Cloud Data Warehouse vs. traditionelle Data Warehouse-Konzepte
Cloud-basierte Data Warehouses sind die neue Norm. Vorbei sind die Zeiten, in denen Ihr Unternehmen Hardware kaufen, Serverräume erstellen und ein engagiertes Team von Mitarbeitern einstellen, schulen und unterhalten musste, um es zu betreiben. Jetzt können Sie mit wenigen Klicks auf Ihrem Laptop und einer Kreditkarte auf praktisch unbegrenzte Rechenleistung und Speicherplatz zugreifen.
Dies bedeutet jedoch nicht, dass traditionelle Data Warehouse-Ideen tot sind. Die klassische Data-Warehouse-Theorie untermauert das meiste, was Cloud-basierte Data Warehouses tun.
In diesem Artikel erklären wir Ihnen die traditionellen Data-Warehouse-Konzepte, die Sie kennen müssen, und die wichtigsten Cloud-Konzepte von einer Auswahl der Top-Anbieter: Amazon, Google und Panoply. Abschließend führen wir eine Kosten-Nutzen-Analyse von traditionellen vs. Cloud-Data Warehouses durch, damit Sie wissen, welches für Sie das Richtige ist.
Lass uns anfangen.
- Traditionelle Data Warehouse-Konzepte
- Fakten, Dimensionen und Kennzahlen
- Normalisierung und Denormalisierung
- Datenmodelle
- Faktentabelle
- Star Schema vs. Snowflake Schema
- OLAP vs. OLTP
- Dreistufige Architektur
- Virtuelles Data Warehouse / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Enterprise Data Warehouse
- Cloud Data Warehouse Konzepte
- Cloud Data Warehouse-Konzepte – Amazon Redshift
- Cluster
- Knoten
- Partitionen/Slices
- Spaltenspeicher
- Komprimierung
- Laden von Daten
- Cloud Database Warehouse – Google BigQuery
- Serverloser Dienst
- Colossus-Dateisystem
- Dremel Execution Engine
- Datenfreigabe
- Streaming und Batch-Aufnahme
- Cloud-Data-Warehouse-Konzepte – Panoply
- Primärschlüssel
- Inkrementelle Schlüssel
- Verschachtelte Daten
- Verlaufstabellen
- Transformationen
- Zeichenfolgenformate
- Datenschutz
- Zugriffskontrolle
- IP-Whitelisting
- Fazit: Traditionelle vs. Data Warehouse-Konzepte in Kürze
- Traditionelle Data-Warehouse-Konzepte
- Cloud-Data-Warehouse-Konzepte – Amazon Redshift als Beispiel
- Cloud-Data-Warehouse-Konzepte – BigQuery als Beispiel
- Traditionelle vs. Cloud-Kosten-Nutzen-Analyse
- Erfahren Sie mehr über Data Warehouses
Traditionelle Data Warehouse-Konzepte
Ein Data Warehouse ist jedes System, das Daten aus einer Vielzahl von Quellen innerhalb einer Organisation sammelt. Data Warehouses werden als zentrale Datenspeicher für Analyse- und Berichtszwecke verwendet.
Ein traditionelles Data Warehouse befindet sich vor Ort in Ihren Büros. Sie kaufen die Hardware, die Serverräume und stellen das Personal ein, um sie zu betreiben. Sie werden auch als lokale, lokale oder (grammatikalisch falsche) lokale Data Warehouses bezeichnet.
Fakten, Dimensionen und Kennzahlen
Die Kernbausteine von Informationen in einem Data Warehouse sind Fakten, Dimensionen und Kennzahlen.
Ein Fakt ist der Teil Ihrer Daten, der auf ein bestimmtes Ereignis oder eine bestimmte Transaktion hinweist. Wenn Ihr Unternehmen beispielsweise Blumen verkauft, sind einige Fakten, die Sie in Ihrem Data Warehouse sehen würden:
- Verkauft 30 Rosen im Laden für $19.99
- Bestellte 500 neue Blumentöpfe aus China für $ 1500
- Bezahltes Gehalt des Kassierers für diesen Monat $1000
Mehrere Zahlen können jede Tatsache beschreiben, und wir nennen diese Zahlen Maßnahmen. Einige Maßnahmen, um die Tatsache zu beschreiben, ‘bestellt 500 neue Blumentöpfe aus China für $1500’ sind:
- Bestellte Menge – 500
- Kosten – $1500
Wenn Analysten mit Daten arbeiten, führen sie Berechnungen zu Kennzahlen durch (z. B. Summe, Maximum, Durchschnitt), um Erkenntnisse zu gewinnen. Zum Beispiel möchten Sie vielleicht die durchschnittliche Anzahl der Blumentöpfe wissen, die Sie jeden Monat bestellen.
Eine Dimension kategorisiert Fakten und Kennzahlen und stellt ihnen strukturierte Kennzeichnungsinformationen zur Verfügung – andernfalls wären sie nur eine Sammlung ungeordneter Zahlen! Einige Dimensionen, um die Tatsache zu beschreiben, dass 500 neue Blumentöpfe aus China für 1500 US-Dollar bestellt wurden, sind:
- Land gekauft von – China
- Zeit gekauft – 1 pm
- Voraussichtliches Ankunftsdatum – 6. Juni
Sie können keine Berechnungen für Abmessungen explizit durchführen, und dies wäre wahrscheinlich nicht sehr hilfreich – wie finden Sie das durchschnittliche Ankunftsdatum für Bestellungen? Es ist jedoch möglich, neue Kennzahlen aus Dimensionen zu erstellen, und diese sind nützlich. Wenn Sie beispielsweise die durchschnittliche Anzahl von Tagen zwischen Bestelldatum und Ankunftsdatum kennen, können Sie Aktienkäufe besser planen.
Normalisierung und Denormalisierung
Normalisierung ist der Prozess der effizienten Organisation von Daten in einem Data Warehouse (oder einem anderen Ort, an dem Daten gespeichert werden). Die Hauptziele bestehen darin, die Datenredundanz zu reduzieren – d. H. doppelte Daten zu entfernen – und die Datenintegrität zu verbessern – d. h. Die Genauigkeit der Daten zu verbessern. Es gibt verschiedene Ebenen der Normalisierung und keinen Konsens für die ‘beste’ Methode. Bei allen Methoden werden jedoch separate, aber verwandte Informationen in verschiedenen Tabellen gespeichert.
Es gibt viele Vorteile der Normalisierung, wie zum Beispiel:
- Schnelleres Suchen und Sortieren in jeder Tabelle
- Einfachere Tabellen beschleunigen das Schreiben und Ausführen von Datenänderungsbefehlen
- Weniger redundante Daten bedeuten, dass Sie Speicherplatz sparen und somit mehr Daten sammeln und speichern können
Denormalisierung ist der Prozess des bewussten Hinzufügens redundanter Kopien oder Gruppen von Daten zu bereits normalisierten Daten. Es ist nicht dasselbe wie unnormalisierte Daten. Die Denormalisierung verbessert die Leseleistung und erleichtert das Bearbeiten von Tabellen in gewünschten Formularen erheblich. Wenn Analysten mit Data Warehouses arbeiten, führen sie in der Regel nur Lesevorgänge für die Daten durch. Somit können denormalisierte Daten ihnen viel Zeit und Kopfschmerzen ersparen.
