căutare comună: proiectul open source aduce înapoi PageRank
Înscrieți-vă pentru recapitulările noastre zilnice ale peisajului de marketing de căutare în continuă schimbare.
Notă: Prin trimiterea acestui formular, sunteți de acord cu Termenii Third Door Media. Vă respectăm confidențialitatea.

în ultimii ani, Google a redus încet cantitatea de date disponibile pentru practicienii SEO. Mai întâi au fost date despre cuvinte cheie, apoi scorul PageRank. Acum este volumul de căutare specific din AdWords (cu excepția cazului în care cheltuiți ceva moola). Puteți citi mai multe despre acest lucru în articolul excelent al lui Russ Jones, care detaliază impactul cercetărilor companiei sale și perspectivele asupra datelor clickstream pentru dezambiguizarea volumului.
un element în care ne-am implicat cu adevărat recent sunt datele comune de accesare cu crawlere. Există mai multe echipe din industria noastră care folosesc aceste date de ceva timp, așa că m-am simțit puțin târziu la joc. Common Crawl data este un proiect open source care zgârie întregul internet la intervale regulate. Din fericire, Amazon, fiind marea companie este, tăbărât în pentru a stoca datele pentru a face disponibile pentru mulți fără costurile ridicate de stocare.
pe lângă datele comune de accesare cu crawlere, există o organizație non-profit numită căutare comună a cărei misiune este de a crea un motor de căutare alternativ open source și transparent — opusul, în multe privințe, al Google. Acest lucru mi-a stârnit interesul, deoarece înseamnă că toți putem juca, modifica și gestiona semnalele pentru a afla cum funcționează motoarele de căutare fără investiția uriașă de timp de a începe de la zero.
date comune de căutare
în prezent, căutarea comună utilizează următoarele surse de date pentru calcularea clasamentului lor de căutare (Aceasta este preluată direct de pe site-ul lor web):
- Crawl comun: cel mai mare depozit deschis de date de accesare cu crawlere web. Aceasta este în prezent sursa noastră unică de date brute de pagină.
- Wikidata: O bază de date gratuită, legată, care acționează ca stocare centrală pentru datele structurate ale multor proiecte Wikimedia, cum ar fi Wikipedia, Wikivoyage și Wikisource.
- lista neagră UT1: întreținută de Fabrice Prigent de la Universitatea din Toulouse 1 Capitole, această listă neagră clasifică domeniile și adresele URL în mai multe categorii, inclusiv “adult” și “phishing.”
- DMOZ: cunoscut și sub numele de Open Directory Project, este cel mai vechi și mai mare Director web încă în viață. Deși datele sale nu sunt la fel de fiabile ca în trecut, le folosim în continuare ca sursă de semnal și metadate.
- Web Data Commons hyperlink Graphics: grafice ale tuturor hyperlinkurilor dintr-o Arhivă comună de accesare cu crawlere din 2012. În prezent, folosim fișierul său de centralitate armonică ca semnal temporar de clasare pe domenii. Intenționăm să efectuăm propria noastră analiză a graficului web în viitorul apropiat.
- Alexa top 1M sites: Alexa clasează site-urile web pe baza unei măsuri combinate de vizualizări de pagină și utilizatori unici ai site-ului. Se știe că este părtinitor din punct de vedere demografic. Îl folosim ca un semnal temporar de clasare pe domenii.
căutare comună ranking
în plus față de aceste surse de date, în investigarea codul, se folosește, de asemenea, lungimea URL-ul, lungimea cale și domeniu PageRank ca semnale de rang în algoritmul său. Iată și iată, din iulie, Common Search are propriile date despre PageRank la nivel de gazdă și cu toții am ratat-o.
voi ajunge la PageRank (PR) într-o clipă, dar este interesant să revizuiți codul De Accesare Cu Crawlere comună, în special ranker.Py porțiune situat aici, pentru că într-adevăr se poate obține în scaunul șoferului cu tweaking greutățile semnalelor pe care le folosește pentru a rang paginile:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
de remarcat, de asemenea, este că căutarea obișnuită folosește BM25 ca măsură de similitudine a cuvântului cheie pentru a documenta corpul și meta-datele. BM25 este o măsură mai bună decât TF-IDF, deoarece ia în considerare lungimea documentului, ceea ce înseamnă că un document de 200 de cuvinte care are cuvântul dvs. cheie de cinci ori este probabil mai relevant decât un document de 1.500 de cuvinte care îl are același număr de ori.
de asemenea, merită să spunem că numărul de semnale de aici este foarte rudimentar și, evident, lipsesc multe dintre rafinările (și datele) pe care Google le-a integrat în algoritmul lor de clasare a căutării. Unul dintre lucrurile cheie la care lucrăm este să folosim datele disponibile în Crawl comun și infrastructura căutării comune pentru a face căutarea vectorială a subiectelor pentru conținut relevant pe baza semanticii, nu doar a potrivirii cuvintelor cheie.
pe PageRank
pe pagina de aici, puteți găsi link-uri către PageRank la nivel de gazdă pentru iunie 2016 Crawl comun. Îl folosesc pe cel intitulat pagerank-top1m.txt.gz (top 1 milion), deoarece celălalt fișier este de 3 GB și peste 112 milioane de domenii. Chiar și în R, nu am suficientă mașină pentru ao încărca fără a limita.
după descărcare, va trebui să aduceți fișierul în directorul dvs. de lucru în R. datele PageRank din Căutarea comună nu sunt normalizate și, de asemenea, nu sunt în formatul curat 0-10 în care suntem cu toții obișnuiți să îl vedem. Căutare comună utilizează ” max(0, min(1, float (rang) / 244660.58))” — practic, rangul unui domeniu împărțit la rangul Facebook — ca metodă de traducere a datelor într-o distribuție între 0 și 1. Dar acest lucru lasă unele lacune clare, în sensul că acest lucru ar lăsa PageRank-ul Linkedin ca 1.4 atunci când este scalat cu 10.

