Cloud Data Warehouse vs concepte tradiționale Data Warehouse
depozitele de date bazate pe Cloud sunt noua normă. Au dispărut zilele în care afacerea dvs. a trebuit să achiziționeze hardware, să creeze camere de server și să angajeze, să antreneze și să mențină o echipă dedicată de personal pentru a o conduce. Acum, cu câteva clicuri pe laptop și un card de credit, puteți accesa puterea de calcul practic nelimitată și spațiul de stocare.
cu toate acestea, acest lucru nu înseamnă că ideile tradiționale de depozit de date sunt moarte. Teoria clasică a depozitului de date stă la baza majorității depozitelor de date bazate pe cloud.
în acest articol, vă vom explica conceptele tradiționale de depozit de date pe care trebuie să le cunoașteți și cele mai importante cloud dintr-o selecție a furnizorilor de top: Amazon, Google și Panoply. În cele din urmă, vom încheia cu o analiză cost-beneficiu a depozitelor de date tradiționale vs.cloud, astfel încât să știți care este potrivit pentru dvs.
să începem.
- concepte tradiționale de depozit de date
- fapte, dimensiuni și măsuri
- normalizare și denormalizare
- modele de date
- tabel de fapte
- schema stelară vs.schema Fulg De Zăpadă
- OLAP vs.OLTP
- arhitectura pe trei niveluri
- Virtual Data Warehouse / Data Mart
- Kimball vs.Inmon
- ETL vs.ELT
- Enterprise Data Warehouse
- Cloud Data Warehouse concepte
- Cloud Data Warehouse Concepts – Amazon Redshift
- clustere
- noduri
- partiții/felii
- stocare coloană
- compresie
- încărcare date
- Cloud Database Warehouse – Google BigQuery
- serviciu fără Server
- Colossus File System
- Dremel Execution Engine
- schimbul de date
- Streaming și Lot ingestia
- Cloud Data Warehouse Concepts – panoplia
- chei primare
- chei incrementale
- date imbricate
- tabele de istoric
- transformări
- formate String
- protecția datelor
- Control Acces
- IP Whitelisting
- concluzie: concepte tradiționale vs.Data Warehouse pe scurt
- concepte tradiționale de depozit de date
- Cloud Data Warehouse Concepts – Amazon Redshift ca exemplu
- Cloud Data Warehouse Concepts – BigQuery ca exemplu
- Analiza Cost-Beneficiu tradițională vs. Cloud
- Aflați mai multe despre depozitele de date
concepte tradiționale de depozit de date
un depozit de date este orice sistem care colectează date dintr-o gamă largă de surse din cadrul unei organizații. Depozitele de date sunt utilizate ca depozite centralizate de date în scopuri analitice și de raportare.
un depozit de date tradițional este situat la fața locului la birourile dvs. Achiziționați hardware-ul, camerele serverului și angajați personalul pentru a-l rula. Acestea sunt, de asemenea, numite depozite de date on-premises, on-prem sau (incorecte din punct de vedere gramatical) on-premise.
fapte, dimensiuni și măsuri
elementele de bază ale informațiilor dintr-un depozit de date sunt fapte, dimensiuni și măsuri.
un fapt este partea din datele dvs. care indică o anumită apariție sau tranzacție. De exemplu, dacă afacerea dvs. vinde flori, unele fapte pe care le-ați vedea în depozitul dvs. de date sunt:
- vândut 30 trandafiri în magazin pentru $19.99
- comandat 500 ghivece de flori noi din China pentru $1500
- Salariu plătit de casier pentru această lună $1000
mai multe numere pot descrie fiecare fapt și numim aceste numere măsuri. Unele măsuri pentru a descrie faptul ‘comandat 500 noi ghivece de flori din China pentru $1500’ sunt:
- cantitate comandată-500
- Cost – $1500
când analiștii lucrează cu date, aceștia efectuează calcule privind măsurile (de exemplu, suma, maximul, media) pentru a culege informații. De exemplu, poate doriți să știți numărul mediu de ghivece de flori pe care le comandați în fiecare lună.
o dimensiune clasifică fapte și măsuri și oferă informații structurate de etichetare pentru ei – în caz contrar, acestea ar fi doar o colecție de numere neordonate! Unele dimensiuni pentru a descrie faptul ‘comandat 500 noi ghivece de flori din China pentru $1500’ sunt:
- țara achiziționată de la-China
- ora achiziționată – 1 pm
- data estimată a sosirii – 6 iunie
nu puteți efectua calcule pe dimensiuni în mod explicit și, probabil, acest lucru nu ar fi foarte util – cum puteți găsi ‘data medie de sosire pentru comenzi’? Cu toate acestea, este posibil să se creeze noi măsuri din dimensiuni, iar acestea sunt utile. De exemplu, dacă știți numărul mediu de zile între data comenzii și data sosirii, puteți planifica mai bine achizițiile de acțiuni.
normalizare și denormalizare
normalizare este procesul de organizare eficientă a datelor într-un depozit de date (sau în orice alt loc care stochează date). Principalele obiective sunt reducerea redundanței datelor – adică eliminarea oricăror date duplicate – și îmbunătățirea integrității datelor-adică îmbunătățirea acurateței datelor. Există niveluri diferite de normalizare și nu există consens pentru cea mai bună metodă. Cu toate acestea, toate metodele implică stocarea unor informații separate, dar conexe, în tabele diferite.
există multe beneficii pentru normalizare, cum ar fi:
- căutarea și sortarea mai rapidă pe fiecare tabel
- tabelele mai simple fac comenzile de modificare a datelor mai rapide pentru a scrie și executa
- date mai puțin redundante înseamnă că economisiți spațiu pe disc și astfel puteți colecta și stoca mai multe date
denormalizarea este procesul de adăugare deliberată a copiilor redundante sau a grupurilor de date la datele deja normalizate. Nu este același lucru cu datele ne-normalizate. Denormalizare îmbunătățește performanța de citire și face mult mai ușor de a manipula tabele în forme pe care doriți. Atunci când analiștii lucrează cu depozitele de date, aceștia efectuează de obicei doar citiri pe date. Astfel, datele denormalizate le pot economisi cantități mari de timp și dureri de cap.
beneficiile denormalizării:
- mai puține tabele minimizează nevoia de alăturări de tabele care accelerează fluxul de lucru al analiștilor de date și îi determină să descopere informații mai utile în date
- mai puține tabele simplifică interogările care duc la mai puține erori
modele de date
ar fi extrem de ineficient să stocați toate datele într-un singur tabel masiv. Deci, depozitul dvs. de date conține multe tabele pe care le puteți uni pentru a obține informații specifice. Tabelul principal se numește tabel de fapt, iar tabelele de dimensiuni îl înconjoară.
primul pas în proiectarea unui depozit de date este construirea unui model de date conceptual care definește datele dorite și relațiile la nivel înalt dintre ele.