Vorteile der Denormalisierung:
- Weniger Tabellen minimieren die Notwendigkeit von Tabellenverknüpfungen, was den Workflow von Datenanalysten beschleunigt und dazu führt, dass sie nützlichere Einblicke in die Daten erhalten
- Weniger Tabellen vereinfachen Abfragen, die zu weniger Fehlern führen
Datenmodelle
Es wäre äußerst ineffizient, alle Ihre Daten in einer riesigen Tabelle zu speichern. Ihr Data Warehouse enthält also viele Tabellen, die Sie zusammenfügen können, um bestimmte Informationen zu erhalten. Die Haupttabelle wird als Faktentabelle bezeichnet, und Dimensionstabellen umgeben sie.
Der erste Schritt beim Entwerfen eines Data Warehouse besteht darin, ein konzeptionelles Datenmodell zu erstellen, das die gewünschten Daten und die Beziehungen auf hoher Ebene zwischen ihnen definiert.
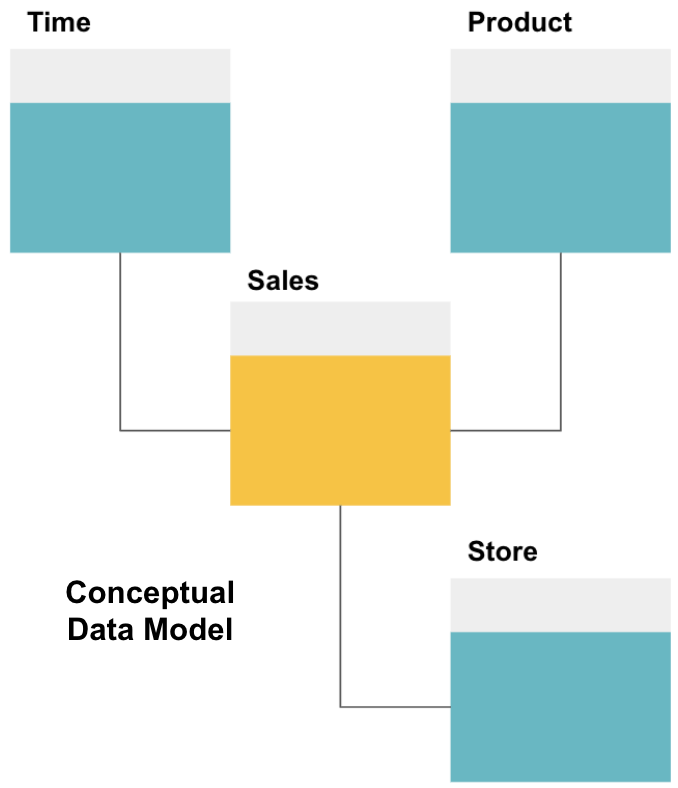
Hier haben wir das konzeptionelle Modell definiert. Wir speichern Verkaufsdaten und verfügen über drei zusätzliche Tabellen – Zeit, Produkt und Geschäft -, die zusätzliche, detailliertere Informationen zu jedem Verkauf enthalten. Die Faktentabelle ist Sales und die anderen sind Dimensionstabellen.
Der nächste Schritt ist die Definition eines logischen Datenmodells. Dieses Modell beschreibt die Daten im Detail in einfachem Englisch, ohne sich Gedanken darüber zu machen, wie sie in Code implementiert werden.
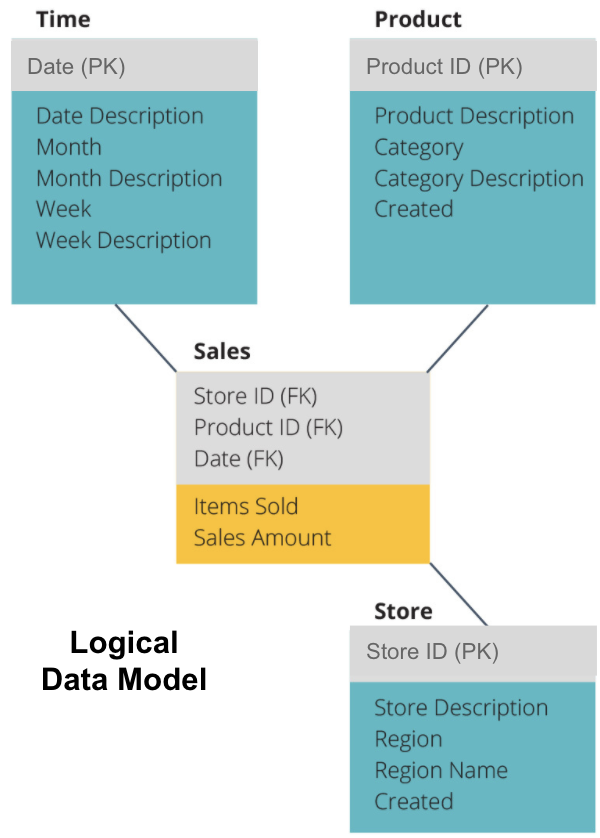
Jetzt haben wir ausgefüllt, welche Informationen jede Tabelle in einfachem Englisch enthält. Jede der Zeit-, Produkt- und Speicherdimensionstabellen zeigt den Primärschlüssel (PK) im grauen Feld und die entsprechenden Daten in den blauen Feldern an. Die Sales-Tabelle enthält drei Fremdschlüssel (FK), damit sie schnell mit den anderen Tabellen verknüpft werden kann.
Die letzte Stufe besteht darin, ein physikalisches Datenmodell zu erstellen. In diesem Modell erfahren Sie, wie Sie das Data Warehouse im Code implementieren. Es definiert Tabellen, ihre Struktur und die Beziehung zwischen ihnen. Es gibt auch Datentypen für Spalten an, und alles wird so benannt, wie es im endgültigen Data Warehouse sein wird, dh alle Großbuchstaben und mit Unterstrichen verbunden. Schließlich beginnt jede Dimensionstabelle mit DIM_ und jede Faktentabelle mit FACT_ .
