sincronizarea timpului în sisteme distribuite
dacă vă aflați familiarizat cu site-uri web, cum ar fi facebook.com sau google.com, poate nu mai puțin de o dată v-ați întrebat cum aceste site-uri pot gestiona milioane sau chiar zeci de milioane de cereri pe secundă. Va exista un singur server comercial care să reziste la această cantitate imensă de solicitări, în modul în care fiecare cerere poate fi servită în timp util pentru utilizatorii finali?
scufundând mai adânc în această chestiune, ajungem la conceptul de sisteme distribuite, o colecție de computere independente (sau noduri) care apar utilizatorilor săi ca un singur sistem coerent. Această noțiune de coerență pentru utilizatori este clară, deoarece ei cred că au de-a face cu o singură mașină humongous care ia forma mai multor procese care rulează în paralel pentru a gestiona loturi de cereri simultan. Cu toate acestea, pentru persoanele care înțeleg infrastructura sistemului, lucrurile nu se dovedesc la fel de ușoare ca atare.
pentru mii de mașini independente care rulează simultan, care pot acoperi mai multe fusuri orare și continente, trebuie să se acorde unele tipuri de sincronizare sau coordonare pentru ca aceste mașini să colaboreze eficient între ele (astfel încât să poată apărea ca una). În acest blog, vom discuta despre sincronizarea timpului și modul în care acesta atinge coerența între mașini în ceea ce privește ordonarea și cauzalitatea evenimentelor.
conținutul acestui blog va fi organizat după cum urmează:
- sincronizare ceas
- Ceasuri logice
- ia
- ce urmează?
Ceasuri fizice
într-un sistem centralizat, timpul este lipsit de ambiguitate. Aproape toate computerele au un “ceas în timp real” pentru a ține evidența timpului, de obicei sincronizat cu un cristal de cuarț prelucrat cu precizie. Pe baza oscilației de frecvență bine definite a acestui cuarț, sistemul de operare al unui computer poate monitoriza cu precizie timpul intern. Chiar și atunci când computerul este oprit sau se descarcă, cuarțul continuă să bifeze datorită bateriei CMOS, o mică centrală integrată în placa de bază. Când computerul se conectează la rețea (Internet), sistemul de operare contactează apoi un server de temporizare, care este echipat cu un receptor UTC sau un ceas precis, pentru a reseta cu exactitate cronometrul local folosind Network Time Protocol, numit și NTP.
deși această frecvență a cuarțului cristal este rezonabil stabilă, este imposibil să se garanteze că toate cristalele diferitelor computere vor funcționa exact la aceeași frecvență. Imaginați-vă un sistem cu n calculatoare, ale căror fiecare cristal rulează la rate ușor diferite, determinând ceasurile să iasă treptat din sincronizare și să dea valori diferite la citire. Diferența dintre valorile de timp cauzate de aceasta se numește oblic de ceas.
în această situație, lucrurile s-au încurcat pentru că au avut mai multe mașini separate spațial. Dacă utilizarea mai multor ceasuri fizice interne este de dorit, cum le sincronizăm cu ceasurile din lumea reală? Cum le sincronizăm între ele?
Network Time Protocol
o abordare comună pentru sincronizarea în pereche între computere este prin utilizarea modelului client-server, adică permite clienților să contacteze un server de timp. Să luăm în considerare următorul exemplu cu 2 mașini a și B:
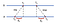
în primul rând, a trimite o cerere timestamped cu valoarea TBH la B. B, pe măsură ce mesajul sosește, înregistrează ora de primire TBH de la propriul ceas local și răspunsuri cu un mesaj timestamped cu T₂, piggybacking valoarea înregistrată anterior TBH. În cele din urmă, A, la primirea răspunsului de la B, înregistrează ora de sosire TBT. Pentru a ține cont de întârzierea în livrarea mesajelor, calculăm Urtux-Txt, Urtux-Txt = Txt-Txt. Acum, o compensare estimată a unei relative la B este:

pe baza cifrului, putem fie să încetinim ceasul lui A, fie să-l fixăm astfel încât cele două mașini să poată fi sincronizate între ele.
deoarece NTP este aplicabil în pereche, ceasul lui B poate fi ajustat și la cel al lui A. Cu toate acestea, nu este înțelept să reglați ceasul în B dacă se știe că este mai precis. Pentru a rezolva această problemă, NTP împarte serverele în straturi, adică clasarea serverelor, astfel încât ceasurile de pe servere mai puțin precise cu ranguri mai mici să fie sincronizate cu cele ale celor mai precise cu ranguri mai mari.
algoritmul Berkeley
spre deosebire de clienții care contactează periodic un server de timp pentru o sincronizare precisă a timpului, Gusella și Zatti, în 1989 Berkeley Unix paper , au propus modelul client-server în care serverul de timp (daemon) sondează periodic fiecare mașină pentru a întreba ce oră este acolo. Pe baza răspunsurilor, calculează timpul dus-întors al mesajelor, media timpului curent cu ignoranța oricăror valori aberante ale timpului și “spune tuturor celorlalte mașini să-și avanseze ceasurile la ora nouă sau să-și încetinească ceasurile până când s-a obținut o reducere specificată” .
