Clustering și K înseamnă: definiție și analiză Cluster în Excel
statistici definiții > Clustering / Cluster Analysis
ce este Clustering?
gruparea în statistici se referă la modul în care datele sunt colectate (“grupate”) de factori precum:
- vârsta.
- dimensiunea gospodăriei.
- venituri.
- sau nivelul de educație.
Sortarea datelor în clustere duce uneori la mai multe investigații asupra datelor. De exemplu, grupurile de cancer pot indica o problemă în mediu. Sau, ele pot fi doar un rezultat al naturii fiind aleatoare. Analiza Cluster tinde să fie subiectivă în multe cazuri; depinde de ceea ce percepeți ca fire comune în date. Tehnica nu este cu adevărat ceva nou în statistici; dacă ați făcut vreodată un grafic cu bare, probabil că ați făcut deja clustere (chiar dacă nu l-ați numit așa). De exemplu, un grafic cu bare care arată rasele de câini necesită gruparea în funcție de rasă (Husky Siberian, Border Collie, ciobanesc German…) sau o diagramă a nivelurilor de venit ar putea fi grupată în funcție de nivelurile de venit scăzute, medii și ridicate.
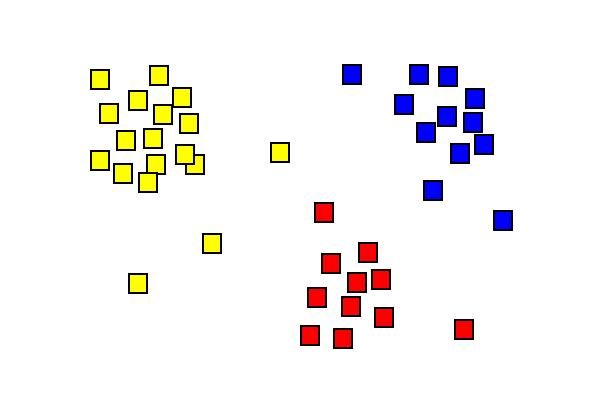
rezultatele analizei Cluster care arată trei clustere colorate diferite.
clusterele se pot baza pe factori precum:
- clustering bazat pe distanță. Elementele sunt sortate în funcție de proximitatea (sau distanța) lor. De exemplu, cazurile de cancer ar putea fi grupate împreună dacă se află în aceeași locație geografică.
- clustering Conceptual. Elementele sunt grupate după factori pe care elementele le au în comun. De exemplu, grupurile de cancer ar putea fi grupate în funcție de “persoanele care lucrează în industria prelucrătoare.”
Tipuri De Grupare
- Grupare Exclusivă. Fiecare element poate aparține numai într-un singur cluster. Nu poate aparține unui alt grup.
- clustering Fuzzy: punctelor de date li se atribuie o probabilitate de apartenență la unul sau mai multe clustere.
- Gruparea Suprapusă. Fiecare element poate aparține mai multor clustere.
- Gruparea Ierarhică. Aceasta este o abordare mai complexă a clustering utilizate în data mining. Practic, fiecărui element i se oferă propriul cluster. O pereche de clustere este unită pe baza asemănărilor, oferind un cluster mai puțin. Acest proces se repetă până când toate elementele sunt grupate. Dendrograma este un grafic care arată clustere ierarhice.
- Clustering Probabilistic. Datele sunt grupate folosind algoritmi care conectează elemente folosind distanțe sau densități. Acest lucru este de obicei efectuat de un computer.
- metoda lui Ward: folosește varianța minimă în fiecare pas pentru a crea clustere relativ mici, de dimensiuni egale.
