cocă concavă
crearea unui chenar cluster folosind o abordare k-cea mai apropiată vecini
acum câteva luni, am scris aici pe Medium un articol despre cartografierea punctelor fierbinți ale accidentelor rutiere din Marea Britanie. Am fost cea mai mare parte preocupat de ilustrarea utilizării algoritmului de clustering DBSCAN pe date geografice. În articol, am folosit informații geografice publicate de Guvernul britanic cu privire la accidentele de circulație raportate. Scopul meu a fost de a rula un proces de clustering bazat pe densitate pentru a găsi zonele în care accidentele de circulație sunt raportate cel mai frecvent. Rezultatul final a fost crearea unui set de geo-garduri reprezentând aceste puncte fierbinți ale accidentelor.
prin colectarea tuturor punctelor dintr-un cluster dat, vă puteți face o idee despre cum ar arăta cluster-ul pe o hartă, dar vă va lipsi o informație importantă: forma exterioară a clusterului. În acest caz, vorbim despre un poligon închis care poate fi reprezentat pe o hartă ca un geo-gard. Se poate presupune că orice punct din interiorul geo-gardului aparține clusterului, ceea ce face ca această formă să fie o informație interesantă: o puteți folosi ca funcție de discriminator. Se poate presupune că toate punctele nou eșantionate care se încadrează în interiorul poligonului aparțin clusterului corespunzător. Așa cum am sugerat în articol, puteți utiliza astfel de poligoane pentru a vă afirma riscul de conducere, folosindu-le pentru a vă clasifica propria locație GPS eșantionată.
întrebarea acum este cum să creați un poligon semnificativ dintr-un nor de puncte care alcătuiesc un cluster specific. Abordarea mea în primul articol a fost oarecum na și a reflectat o soluție pe care am folosit deja în codul de producție. Această soluție a presupus plasarea unui cerc centrat la fiecare dintre punctele clusterului și apoi îmbinarea tuturor cercurilor împreună pentru a forma un poligon în formă de nor. Rezultatul nu este foarte frumos, nici realist. De asemenea, prin utilizarea cercurilor ca formă de bază pentru construirea poligonului final, acestea vor avea mai multe puncte decât o formă mai raționalizată, crescând astfel costurile de stocare și făcând algoritmii de detectare a incluziunii să ruleze mai lent.

pe de altă parte, această abordare are avantajul de a fi simplă din punct de vedere computațional (cel puțin din perspectiva dezvoltatorului), deoarece folosește funcția Shapely ‘ s cascaded_union pentru a îmbina toate cercurile împreună. Un alt avantaj este că forma poligonului este definită implicit folosind toate punctele din cluster.
pentru abordări mai sofisticate, trebuie să identificăm cumva punctele de frontieră ale clusterului, cele care par să definească forma norului de puncte. Interesant, cu unele implementări DBSCAN puteți recupera de fapt punctele de frontieră ca un produs secundar al procesului de clustering. Din păcate, aceste informații nu sunt (aparent) disponibile în implementarea SciKit Learn, așa că trebuie să ne descurcăm.
prima abordare care mi-a venit în minte a fost calcularea corpului convex al setului de puncte. Acesta este un algoritm bine înțeles, dar suferă de problema de a nu manipula forme concave, ca acesta:

această formă nu surprinde corect esența punctelor subiacente. Dacă ar fi folosit ca discriminator, unele puncte ar fi clasificate incorect ca fiind în interiorul clusterului atunci când nu sunt. Avem nevoie de o altă abordare.
alternativa Coca concavă
din fericire, există alternative la această stare de lucruri: putem calcula o coca concavă. Iată cum arată corpul concav atunci când este aplicat aceluiași set de puncte ca în imaginea anterioară:

sau poate asta:
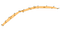
după cum puteți vedea, și contrar carenei convexe, nu există o singură definiție a ceea ce este carena concavă a unui set de puncte. Cu algoritmul pe care îl prezint aici, alegerea cât de concavă doriți să fie corpurile dvs. se face printr — un singur parametru: k-numărul celor mai apropiați vecini luați în considerare în timpul calculului corpului. Să vedem cum funcționează.