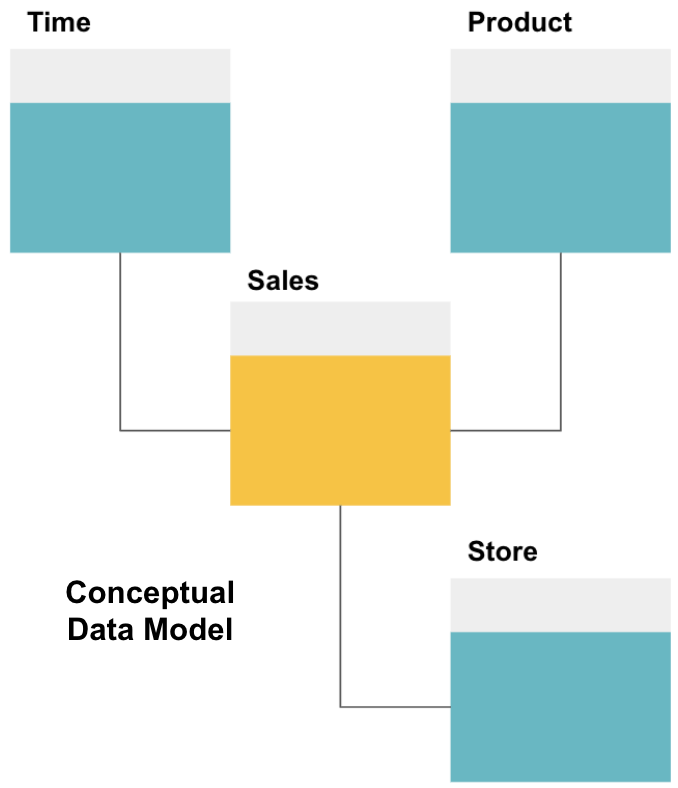
aici am definit modelul conceptual. Stocăm date despre vânzări și avem trei tabele suplimentare – timp, Produs și magazin – care oferă informații suplimentare și mai detaliate despre fiecare vânzare. Tabelul de fapt este de vânzări, iar celelalte sunt tabele de dimensiuni.
următorul pas este definirea unui model de date logic. Acest model descrie datele în detaliu în limba engleză simplă, fără să vă faceți griji cu privire la modul de implementare a acestora în cod.
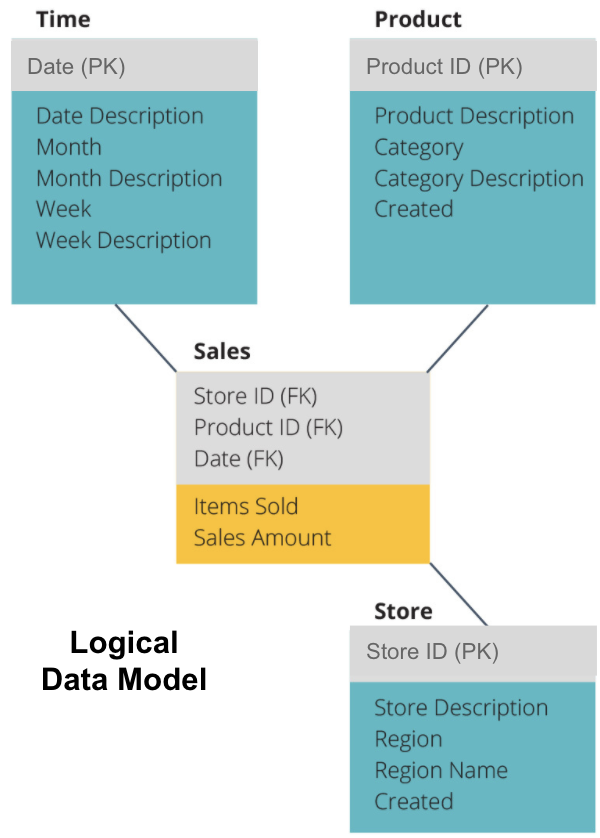
acum am completat ce informații conține fiecare tabel în engleză simplă. Fiecare dintre tabelele de dimensiuni Time, Product și Store afișează cheia primară (PK) în caseta gri și datele corespunzătoare în casetele albastre. Tabelul de vânzări conține trei chei străine (FK), astfel încât să se poată alătura rapid cu celelalte tabele.
etapa finală este crearea unui model de date fizice. Acest model vă spune cum să implementați depozitul de date în cod. Definește tabelele, structura lor și relația dintre ele. De asemenea, specifică tipurile de date pentru coloane și totul este denumit așa cum va fi în depozitul final de date, adică toate capacele și conectate cu subliniere. În cele din urmă, fiecare tabel dimensiune începe cu DIM_, și fiecare tabel de fapt începe cu FACT_.
