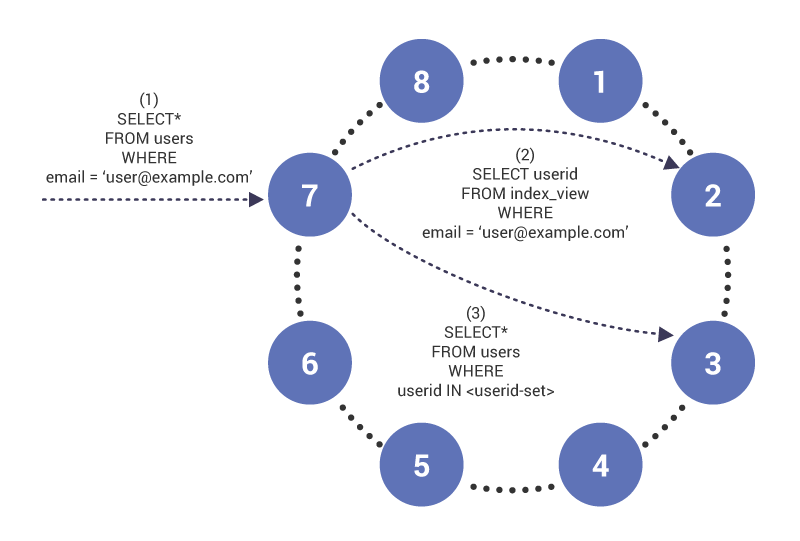
in Fase (1) komt de query op knooppunt 7, die fungeert als coördinator voor de query. Het knooppunt merkt op dat we querying op een geïndexeerde kolom en daarom in Fase (2), geeft een read to index table op knooppunt 2, die de index tabel rij voor “”heeft. De query geeft een set gebruikers-ID ‘ s terug die in Fase (3) worden gebruikt om de inhoud van de geïndexeerde tabel op te halen.
voorbeeld
we moeten eerst een schema maken. In dit voorbeeld hebben we een tabel die gebruikersinformatie weergeeft met userid als de partitiesleutel en naam, e-mail en land als reguliere kolommen:
we vullen de tabel dan met wat testgegevens gegenereerd met Mockaroo:
secundaire indexen zijn ontworpen om het efficiënt opvragen van niet-partitie sleutelkolommen mogelijk te maken. Hoewel Apache Cassandra ook queries ondersteunt op niet-partitiesleutelkolommen met ALLOW FILTERING, is dat zeer inefficiënt (waarbij de hele tabel moet worden gescand) en wordt momenteel niet ondersteund door Scylla (zie probleem #2200 voor details).
u kunt tabelkolommen indexeren met behulp van het statement index maken. Als u bijvoorbeeld indexen voor e-mail-en landkolommen wilt maken, voert u de volgende CQL-statements uit:
Scylla maakt automatisch een gematerialiseerde weergave met de geïndexeerde kolom als de partitiesleutel en de primaire doeltabel (partitiesleutel en clustering keys) als clustering keys.
bijvoorbeeld, de gematerialiseerde weergave voor de index op de kolom email ziet er als volgt uit:
als de bovenstaande weergave zou worden gemaakt als een gewone tabel, zou het er effectief als volgt uitzien:
de kolom email wordt gebruikt als de partitiesleutel voor de indextabel en userid is opgenomen als een clustering key, die ons in staat stelt om efficiënt partitiesleutels voor de doeltabel te vinden met slechts email.
u kunt het commando DESCRIBE gebruiken om het hele schema voor de ks.users tabel te zien, inclusief gemaakte indexen en weergaven:
nu met de secundaire Index op zijn plaats, kunt u geïndexeerde kolommen opvragen alsof het partitiesleutels waren:
we zijn klaar met het voorbeeld!
Wanneer moeten secundaire indexen worden gebruikt?
secundaire indexen zijn (meestal) transparant voor de toepassing. Queries hebben toegang tot alle kolommen in de tabel en u kunt indexen toevoegen en verwijderen zonder de toepassing te wijzigen. Secundaire indexen kunnen ook minder overhead hebben dan gematerialiseerde weergaven omdat secundaire indexen alleen de geïndexeerde kolom en primaire sleutel hoeven te dupliceren, niet de opgevraagde kolommen zoals bij een gematerialiseerde weergave. Bovendien kunnen om dezelfde reden updates efficiënter zijn met secundaire indexen, omdat alleen wijzigingen in de primaire sleutel en geïndexeerde kolom een update veroorzaken in de indexweergave. In het geval van een gematerialiseerde weergave vereist een update van een van de kolommen die in de weergave verschijnen dat de achterweergave wordt bijgewerkt.
Zoals altijd hangt de beslissing om secundaire indexen of gematerialiseerde weergaven te gebruiken echt af van de vereisten van uw toepassing. Als u maximale prestaties nodig hebt en waarschijnlijk een specifieke set kolommen opvraagt, moet u gematerialiseerde weergaven gebruiken. Als de toepassing echter verschillende sets kolommen moet opvragen, zijn secundaire indexen een betere keuze, omdat ze kunnen worden toegevoegd en verwijderd met minder opslagkosten, afhankelijk van de behoeften van de toepassing.
wilt u meer weten over secundaire indexen? Bekijk mijn presentatie van Scylla Summit 2017 op SlideShare. Als u deze functie wilt uitproberen, wordt verwacht dat het in de komende Scylla 2.2 release.