evoluția sistemului de planificare a clusterelor
Kubernetes a devenit standardul de facto în domeniul orchestrării containerelor. Toate aplicațiile vor fi dezvoltate și rulate pe Kubernetes în viitor. Scopul acestei serii de articole este de a introduce principiile de implementare care stau la baza Kubernetes într-un mod profund și simplu.
Kubernetes este un sistem de planificare cluster. Acest articol introduce în principal o arhitectură anterioară a sistemului de planificare a clusterului Kubernetes. Analizând ideile lor de proiectare și caracteristicile arhitecturii, putem studia procesul de evoluție al arhitecturii Sistemului de planificare a clusterului și principala problemă care trebuie luată în considerare în proiectarea arhitecturii. Acest lucru va fi foarte util în înțelegerea arhitecturii Kubernetes.
trebuie să înțelegem unele dintre conceptele de bază ale sistemului de programare cluster, în scopul de a face clar, voi explica conceptul printr-un exemplu, să presupunem că vrem să pună în aplicare un cron distribuit. Sistemul gestionează un set de gazde Linux. Utilizatorul definește lucrarea prin API-ul furnizat de sistem. sistemul va efectua periodic sarcina corespunzătoare pe baza definiției sarcinii, în acest exemplu, conceptele de bază sunt mai jos:
- Cluster: gazdele Linux gestionate de acest sistem formează un bazin de resurse pentru a rula sarcini. Acest grup de resurse se numește Cluster.
- Job: definește modul în care clusterul își îndeplinește sarcinile. În acest exemplu, Crontab este exact o lucrare simplă care arată clar ce trebuie să facă (script de execuție) la ce oră(interval de timp).Definiția unor locuri de muncă sunt mai complexe, cum ar fi definirea unui loc de muncă pentru a fi finalizate în mai multe sarcini, și dependențele dintre sarcini, precum și cerințele de resurse ale fiecărei sarcini.
- Task: un job trebuie să fie programat în anumite taskuri de performanță. Dacă definim un loc de muncă pentru a efectua un script la 1am în fiecare noapte, atunci procesul de script efectuat la 1am în fiecare zi este o sarcină.
la proiectarea sistemului de planificare cluster, sarcinile de bază ale sistemului sunt două:
- programarea sarcinilor: După ce joburile sunt trimise la sistemul de planificare cluster, joburile trimise trebuie împărțite în sarcini de execuție specifice, iar rezultatele de execuție ale taskurilor trebuie urmărite și monitorizate. În exemplul cron distribuit, sistemul de planificare trebuie să înceapă în timp util procesul în conformitate cu cerințele operației. Dacă procesul nu reușește să efectueze, reîncercarea este necesară etc. Unele scenarii complexe, cum ar fi Hadoop harta Reduce, sistemul de planificare trebuie să împartă harta Reduce sarcina în harta multiple corespunzătoare și de a Reduce sarcinile, și în cele din urmă a obține datele rezultat de execuție sarcină.
- resource scheduling: este folosit în esență pentru a se potrivi taskurilor și resurselor, iar resursele adecvate sunt alocate pentru a rula taskuri în funcție de utilizarea resurselor gazdelor din cluster. Este similar cu procesul de programare a algoritmului sistemului de operare, scopul principal al programării resurselor este de a îmbunătăți utilizarea resurselor pe cât posibil și de a reduce timpul de așteptare pentru sarcini în condițiile furnizării fixe de resurse și de a reduce întârzierea sarcinii sau a timpului de răspuns (dacă este o sarcină batch, se referă la timpul de la început până la sfârșit al operațiunilor de sarcini, dacă este vorba de sarcini de tip Răspuns online, cum ar fi aplicațiile Web, care se referă la fiecare timp de răspuns la cerere), prioritatea sarcinii trebuie luată în considerare, fiind în același timp cât mai echitabilă posibil (resursele sunt alocate în mod echitabil tuturor sarcinilor). Unele dintre aceste obiective sunt contradictorii și trebuie să fie echilibrate, cum ar fi utilizarea resurselor, timpul de răspuns, corectitudinea și prioritățile.