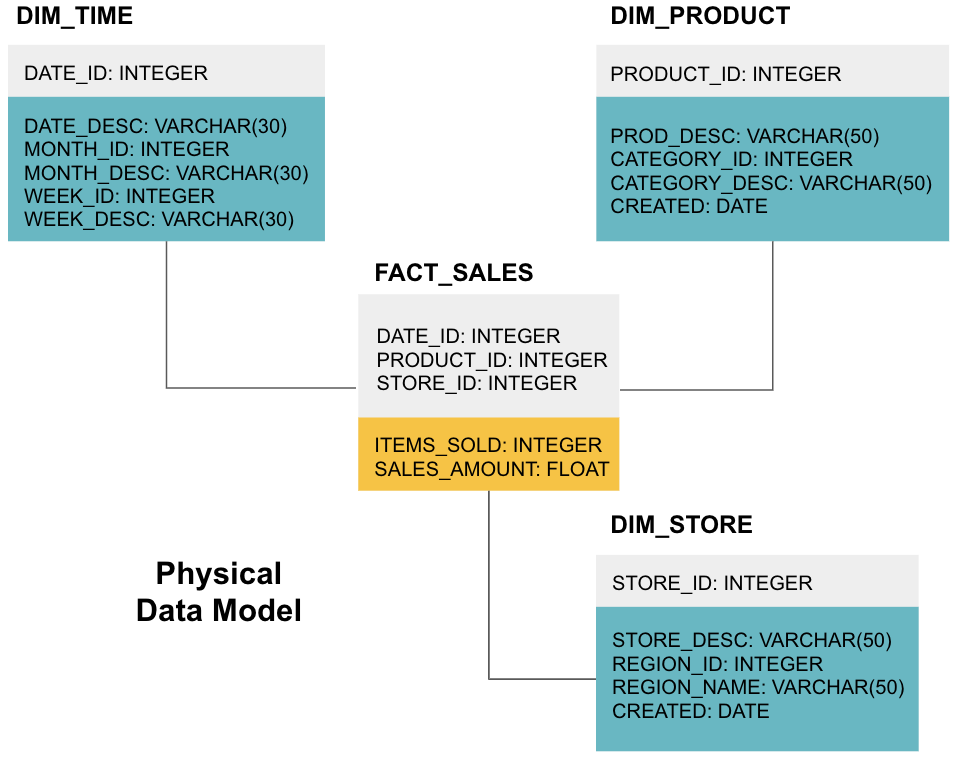
acum știți cum să proiectați un depozit de date, dar există câteva nuanțe pentru tabelele de fapt și dimensiuni pe care le vom explica în continuare.
tabel de fapte
fiecare funcție de afaceri – de exemplu, vânzări, marketing, finanțe – are un tabel de fapte corespunzător.
tabelele de fapte au două tipuri de coloane: coloane de dimensiuni și coloane de fapte. Coloanele de dimensiuni-colorate în gri în exemplele noastre-conțin chei străine (FK) pe care le utilizați pentru a asocia un tabel de fapte cu un tabel de dimensiuni. Aceste chei străine sunt cheile primare (PK) pentru fiecare dintre tabelele de dimensiuni. Coloanele Fact-colorate în galben în exemplele noastre-conțin datele și măsurile reale care trebuie analizate, de exemplu, numărul de articole vândute și valoarea totală a vânzărilor în dolari.
un tabel de fapte factless este un anumit tip de tabel de fapte care are doar coloane de dimensiuni. Astfel de tabele sunt utile pentru urmărirea evenimentelor, cum ar fi participarea studenților sau concediul angajaților, deoarece dimensiunile vă spun tot ce trebuie să știți despre evenimente.
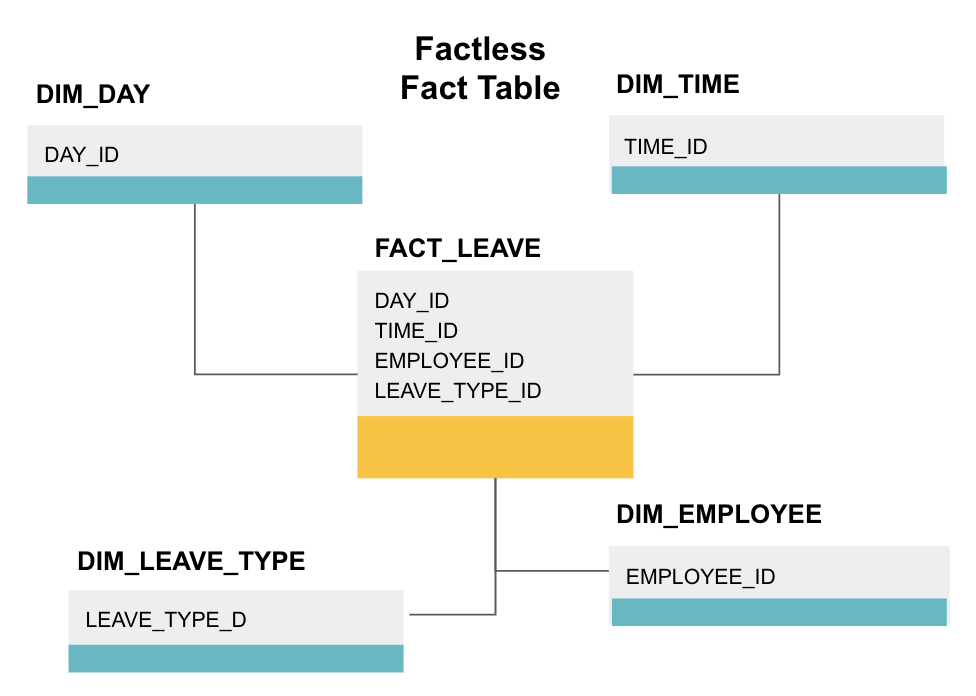
tabelul de mai sus fapt factless piese concediu angajat. Nu există fapte, deoarece trebuie doar să știți:
- ce zi au fost oprite (DAY_ID).
- cât timp au fost oprite (TIME_ID).
- cine era în concediu (EMPLOYEE_ID).
- motivul pentru care sunt în concediu, de ex., boală, vacanță, numirea medicului etc. (LEAVE_TYPE_ID).
