indexare secundară scalabilă, distribuită în Scylla

modelul de date din Scylla și Apache Cassandra partiționează date între nodurile clusterului folosind o cheie de partiție, care este definită de schema bazei de date. Utilizarea unei chei de partiție oferă o modalitate eficientă de a căuta rânduri folosind cheia de partiție, deoarece puteți găsi nodul care deține rândul prin hashing-ul cheii de partiție. Din păcate, acest lucru înseamnă, de asemenea, că găsirea unui rând folosind o cheie non-partiție necesită o Scanare completă a tabelului, care este ineficientă. Indexurile secundare sunt un mecanism în Apache Cassandra care permite căutări eficiente pe chei non-partiție prin crearea unui index.
în această postare pe blog veți învăța:
- cum Apache Cassandra implementează indici secundari folosind indexarea locală
- de ce am decis să luăm o strategie de implementare diferită pentru Scylla folosind indexarea globală
- cum afectează indexarea globală modul în care ar trebui să utilizați indexarea secundară
- cum să creați propriile indici secundari și să le utilizați în cererea dvs. interogări CQL
fundal
dimensiunea unui index este proporțională cu dimensiunea datelor indexate. Deoarece datele din Scylla și Apache Cassandra sunt distribuite la mai multe noduri, este imposibil să stocați întregul index pe un singur nod. Apache Cassandra implementează indici secundari ca indici locali, ceea ce înseamnă că indexul este stocat pe același nod ca și datele care sunt indexate din acel nod. Beneficiul unui index local este că scrierile sunt foarte rapide, dar dezavantajul este că citirile trebuie să interogheze fiecare nod pentru a găsi indexul pentru a efectua o căutare, ceea ce face ca indexurile locale să nu poată fi evaluate pentru clustere mari. În plus față de indicii secundari nativi, Apache Cassandra are și o altă schemă locală de indexare, Sstable Attached Secondary Index (sasi), care acceptă interogări și căutări complexe. Cu toate acestea, din punct de vedere al scalabilității, are exact aceleași caracteristici ca și indicii secundari originali.
vizualizările materializate în Scylla și Apache Cassandra sunt un mecanism de denormalizare automată a datelor dintr-un tabel de bază într-un tabel de vizualizare folosind o cheie de partiție diferită. Aceasta rezolvă problema scalabilității indexurilor locale, dar are un cost de stocare, deoarece trebuie să duplicați întregul tabel în cel mai rău caz. Prin urmare, vizualizările materializate nu înlocuiesc indicii secundari pentru toate cazurile de utilizare. Cu toate acestea, vizualizările materializate oferă infrastructura necesară pentru implementarea indexurilor secundare folosind indexarea globală, care este abordarea de implementare adoptată pentru Scylla.
indexare globală
Scylla adoptă o abordare diferită de Apache Cassandra și implementează indexuri secundare folosind indexarea globală. Cu indexarea globală, se creează o vizualizare materializată pentru fiecare index. Vizualizarea materializată are coloana indexată ca cheie de partiție și cheie primară (cheie de partiție și Chei de grupare) a rândului indexat ca chei de grupare. Scylla împarte interogările indexate în două părți: (1) o interogare din tabelul index pentru a prelua cheile de partiție pentru tabelul indexat și (2) o interogare în tabelul indexat folosind tastele de partiție preluate. Beneficiul acestei abordări este că putem folosi valoarea coloanei indexate pentru a găsi rândul tabelului index corespunzător din cluster, astfel încât citirile să fie scalabile. Dezavantajul abordării este că scrierile sunt mai lente decât în cazul indexării locale, din cauza tuturor cheltuielilor generale de la menținerea actualizării vizualizării indexului.
interogarea pe o coloană indexată arată după cum urmează. Să presupunem un tabel care arată astfel:
și o interogare pe coloana email, care nu este o cheie de partiție, dar are un index:
în faza (1), interogarea ajunge pe nodul 7, care acționează ca un coordonator pentru interogare. Nodul observă că interogăm pe o coloană indexată și, prin urmare, în faza (2), emite o citire în tabelul index pe nodul 2, care are rândul tabelului index pentru “”. Interogarea returnează un set de ID-uri de utilizator care sunt utilizate în faza (3) pentru a prelua conținutul tabelului indexat.