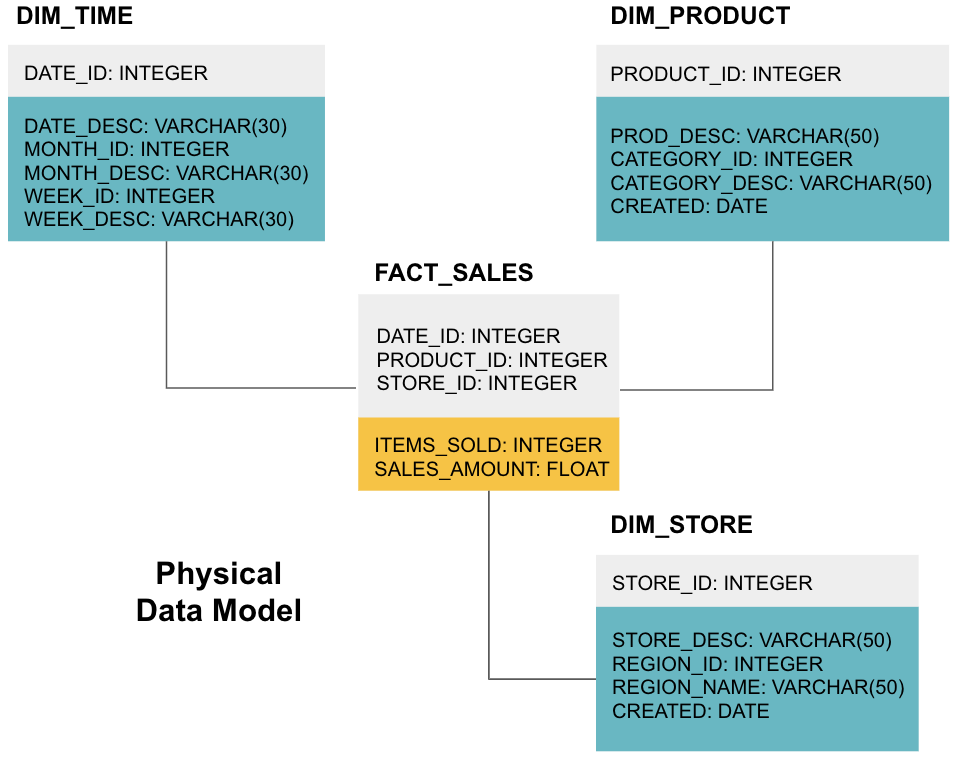
Jetzt wissen Sie, wie Sie ein Data Warehouse entwerfen, aber Fakten- und Dimensionstabellen haben einige Nuancen, die wir als nächstes erläutern werden.
Faktentabelle
Jede Geschäftsfunktion – z. B. Vertrieb, Marketing, Finanzen – verfügt über eine entsprechende Faktentabelle.
Faktentabellen haben zwei Arten von Spalten: Dimensionsspalten und Faktenspalten. Dimensionsspalten – in unseren Beispielen grau gefärbt – enthalten Fremdschlüssel (FK), mit denen Sie eine Faktentabelle mit einer Dimensionstabelle verknüpfen. Diese Fremdschlüssel sind die Primärschlüssel (PK) für jede der Dimensionstabellen. Faktenspalten – in unseren Beispielen gelb gefärbt – enthalten die tatsächlichen Daten und zu analysierenden Kennzahlen, z. B. die Anzahl der verkauften Artikel und den gesamten Dollarwert des Umsatzes.
Eine faktenlose Faktentabelle ist eine bestimmte Art von Faktentabelle, die nur Dimensionsspalten enthält. Solche Tabellen sind nützlich, um Ereignisse wie die Anwesenheit von Studenten oder den Urlaub von Mitarbeitern zu verfolgen, da die Dimensionen Ihnen alles sagen, was Sie über die Ereignisse wissen müssen.
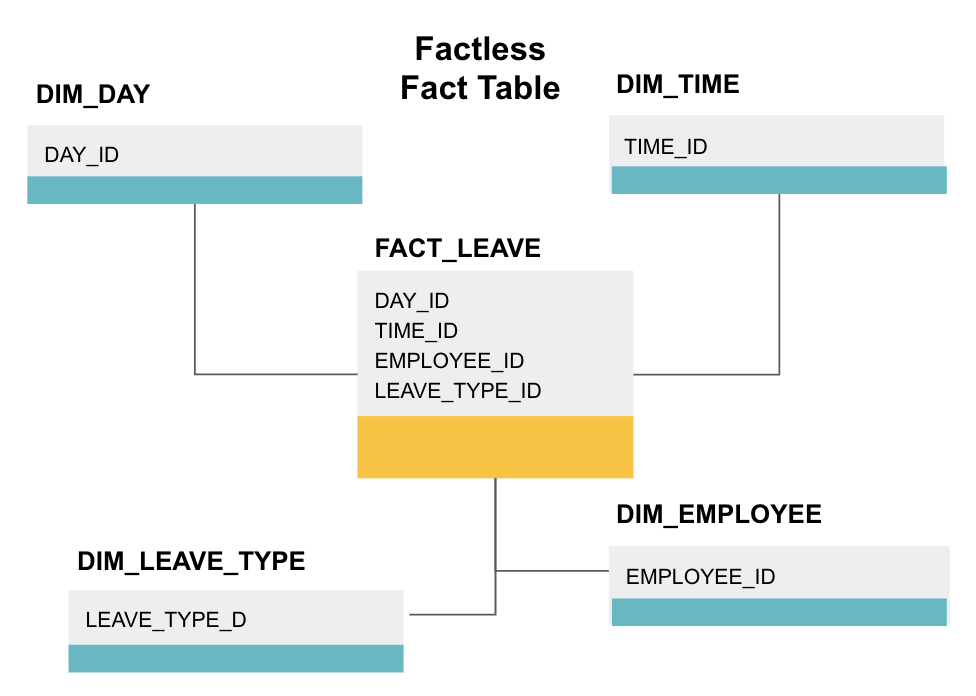
Die obige faktenlose Faktentabelle verfolgt den Mitarbeiterurlaub. Es gibt keine Fakten, da Sie nur wissen müssen:
- An welchem Tag sie frei waren (DAY_ID).
- Wie lange sie ausgeschaltet waren (TIME_ID).
- Wer war im Urlaub (EMPLOYEE_ID).
- Ihr Grund für den Urlaub, z., Krankheit, Urlaub, Arzttermin, etc. (LEAVE_TYPE_ID).
Star Schema vs. Snowflake Schema
Die obigen Data Warehouses hatten alle ein ähnliches Layout. Dies ist jedoch nicht die einzige Möglichkeit, sie zu arrangieren.
Die beiden am häufigsten verwendeten Schemata zum Organisieren von Data Warehouses sind Star und Snowflake. Beide Methoden verwenden Dimensionstabellen, die die in einer Faktentabelle enthaltenen Informationen beschreiben.
Das Sternschema nimmt die Informationen aus der Faktentabelle und teilt sie in denormalisierte Dimensionstabellen auf. Der Schwerpunkt für das Sternschema liegt auf der Abfragegeschwindigkeit. Es ist nur ein Join erforderlich, um Faktentabellen mit jeder Dimension zu verknüpfen, sodass das Abfragen jeder Tabelle einfach ist. Da die Tabellen jedoch denormalisiert sind, enthalten sie häufig wiederholte und redundante Daten.