K înseamnă Clustering
Clustering este doar o modalitate de a grupa un set de date în seturi mai mici. Cele două moduri în care puteți grupa un set de date sunt cantitativ (folosind numere) și calitativ (folosind categorii). De exemplu, cărți despre Amazon.com sunt listate atât pe categorii (calitative), cât și pe cele mai bune vânzări (cantitative). K-înseamnă clustering este unul dintre cei mai simpli algoritmi de învățare nesupravegheați care rezolvă problemele de clustering folosind o metodă cantitativă: pre-definiți un număr de clustere și folosiți un algoritm simplu pentru a sorta datele. Acestea fiind spuse,” simplu ” în lumea computerelor nu echivalează cu simplu în viața reală. Aceasta este de fapt o problemă NP-hard, astfel încât veți dori să utilizați software-ul pentru K-înseamnă clustering. Unele programe care vor efectua acest lucru pentru dvs. (faceți clic pe linkul pentru procedură) sunt:
- SPSS.
- r
- MATLAB
pașii generali din spatele algoritmului de grupare k-means sunt:
- decideți câte clustere (k).
- așezați K puncte centrale în locații diferite (de obicei departe unul de celălalt).
- luați fiecare punct de date și plasați-l aproape de punctul central corespunzător. Repetați până când toate punctele de date au fost atribuite.
- re-calcula K noi puncte centrale ca barycenters.
- repetați atribuirea punctelor de date, de data aceasta la noul punct central (baricentrul).
- repetați 4 și 5 până când punctele centrale (baricentrele) nu se mai mișcă.
K-înseamnă grupare: o definiție mai formală
o modalitate mai formală de a defini K-înseamnă grupare este de a clasifica n obiecte în K(k> 1) grupuri predefinite. Scopul este de a minimiza distanța de la fiecare punct de date la cluster. Cu alte cuvinte, pentru a găsi:
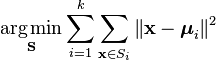
unde:
X este un punct de date
k este numărul de clustere
ui este media punctelor din Si.
analiza Cluster vs.analiza discriminantă
analiza Cluster este foarte asemănătoare cu analiza discriminantă. Ambele metode implică separarea în grupuri. Cu toate acestea, analiza cluster este o modalitate de a identifica grupurile, în timp ce analiza discriminantă necesită cunoașterea grupurilor înainte de a începe analiza. De exemplu, să presupunem că ați avut un grup de pacienți psihiatrici cu comportamente anormale. Analiza clusterului vă poate ajuta să găsiți grupuri distincte, cum ar fi pacienții cu antecedente de abuz, cei cu PTSD sau cei care suferă de halucinații. Dacă ar fi să executați analize discriminante pe același grup de persoane, trebuie să cunoașteți diagnosticul pacienților înainte de a începe să le plasați în grupuri.
Clustering în Excel
Microsoft Excel are un add-in data mining pentru a face clustere. Puteți găsi instrucțiuni aici. Expertul funcționează cu tabele Excel, intervale sau interogări de sondaj de analiză. Acest add-in poate fi personalizat, spre deosebire de instrumentul Detect Categories. În plus, instrumentul Detect Categories este limitat la datele din tabele.
pentru a utiliza:
- descărcați și instalați programul de completare Data Mining.
- Faceți clic pe “data Mining”, apoi faceți clic pe “Cluster”, apoi pe “Next”.”
- spuneți Excel unde sunt datele dvs. De exemplu, selectați o gamă de date. Pagina de clustering va deveni disponibilă.
- Clustering: lăsați ca este pentru gruparea automată, sau puteți specifica un număr de grupuri.
- segmente: lăsați ca atare pentru gruparea automată sau specificați un număr de categorii.
Stephanie Glen. “Clustering și K înseamnă: definiție & analiza clusterului în Excel” din StatisticsHowTo.com: Statistici elementare pentru restul dintre noi! https://www.statisticshowto.com/clustering/
——————————————————————————
aveți nevoie de ajutor cu o temă sau o întrebare de testare? Cu studiul Chegg, puteți obține soluții pas cu pas la întrebările dvs. de la un expert în domeniu. Primele 30 de minute cu un tutore Chegg sunt gratuite!