Clustering und K bedeutet: Definition & Clusteranalyse in Excel
Statistikdefinitionen > Clustering / Clusteranalyse
Was ist Clustering?
Clustering in Statistiken bezieht sich darauf, wie Daten gesammelt (“clustert”) werden, indem Faktoren wie:
- Alter.
- Haushaltsgröße.
- Einkommen.
- Oder Bildungsniveau.
Das Sortieren von Daten in Cluster führt manchmal zu einer genaueren Untersuchung der Daten. Zum Beispiel können Krebscluster auf ein Problem in der Umwelt hinweisen. Oder sie können nur ein Ergebnis der zufälligen Natur sein. Die Clusteranalyse ist in vielen Fällen subjektiv; Es hängt davon ab, was Sie als gemeinsame Fäden in den Daten wahrnehmen. Wenn Sie jemals ein Balkendiagramm erstellt haben, haben Sie wahrscheinlich bereits Cluster erstellt (auch wenn Sie es nicht so genannt haben). Für ein Balkendiagramm mit Hunderassen müssen Sie beispielsweise nach Rassen gruppieren (Siberian Husky, Border Collie, Deutscher Schäferhund …), oder ein Diagramm der Einkommensniveaus kann nach niedrigen, mittleren und hohen Einkommensniveaus gruppiert werden.
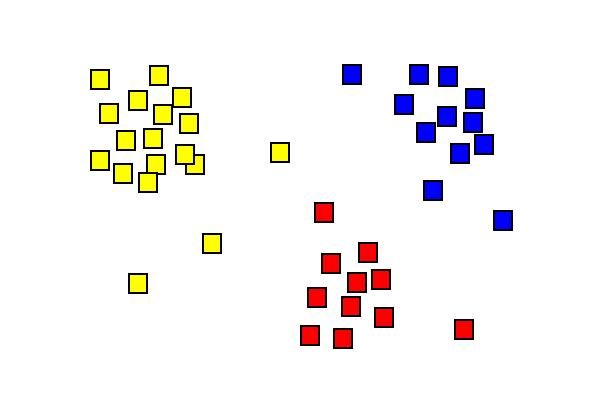
Ergebnisse der Clusteranalyse zeigen drei verschiedenfarbige Cluster.
Cluster können auf Faktoren wie:
- Entfernungsbasiertes Clustering. Die Elemente werden nach ihrer Nähe (oder Entfernung) sortiert. Beispielsweise können Krebsfälle zusammengefasst werden, wenn sie sich an demselben geografischen Ort befinden.
- Konzeptionelles Clustering. Elemente werden nach Faktoren gruppiert, die Elemente gemeinsam haben. Zum Beispiel könnten Krebscluster nach “Menschen, die in der Fertigung arbeiten” gruppiert werden.”
Clustering-Typen
- Exklusives Clustering. Jedes Element kann nur zu einem einzelnen Cluster gehören. Es kann nicht in einen anderen Cluster gehören.
- Fuzzy Clustering: Datenpunkten wird die Wahrscheinlichkeit zugewiesen, zu einem oder mehreren Clustern zu gehören.
- Überlappendes Clustering. Jedes Element kann zu mehr als einem Cluster gehören.
- Hierarchisches Clustering. Dies ist ein komplexerer Ansatz für das Clustering, der beim Data Mining verwendet wird. Grundsätzlich erhält jedes Element einen eigenen Cluster. Ein Paar von Clustern wird basierend auf Ähnlichkeiten verbunden, wodurch ein Cluster weniger entsteht. Dieser Vorgang wird wiederholt, bis alle Elemente gruppiert sind. Das Dendrogramm ist ein Diagramm, das hierarchische Cluster zeigt.
- Probabilistisches Clustering. Daten werden mithilfe von Algorithmen gruppiert, die Elemente anhand von Entfernungen oder Dichten verbinden. Dies wird normalerweise von einem Computer ausgeführt.
- Ward’s Methode: Verwendet minimale Varianz in jedem Schritt, um relativ kleine, gleichmäßige Cluster zu erstellen.