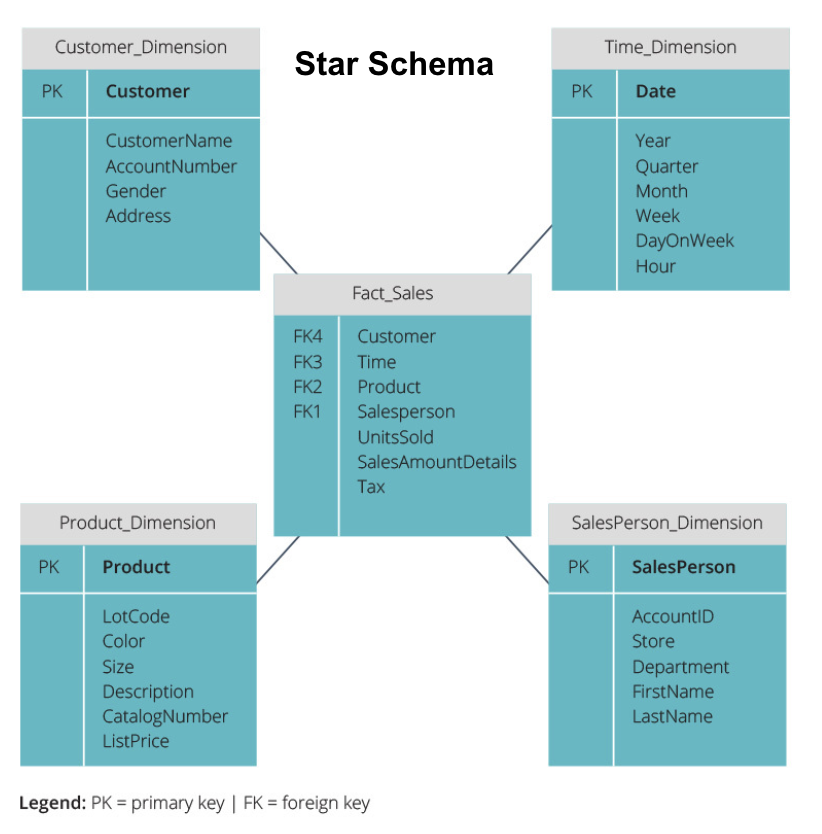
schema stelară vs.schema Fulg De Zăpadă
depozitele de date de mai sus au avut toate un aspect similar. Totuși, aceasta nu este singura modalitate de a le aranja.
cele mai comune două scheme utilizate pentru organizarea depozitelor de date sunt star și snowflake. Ambele metode folosesc tabele de dimensiuni care descriu informațiile conținute într-un tabel de fapte.
schema stelară preia informațiile din tabelul fact și le împarte în tabele de dimensiuni denormalizate. Accentul pentru schema stea este pe viteza de interogare. Este nevoie de un singur join pentru a lega tabele de fapt la fiecare dimensiune, astfel interogarea fiecare tabel este ușor. Cu toate acestea, deoarece tabelele sunt denormalizate, ele conțin adesea date repetate și redundante.
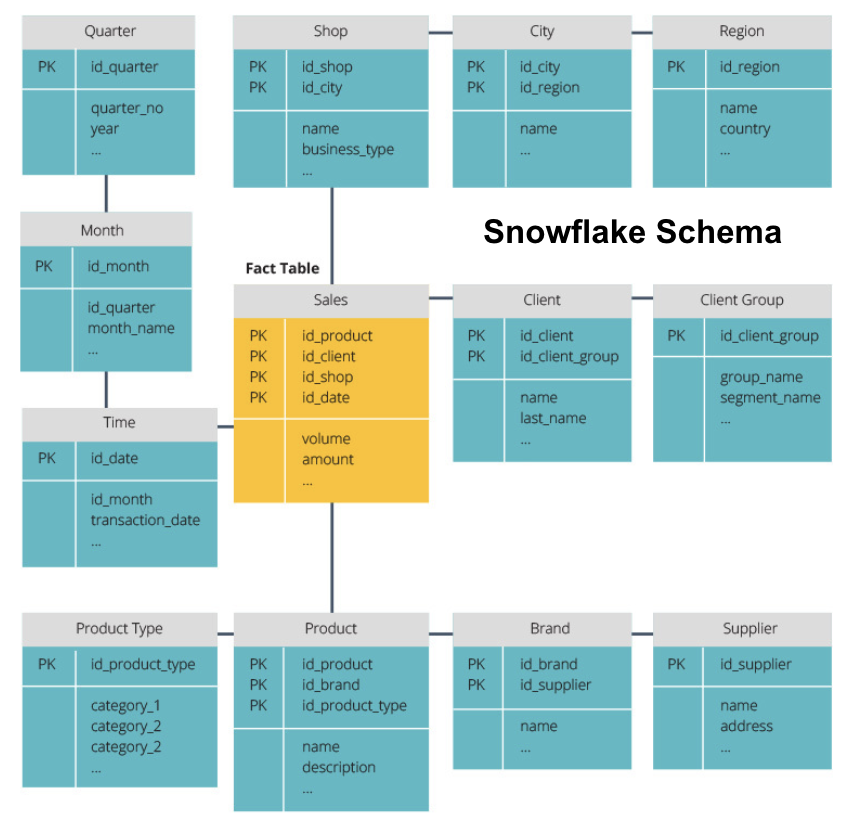
schema snowflake împarte tabelul fact într-o serie de tabele de dimensiuni normalizate. Normalizarea creează mai multe tabele de dimensiuni și astfel reduce problemele de integritate a datelor. Cu toate acestea, interogarea este mai dificilă folosind schema snowflake, deoarece aveți nevoie de mai multe îmbinări de tabel pentru a accesa datele relevante. Deci, aveți date mai puțin redundante, dar este mai greu de accesat.
acum vom explica câteva concepte fundamentale ale depozitului de date.
OLAP vs.OLTP
procesarea tranzacțiilor Online (OLTP) se caracterizează prin tranzacții de scriere scurtă care implică aplicațiile front-end ale arhitecturii de date a unei întreprinderi. Bazele de date OLTP subliniază procesarea rapidă a interogărilor și se ocupă doar de datele curente. Întreprinderile le folosesc pentru a capta informații pentru procesele de afaceri și pentru a furniza date sursă pentru depozitul de date.
procesarea analitică Online (OLAP) vă permite să rulați interogări complexe de citire și astfel să efectuați o analiză detaliată a datelor tranzacționale istorice. Sistemele OLAP ajută la analiza datelor din depozitul de date.
arhitectura pe trei niveluri
depozitele de date tradiționale sunt de obicei structurate în trei niveluri:
- nivelul inferior: un server de baze de date, de obicei un RDBMS, care extrage date din diferite surse folosind un gateway. Sursele de date introduse în acest nivel includ baze de date operaționale și alte tipuri de date front-end, cum ar fi fișierele CSV și JSON.