următorul cod va încărca setul de date și va adăuga o coloană PR cu un PR mai bine aproximat:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
a trebuit să ne jucăm puțin cu numerele pentru a ajunge undeva aproape (pentru mai multe eșantioane de domenii pentru care mi-am amintit PR-ul) de vechiul Google PR. Mai jos sunt câteva exemple de rezultate PageRank:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Iată un complot de 100.000 de eșantioane aleatorii. Scorul PageRank calculat este de-a lungul axei Y, iar scorul inițial de căutare comun este de-a lungul axei X.
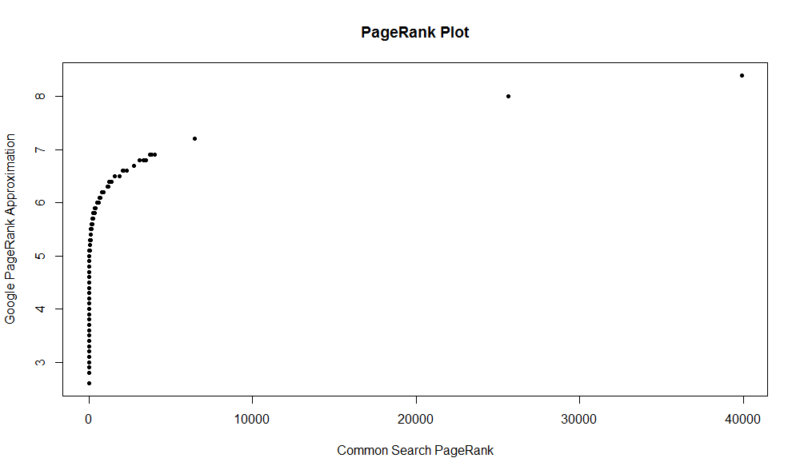
pentru a obține propriile rezultate, puteți rula următoarea comandă în R (înlocuiți doar propriul domeniu):
df

rețineți că acest set de date are doar primele un milion de domenii de către PageRank, deci din 112 milioane de domenii indexate în căutarea obișnuită, există șanse mari ca site-ul dvs. să nu fie acolo dacă nu are un profil de legătură destul de bun. De asemenea, această valoare nu include nicio indicație a nocivității legăturilor, ci doar o aproximare a popularității site-ului dvs. în ceea ce privește legăturile.
căutarea comună este un instrument excelent și o bază excelentă. Aștept cu nerăbdare să mă implic mai mult în comunitatea de acolo și, sperăm, să învăț să înțeleg mai bine piulițele și șuruburile din spatele motoarelor de căutare, lucrând efectiv la unul. Cu R și un mic cod, puteți avea o modalitate rapidă de a verifica PR pentru un milion de domenii în câteva secunde. Sper că ți-a plăcut!
Înscrieți-vă pentru recapitulările noastre zilnice ale peisajului de marketing de căutare în continuă schimbare.
Notă: Prin trimiterea acestui formular, sunteți de acord cu Termenii Third Door Media. Vă respectăm confidențialitatea.
despre autor

JR Oakes este directorul principal al cercetării tehnice SEO la Locomotive. A fost anterior director de SEO tehnic la Agenția Adapt Partners. Lucrează cu clienții pe o gamă largă de fronturi, inclusiv probleme tehnice, performanță, CTR, capacitate de accesare cu crawlere, conținut și analiză a datelor. JR iubește testarea, codificarea și prototiparea soluțiilor la probleme dificile de marketing de căutare. Când nu lucrează, îi place să citească despre tehnologiile emergente, să cânte la chitară bas, să privească baschet la facultate, să gătească și să petreacă timp cu prietenii și familia. Este, de asemenea, unul dintre co-organizatorii Raleigh SEO Meetup, Raleigh SEO Conference și RTP SEO Meetup.