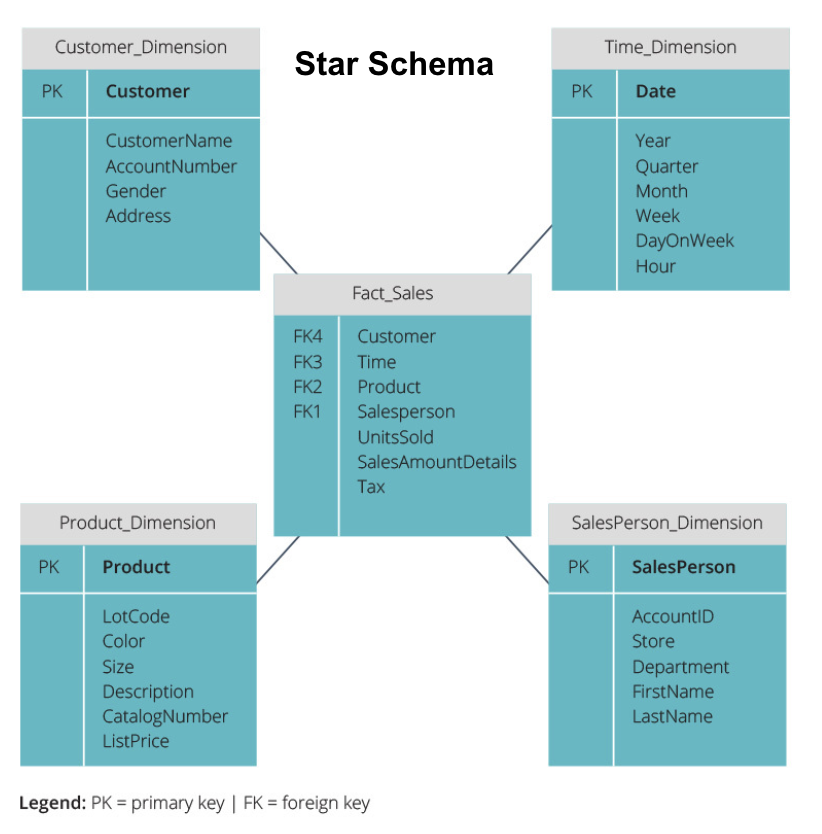
Das Snowflake-Schema teilt die Faktentabelle in eine Reihe normalisierter Dimensionstabellen auf. Durch die Normalisierung werden mehr Dimensionstabellen erstellt, wodurch Probleme mit der Datenintegrität reduziert werden. Die Abfrage mit dem Snowflake-Schema ist jedoch schwieriger, da Sie mehr Tabellenverknüpfungen benötigen, um auf die relevanten Daten zuzugreifen. Sie haben also weniger redundante Daten, aber es ist schwieriger darauf zuzugreifen.
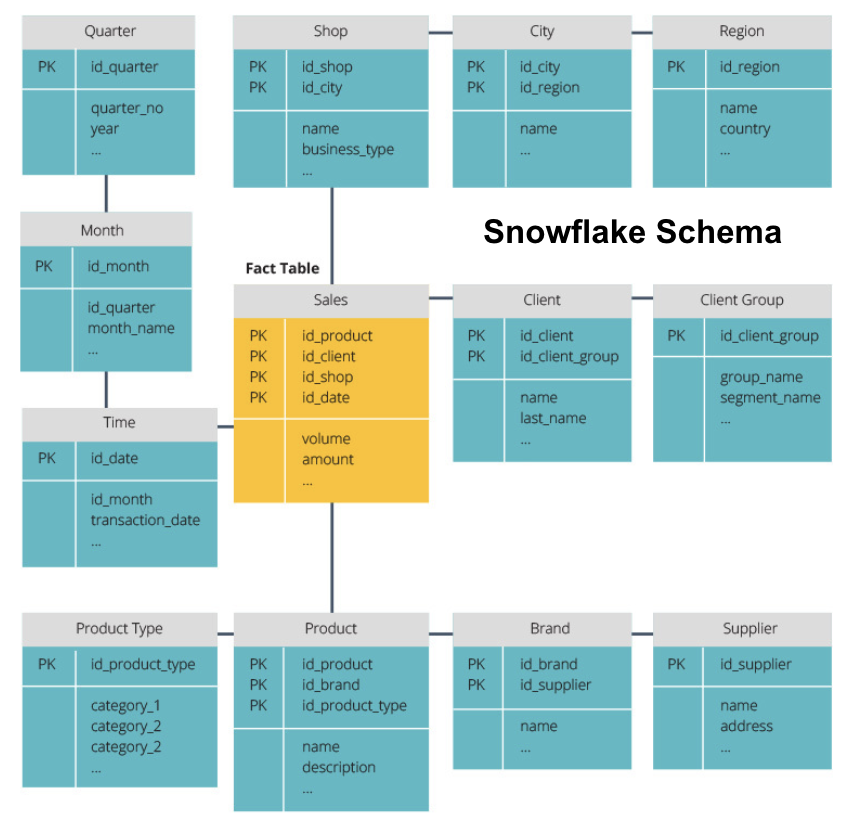
Jetzt werden wir einige grundlegendere Data Warehouse-Konzepte erklären.
OLAP vs. OLTP
Die Online-Transaktionsverarbeitung (OLTP) zeichnet sich durch kurze Schreibvorgänge aus, die die Front-End-Anwendungen der Datenarchitektur eines Unternehmens betreffen. OLTP-Datenbanken legen Wert auf eine schnelle Abfrageverarbeitung und behandeln nur aktuelle Daten. Unternehmen verwenden diese, um Informationen für Geschäftsprozesse zu erfassen und Quelldaten für das Data Warehouse bereitzustellen.
Mit Online Analytical Processing (OLAP) können Sie komplexe Leseabfragen ausführen und so eine detaillierte Analyse historischer Transaktionsdaten durchführen. OLAP-Systeme helfen bei der Analyse der Daten im Data Warehouse.
Dreistufige Architektur
Herkömmliche Data Warehouses sind in der Regel in drei Ebenen strukturiert:
- Unterste Ebene: Ein Datenbankserver, normalerweise ein RDBMS, der Daten aus verschiedenen Quellen mithilfe eines Gateways extrahiert. Zu den Datenquellen, die in diese Ebene eingespeist werden, gehören Betriebsdatenbanken und andere Arten von Front-End-Daten wie CSV- und JSON-Dateien.
- Middle Tier: Ein OLAP-Server, der entweder
- die Vorgänge direkt implementiert oder
- die Vorgänge für mehrdimensionale Daten relationalen Standardoperationen zuordnet, z. B. das Abflachen von XML- oder JSON-Daten in Zeilen innerhalb von Tabellen.
- Top Tier: Die Abfrage- und Reporting-Tools für Datenanalyse und Business Intelligence.
Virtuelles Data Warehouse / Data Mart
Virtuelles Data Warehousing verwendet verteilte Abfragen auf mehrere Datenbanken, ohne die Daten in ein physisches Data Warehouse zu integrieren.
Data Marts sind Teilmengen von Data Warehouses, die auf bestimmte Geschäftsfunktionen wie Vertrieb oder Finanzen ausgerichtet sind. Ein Data Warehouse kombiniert in der Regel Informationen aus mehreren Data Marts in mehreren Geschäftsfunktionen. Ein Data Mart enthält jedoch Daten aus einer Reihe von Quellsystemen für eine Geschäftsfunktion.
Kimball vs. Inmon
Es gibt zwei Ansätze für das Data Warehouse-Design, die von Bill Inmon und Ralph Kimball vorgeschlagen wurden. Bill Inmon ist ein US-amerikanischer Informatiker, der als Vater des Data Warehouse gilt. Ralph Kimball ist einer der ursprünglichen Architekten von Data Warehousing und hat mehrere Bücher zu diesem Thema geschrieben.