- Middle Tier: un server OLAP care fie
- implementează direct operațiile, fie
- mapează operațiile pe date multidimensionale la operații relaționale standard, de exemplu, aplatizarea datelor XML sau JSON în rânduri din tabele.
- Top Tier: instrumentele de interogare și raportare pentru analiza datelor și business intelligence.
Virtual Data Warehouse / Data Mart
Virtual data warehousing utilizează interogări distribuite pe mai multe baze de date, fără a integra datele într-un singur depozit de date fizice.
data marts sunt subseturi de depozite de date orientate pentru funcții specifice de afaceri, cum ar fi vânzările sau finanțele. Un depozit de date Combină de obicei informații de la mai multe marts de date în mai multe funcții de afaceri. Cu toate acestea, un mart de date conține date dintr-un set de sisteme sursă pentru o funcție de afaceri.
Kimball vs.Inmon
există două abordări pentru proiectarea depozitului de date, propuse de Bill Inmon și Ralph Kimball. Bill Inmon este un informatician American care este recunoscut ca tatăl depozitului de date. Ralph Kimball este unul dintre arhitecții originali ai depozitării datelor și a scris mai multe cărți pe această temă.
cei doi experți au avut opinii contradictorii cu privire la modul în care ar trebui structurate depozitele de date. Acest conflict a dat naștere la două școli de gândire.
abordarea Inmon este un design de sus în jos. Cu metodologia Inmon, depozitul de date este creat mai întâi și este văzut ca componenta centrală a mediului analitic. Datele sunt apoi rezumate și distribuite din depozitul centralizat la unul sau mai multe marts de date dependente.
abordarea Kimball are o vedere de jos în sus a designului depozitului de date. În această arhitectură, o organizație creează marturi de date separate, care oferă vizualizări în departamente unice din cadrul unei organizații. Depozitul de date este combinația acestor marturi de date.
ETL vs.ELT
Extract, Transform, Load (ETL) descrie procesul de extragere a datelor din sistemele sursă (de obicei sisteme tranzacționale), convertirea datelor într-un format sau structură adecvată pentru interogare și analiză și, în final, încărcarea acestora în depozitul de date. ETL utilizează o bază de date separată și aplică o serie de reguli sau funcții datelor extrase înainte de încărcare.
Extract, Load, Transform (ELT) este o abordare diferită a datelor de încărcare. ELT preia datele din surse disparate și le încarcă direct în sistemul țintă, cum ar fi depozitul de date. Sistemul transformă apoi datele încărcate la cerere pentru a permite analiza.
ELT oferă o încărcare mai rapidă decât ETL, dar necesită un sistem puternic pentru a efectua transformările de date la cerere.
Enterprise Data Warehouse
un depozit de date enterprise este conceput ca un depozit unificat, centralizat care conține toate informațiile tranzacționale din organizație, atât actuale, cât și istorice. Un depozit de date de întreprindere ar trebui să includă date din toate domeniile legate de afaceri, cum ar fi marketingul, vânzările, finanțele și resursele umane.
acestea sunt ideile de bază care alcătuiesc depozitele tradiționale de date. Acum, să ne uităm la ce depozite de date cloud au adăugat deasupra lor.
Cloud Data Warehouse concepte
cloud data depozite sunt noi și în continuă schimbare. Pentru a înțelege cel mai bine conceptele lor fundamentale, cel mai bine este să aflați despre soluțiile de depozit de date cloud.
trei soluții de depozit de date cloud sunt Amazon Redshift, Google BigQuery și Panoply. Mai jos, vă explicăm concepte fundamentale din fiecare dintre aceste servicii pentru a vă oferi o înțelegere generală a modului în care funcționează depozitele de date moderne.
Cloud Data Warehouse Concepts – Amazon Redshift
următoarele concepte sunt utilizate în mod explicit în Amazon Redshift cloud data warehouse, dar se pot aplica soluțiilor suplimentare de depozit de date în viitor bazate pe infrastructura Amazon.
clustere
Amazon Redshift își bazează arhitectura pe clustere. Un cluster este pur și simplu un grup de resurse de calcul partajate, numite noduri.
noduri
nodurile sunt resurse de calcul care au CPU, RAM și spațiu pe hard disk. Un cluster care conține două sau mai multe noduri este compus dintr-un nod lider și noduri de calcul.
nodurile Leader comunică cu programele client și compilează codul pentru a executa interogări, atribuindu-l nodurilor de calcul. Nodurile de calcul rulează interogările și returnează rezultatele la nodul leader. Un nod de calcul execută numai interogări care tabele de referință stocate pe acel nod.
partiții/felii
partiții Amazon fiecare nod calcula în felii. O felie primește o alocare de memorie și spațiu pe disc pe nod. Mai multe felii funcționează în paralel pentru a accelera timpul de execuție a interogării.
stocare coloană
Redshift utilizează stocarea coloană, permițând o performanță mai bună a interogării analitice. În loc să stocheze înregistrări în rânduri, stochează valori dintr-o singură coloană pentru mai multe rânduri. Următoarele diagrame fac acest lucru mai clar:
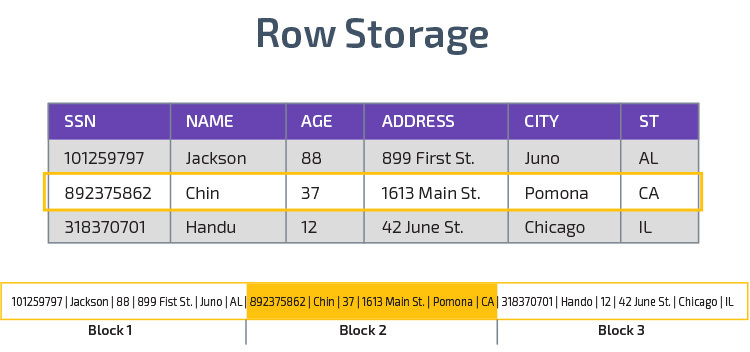
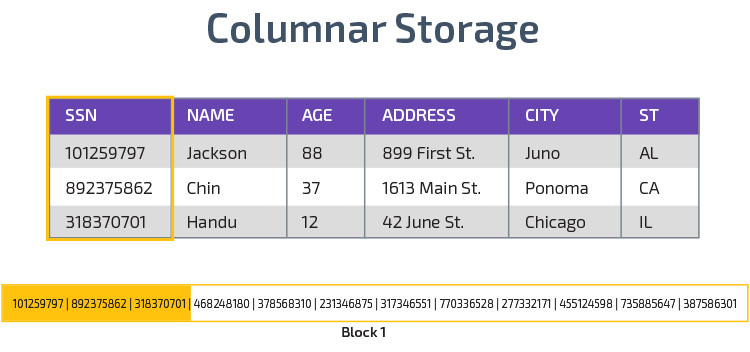
stocarea columnară face posibilă citirea mai rapidă a datelor, ceea ce este crucial pentru interogările analitice care acoperă multe coloane dintr-un set de date. Stocarea columnară ocupă, de asemenea, mai puțin spațiu pe disc, deoarece fiecare bloc conține același tip de date, ceea ce înseamnă că poate fi comprimat într-un format specific.