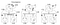
Ceasuri logice
să facem un pas înapoi și să reconsiderăm Baza noastră pentru marcajele de timp sincronizate. În secțiunea anterioară, atribuim valori concrete ceasurilor tuturor mașinilor participante, de acum înainte pot conveni asupra unei cronologii globale la care se întâmplă evenimente în timpul executării sistemului. Cu toate acestea, ceea ce contează cu adevărat pe parcursul cronologiei este ordinea în care apar evenimentele conexe. De exemplu, daca cumva am nevoie doar să știu Un eveniment se întâmplă înainte de evenimentul B, nu contează dacă Tₐ = 2, Tᵦ = 6 sau Tₐ = 4, Tᵦ = 10, atâta timp cât Tₐ < Tᵦ. Acest lucru ne îndreaptă atenția către tărâmul ceasurilor logice, unde sincronizarea este influențată de definiția lui Leslie Lamport a relației “se întâmplă înainte”.
ceasurile logice ale lui Lamport
în fenomenalul său timp de hârtie din 1978, ceasuri și ordonarea evenimentelor într – un sistem distribuit, Lamport a definit relația” happens-before “” XV ” după cum urmează:
1. Dacă a și b sunt evenimente în același proces, iar a vine înaintea lui b, atunci a b.
2. Dacă a este trimiterea unui mesaj printr-un proces și b este primirea aceluiași mesaj printr-un alt proces, atunci a b.
3. În cazul în care A. C. B și B. C. C, atunci A. C. c.
dacă evenimentele x, y apar în diferite procese care nu fac schimb de mesaje, nici x x x x x x x x x x x este adevărat, x și y se spune că sunt concurente. Având în vedere o funcție C care atribuie o valoare de timp C(A) pentru un eveniment asupra căruia toate procesele sunt de acord, dacă a și b sunt evenimente în cadrul aceluiași proces și a are loc înainte de b, C(a) < C (b)*. În mod similar, dacă a este trimiterea unui mesaj printr-un proces și b este recepția acelui mesaj printr-un alt proces, C(a) < C(B) **.
acum să ne uităm la algoritmul pe care Lamport l-a propus pentru atribuirea timpilor evenimentelor. Luați în considerare următorul exemplu cu un grup de 3 procese A, B, C:

aceste ceasuri 3 procese funcționează pe cont propriu calendarul și sunt inițial de sincronizare. Fiecare ceas poate fi implementat cu un contor software simplu, incrementat cu o valoare specifică la fiecare unitate de timp T. Cu toate acestea, valoarea cu care un ceas este incrementat diferă pe proces: 1 Pentru a, 5 pentru B și 2 Pentru C.
la ora 1, a trimite mesajul m1 la B. la momentul sosirii, ceasul de la B Citește 10 în ceasul său intern. Deoarece mesajul a fost trimis a fost timestamped cu timpul 1, valoarea 10 în procesul B este cu siguranță posibil (putem deduce că a fost nevoie de 9 căpușe pentru a ajunge la B de la A).
acum ia în considerare mesajul m2. Părăsește B la 15 și ajunge la C la 8. Această valoare de ceas la C este în mod clar imposibilă, deoarece timpul nu poate merge înapoi. De la * * și faptul că m2 pleacă la 15, trebuie să ajungă la 16 sau mai târziu. Prin urmare, trebuie să actualizăm valoarea curentă a timpului la C pentru a fi mai mare de 15 (adăugăm +1 la timp pentru simplitate). Cu alte cuvinte, atunci când sosește un mesaj și ceasul receptorului arată o valoare care precede marcajul de timp care indică plecarea mesajului, receptorul își transmite rapid ceasul pentru a fi cu o unitate de timp mai mult decât ora de plecare. În Figura 6, vedem că m2 corectează acum valoarea ceasului la C la 16. În mod similar, m3 și m4 ajung la 30 și respectiv 36.
din exemplul de mai sus, Maarten van Steen et al formulează algoritmul Lamport după cum urmează:
1. Înainte de a executa un eveniment (adică trimiterea unui mesaj prin rețea,…), p incremente de la C la C la C la C < – C la C la 1.
2. Atunci când procesul de P XV trimite mesajul m la procesul de Pj, se stabilește m timestamp ts(M) este egal cu C, După ce a executat etapa anterioară.
3. La primirea unui mesaj m, proces PJ ajustează propriul contor local ca CJ < – max{Cj, ts(m)} după care execută apoi primul pas și livrează mesajul către aplicație.