Hadoop MRv1
harta Reduce este un fel de model de calcul paralel. Hadoop poate rula acest tip de platformă de gestionare a clusterului de calcul paralel. MRv1 este prima versiune de generație a Map Reduce motor de planificare sarcină a platformei Hadoop. Pe scurt, MRv1 este responsabil pentru programarea și executarea de locuri de muncă pe cluster, și a reveni la rezultatele de calcul atunci când un utilizator definește o hartă reduce calcul și trimiteți-l la Hadoop. Iată cum arată arhitectura MRv1:
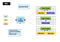
arhitectura este relativ simplă, arhitectura standard Master/Slave are două componente de bază:
- Job Tracker este componenta principală de gestionare a clusterului, care este responsabilă atât pentru programarea resurselor, cât și pentru programarea sarcinilor.
- Task Tracker rulează pe fiecare mașină din cluster, care este responsabil pentru rularea sarcinilor specifice pe gazdă și starea de raportare.
odată cu popularitatea Hadoop și creșterea diferitelor cereri, MRv1 are următoarele probleme care trebuie îmbunătățite:
- performanța are un anumit blocaj: numărul maxim de noduri care acceptă gestionarea este de 5.000, iar numărul maxim de sarcini de operare de susținere este de 40.000. Mai este loc pentru îmbunătățiri.
- nu este suficient de flexibil pentru a extinde sau sprijini alte tipuri de sarcini. În plus față de sarcinile de tip reducere a hărții, există multe alte tipuri de sarcini în ecosistemul Hadoop care trebuie programate, cum ar fi Spark, Hive, HBase, Storm, Oozie etc. Prin urmare, este nevoie de un sistem de planificare mai general, care poate sprijini și extinde mai multe tipuri de sarcini
- utilizarea redusă a resurselor: MRv1 configurează static un număr fix de sloturi pentru fiecare nod, și fiecare slot poate fi utilizat numai pentru tipul de sarcină specifică (hartă sau Reduce), ceea ce duce la problema utilizării resurselor. De exemplu, un număr mare de sarcini de hartă sunt în așteptare pentru resurse inactive, dar, de fapt, un număr mare de sloturi de reducere sunt inactive pentru mașini.
- probleme multi-închiriere și multi-versiune. De exemplu, diferite departamente execută sarcini în același cluster, dar sunt izolate logic unele de altele sau rulează versiuni diferite ale Hadoop în același cluster.
fire
fire(încă un alt negociator de resurse) este o a doua generație de Hadoop ,scopul principal este de a rezolva toate tipurile de probleme în MRv1. Arhitectura firelor arată astfel:

simpla înțelegere a firelor este că principala îmbunătățire față de MRv1 este împărțirea responsabilităților JobTrack-ului original în două componente diferite: Manager de resurse și master de aplicații
- Manager de resurse: Este responsabil pentru programarea resurselor, gestionează toate resursele, atribuie resurse diferitelor tipuri de sarcini și extinde cu ușurință algoritmul de planificare a resurselor printr-o arhitectură conectabilă.
- Application Master: este responsabil pentru programarea sarcinilor. Fiecare lucrare (numită aplicație în fire) pornește un Master de aplicație corespunzător, care este responsabil pentru împărțirea lucrării în sarcini specifice și aplicarea resurselor de la Resource Manager, pornirea sarcinii, urmărirea stării sarcinii și raportarea rezultatelor.
să aruncăm o privire la modul în care această schimbare de arhitectură a rezolvat diferitele probleme ale MRv1:
- împărțiți responsabilitățile inițiale de planificare a sarcinilor de Job Tracker și rezultând îmbunătățiri semnificative ale performanței. Responsabilitățile de planificare a sarcinilor ale Tracker-ului inițial de locuri de muncă au fost împărțite pentru a fi întreprinse de Maestrul aplicației,iar maestrul aplicației a fost distribuit, fiecare instanță a gestionat doar cererea unui singur loc de muncă, astfel a promovat numărul maxim de noduri de cluster de la 5.000 la 10.000.
- componentele task scheduling, Application Master și resource scheduling sunt decuplate și create dinamic pe baza solicitărilor de joburi. O instanță Master aplicație este responsabil pentru un singur loc de muncă de programare, ceea ce face mai ușor pentru a sprijini diferite tipuri de locuri de muncă.