Die beiden Experten hatten widersprüchliche Meinungen darüber, wie Data Warehouses strukturiert sein sollten. Dieser Konflikt hat zwei Denkschulen hervorgebracht.
Der Inmon-Ansatz ist ein Top-Down-Design. Bei der Inmon-Methodik wird zunächst das Data Warehouse erstellt und als zentraler Bestandteil der Analyseumgebung gesehen. Die Daten werden dann zusammengefasst und vom zentralen Warehouse an einen oder mehrere abhängige Data Marts verteilt.
Der Kimball-Ansatz betrachtet das Data Warehouse-Design von unten nach oben. In dieser Architektur erstellt eine Organisation separate Data Marts, die Einblicke in einzelne Abteilungen innerhalb einer Organisation bieten. Das Data Warehouse ist die Kombination dieser Data Marts.
ETL vs. ELT
Extract, Transform, Load (ETL) beschreibt den Prozess des Extrahierens der Daten aus Quellsystemen (typischerweise Transaktionssystemen), des Konvertierens der Daten in ein Format oder eine Struktur, die für Abfragen und Analysen geeignet ist, und schließlich des Ladens in das Data Warehouse. ETL nutzt eine separate Staging-Datenbank und wendet vor dem Laden eine Reihe von Regeln oder Funktionen auf die extrahierten Daten an.
Extrahieren, Laden, Transformieren (ELT) ist ein anderer Ansatz zum Laden von Daten. ELT nimmt die Daten aus unterschiedlichen Quellen und lädt sie direkt in das Zielsystem, wie das Data Warehouse. Das System wandelt die geladenen Daten dann bei Bedarf um, um eine Analyse zu ermöglichen.
ELT bietet ein schnelleres Laden als ETL, erfordert jedoch ein leistungsfähiges System, um die Datentransformationen bei Bedarf durchzuführen.
Enterprise Data Warehouse
Ein Enterprise Data Warehouse ist als einheitliches, zentralisiertes Warehouse gedacht, das alle aktuellen und historischen Transaktionsinformationen in der Organisation enthält. Ein Enterprise Data Warehouse sollte Daten aus allen mit dem Unternehmen verbundenen Themenbereichen wie Marketing, Vertrieb, Finanzen und Personalwesen enthalten.
Dies sind die Kernideen, die traditionelle Data Warehouses ausmachen. Schauen wir uns nun an, was Cloud Data Warehouses zusätzlich hinzugefügt haben.
Cloud Data Warehouse Konzepte
Cloud Data Warehouses sind neu und verändern sich ständig. Um ihre grundlegenden Konzepte am besten zu verstehen, sollten Sie sich über die führenden Cloud-Data-Warehouse-Lösungen informieren.
Drei führende Cloud-Data-Warehouse-Lösungen sind Amazon Redshift, Google BigQuery und Panoply. Im Folgenden erläutern wir grundlegende Konzepte aus jedem dieser Dienste, um Ihnen ein allgemeines Verständnis der Funktionsweise moderner Data Warehouses zu vermitteln.
Cloud Data Warehouse-Konzepte – Amazon Redshift
Die folgenden Konzepte werden explizit im Amazon Redshift Cloud Data Warehouse verwendet, können jedoch in Zukunft für zusätzliche Data Warehouse-Lösungen gelten, die auf Amazon Infrastructure basieren.
Cluster
Amazon Redshift basiert seine Architektur auf Clustern. Ein Cluster ist einfach eine Gruppe gemeinsam genutzter Computerressourcen, die als Knoten bezeichnet werden.
Knoten
Knoten sind Rechenressourcen mit CPU, RAM und Festplattenspeicher. Ein Cluster, der zwei oder mehr Knoten enthält, besteht aus einem Leader-Knoten und Compute-Knoten.
Leader-Knoten kommunizieren mit Client-Programmen und kompilieren Code, um Abfragen auszuführen, und weisen ihn Compute-Knoten zu. Compute-Knoten führen die Abfragen aus und geben die Ergebnisse an den Leader-Knoten zurück. Ein Compute-Knoten führt nur Abfragen aus, die auf Tabellen verweisen, die auf diesem Knoten gespeichert sind.
Partitionen/Slices
Amazon partitioniert jeden Compute Node in Slices. Ein Slice erhält eine Zuweisung von Speicher und Speicherplatz auf dem Knoten. Mehrere Slices arbeiten parallel, um die Abfrageausführungszeit zu beschleunigen.
Spaltenspeicher
Redshift verwendet Spaltenspeicher, um eine bessere analytische Abfrageleistung zu ermöglichen. Anstatt Datensätze in Zeilen zu speichern, werden Werte aus einer einzelnen Spalte für mehrere Zeilen gespeichert. Die folgenden Diagramme verdeutlichen dies:
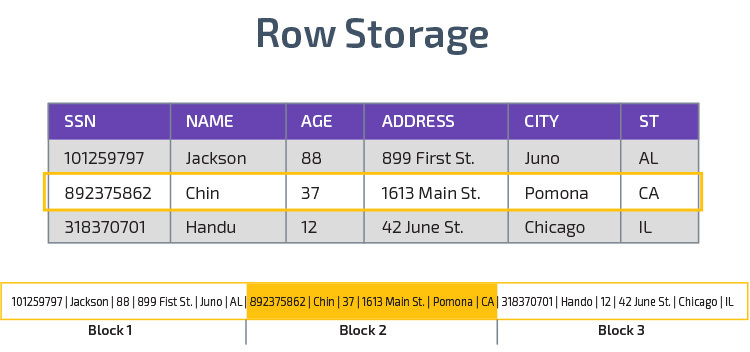
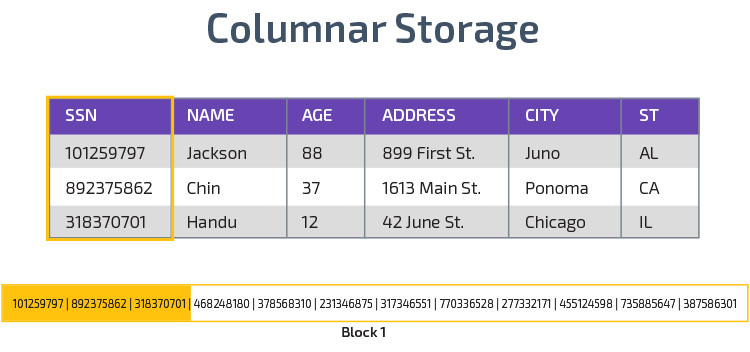
Die Spaltenspeicherung ermöglicht ein schnelleres Lesen von Daten, was für analytische Abfragen, die sich über viele Spalten in einem Datensatz erstrecken, von entscheidender Bedeutung ist. Der Spaltenspeicher beansprucht auch weniger Speicherplatz, da jeder Block denselben Datentyp enthält, was bedeutet, dass er in ein bestimmtes Format komprimiert werden kann.