Ceasuri vectoriale
amintiți-vă înapoi la definiția lui Lamport a relației “se întâmplă înainte”, dacă există două evenimente A și b astfel încât a apare înainte de b, atunci a este poziționat și în acea ordonare înainte de b, adică C(a) < C(B). Cu toate acestea, acest lucru nu implică cauzalitate inversă, deoarece nu putem deduce că a merge înainte de b Doar prin compararea valorilor C(A) și C(b) (dovada este lăsată ca un exercițiu cititorului).
pentru a obține mai multe informații despre ordonarea evenimentelor pe baza marcajului lor de timp, se propune ceasurile vectoriale, o versiune mai avansată a ceasului logic al lui Lamport. Pentru fiecare procedeu P Inktv al sistemului, algoritmul menține un vector VC INKTV cu următoarele atribute:
1. VC-ul: ceasul logic local la P-ul, sau numărul de evenimente care au avut loc înainte de marcajul temporal curent.
2. În cazul în care VC XCT = k, P XCT știu că evenimentele K au avut loc la Pj.
algoritmul ceasurilor vectoriale merge după cum urmează:
1. Înainte de a executa un eveniment, P.
2. Atunci când P Xqtx trimite un mesaj m către Pj, acesta stabilește marcajul de timp ts(m) egal cu VC XQTX după ce a efectuat pasul anterior.
3. Când mesajul m este primit, procesul de actualizare Pj fiecare k de propriul ceas vector: VCJ max { VCJ , ts(m)}. Apoi continuă să execute primul pas și livrează mesajul către aplicație.
prin acești pași, atunci când un proces PJ primește un mesaj m de la procesul P_3 cu timestamp ts(m), acesta cunoaște numărul de evenimente care au avut loc la P_3 precedat întâmplător trimiterea lui m. în plus, Pj știe și despre evenimentele care au fost cunoscute de P_3 despre alte procese înainte de a trimite m. (Da, este adevărat, dacă raportați acest algoritm la protocolul de bârfă#).
sperăm că explicația nu vă lasă să vă zgâriați capul prea mult timp. Să ne aruncăm într-un exemplu pentru a stăpâni conceptul:

în acest exemplu, avem trei procese PBH, P₂, și Pchange alternativ mesaje pentru a sincroniza ceasurile lor împreună. PBH trimite mesajul m1 la ora logică VC₂ = (1, 0, 0) (pasul 1) la P₂. P₂, la primirea m1 cu timestamp ts (m1) = (1, 0, 0), ajustează timpul său logic VC₂ la (1, 1, 0) (Pasul 3) și trimite mesajul m2 înapoi la p₂ cu timestamp (1, 2, 0) (pasul 1). În mod similar, procesul PBT acceptă mesajul m2 de la P₂, își modifică ceasul logic la (2, 2, 0) (Pasul 3), după care trimite mesajul m3 către PBT at (3, 2, 0). PBT își ajustează ceasul la (3, 2, 1) (Pasul 1) după ce primește mesajul m3 de la Pchester. Mai târziu, preia mesajul m4, trimis de P₂ la (1, 4, 0), ajustând astfel ceasul la (3, 4, 2) (Pasul 3).
pe baza modului în care derulăm rapid ceasurile interne pentru sincronizare, evenimentul a precede evenimentul b dacă pentru toate k, ts(a) ts(B) și există cel puțin un indice k’ pentru care ts(a) < ts(b). Nu este greu de văzut că (2, 2, 0) precede (3, 2, 1), dar (1, 4, 0) și (3, 2, 0) pot intra în conflict între ele. Prin urmare, cu ceasurile vectoriale, putem detecta dacă există sau nu o dependență cauzală între oricare două evenimente.
ia
când vine vorba de conceptul de timp în sistem distribuit, obiectivul principal este de a atinge ordinea corectă a evenimentelor. Evenimentele pot fi poziționate fie în ordine cronologică cu ceasuri fizice, fie în ordine logică cu ceasurile logice Lamtport și ceasurile vectoriale de-a lungul cronologiei de execuție.
ce urmează?
în continuare în serie, vom trece peste modul în care sincronizarea timpului poate oferi răspunsuri surprinzător de simple la unele probleme clasice din sistemele distribuite: cel mult un mesaj , consistența cache-ului și excluderea reciprocă .
Leslie Lamport: timpul, ceasurile și ordonarea evenimentelor într-un sistem distribuit. 1978.
Barbara Liskov: utilizări practice ale ceasurilor sincronizate în sistemele distribuite. 1993.
Maarten van Steen, Andrew S. Tanenbaum: Sisteme distribuite. 2017.
Barbara Liskov, Liuba Shrira, John Wroclawski: Mesaje eficiente cel mult o dată bazate pe ceasuri sincronizate. 1991.
Cary G. Gray, David R. Cheriton: Leasing: un mecanism eficient tolerant la erori pentru consistența cache-ului de fișiere distribuite. 1989.
Ricardo Gusella, Stefano Zatti: precizia sincronizării ceasului realizată de TEMPO în Berkeley Unix 4.3 BSD. 1989.