algoritmul
algoritmul pe care îl prezint aici a fost descris acum un deceniu de Adriano Moreira și Maribel Yasmina Santos de la Universitatea din Minho, Portugalia . Din abstract:
această lucrare descrie un algoritm pentru a calcula plicul unui set de puncte într-un plan, care generează convexe pe corpuri neconvexe care reprezintă zona ocupată de punctele date. Algoritmul propus se bazează pe o abordare k-cea mai apropiată vecini, unde valoarea lui k, singurul parametru algoritm, este utilizată pentru a controla “netezimea” soluției finale.
deoarece voi aplica acest algoritm informațiilor geografice, au trebuit făcute unele modificări, și anume la calcularea unghiurilor și distanțelor . Dar acestea nu modifică în nici un fel esența algoritmului, care poate fi descris pe larg prin următorii pași:
- găsiți punctul cu cea mai mică coordonată y (latitudine) și faceți-l cel curent.
- găsiți k-cele mai apropiate puncte de punctul curent.
- din cele mai apropiate puncte k, selectați cel care corespunde celui mai mare viraj din dreapta din unghiul anterior. Aici vom folosi conceptul de rulment și vom începe cu un unghi de 270 de grade (spre vest).
- verificați dacă prin adăugarea noului punct la șirul de linie în creștere, acesta nu se intersectează. Dacă Da, selectați un alt punct din k-cel mai apropiat sau reporniți cu o valoare mai mare de k.
- faceți din noul punct punctul curent și eliminați-l din listă.
- după iterații k adăugați primul punct înapoi la listă.
- buclă la numărul 2.
algoritmul pare a fi destul de simplu, dar există o serie de detalii la care trebuie să fim atenți, mai ales că avem de-a face cu Coordonate geografice. Distanțele și unghiurile sunt măsurate într-un mod diferit.
Codul
here I am publishing este o versiune adaptată a codului articolului anterior. Veți găsi în continuare același cod de grupare și același generator de cluster în formă de nor. Versiunea actualizată conține acum un pachet numit geomath.hulls unde puteți găsi clasa ConcaveHull. Pentru a vă crea corpurile concave, procedați după cum urmează:
în codul de mai sus, points este o serie de dimensiuni (n, 2), Unde rândurile conțin punctele observate, iar coloanele conțin coordonatele geografice (longitudine, latitudine). Matricea rezultată are exact aceeași structură, dar conține doar punctele care aparțin formei poligonale a clusterului. Un fel de filtru.
pentru că vom fi de manipulare matrice este firesc să aducă NumPy în luptă. Toate calculele au fost vectorizate în mod corespunzător, ori de câte ori a fost posibil, și s-au făcut eforturi pentru a îmbunătăți performanța la adăugarea și eliminarea elementelor din matrice (spoiler: acestea nu sunt mutate deloc). Una dintre îmbunătățirile lipsă este paralelizarea codului. Dar asta poate aștepta.
am organizat codul în jurul algoritmului așa cum este expus în lucrare, deși unele optimizări au fost făcute în timpul traducerii. Algoritmul este construit în jurul unui număr de subrutine care sunt clar identificate de hârtie, așa că haideți să le scoatem din drum chiar acum. Pentru confortul dvs. de lectură, voi folosi aceleași nume ca cele folosite în lucrare.
după cum puteți vedea, lista de puncte este implementată ca o matrice NumPy din motive de performanță. Curățarea listei se efectuează pe linia 10, unde sunt păstrate doar punctele unice. Matricea setului de date este organizată cu observații în rânduri și Coordonate geografice în cele două coloane. Rețineți că, de asemenea, creez o matrice booleană pe linia 13 care va fi utilizată pentru a indexa în matricea principală a setului de date, ușurând sarcina de a elimina elementele și, din când în când, adăugându-le înapoi. Am văzut această tehnică numită “mască” pe documentația NumPy și este foarte puternică. În ceea ce privește numerele prime, le voi discuta mai târziu.
FindMinYPoint-aceasta necesită o funcție mică:
această funcție este apelată cu matricea setului de date ca argument și returnează indexul punctului cu cea mai mică latitudine. Rețineți că rândurile sunt codificate cu longitudine în prima coloană și latitudine în a doua.