- este introdusă tehnologia de izolare a containerelor, fiecare sarcină este rulată într-un container izolat, ceea ce îmbunătățește foarte mult utilizarea resurselor în funcție de cererea sarcinii de resurse care pot fi alocate dinamic. Dezavantajul acestui lucru este gestionarea resurselor și alocarea firelor au o singură dimensiune a memoriei.
Mesos architecture
scopul de proiectare al fire este încă de a servi programarea ecosistemului Hadoop. Scopul Mesos se apropie, este conceput pentru a fi un sistem general de planificare, care poate gestiona funcționarea întregului centru de date. După cum vedem, designul arhitectural al Mesos a folosit o mulțime de fire pentru referință, programarea locurilor de muncă și programarea resurselor sunt suportate de diferitele module separat. Dar cea mai mare diferență între Mesos și fire este modul de planificare a resurselor, un mecanism unic numit oferta de resurse este proiectat. Presiunea programării resurselor este eliberată în continuare, iar scalabilitatea programării lucrărilor este crescută.

principalele componente ale Mesos sunt:
- Mesos Master: este o componentă responsabilă exclusiv pentru alocarea resurselor și componentele managementului, care este managerul de resurse corespunzător firului interior. Dar modul de funcționare este ușor diferit dacă va fi discutat mai târziu.
- Framework: este responsabil pentru programarea joburilor, diferite tipuri de joburi vor avea un Framework corespunzător, cum ar fi Spark Framework care este responsabil pentru joburile Spark.
oferta de Resurse a Mesos
poate părea că arhitecturile Mesos și fire sunt destul de similare, dar, de fapt, la aspectul gestionării resurselor, Maestrul Mesos are un mecanism de ofertă de resurse foarte unic (și oarecum bizar) :
- fire este trage: Resursele furnizate de Resource Manager în fire sunt pasive,atunci când consumatorii de resurse (application Master) au nevoie de resurse, pot apela interfața Resource Manager pentru a obține resurse, iar Resource Manager răspunde pasiv doar nevoilor application Master.
- Mesos este Push: resursele furnizate de Maestrul Mesos sunt proactive. Maestrul Mesos va lua în mod regulat inițiativa de a împinge toate resursele disponibile actuale (așa-numitele oferte de Resurse, o voi numi ofertă de acum înainte) la cadru. Dacă există sarcini pe care cadrul trebuie să le îndeplinească, acesta nu poate solicita în mod activ resurse, cu excepția cazului în care ofertele sunt primite. Cadru Selectează o resursă calificată din oferta de a accepta (această mișcare se numește accepta în Mesos,) și respinge ofertele rămase (această mișcare se numește respinge). Dacă nu există suficiente resurse calificate în această rundă de ofertă, trebuie să așteptăm următoarea rundă de Master pentru a oferi oferta.
cred că atunci când veți vedea acest mecanism de ofertă activă, veți avea același sentiment cu mine. Adică, eficiența este relativ scăzută și vor apărea următoarele probleme:
- eficiența decizională a oricărui cadru afectează eficiența generală. Pentru consecvență, Master poate oferi doar o ofertă unui cadru la un moment dat și poate aștepta ca Cadrul să selecteze Oferta înainte de a oferi restul cadrului următor. În acest fel, eficiența decizională a oricărui cadru va afecta eficiența generală.
- “pierdem” mult timp pe cadre care nu necesită resurse. Mesos nu știe cu adevărat ce cadru are nevoie de resurse. Deci, nu va fi cadru cu cerințele de resurse este de așteptare pentru oferta, dar Cadrul fără cerințe de resurse primește oferta frecvent.
ca răspuns la problemele de mai sus, Mesos a oferit unele mecanisme pentru a atenua problemele, cum ar fi stabilirea unui interval de timp pentru ca Cadrul să ia decizii sau să permită cadrului să respingă ofertele prin setarea acestuia pentru a fi suprimat. Deoarece nu este punctul central al acestei discuții, detaliile sunt neglijate aici.
de fapt, există câteva avantaje evidente pentru Mesos folosind acest mecanism de ofertă activă:
- performanța este în mod evident îmbunătățită. Un cluster poate suporta până la 100.000 de noduri conform testării de simulare, pentru mediul de producție Twitter, cel mai mare cluster poate suporta 80.000 de noduri. principalul motiv este că oferta activă a Mesos Master mechanism simplifică și mai mult responsabilitățile Mesos. procesul de planificare a resurselor, potrivirea resurselor la sarcini, în Mesos este împărțit în două etape: resurse de oferit și ofertă pentru sarcini. Maestrul Mesos este responsabil doar pentru finalizarea primei faze, iar potrivirea celei de-a doua faze este lăsată cadrului.
