tijdsynchronisatie in Gedistribueerde Systemen
als u bekend bent met websites zoals facebook.com of google.com, misschien niet minder dan een keer heb je je afgevraagd hoe deze websites kunnen omgaan met miljoenen of zelfs tientallen miljoenen verzoeken per seconde. Zal er één commerciële server zijn die deze enorme hoeveelheid verzoeken kan weerstaan, op de manier dat elk verzoek tijdig kan worden bediend voor eindgebruikers?
als we dieper in deze kwestie duiken, komen we tot het concept van gedistribueerde systemen, een verzameling van onafhankelijke computers (of knooppunten) die voor de gebruikers als één samenhangend systeem lijken. Dit begrip van samenhang voor gebruikers is duidelijk, omdat ze geloven dat ze te maken hebben met een enkele gigantische machine die de vorm aanneemt van meerdere processen die parallel lopen om batches van verzoeken tegelijk af te handelen. Echter, voor mensen die begrijpen systeeminfrastructuur, dingen blijken niet zo gemakkelijk als zodanig.
voor duizenden onafhankelijke machines die gelijktijdig draaien en die meerdere tijdzones en continenten kunnen bestrijken, moeten bepaalde soorten synchronisatie of coördinatie worden opgegeven om deze machines efficiënt met elkaar te laten samenwerken (zodat ze als één machine kunnen verschijnen). In deze blog zullen we de synchronisatie van tijd bespreken en hoe het consistentie tussen machines bereikt over het ordenen en causaliteit van gebeurtenissen.
de inhoud van deze blog wordt als volgt georganiseerd:
- kloksynchronisatie
- logische klokken
- Take away
- What ‘ s next?
fysieke Klokken
in een gecentraliseerd systeem is de tijd ondubbelzinnig. Bijna alle computers hebben een “real-time klok” om de tijd bij te houden, meestal gesynchroniseerd met een precies bewerkt kwartskristal. Op basis van de goed gedefinieerde frequentie oscillatie van dit kwarts, kan het besturingssysteem van een computer de interne tijd nauwkeurig controleren. Zelfs wanneer de computer wordt uitgeschakeld of niet meer wordt opgeladen, blijft het kwarts tikken dankzij de CMOS-batterij, een kleine krachtpatser die in het moederbord is geïntegreerd. Wanneer de computer verbinding maakt met het Netwerk (Internet), neemt het besturingssysteem contact op met een timer-server, die is uitgerust met een UTC-ontvanger of een nauwkeurige klok, om de lokale timer nauwkeurig te resetten met behulp van Network Time Protocol, ook wel NTP genoemd.
hoewel deze frequentie van het kristalkwarts redelijk stabiel is, is het onmogelijk te garanderen dat alle kristallen van verschillende computers met exact dezelfde frequentie werken. Stel je een systeem voor met n computers, waarvan elk kristal met iets verschillende snelheden loopt, waardoor de klokken geleidelijk uit de synchronisatie raken en verschillende waarden geven bij het uitlezen. Het verschil in de tijd waarden veroorzaakt door dit heet klok scheef.
onder deze omstandigheden werd het rommelig omdat er meerdere ruimtelijk gescheiden machines waren. Als het gebruik van meerdere interne fysieke klokken wenselijk is, hoe synchroniseren we ze dan met echte klokken? Hoe synchroniseren we ze met elkaar?