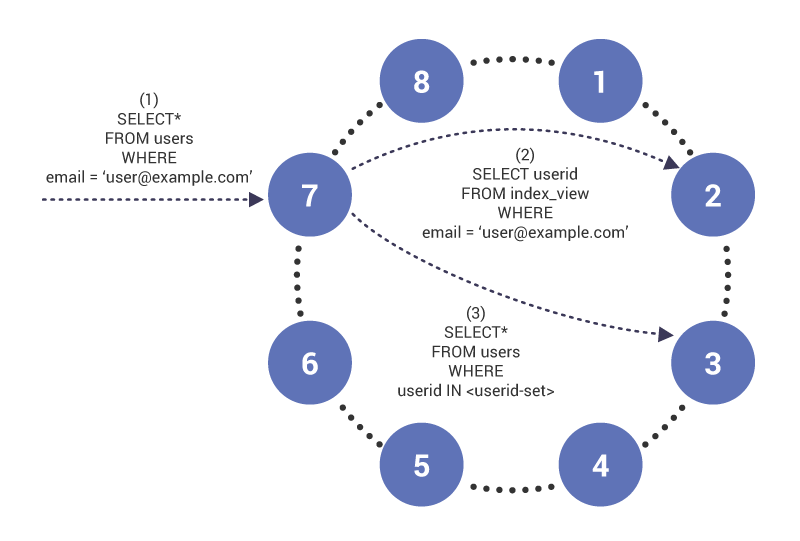
exemplu
mai întâi trebuie să creăm o schemă. În acest exemplu, avem un tabel care reprezintă informațiile utilizatorului cu ID-ul utilizatorului ca cheie de partiție și Nume, e-mail și țară ca coloane obișnuite:
apoi populăm tabelul cu unele date de testare generate cu Mockaroo:
indici secundari sunt concepute pentru a permite interogarea eficientă a coloanelor cheie non-partiție. În timp ce Apache Cassandra acceptă, de asemenea, interogări pe coloane cheie non-partiție folosind ALLOW FILTERING, este foarte ineficient (care necesită scanarea întregului tabel) și în prezent nu este acceptat de Scylla (consultați numărul 2200 pentru detalii).
puteți indexa coloanele tabelului utilizând instrucțiunea creare INDEX. De exemplu, pentru a crea indexuri pentru coloanele de e-mail și țară, executați următoarele instrucțiuni CQL:
Scylla creează automat o vizualizare materializată care are coloana indexată ca cheie de partiție și cheie primară a tabelului țintă (cheie de partiție și taste de grupare) ca taste de grupare.
de exemplu, vizualizarea materializată pentru indexul de pe coloana email arată după cum urmează:
dacă vizualizarea de mai sus ar fi creată ca un tabel obișnuit, ar arăta efectiv după cum urmează:
coloana email este utilizată ca cheie de partiție pentru tabelul index și userid este inclusă ca cheie de grupare, ceea ce ne permite să găsim eficient cheile de partiție pentru tabelul țintă folosind doar email.
puteți utiliza comanda DESCRIBE pentru a vedea întreaga schemă pentru tabelul ks.users, inclusiv indexurile și vizualizările create:
acum, cu indexul secundar în loc, puteți interoga coloanele indexate ca și cum ar fi chei de partiție:
am terminat cu exemplul!
când se utilizează indicii secundari?
indicii secundari sunt (în mare parte) transparenți pentru aplicație. Interogările au acces la toate coloanele din tabel și puteți adăuga și elimina indexurile fără a schimba aplicația. Indexurile secundare pot avea, de asemenea, mai puține cheltuieli de stocare decât vizualizările materializate, deoarece indexurile secundare trebuie doar să dubleze coloana indexată și cheia primară, nu coloanele interogate ca în cazul unei vizualizări materializate. Mai mult, din același motiv, actualizările pot fi mai eficiente cu indexurile secundare, deoarece numai modificările aduse cheii primare și coloanei indexate determină o actualizare în vizualizarea index. În cazul unei vizualizări materializate, o actualizare la oricare dintre coloanele care apar în vizualizare necesită actualizarea vizualizării de rezervă.
ca întotdeauna, decizia de a utiliza indici secundari sau vizualizări materializate depinde într-adevăr de cerințele aplicației dvs. Dacă aveți nevoie de performanță maximă și este posibil să interogați un anumit set de coloane, ar trebui să utilizați Vizualizări materializate. Cu toate acestea, dacă aplicația trebuie să interogheze diferite seturi de coloane, indicii secundari sunt o alegere mai bună, deoarece pot fi adăugați și eliminați cu mai puțin spațiu de stocare, în funcție de nevoile aplicației.
doriți să aflați mai multe despre indicii secundari? Check out prezentarea mea de la Summit-ul Scylla 2017 pe SlideShare. Dacă doriți să încercați această caracteristică, este de așteptat să fie în viitoarea versiune Scylla 2.2.