RemovePoint
AddPoint — acestea sunt no-brainers, datorită utilizării matricei indices. Această matrice este utilizată pentru a stoca indicii activi în matricea principală a setului de date, astfel încât eliminarea elementelor din setul de date este o clipă.
deși algoritmul descris în lucrare solicită adăugarea unui punct la matricea care alcătuiește corpul, acesta este de fapt implementat ca:
mai târziu, variabila test_hull va fi atribuită înapoi la hull când șirul de linie este considerat ca ne-intersectat. Dar eu sunt obtinerea înainte de joc aici. Eliminarea unui punct din matricea setului de date este la fel de simplă ca:
self.indices = False
adăugarea-l înapoi este doar o chestiune de flipping că valoarea matrice la același index înapoi la adevărat. Dar toată această comoditate vine cu prețul de a trebui să ne păstrăm filele pe indici. Mai multe despre asta mai târziu.
NearestPoints-lucrurile încep să devină interesante aici, deoarece nu avem de-a face cu coordonate plane, deci cu Pitagora și cu Haversine:
rețineți că al doilea și al treilea parametri sunt matrice în formatul setului de date: longitudine în prima coloană și latitudine în a doua. După cum puteți vedea, această funcție returnează o serie de distanțe în metri între punctul din al doilea argument și punctele din al treilea argument. Odată ce avem aceste, putem obține k-cel mai apropiat vecinii calea ușoară. Dar există o funcție specializată pentru asta și merită câteva explicații:
funcția începe prin crearea unei matrice cu indicii de bază. Acestea sunt indicii punctelor care nu au fost eliminate din matricea setului de date. De exemplu, dacă pe un cluster de zece puncte am început prin eliminarea primului punct, matricea indicilor de bază ar fi . Apoi, calculăm distanțele și sortăm indicii matricei rezultate. Primele k sunt extrase și apoi utilizate ca mască pentru a prelua indicii de bază. Este un fel de contorsionat, dar funcționează. După cum puteți vedea, funcția nu returnează o serie de coordonate, ci o serie de indici în matricea setului de date.
SortByAngle — există mai multe probleme aici pentru că nu calculăm unghiuri simple, calculăm rulmenți. Acestea sunt măsurate ca zero grade spre nord, cu unghiuri crescând în sensul acelor de ceasornic. Iată nucleul codului care calculează rulmenții:
funcția returnează o serie de rulmenți măsurați de la punctul al cărui indice se află în primul argument, la punctele ale căror indici se află în al treilea argument. Sortarea este simplă:
în acest moment, matricea candidaților conține indicii celor mai apropiate puncte k sortate după ordinea descrescătoare a rulmentului.
IntersectQ — în loc să-mi rulez propriile funcții de intersecție a liniei, am apelat la Shapely pentru ajutor. De fapt, în timp ce construim poligonul, gestionăm în esență un șir de linii, adăugând segmente care nu se intersectează cu cele anterioare. Testarea pentru acest lucru este simplu: vom ridica matrice Coca în construcție, converti la un obiect șir de linie bine proporționat, și testa dacă este simplu (non auto-intersectează) sau nu.
pe scurt, un șir de linii bine proporționat devine complex dacă se auto-încrucișează, astfel încât predicatul is_simple devine fals. Ușor.
PointInPolygon — acest lucru sa dovedit a fi cel mai dificil de implementat. Permiteți-mi să explic uitându-mă la codul care efectuează validarea finală a poligonului hull (verifică dacă toate punctele clusterului sunt incluse în poligon):
funcțiile Shapely de a testa intersecția și incluziunea ar fi trebuit să fie suficiente pentru a verifica dacă poligonul final al corpului se suprapune peste toate punctele clusterului, dar nu au fost. De ce? Shapely este coordonată-agnostic, deci se va ocupa de coordonatele geografice exprimate în latitudini și longitudini Exact la fel ca coordonatele pe un plan cartezian. Dar lumea se comportă diferit atunci când trăiești pe o sferă, iar unghiurile (sau rulmenții) nu sunt constante de-a lungul unui geodezic. Exemplul de referință al unei linii geodezice care leagă Bagdadul de Osaka ilustrează perfect acest lucru. Se întâmplă ca, în anumite circumstanțe, algoritmul să poată include un punct bazat pe criteriul rulmentului, dar mai târziu, folosind algoritmii planari ai lui Shapely, să fie considerat atât de ușor în afara poligonului. Asta face corecția distanței mici acolo.
mi-a luat ceva timp să-mi dau seama de asta. Ajutorul meu de depanare a fost QGIS, o mare bucată de software liber. La fiecare pas al calculelor suspecte, aș scoate datele în format WKT într-un fișier CSV pentru a fi citite ca strat. Un adevărat salvator!