Network Time Protocol
een gemeenschappelijke aanpak voor synchronisatie tussen computers in paren is door het gebruik van het client-server model, dat wil zeggen clients contact laten maken met een tijdserver. Laten we eens kijken naar het volgende voorbeeld met 2 machines A en B:
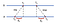
eerst stuurt A een verzoekstempel met de waarde T₀ naar B. B, als het bericht aankomt, registreert het tijdstip van ontvangst T₁ van zijn eigen lokale klok en reacties met een bericht tijdstempel met T₂, piggybacking de eerder geregistreerde waarde T₁. Ten slotte registreert A, na ontvangst van het antwoord van B, de aankomsttijd T₃. Om rekening te houden met de vertraging in het leveren van berichten, berekenen we Δ₁ = T₁-T₀, Δ₂ = T₃-T₂. Een geschatte offset van a ten opzichte van B is:

op basis van θ kunnen we de klok van A vertragen of vastzetten zodat de twee machines met elkaar kunnen worden gesynchroniseerd.
omdat NTP paarsgewijs toepasbaar is, kan de klok van B ook worden aangepast aan die van A. Het is echter onverstandig om de klok in B aan te passen als bekend is dat deze nauwkeuriger is. Om dit probleem op te lossen, verdeelt NTP servers in strata, dat wil zeggen ranking servers zodat de klokken van minder accurate servers met kleinere rangen gesynchroniseerd worden met die van de meer accurate servers met hogere rangen.
Berkeley algoritme
in tegenstelling tot clients die periodiek contact opnemen met een tijdserver voor nauwkeurige tijdssynchronisatie, stelden Gusella en Zatti, in 1989 Berkeley Unix paper , het client-server model voor waarin de tijdserver (daemon) elke machine periodiek peilt om te vragen hoe laat het daar is. Op basis van de reacties, berekent het de round-trip tijd van de berichten, gemiddelden de huidige tijd met onwetendheid van eventuele uitschieters in tijdwaarden, en “vertelt alle andere machines om hun klokken vooruit naar de nieuwe tijd of vertragen hun klokken naar beneden totdat een bepaalde vermindering haw bereikt” .
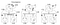
logische Klokken
laten we een stap terug doen en onze basis voor gesynchroniseerde tijdstempels heroverwegen. In de vorige paragraaf kennen we concrete waarden toe aan de klokken van alle deelnemende machines, voortaan kunnen ze het eens worden over een wereldwijde tijdlijn waarop gebeurtenissen plaatsvinden tijdens de uitvoering van het systeem. Echter, wat echt belangrijk is in de tijdlijn is de volgorde waarin gerelateerde gebeurtenissen plaatsvinden. Bijvoorbeeld, als een of andere manier hoeven we alleen maar te weten Een evenement gebeurt vóór de gebeurtenis B, het maakt niet uit als Tₐ = 2, Tᵦ = 6 of Tₐ = 4, Tᵦ = 10, zolang Tₐ < Tᵦ. Dit verschuift onze aandacht naar het rijk van logische klokken, waar synchronisatie wordt beïnvloed door Leslie Lamport ‘ s definitie van “happens-before” relatie .Lamport ‘ s logische Klokken
in zijn fenomenale 1978 paper Time, Clocks, and the ordening of Events in a Distributed System, definieerde Lamport de “happens-before” relatie “→” als volgt:
1. Als A en b gebeurtenissen zijn in hetzelfde proces, en a komt voor b, dan a→b.
2. Als a het verzenden van een bericht is door een proces en b de ontvangst van hetzelfde bericht door een ander proces, dan is a→b.
3. Als a→b en b→c, dan a→c.
als gebeurtenissen x, y voorkomen in verschillende processen die geen berichten uitwisselen, is noch x → y noch y → x waar, x en y worden gezegd dat ze gelijktijdig zijn. Gegeven een c-functie die een tijdwaarde C(a) toekent aan een gebeurtenis waarover alle processen het eens zijn, als a en b gebeurtenissen binnen hetzelfde proces zijn en a vóór b, c(a) < C(b)*optreedt. Als a het verzenden van een bericht is via een proces en b de ontvangst van dat bericht via een ander proces, dan is C(A) < C(b) **.