K Bedeutet Clustering
Clustering ist nur eine Möglichkeit, einen Datensatz in kleinere Mengen zu gruppieren. Die beiden Möglichkeiten, wie Sie einen Datensatz gruppieren können, sind quantitativ (unter Verwendung von Zahlen) und qualitativ (unter Verwendung von Kategorien). Zum Beispiel Bücher über Amazon.com werden sowohl nach Kategorie (qualitativ) als auch nach Bestseller (quantitativ) aufgelistet. K-Means Clustering ist einer der einfachsten unbeaufsichtigten Lernalgorithmen, der Clusterprobleme mithilfe einer quantitativen Methode löst: Sie definieren eine Reihe von Clustern vor und verwenden einen einfachen Algorithmus zum Sortieren Ihrer Daten. Das heißt, “einfach” in der Computerwelt entspricht nicht einfach im wirklichen Leben. Dies ist eigentlich ein NP-hartes Problem, daher sollten Sie Software für das K-Means-Clustering verwenden. Einige Programme, die dies für Sie ausführen (klicken Sie auf den Link für das Verfahren), sind:
- SPSS.
- r
- MATLAB
Die allgemeinen Schritte hinter dem K-Means-Clustering-Algorithmus sind:
- Untersuche die Tür (k).
- Platzieren Sie k zentrale Punkte an verschiedenen Orten (normalerweise weit voneinander entfernt).
- Nehmen Sie jeden Datenpunkt und platzieren Sie ihn in der Nähe des entsprechenden Mittelpunkts. Wiederholen, bis alle Datenpunkte zugewiesen wurden.
- Berechnen Sie k neue zentrale Punkte als Baryzentren neu.
- Wiederholen Sie die Zuordnung der Datenpunkte, diesmal zum neuen Mittelpunkt (dem Baryzentrum).
- Wiederholen Sie 4 und 5, bis sich die Mittelpunkte (Barycenters) nicht mehr bewegen.
K-Means-Clustering: Eine formellere Definition
Eine formellere Methode zur Definition von K-Means-Clustering besteht darin, n Objekte in k (k>1) vordefinierte Gruppen zu kategorisieren. Ziel ist es, die Entfernung von jedem Datenpunkt zum Cluster zu minimieren. Mit anderen Worten, zu finden: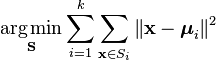
wo:
X ist ein Datenpunkt
k ist die Anzahl der Cluster
ui ist der Mittelwert der Punkte in Si.
Clusteranalyse vs. Diskriminanzanalyse
Die Clusteranalyse ist der Diskriminanzanalyse sehr ähnlich. Beide Methoden beinhalten die Trennung in Gruppen. Die Clusteranalyse ist jedoch eine Möglichkeit, die Gruppen zu identifizieren, während die Diskriminanzanalyse erfordert, dass Sie die Gruppen kennen, bevor Sie mit der Analyse beginnen. Angenommen, Sie hatten eine Gruppe psychiatrischer Patienten mit abnormalem Verhalten. Cluster-Analyse könnte Ihnen helfen, verschiedene Gruppen zu finden, wie Patienten mit einer Geschichte von Missbrauch, diejenigen mit PTSD, oder diejenigen, die Halluzinationen erleben. Wenn Sie eine Diskriminanzanalyse an derselben Personengruppe durchführen, müssen Sie die Diagnosen der Patienten kennen, bevor Sie sie in Gruppen einteilen.
Clustering in Excel
Microsoft Excel verfügt über ein Data Mining-Add-In zum Erstellen von Clustern. Eine Anleitung finden Sie hier. Der Assistent arbeitet mit Excel-Tabellen, Bereiche oder Analyse Umfrage Abfragen. Dieses Add-In kann im Gegensatz zum Tool Kategorien erkennen angepasst werden. Darüber hinaus ist das Tool Kategorien erkennen auf Daten aus Tabellen beschränkt.
Zu verwenden:
- Laden Sie das Data Mining-Add-In herunter und installieren Sie es.
- Klicken Sie auf “Data Mining”, dann auf “Cluster” und dann auf “Weiter.”
- Teilen Sie Excel mit, wo sich Ihre Daten befinden. Wählen Sie beispielsweise einen Datenbereich aus. Die Clustering-Seite wird verfügbar.
- Clustering: Belassen Sie es bei der automatischen Gruppierung, oder Sie können eine Anzahl von Gruppen angeben.
- Segmente: Für die automatische Gruppierung unverändert lassen oder eine Reihe von Kategorien angeben.
Stephanie Glen. “Clustering und K bedeutet: Definition & Clusteranalyse in Excel” From StatisticsHowTo.com: Elementare Statistiken für den Rest von uns! https://www.statisticshowto.com/clustering/
——————————————————————————
Benötigen Sie Hilfe bei einer Hausaufgabe oder Testfrage? Mit Chegg Study erhalten Sie Schritt-für-Schritt-Lösungen für Ihre Fragen von einem Experten auf diesem Gebiet. Deine ersten 30 Minuten mit einem Chegg Tutor sind kostenlos!