compresie
compresie reduce dimensiunea datelor stocate. În Redshift, din cauza modului în care sunt stocate datele, compresia are loc la nivelul coloanei. Redshift vă permite să comprimați informațiile manual atunci când creați un tabel sau utilizând automat comanda Copiere.
încărcare date
puteți utiliza comanda Copiere Redshift pentru a încărca cantități mari de date în depozitul de date. Comanda COPY utilizează arhitectura MPP a redshift pentru a citi și încărca date în paralel din fișierele de pe Amazon S3, dintr-un tabel DynamoDB sau ieșire de text de la una sau mai multe gazde la distanță.
de asemenea, este posibil să transmiteți date în Redshift, utilizând serviciul Amazon Kinesis Firehose.
Cloud Database Warehouse – Google BigQuery
următoarele concepte sunt utilizate în mod explicit în Google BigQuery cloud data warehouse, dar se pot aplica soluțiilor suplimentare în viitor bazate pe infrastructura Google.
serviciu fără Server
BigQuery folosește arhitectura fără server. Cu BigQuery, companiile nu trebuie să gestioneze unitățile de server fizice pentru a-și rula depozitele de date. În schimb, BigQuery gestionează dinamic alocarea resurselor sale de calcul. Întreprinderile care utilizează serviciul plătesc pur și simplu pentru stocarea datelor pe gigabyte și interogări pe terabyte.
Colossus File System
BigQuery utilizează cea mai recentă versiune a sistemului de fișiere distribuit Google, cu numele de cod Colossus. Sistemul de fișiere Colossus utilizează algoritmi de stocare și compresie coloană pentru a stoca datele în scopuri analitice în mod optim.
Dremel Execution Engine
Dremel execution engine utilizează un aspect coloană pentru a interoga magazine vaste de date rapid. Motorul de execuție Dremel poate rula interogări ad-hoc pe miliarde de rânduri în câteva secunde, deoarece folosește procesarea masivă paralelă sub forma unei arhitecturi de arbori.
arhitectura arborelui distribuie interogări între mai multe servere intermediare de la un server rădăcină. Serverele intermediare împing interogarea în jos la serverele leaf (care conțin date stocate), care scanează datele în paralel. Pe drumul înapoi în copac, fiecare server leaf Trimite rezultate de interogare, iar serverele intermediare efectuează o agregare paralelă a rezultatelor parțiale.
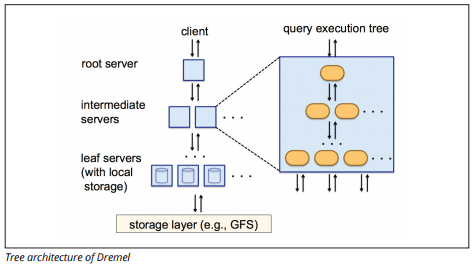
sursa imaginii
Dremel permite organizațiilor să ruleze interogări pe până la zeci de mii de servere simultan. Potrivit Google, Dremel poate scana 35 de miliarde de rânduri fără un index în zeci de secunde.
schimbul de date
arhitectura serverless Google BigQuery permite întreprinderilor să partajeze cu ușurință date cu alte organizații, fără a cere acestor organizații să investească în propria lor stocare.
organizațiile care doresc să interogheze date partajate pot face acest lucru și vor plăti doar pentru interogări. Nu este nevoie să creați silozuri de date partajate costisitoare, externe infrastructurii de date a organizației și să copiați datele în acele silozuri.
Streaming și Lot ingestia
este posibil să se încarce date la BigQuery de stocare Google Cloud, inclusiv CSV, JSON (newline-delimitat), și fișiere Avro, precum și backup Google Cloud Datastore. De asemenea, puteți încărca date direct dintr-o sursă de date lizibilă.
BigQuery oferă, de asemenea, un API de Streaming pentru a încărca date în sistem la o viteză de milioane de rânduri pe secundă fără a efectua o încărcare. Datele sunt disponibile pentru analiză aproape imediat.
Cloud Data Warehouse Concepts – panoplia
panoplia este un depozit all-in-one care combină ETL cu un depozit de date puternic. Este cel mai simplu mod de a sincroniza, stoca și accesa datele unei companii prin eliminarea dezvoltării și codificării asociate cu transformarea, integrarea și gestionarea datelor mari.
mai jos sunt câteva dintre conceptele principale din depozitul de date Panoply legate de modelarea datelor și protecția datelor.
chei primare
chei primare asigurați-vă că toate rândurile din tabelele dvs. sunt unice. Fiecare tabel are una sau mai multe chei primare care definesc ceea ce reprezintă un singur rând unic în baza de date. Toate API-urile au o cheie primară implicită pentru tabele.
chei incrementale
panoplia utilizează o cheie incrementală pentru a controla atributele pentru încărcarea incrementală a datelor în depozitul de date din surse, mai degrabă decât reîncărcarea întregului set de date de fiecare dată când se schimbă ceva. Această caracteristică este utilă pentru seturi de date mai mari, care pot dura mult timp pentru a citi date în mare parte neschimbate. Cheia incrementală indică ultimul punct de actualizare pentru rândurile din acea sursă de date.
date imbricate
datele imbricate nu sunt pe deplin compatibile cu suitele BI și interogările SQL standard—panoplia se ocupă de datele imbricate utilizând un model puternic relațional care nu permite valori imbricate. Panoplia transformă datele imbricate în aceste moduri:
- Subtables: în mod implicit, panoply transformă datele imbricate într-un set de tabele de relații mulți-La-mulți sau unu-la-mulți, care sunt tabele relaționale plate.