laten we nu eens kijken naar het algoritme dat Lamport voorstelde voor het toewijzen van tijden aan gebeurtenissen. Overweeg het volgende voorbeeld met een cluster van 3 processen A, B, C:

deze drie procesklokken werken op hun eigen timing en zijn aanvankelijk niet gesynchroniseerd. Elke klok kan worden geïmplementeerd met een eenvoudige software teller, verhoogd met een specifieke waarde elke T tijd eenheden. De waarde waarmee een klok wordt verhoogd verschilt echter per proces: 1 Voor A, 5 voor B en 2 Voor C.
op tijdstip 1 stuurt A bericht m1 naar B. Op het moment van aankomst leest de klok bij B 10 in zijn interne klok. Aangezien het bericht is verzonden werd getimestamped met tijd 1, de waarde 10 in proces B is zeker mogelijk(we kunnen concluderen dat het 9 teken nodig om te komen tot B van A).
overweeg nu bericht m2. Het verlaat B om 15 en komt aan bij C om 8. Deze klokwaarde bij C is duidelijk onmogelijk omdat de tijd niet terug kan gaan. Van ** en het feit dat m2 vertrekt op 15, moet het aankomen op 16 of later. Daarom moeten we de huidige tijdwaarde bijwerken om groter te zijn dan 15 (we voegen +1 toe aan de tijd voor eenvoud). Met andere woorden, wanneer een bericht binnenkomt en de klok van de ontvanger een waarde toont die voorafgaat aan de tijdstempel die het vertrek van het bericht aangeeft, wordt de klok door de ontvanger snel vooruitgestuurd om een eenheid van tijd meer te zijn dan de vertrektijd. In Figuur 6 zien we dat m2 nu de klokwaarde corrigeert op C naar 16. Op dezelfde manier komen m3 en m4 op respectievelijk 30 en 36.
uit het bovenstaande voorbeeld formuleert Maarten Van Steen et al het algoritme van Lamport als volgt:
1. Voor het uitvoeren van een gebeurtenis (dat wil zeggen het verzenden van een bericht over het netwerk, …), Pᵢ stappen Cᵢ: cᵢ <- Cᵢ + 1.
2. Wanneer proces Pᵢ bericht m verzendt naar proces Pj, stelt het m ‘ s tijdstempel ts (m) gelijk aan Cᵢ na het uitvoeren van de vorige stap.
3. Na ontvangst van een bericht m, past process Pj zijn eigen lokale teller aan als Cj <- max{Cj, ts(m)} waarna het de eerste stap uitvoert en het bericht aan de toepassing aflevert.
Vectorklokken
denk terug aan Lamport ‘ s definitie van “happens-before” relatie, als er twee gebeurtenissen a en b zodanig zijn dat a Voor b voorkomt, dan wordt a ook geplaatst in die volgorde voor b, dat wil zeggen C(a) < C(b). Dit impliceert echter geen omgekeerde causaliteit, aangezien we niet kunnen afleiden dat a Voor b gaat door alleen de waarden van C(a) en C(b) te vergelijken (het bewijs wordt als oefening aan de lezer overgelaten).
om meer informatie af te leiden over de volgorde van gebeurtenissen op basis van hun tijdstempel, wordt vectorklokken, een meer geavanceerde versie van Lamport ‘ s logische klok, voorgesteld. Voor elk proces Pᵢ van het systeem onderhoudt het algoritme een vector VCᵢ met de volgende kenmerken:
1. VCᵢ: lokale logische klok op Pᵢ, of het aantal gebeurtenissen dat zich heeft voorgedaan vóór de huidige tijdstempel.
2. Als VCᵢ = k, Pᵢ weet dat k gebeurtenissen hebben plaatsgevonden op Pj.
het algoritme van Vectorklokken gaat dan als volgt:
1. Voordat een gebeurtenis wordt uitgevoerd, registreert Pᵢ een nieuwe gebeurtenis op zichzelf door vcᵢ <- VCᵢ + 1 uit te voeren.
2. Wanneer Pᵢ een bericht m naar Pj stuurt, stelt het tijdstempel ts (m) gelijk aan VCᵢ na het uitvoeren van de vorige stap.