Komprimierung
Komprimierung reduziert die Größe der gespeicherten Daten. In Redshift erfolgt die Komprimierung aufgrund der Art und Weise, wie Daten gespeichert werden, auf Spaltenebene. Mit Redshift können Sie Informationen beim Erstellen einer Tabelle manuell oder automatisch mit dem Befehl KOPIEREN komprimieren.
Laden von Daten
Mit dem COPY-Befehl von Redshift können Sie große Datenmengen in das Data Warehouse laden. Der Befehl COPY nutzt die MPP-Architektur von Redshift zum parallelen Lesen und Laden von Daten aus Dateien in Amazon S3, aus einer DynamoDB-Tabelle oder Textausgabe von einem oder mehreren Remote-Hosts.
Es ist auch möglich, Daten mit dem Amazon Kinesis Firehose-Dienst in Redshift zu streamen.
Cloud Database Warehouse – Google BigQuery
Die folgenden Konzepte werden explizit im Google BigQuery Cloud Data Warehouse verwendet, können jedoch in Zukunft für zusätzliche Lösungen gelten, die auf der Google-Infrastruktur basieren.
Serverloser Dienst
BigQuery verwendet eine serverlose Architektur. Mit BigQuery müssen Unternehmen keine physischen Servereinheiten verwalten, um ihre Data Warehouses auszuführen. Stattdessen verwaltet BigQuery dynamisch die Zuweisung seiner Rechenressourcen. Unternehmen, die den Dienst nutzen, zahlen einfach für die Datenspeicherung pro Gigabyte und Abfragen pro Terabyte.
Colossus-Dateisystem
BigQuery verwendet die neueste Version des verteilten Dateisystems von Google mit dem Codenamen Colossus. Das Colossus-Dateisystem verwendet spaltenförmige Speicher- und Komprimierungsalgorithmen, um Daten für Analysezwecke optimal zu speichern.
Dremel Execution Engine
Die Dremel Execution Engine verwendet ein spaltenartiges Layout, um große Datenbestände schnell abzufragen. Die Ausführungsengine von Dremel kann Ad-hoc-Abfragen für Milliarden von Zeilen in Sekunden ausführen, da sie eine massiv parallele Verarbeitung in Form einer Baumarchitektur verwendet.
Die Baumarchitektur verteilt Abfragen von einem Root-Server auf mehrere Zwischenserver. Die Zwischenserver schieben die Abfrage auf Blattserver (die gespeicherte Daten enthalten), die die Daten parallel scannen. Auf dem Weg zurück in den Baum sendet jeder Blattserver Abfrageergebnisse, und die Zwischenserver führen eine parallele Aggregation von Teilergebnissen durch.
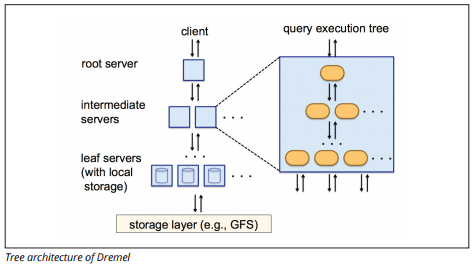
Bildquelle
Mit Dremel können Unternehmen Abfragen auf bis zu zehntausenden Servern gleichzeitig ausführen. Laut Google kann Dremel 35 Milliarden Zeilen ohne Index in zehn Sekunden scannen.
Datenfreigabe
Die serverlose Architektur von Google BigQuery ermöglicht es Unternehmen, Daten problemlos mit anderen Organisationen zu teilen, ohne dass diese Organisationen in ihren eigenen Speicher investieren müssen.
Organisationen, die gemeinsam genutzte Daten abfragen möchten, können dies tun und zahlen nur für die Abfragen. Es ist nicht erforderlich, kostspielige gemeinsame Datensilos außerhalb der Dateninfrastruktur des Unternehmens zu erstellen und die Daten in diese Silos zu kopieren.
Streaming und Batch-Aufnahme
Es ist möglich, Daten aus Google Cloud Storage in BigQuery zu laden, einschließlich CSV-, JSON- (Zeilenumbruch) und Avro-Dateien sowie Google Cloud Datastore-Backups. Sie können Daten auch direkt aus einer lesbaren Datenquelle laden.
BigQuery bietet auch eine Streaming-API, um Daten mit einer Geschwindigkeit von Millionen von Zeilen pro Sekunde in das System zu laden, ohne eine Last auszuführen. Die Daten stehen fast sofort zur Analyse zur Verfügung.
Cloud-Data-Warehouse-Konzepte – Panoply
Panoply ist ein All-in-One-Warehouse, das ETL mit einem leistungsstarken Data Warehouse kombiniert. Es ist der einfachste Weg, die Daten eines Unternehmens zu synchronisieren, zu speichern und darauf zuzugreifen, indem die Entwicklung und Codierung entfällt, die mit der Transformation, Integration und Verwaltung von Big Data verbunden sind.
Im Folgenden finden Sie einige der wichtigsten Konzepte im Panoply Data Warehouse in Bezug auf Datenmodellierung und Datenschutz.
Primärschlüssel
Primärschlüssel stellen sicher, dass alle Zeilen in Ihren Tabellen eindeutig sind. Jede Tabelle verfügt über einen oder mehrere Primärschlüssel, die definieren, was eine einzelne eindeutige Zeile in der Datenbank darstellt. Alle APIs haben einen Standardprimärschlüssel für Tabellen.
Inkrementelle Schlüssel
Panoply verwendet einen inkrementellen Schlüssel, um Attribute für das inkrementelle Laden von Daten aus Quellen in das Data Warehouse zu steuern, anstatt bei jeder Änderung den gesamten Datensatz neu zu laden. Diese Funktion ist hilfreich bei größeren Datensätzen, deren Lesen größtenteils unveränderter Daten lange dauern kann. Der inkrementelle Schlüssel gibt den letzten Aktualisierungspunkt für die Zeilen in dieser Datenquelle an.
Verschachtelte Daten
Verschachtelte Daten sind nicht vollständig kompatibel mit BI—Suites und Standard-SQL-Abfragen – Panoply behandelt verschachtelte Daten mithilfe eines stark relationalen Modells, das keine verschachtelten Werte zulässt. Panoply transformiert verschachtelte Daten auf diese Weise:
- Untertabellen: Standardmäßig wandelt Panoply verschachtelte Daten in einen Satz von Viele-zu-Viele- oder Eins-zu-Viele-Beziehungstabellen um, bei denen es sich um flache relationale Tabellen handelt.
- Reduzieren: Wenn dieser Modus aktiviert ist, reduziert Panoply die verschachtelte Struktur auf den Datensatz, der sie enthält.
Verlaufstabellen
Manchmal müssen Sie Daten analysieren, indem Sie die sich im Laufe der Zeit ändernden Daten nachverfolgen, um genau zu sehen, wie sich die Daten ändern (z. B. die Adressen von Personen).
Um solche Analysen durchzuführen, verwendet Panoply Verlaufstabellen, bei denen es sich um Zeitreihentabellen handelt, die historische Momentaufnahmen jeder Zeile in der ursprünglichen statischen Tabelle enthalten. Anschließend können Sie die ursprüngliche Tabelle oder Änderungen an der Tabelle einfach abfragen, indem Sie zu einem beliebigen Zeitpunkt zurückspulen.