în cele din urmă, dacă poligonul nu reușește să acopere toate punctele clusterului, singura opțiune este să măriți k și să încercați din nou. Aici am adăugat un pic din propria mea intuiție.
prim k
articolul sugerează că valoarea lui k să fie mărită cu una și că algoritmul este executat din nou de la zero. Testele mele timpurii cu această opțiune nu au fost foarte satisfăcătoare: timpul de rulare ar fi lent pe clusterele problematice. Acest lucru s-a datorat creșterii lente a k, așa că am decis să folosesc un alt program de creștere: un tabel cu numere prime. Algoritmul începe deja cu k = 3, deci a fost o extensie ușoară pentru a-l face să evolueze pe o listă de numere prime. Aceasta este ceea ce vedeți întâmplându-se în apelul recursiv:
am un lucru pentru numere prime, știi…
arunce în aer
poligoane Coca concavă generate de acest algoritm încă mai au nevoie de unele de prelucrare în continuare, pentru că ei vor discrimina doar puncte în interiorul corpului navei, dar nu aproape de ea. Soluția este să adăugați niște căptușeli la aceste clustere slabe. Aici folosesc exact aceeași tehnică ca cea folosită înainte și iată cum arată:

aici, am folosit Shapely buffer funcția de a face truc.
funcția acceptă un poligon bine proporționat și returnează o versiune umflată a sa. Al doilea parametru este raza în metri a căptușelii adăugate.
rularea codului
începeți trăgând codul din depozitul GitHub în mașina dvs. locală. Fișierul pe care doriți să îl executați este ShowHotSpots.py în directorul principal. La prima execuție, codul va citi în datele privind accidentele rutiere din Marea Britanie din 2013 până în 2016 și le va grupa. Rezultatele sunt apoi memorate în cache ca fișier CSV pentru rulările ulterioare.
vi se vor prezenta apoi două hărți: prima este generată folosind clusterele în formă de nor, în timp ce a doua folosește algoritmul concav de grupare discutat aici. În timp ce se execută codul de generare a poligonului, este posibil să vedeți că sunt raportate câteva defecțiuni. Pentru a înțelege de ce algoritmul nu reușește să creeze o carenă concavă, codul scrie clusterele în fișiere CSV în directorul data/out/failed/. Ca de obicei, puteți utiliza QGIS pentru a importa aceste fișiere ca straturi tematice.
în esență, acest algoritm eșuează atunci când nu găsește suficiente puncte pentru a “ocoli” forma fără a se intersecta. Aceasta înseamnă că trebuie să fiți gata fie să aruncați aceste clustere, fie să le aplicați un tratament diferit (cocă convexă sau bule coagulate).
Concaveness
este o folie. În acest articol am prezentat o metodă de post-procesare a clusterelor geografice dbscan generate în forme concave. Această metodă poate oferi un poligon exterior mai potrivit pentru clustere în comparație cu alte alternative.
Vă mulțumim pentru lectură și bucurați-vă de tinkering cu codul!
Kryszkiewicz M., Lasek P. (2010) TI-DBSCAN: gruparea cu DBSCAN prin intermediul inegalității triunghiului. În: Szczuka M., Kryszkiewicz M., Ramanna S., Jensen R., Hu Q. (eds) seturi brute și tendințele actuale în calcul. RSCTC 2010. Note de curs în informatică, vol. 6086. Springer, Berlin, Heidelberg
Scikit-aflați: învățarea automată în Python, Pedregosa și colab., JMLR 12, pp. 2825-2830, 2011
Moreira, A. și Santos, M. Y., 2007, Coca concavă: o abordare a vecinilor k-cea mai apropiată pentru calculul regiunii ocupate de un set de puncte
calculați distanța, rulmentul și multe altele între punctele de latitudine / longitudine
depozit GitHub