3. Wanneer bericht m is ontvangen, verwerk PJ elke k van zijn eigen vectorklok: vcj ← max { VCj , ts (m)}. Vervolgens gaat het verder met het uitvoeren van de eerste stap en levert het bericht aan de applicatie.
door deze stappen, wanneer een proces Pj een bericht m ontvangt van proces Pᵢ met tijdstempel ts(m), weet het het aantal gebeurtenissen dat zich heeft voorgedaan op Pᵢ terloops voorafgaand aan het verzenden van m. bovendien Weet Pj ook over de gebeurtenissen die bekend zijn bij Pᵢ over andere processen voordat het verzenden van m. (ja, dat is waar, als je dit algoritme relateert aan het Roddelprotocol 🙂).
hopelijk laat de Verklaring je niet te lang op je hoofd krabben. Laten we een voorbeeld nemen om het concept onder de knie te krijgen:

in dit voorbeeld hebben we drie processen P₁, P₂, en P₃ als alternatief het uitwisselen van berichten om hun klokken samen te synchroniseren. P₁ stuurt bericht m1 op logische tijd VC₁ = (1, 0, 0) (Stap 1) naar P₂. P₂, bij ontvangst van m1 met tijdstempel ts (m1) = (1, 0, 0), past zijn logische tijd VC₂ aan (1, 1, 0) (stap 3) en stuurt bericht m2 terug naar P₁ met tijdstempel (1, 2, 0) (Stap 1). Op dezelfde manier accepteert proces P₁ het bericht m2 van P₂, verandert zijn logische klok naar (2, 2, 0) (stap 3), waarna het bericht m3 naar P₃ op (3, 2, 0) stuurt. P₃ past zijn klok aan (3, 2, 1) (stap 1) Nadat het bericht m3 van P₁ ontvangt. Later neemt het bericht M4 in, verzonden door P₂ op (1, 4, 0), en daarmee zijn klok aan te passen aan (3, 4, 2) (Stap 3).
gebaseerd op hoe we de interne klokken vooruitspoelen Voor synchronisatie, gaat gebeurtenis a vooraf aan gebeurtenis b als voor alle k, ts(a) ≤ ts(b), en er is ten minste één index k’ waarvoor ts(a) < ts(b). Het is niet moeilijk om te zien dat (2, 2, 0) vooraf gaat aan (3, 2, 1), maar (1, 4, 0) en (3, 2, 0) kunnen met elkaar conflicteren. Daarom kunnen we met vectorklokken detecteren of er een causale afhankelijkheid is tussen twee gebeurtenissen.
Take away
wanneer het gaat om het begrip tijd in een gedistribueerd systeem, is het primaire doel om de juiste volgorde van de gebeurtenissen te bereiken. Gebeurtenissen kunnen worden geplaatst in chronologische volgorde met fysieke klokken of in logische volgorde met Lamtport ‘ s logische klokken en Vector Klokken langs de uitvoering tijdlijn.
wat volgt?
in de volgende reeks zullen we bespreken hoe tijdssynchronisatie verrassend eenvoudige antwoorden kan bieden op enkele klassieke problemen in gedistribueerde systemen: hoogstens één bericht , cacheconsistentie en wederzijdse uitsluiting .
Leslie Lamport: tijd, klokken en de volgorde van gebeurtenissen in een gedistribueerd systeem. 1978.
Barbara Liskov: praktisch gebruik van gesynchroniseerde klokken in gedistribueerde systemen. 1993.
Maarten van Steen, Andrew S. Tanenbaum: Distributed Systems. 2017.
Barbara Liskov, Liuba Shrira, John Wroclawski: Efficiënte berichten op basis van gesynchroniseerde Klokken. 1991.
Cary G. Gray, David R. Cheriton: Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache consistence. 1989.
Ricardo Gusella, Stefano Zatti: the Accuracy of the Clock Synchronization reached by TEMPO in Berkeley UNIX 4.3 BSD. 1989.