- aplatizare: cu acest mod activat, panoplia aplatizează structura imbricată pe înregistrarea care o conține.
tabele de istoric
uneori trebuie să analizați datele urmărind schimbarea datelor în timp pentru a vedea exact cum se schimbă datele (de exemplu, adresele oamenilor).
pentru a efectua astfel de analize, Panoply utilizează tabele de istorie, care sunt tabele de serii de timp care conțin instantanee istorice ale fiecărui rând din tabelul static original. Puteți efectua apoi interogarea directă a tabelului original sau revizuiri ale tabelului prin rebobinarea în orice moment.
transformări
panoplia folosește ELT, care este o variație a procesului original de integrare a datelor ETL. După ce ați injectat date din sursă în depozitul dvs. de date, panoplia le transformă imediat. Acest proces vă oferă analiza datelor în timp real și performanțe optime în comparație cu procesul ETL standard.
formate String
panoplia analizează formatele string și le gestionează ca și cum ar fi obiecte imbricate în datele originale. Formatele de șir acceptate sunt CSV, TSV, JSON, JSON-Line, Ruby object format, șiruri de interogare URL și jurnale de distribuție web.
protecția datelor
Panoply este construit pe partea de sus a AWS, deci are cele mai recente patch-uri de securitate și capabilități de criptare furnizate de AWS, inclusiv criptare RSA accelerată hardware și set specific de caracteristici de securitate Amazon Redshift lui.
protecție suplimentară vine de la criptare columnar, care vă permite să utilizați cheile private, care nu sunt stocate pe serverele Panoply lui.
Control Acces
Panoply utilizează verificarea în doi pași pentru a preveni accesul neautorizat, iar un sistem de permisiuni vă permite să restricționați accesul la anumite tabele, vizualizări sau coloane. Detectarea anomaliilor identifică interogările care provin de la computere noi sau dintr-o altă țară, permițându-vă să blocați aceste interogări, cu excepția cazului în care primesc aprobare manuală.
IP Whitelisting
vă recomandăm să blocați conexiunile din surse nerecunoscute utilizând un firewall sau un grup de securitate AWS și lista albă gama de adrese IP pe care sursele de date Panoply le utilizează întotdeauna la accesarea bazei de date.
concluzie: concepte tradiționale vs.Data Warehouse pe scurt
pentru a încheia, vom rezuma conceptele introduse în acest document.
concepte tradiționale de depozit de date
- fapte și măsuri: o măsură este o proprietate pe care se pot face calcule. Ne referim la o colecție de măsuri ca fapte, dar uneori termenii sunt folosiți în mod interschimbabil.
- normalizare: procesul de reducere a cantității de date duplicate, ceea ce duce la un depozit de date mai eficient în memorie, care este mai lent de interogat.
- Dimensiune: folosit pentru a clasifica și contextualiza fapte și măsuri, permițând analiza și raportarea cu privire la aceste măsuri.
- model Conceptual de date: definește entitățile critice de date la nivel înalt și relațiile dintre ele.
- model de date logice: Descrie relațiile de date, entitățile și atributele în limba engleză simplă, fără să vă faceți griji cu privire la modul de implementare a acestora în cod.
- model de date fizice: o reprezentare a modului de implementare a proiectării datelor într-un sistem specific de gestionare a bazelor de date.
- schema stea: ia un tabel de fapt și Împarte informațiile sale în tabele de dimensiuni denormalizate.
- schema Snowflake: împarte tabelul fact în tabele de dimensiuni normalizate. Normalizarea reduce problemele de redundanță a datelor și îmbunătățește integritatea datelor, dar interogările sunt mai complexe.
- OLTP: Sistemele de procesare a tranzacțiilor online facilitează procesarea rapidă, orientată spre tranzacții, cu interogări simple.
- OLAP: procesarea analitică Online vă permite să rulați interogări complexe de citire și astfel să efectuați o analiză detaliată a datelor tranzacționale istorice.
- Data mart: o arhivă de date care se concentrează pe un anumit subiect sau departament din cadrul unei organizații.
- abordare Inmon: abordarea depozit de date Bill Inmon definește depozitul de date ca depozit de date centralizat pentru întreaga întreprindere. Marts de date pot fi construite din depozitul de date pentru a servi nevoilor analitice ale diferitelor departamente.
- abordarea Kimball: Ralph Kimball descrie un depozit de date ca fuzionarea datelor critice pentru misiune, care sunt create pentru a servi nevoilor analitice ale diferitelor departamente.
- ETL: integrează datele în depozitul de date extragându-le din diverse surse tranzacționale, transformând datele pentru a le optimiza pentru analiză și, în final, încărcându-le în depozitul de date.
- ELT: O variație pe ETL care extrage datele brute din sursele de date ale unei organizații și le încarcă în depozitul de date. Atunci când este necesar, este transformat în scopuri analitice.
- Enterprise Data Warehouse: EDW consolidează datele din toate domeniile legate de întreprindere.
Cloud Data Warehouse Concepts – Amazon Redshift ca exemplu
- Cluster: un grup de resurse de calcul partajate bazate în cloud.
- nod: o resursă de calcul conținută într-un cluster. Fiecare nod are propriul CPU, RAM și spațiu pe hard disk.
- stocare coloană: Aceasta stochează valorile unui tabel în coloane, mai degrabă decât rânduri, care optimizează datele pentru interogări agregate.
- compresie: tehnici de reducere a dimensiunii datelor stocate.
- încărcarea datelor: obținerea datelor din surse în depozitul de date bazat pe cloud. În Redshift, puteți utiliza comanda Copiere sau un serviciu de streaming de date.
Cloud Data Warehouse Concepts – BigQuery ca exemplu
- Serverless service: furnizorul de cloud gestionează dinamic alocarea resurselor mașinii pe baza cantității pe care utilizatorul o consumă. Furnizorul de cloud ascunde deciziile de gestionare a serverului și de planificare a capacității de la utilizatorii serviciului.