- mai flexibil și capabil să îndeplinească politici mai responsabile de planificare a sarcinilor. De exemplu, strategia de utilizare a resurselor pentru toate sau nimic.
algoritmul de programare al Mesos DRF (corectitudinea dominantă a resurselor)
în ceea ce privește algoritmul DRF, de fapt nu are nimic de-a face cu înțelegerea noastră despre arhitectura Mesos, dar este foarte importantă și importantă în Mesos, așa că voi explica un pic mai mult aici.
după cum sa menționat mai sus, Mesos oferă oferta cadrului la rândul său, deci care Cadru ar trebui selectat pentru a oferi oferta de fiecare dată? Aceasta este problema de bază care trebuie rezolvată prin algoritmul DRF. Principiul de bază este de a lua în considerare atât corectitudinea, cât și eficiența. În timp ce satisface toate cerințele de resurse ale cadrului, ar trebui să fie cât mai corect posibil pentru a evita un cadru consuma prea multe resurse și foame alte cadre la moarte.
DRF este o variantă a algoritmului de corectitudine min-max. În termeni simpli, este de a selecta cadrul cu cea mai mică utilizare a resurselor dominante pentru a oferi oferta de fiecare dată. Cum se calculează utilizarea dominantă a resurselor cadrului? Din toate tipurile de resurse ocupate de cadru, Tipul de resursă cu cea mai mică rată de ocupare a resurselor este selectat ca resursă dominantă. Rata sa de ocupare a resurselor este exact utilizarea dominantă a resurselor cadrului. De exemplu, un procesor de cadru ocupă 20% din resursa totală, 30% din memorie și 10% din disc. Deci, utilizarea dominantă a resurselor cadrului va fi de 10%, termenul oficial numește un disc ca resursă dominantă, iar acest 10% se numește utilizare dominantă a resurselor.
scopul final al DRF este de a distribui resursele în mod egal între toate cadrele. Dacă un Framework X acceptă prea multe resurse în această rundă de ofertă, atunci va dura mult mai mult pentru a obține oportunitatea următoarei runde de ofertă. Cu toate acestea, cititorii atenți vor descoperi că există o ipoteză în acest algoritm, adică după ce cadrul acceptă resurse, le va elibera rapid, altfel vor exista două consecințe:
- alte cadre mor de foame. Un cadru a acceptă majoritatea resurselor din cluster la un moment dat, iar sarcina continuă să ruleze fără a renunța, astfel încât majoritatea resurselor sunt ocupate de Cadrul a tot timpul, iar alte cadre nu vor mai primi resursele.
- înfometați-vă până la moarte. Deoarece utilizarea dominantă a resurselor acestui cadru este întotdeauna foarte mare, deci nu există nicio șansă de a primi ofertă mult timp, astfel încât nu pot fi rulate mai multe sarcini.
deci Mesos este potrivit doar pentru programarea sarcinilor scurte, iar Mesos au fost inițial concepute pentru sarcini scurte ale centrelor de date.
sumarizare
din arhitectura mare, toate arhitectura sistemului de planificare este arhitectura Master/Slave, Slave end este instalat pe fiecare mașină cu cerința de management, care este folosit pentru a colecta informații gazdă, și de a efectua sarcini pe gazdă. Master este în principal responsabil pentru programarea resurselor și programarea sarcinilor. Programarea resurselor are cerințe mai mari privind performanța și programarea sarcinilor are cerințe mai mari privind scalabilitatea. Tendința generală este de a discuta cele două tipuri de taxe decupla și să le completeze prin diferite componente.