Transformationen
Panoply verwendet ELT, eine Variation des ursprünglichen ETL-Datenintegrationsprozesses. Sobald Sie Daten aus der Quelle in Ihr Data Warehouse eingefügt haben, wandelt Panoply sie sofort um. Dieser Prozess bietet Ihnen Echtzeit-Datenanalyse und optimale Leistung im Vergleich zum Standard-ETL-Prozess.
Zeichenfolgenformate
Panoply analysiert Zeichenfolgenformate und behandelt sie so, als wären sie verschachtelte Objekte in den Originaldaten. Unterstützte Zeichenfolgenformate sind CSV, TSV, JSON, JSON-Line, Ruby object Format, URL Query Strings und Web Distribution Logs.
Datenschutz
Panoply basiert auf AWS und verfügt daher über die neuesten Sicherheitspatches und Verschlüsselungsfunktionen von AWS, einschließlich hardwarebeschleunigter RSA-Verschlüsselung und der spezifischen Sicherheitsfunktionen von Amazon Redshift.
Zusätzlicher Schutz kommt von der Säulenverschlüsselung, mit der Sie Ihre privaten Schlüssel verwenden können, die nicht auf den Servern von Panoply gespeichert sind.
Zugriffskontrolle
Panoply verwendet eine zweistufige Überprüfung, um unbefugten Zugriff zu verhindern, und ein Berechtigungssystem ermöglicht es Ihnen, den Zugriff auf bestimmte Tabellen, Ansichten oder Spalten einzuschränken. Die Anomalieerkennung identifiziert Abfragen, die von neuen Computern oder einem anderen Land stammen, sodass Sie diese Abfragen blockieren können, es sei denn, sie erhalten eine manuelle Genehmigung.
IP-Whitelisting
Wir empfehlen Ihnen, Verbindungen aus nicht erkannten Quellen mithilfe einer Firewall oder einer AWS-Sicherheitsgruppe zu blockieren und den Bereich der IP-Adressen, die die Datenquellen von Panoply beim Zugriff auf Ihre Datenbank immer verwenden, auf die Whitelist zu setzen.
Fazit: Traditionelle vs. Data Warehouse-Konzepte in Kürze
Zum Abschluss fassen wir die in diesem Dokument vorgestellten Konzepte zusammen.
Traditionelle Data-Warehouse-Konzepte
- Fakten und Kennzahlen: Eine Kennzahl ist eine Eigenschaft, für die Berechnungen durchgeführt werden können. Wir bezeichnen eine Sammlung von Maßnahmen als Fakten, aber manchmal werden die Begriffe synonym verwendet.
- Normalisierung: Der Prozess der Reduzierung der Menge an doppelten Daten, was zu einem speichereffizienteren Data Warehouse führt, das langsamer abzufragen ist.
- Dimension: Wird zur Kategorisierung und Kontextualisierung von Fakten und Maßnahmen verwendet, um die Analyse und Berichterstattung über diese Maßnahmen zu ermöglichen.
- Konzeptionelles Datenmodell: Definiert die kritischen High-Level-Datenentitäten und die Beziehungen zwischen ihnen.
- Logisches Datenmodell: Beschreibt Datenbeziehungen, Entitäten und Attribute in einfachem Englisch, ohne sich Gedanken darüber machen zu müssen, wie sie in Code implementiert werden.
- Physisches Datenmodell: Eine Darstellung der Implementierung des Datenentwurfs in einem bestimmten Datenbankmanagementsystem.
- Sternschema: Nimmt eine Faktentabelle und teilt ihre Informationen in denormalisierte Dimensionstabellen auf.
- Snowflake-Schema: Teilt die Faktentabelle in normalisierte Dimensionstabellen auf. Die Normalisierung reduziert Datenredundanzprobleme und verbessert die Datenintegrität, Abfragen sind jedoch komplexer.
- OLTP: Online-Transaktionsverarbeitungssysteme ermöglichen eine schnelle, transaktionsorientierte Verarbeitung mit einfachen Abfragen.
- OLAP: Online analytical Processing ermöglicht es Ihnen, komplexe Leseabfragen auszuführen und so eine detaillierte Analyse historischer Transaktionsdaten durchzuführen.
- Data Mart: Ein Datenarchiv, das sich auf ein bestimmtes Thema oder eine bestimmte Abteilung innerhalb einer Organisation konzentriert.
- Inmon-Ansatz: Der Data-Warehouse-Ansatz von Bill Inmon definiert das Data Warehouse als zentrales Datenrepository für das gesamte Unternehmen. Data Marts können aus dem Data Warehouse erstellt werden, um die analytischen Anforderungen verschiedener Abteilungen zu erfüllen.
- Kimball-Ansatz: Ralph Kimball beschreibt ein Data Warehouse als das Zusammenführen von unternehmenskritischen Data Marts, die zunächst erstellt werden, um die analytischen Anforderungen verschiedener Abteilungen zu erfüllen.
- ETL: Integriert Daten in das Data Warehouse, indem es sie aus verschiedenen Transaktionsquellen extrahiert, die Daten transformiert, um sie für die Analyse zu optimieren, und schließlich in das Data Warehouse lädt.
- ELT: Eine Variante von ETL, die Rohdaten aus den Datenquellen einer Organisation extrahiert und in das Data Warehouse lädt. Bei Bedarf wird es für Analysezwecke transformiert.
- Enterprise Data Warehouse: Die EDW konsolidiert Daten aus allen Themenbereichen rund um das Unternehmen.
Cloud-Data-Warehouse-Konzepte – Amazon Redshift als Beispiel
- Cluster: Eine Gruppe gemeinsam genutzter Computerressourcen in der Cloud.
- Knoten: Eine Rechenressource, die in einem Cluster enthalten ist. Jeder Knoten verfügt über eine eigene CPU, RAM und Festplattenspeicher.
- Säulenlagerung: Dadurch werden die Werte einer Tabelle in Spalten statt in Zeilen gespeichert, wodurch die Daten für aggregierte Abfragen optimiert werden.
- Komprimierung: Techniken zur Reduzierung der Größe gespeicherter Daten.
- Laden von Daten: Abrufen von Daten aus Quellen in das Cloud-basierte Data Warehouse. In Redshift können Sie den Befehl KOPIEREN oder einen Datenstreamingdienst verwenden.
Cloud-Data-Warehouse-Konzepte – BigQuery als Beispiel
- Serverloser Dienst: Der Cloud-Anbieter verwaltet die Zuweisung von Maschinenressourcen dynamisch basierend auf der Menge, die der Benutzer verbraucht. Der Cloud-Anbieter verbirgt Entscheidungen zur Serververwaltung und Kapazitätsplanung vor den Benutzern des Dienstes.
- Colossus File System: Ein verteiltes Dateisystem, das spaltenartige Speicher- und Datenkomprimierungsalgorithmen verwendet, um Daten für die Analyse zu optimieren.
- Dremel Execution Engine: Eine Abfrage-Engine, die massiv parallele Verarbeitung und Spaltenspeicherung verwendet, um Abfragen schnell auszuführen.