- Colossus file system: un sistem de fișiere distribuit care utilizează algoritmi de stocare coloană și compresie a datelor pentru a optimiza datele pentru analiză.
- Dremel execution engine: un motor de interogare care utilizează procesare paralelă masivă și stocare coloană pentru a executa interogări rapid.
- partajarea datelor: într—un serviciu fără server, este practic să interogați datele partajate ale unei alte organizații fără a investi în stocarea datelor-pur și simplu plătiți pentru interogări.
- Streaming de date: introducerea datelor în timp real în depozitul de date fără a efectua o încărcare. Puteți transmite date în solicitări batch, care sunt mai multe apeluri API combinate într-o singură solicitare HTTP.
Analiza Cost-Beneficiu tradițională vs. Cloud
| Cost/beneficiu | tradițional | Cloud |
| Cost | cost mare în avans pentru achiziționarea și instalarea unui sistem on-prem. aveți nevoie de hardware, camere de server și personal specializat (pe care îl plătiți în mod continuu). dacă nu sunteți sigur de cât spațiu de stocare aveți nevoie, există riscul unor costuri ridicate scufundate greu de recuperat. |
nu este nevoie să achiziționați hardware, camere de server sau să angajați specialiști. niciun risc de costuri nerecuperabile – cumpărarea mai multor depozite în viitor este ușoară. în plus, costul stocării și al puterii de calcul scad în timp. |
| scalabilitate | odată ce vă maximizați camerele de server actuale sau capacitatea hardware, poate fi necesar să achiziționați hardware nou și să construiți/cumpărați mai multe locuri pentru a-l găzdui. în plus, trebuie să cumpărați suficient spațiu de stocare pentru a face față orelor de vârf; astfel, de cele mai multe ori, cea mai mare parte a spațiului dvs. de stocare nu este utilizat. |
puteți cumpăra cu ușurință mai mult spațiu de stocare ca și când aveți nevoie. de multe ori trebuie doar să plătiți pentru ceea ce utilizați, deci nu există niciun risc de a plăti în exces. |
| integrări | deoarece cloud computing este norma, majoritatea integrărilor pe care doriți să le faceți vor fi către serviciile cloud. conectarea depozitului de date personalizat la acestea se poate dovedi dificilă. |
deoarece depozitele de date cloud sunt deja în cloud, conectarea la o serie de alte servicii cloud este simplă. |
| securitate | aveți control total asupra depozitului de date. comparând cantitatea de date pe care o găzduiești cu Amazon sau Google, ești o țintă mai mică pentru hoți. Deci, s-ar putea să fii mai probabil să fii lăsat în pace. |
furnizorii de depozite de date Cloud au Echipe pline de ingineri de securitate cu înaltă calificare, al căror unic scop este de a-și face produsul cât mai sigur posibil. cele mai proeminente companii din lume le gestionează și, prin urmare, implementează practici de securitate de talie mondială. |
| guvernanță | știți exact unde sunt datele dvs. și le puteți accesa local. risc mai mic ca datele extrem de sensibile să încalce din greșeală Legea, de exemplu, călătorind în întreaga lume pe un server cloud. |
furnizorii de depozit de date cloud de top se asigură că respectă legile de guvernanță și securitate, cum ar fi GDPR. În plus, vă ajută afacerea să vă asigure că sunteți conform. au existat probleme cu privire la cunoașterea exactă a datelor dvs. și unde se mișcă. Aceste probleme sunt abordate și rezolvate în mod activ. rețineți că stocarea unor cantități mari de date extrem de sensibile în cloud poate fi împotriva legilor specifice. Acesta este un caz în care cloud computing-ul poate fi inadecvat pentru afacerea dvs. |
| fiabilitate | dacă depozitul dvs. de date on-prem eșuează, este responsabilitatea dvs. să îl remediați. echipa dvs. IT are acces la hardware-ul fizic și poate accesa fiecare strat software pentru depanare. Acest acces rapid poate face rezolvarea problemelor mult mai rapid. cu toate acestea, nu există nicio garanție că depozitul dvs. va avea o anumită perioadă de funcționare în fiecare an. |
furnizorii de depozite de date Cloud își garantează fiabilitatea și timpul de funcționare în SLA-urile lor. ele funcționează pe sisteme distribuite masiv în întreaga lume, deci dacă există un eșec pe unul, este foarte puțin probabil să vă afecteze. |
| Control | depozitul de date este personalizat construit pentru a se potrivi nevoilor dumneavoastră. În teorie, face ceea ce vrei să facă, când vrei, într-un mod pe care îl înțelegi. | nu aveți control total asupra depozitului de date. cu toate acestea, în majoritatea timpului, controlul pe care îl aveți este mai mult decât suficient. |
| Speed | dacă sunteți o companie mică într-o singură locație geografică cu o cantitate mică de date, prelucrarea datelor dvs. va fi mai rapidă. cu toate acestea, vorbim de milisecunde vs.secunde pentru finalizarea unor procese. este puțin probabil ca o companie mare care operează în mai multe țări să înregistreze câștiguri semnificative de viteză cu un sistem on-prem. |
furnizorii de Cloud au investit și au creat sisteme care implementează procesare masivă paralelă (MPP), motoare de arhitectură și execuție personalizate și algoritmi inteligenți de procesare a datelor. depozitele de date Cloud sunt rezultatul anilor de cercetare și testare pentru a crea resurse optimizate pentru viteză și performanță. poate fi ușor mai lent decât on-prem în unele cazuri, dar aceste întârzieri sunt adesea neglijabile pentru oameni (secunde vs.milisecunde). |
Panoply este un loc sigur pentru a stoca, sincroniza și accesa toate datele dvs. de afaceri. Panoplia poate fi configurată în câteva minute, necesită întreținere zero și oferă asistență online, inclusiv acces la arhitecți de date cu experiență. Încercați Panoply gratuit timp de 14 zile.
Aflați mai multe despre depozitele de date
- arhitectura depozitului de date: tradițional vs. Cloud
- baza de Date vs. depozit de date
- Data Mart vs. depozit de date