- Datenfreigabe: In einem serverlosen Dienst ist es praktisch, die freigegebenen Daten einer anderen Organisation abzufragen, ohne in die Datenspeicherung zu investieren — Sie zahlen einfach für die Abfragen.
- Streaming-Daten: Einfügen von Daten in Echtzeit in das Data Warehouse, ohne eine Last auszuführen. Sie können Daten in Stapelanforderungen streamen, bei denen es sich um mehrere API-Aufrufe handelt, die zu einer HTTP-Anforderung zusammengefasst sind.
Traditionelle vs. Cloud-Kosten-Nutzen-Analyse
| Kosten/Nutzen | Traditionell | Cloud |
| Kosten | Hohe Vorabkosten für den Kauf und die Installation eines lokalen Systems. Sie benötigen Hardware, Serverräume und Fachpersonal (das Sie laufend bezahlen). Wenn Sie sich nicht sicher sind, wie viel Speicherplatz Sie benötigen, besteht die Gefahr hoher versunkener Kosten, die nur schwer wieder hereinzuholen sind. |
Sie müssen keine Hardware oder Serverräume kaufen oder Spezialisten einstellen. Kein Risiko von versunkenen Kosten – der Kauf von mehr Speicher in der Zukunft ist einfach. Außerdem sinken die Kosten für Speicher und Rechenleistung im Laufe der Zeit. |
| Skalierbarkeit | Sobald Sie Ihre aktuellen Serverräume oder Hardwarekapazitäten ausgeschöpft haben, müssen Sie möglicherweise neue Hardware kaufen und mehr Plätze für die Unterbringung bauen / kaufen. Außerdem müssen Sie genügend Speicherplatz kaufen, um mit Spitzenzeiten fertig zu werden; daher wird der größte Teil Ihres Speichers meistens nicht verwendet. |
Sie können ganz einfach mehr Speicherplatz kaufen, wenn Sie ihn benötigen. Sie müssen oft nur für das bezahlen, was Sie verwenden, sodass das Risiko einer Überzahlung gering bis gar nicht besteht. |
| Integrationen | Da Cloud Computing die Norm ist, werden die meisten Integrationen, die Sie vornehmen möchten, Cloud-Services sein. Die Verbindung Ihres benutzerdefinierten Data Warehouses mit ihnen kann sich als schwierig erweisen. |
Da sich Cloud Data Warehouses bereits in der Cloud befinden, ist die Verbindung zu einer Reihe anderer Cloud-Services einfach. |
| Sicherheit | Sie haben die volle Kontrolle über Ihr Data Warehouse. Wenn Sie die Datenmenge, die Sie speichern, mit Amazon oder Google vergleichen, sind Sie ein kleineres Ziel für Diebe. Es ist also wahrscheinlicher, dass Sie in Ruhe gelassen werden. |
Cloud-Data-Warehouse-Anbieter verfügen über Teams mit hochqualifizierten Sicherheitsingenieuren, deren einziger Zweck es ist, ihr Produkt so sicher wie möglich zu machen. Die bekanntesten Unternehmen der Welt verwalten sie und implementieren daher erstklassige Sicherheitspraktiken. |
| Governance | Sie wissen genau, wo sich Ihre Daten befinden und können lokal darauf zugreifen. Geringeres Risiko, dass hochsensible Daten versehentlich gegen das Gesetz verstoßen, indem sie beispielsweise auf einem Cloud-Server um die Welt reisen. |
Die führenden Cloud-Data-Warehouse-Anbieter stellen sicher, dass sie Governance- und Sicherheitsgesetze wie die DSGVO einhalten. Außerdem helfen sie Ihrem Unternehmen, sicherzustellen, dass Sie konform sind. Es gab Probleme damit, genau zu wissen, wo sich Ihre Daten befinden und wohin sie sich bewegen. Diese Probleme werden aktiv angegangen und gelöst. Beachten Sie, dass das Speichern großer Mengen hochsensibler Daten in der Cloud gegen bestimmte Gesetze verstoßen kann. Dies ist ein Fall, in dem Cloud Computing für Ihr Unternehmen ungeeignet sein kann. |
| Zuverlässigkeit | Wenn Ihr lokales Data Warehouse ausfällt, liegt es in Ihrer Verantwortung, das Problem zu beheben. Ihr IT-Team hat Zugriff auf die physische Hardware und kann auf jede Softwareschicht zugreifen, um Fehler zu beheben. Dieser schnelle Zugriff kann die Lösung von Problemen erheblich beschleunigen. Es gibt jedoch keine Garantie dafür, dass Ihr Lager jedes Jahr eine bestimmte Betriebszeit hat. |
Cloud-Data-Warehouse-Anbieter garantieren ihre Zuverlässigkeit und Verfügbarkeit in ihren SLAs. Sie arbeiten auf massiv verteilten Systemen auf der ganzen Welt, also wenn es einen Fehler auf einem gibt, ist es sehr unwahrscheinlich, dass Sie betroffen sind. |
| Control | Ihr Data Warehouse ist speziell auf Ihre Bedürfnisse zugeschnitten. Theoretisch macht es, was Sie wollen, wann Sie es wollen, auf eine Weise, die Sie verstehen. | Sie haben keine vollständige Kontrolle über Ihr Data Warehouse. In den meisten Fällen ist die Kontrolle, die Sie haben, jedoch mehr als ausreichend. |
| Geschwindigkeit | Wenn Sie ein kleines Unternehmen an einem geografischen Standort mit einer kleinen Datenmenge sind, wird Ihre Datenverarbeitung schneller sein. Wir sprechen jedoch von Millisekunden vs. Sekunden, damit einige Prozesse abgeschlossen sind. Es ist unwahrscheinlich, dass ein großes Unternehmen, das in mehreren Ländern tätig ist, mit einem On-Prem-System signifikante Geschwindigkeitssteigerungen erzielt. |
Cloud-Anbieter haben in Systeme investiert und diese geschaffen, die Massively Parallel Processing (MPP), maßgeschneiderte Architektur- und Ausführungsengines sowie intelligente Datenverarbeitungsalgorithmen implementieren. Cloud Data Warehouses sind das Ergebnis jahrelanger Forschung und Tests, um Ressourcen zu schaffen, die auf Geschwindigkeit und Leistung optimiert sind. Es kann in einigen Fällen etwas langsamer sein als on-prem, aber diese Verzögerungen sind für Menschen oft vernachlässigbar (Sekunden vs. Millisekunden). |
Panoply ist ein sicherer Ort zum Speichern, Synchronisieren und Zugreifen auf alle Ihre Geschäftsdaten. Panoply kann in wenigen Minuten eingerichtet werden, erfordert keine laufende Wartung und bietet Online-Support, einschließlich des Zugriffs auf erfahrene Datenarchitekten. Testen Sie Panoply 14 Tage lang kostenlos.
Erfahren Sie mehr über Data Warehouses
- Data Warehouse-Architektur: Traditionell vs. Cloud
- Datenbank vs. Data Warehouse
- Data Mart vs. Data Warehouse