Almacén de Datos en la Nube vs Conceptos de Almacén de Datos Tradicionales
Los almacenes de datos basados en la nube son la nueva norma. Atrás quedaron los días en que su empresa tenía que comprar hardware, crear salas de servidores y contratar, entrenar y mantener un equipo de personal dedicado para administrarlo. Ahora, con unos pocos clics en su computadora portátil y una tarjeta de crédito, puede acceder a una potencia de computación y espacio de almacenamiento prácticamente ilimitados.
Sin embargo, esto no significa que las ideas tradicionales del almacén de datos estén muertas. La teoría clásica de los almacenes de datos sustenta la mayor parte de lo que hacen los almacenes de datos basados en la nube.
En este artículo, explicaremos los conceptos tradicionales de almacén de datos que necesita conocer y los más importantes en la nube de una selección de los principales proveedores: Amazon, Google y Panoply. Finalmente, concluiremos con un análisis de costo-beneficio de los almacenes de datos tradicionales frente a los de la nube, para que sepa cuál es el adecuado para usted.
Comencemos.
- Conceptos tradicionales de almacén de datos
- Hechos, dimensiones y medidas
- Normalización y desnormalización
- Modelos de datos
- Tabla de datos
- Esquema de estrella vs. Esquema de copo de nieve
- OLAP vs. OLTP
- Arquitectura de tres niveles
- Almacén de datos virtual / Data Mart
- Kimball vs. Inmon
- ETL vs. ELT
- Almacén de datos empresarial
- Los conceptos de almacén de datos en la nube
- Conceptos de almacén de datos en la nube: Amazon Redshift
- Clústeres
- Nodos
- Particiones/sectores
- Almacenamiento en columnas
- Compresión
- Carga de datos
- Almacén de bases de datos en la nube: Google BigQuery
- Servicio sin servidor
- Sistema de archivos Colossus
- Motor de ejecución Dremel
- Intercambio de datos
- Transmisión por secuencias e ingestión por lotes
- Conceptos de almacén de datos en la nube: Panoply
- Claves principales
- Claves incrementales
- Datos anidados
- Tablas de historial
- Transformaciones
- Formatos de cadena
- Protección de datos
- Control de acceso
- Lista blanca de IP
- Conclusión: Conceptos tradicionales vs. de Almacén de datos en breve
- Conceptos tradicionales de almacén de datos
- Conceptos de almacén de datos en la nube: Amazon Redshift como ejemplo
- Conceptos de almacén de datos en la nube – BigQuery como ejemplo
- Tradicional vs Cloud Análisis de Costo-Beneficio
- Más información sobre los Almacenes de datos
Conceptos tradicionales de almacén de datos
Un almacén de datos es cualquier sistema que recopila datos de una amplia gama de fuentes dentro de una organización. Los almacenes de datos se utilizan como repositorios de datos centralizados con fines analíticos y de presentación de informes.
Un almacén de datos tradicional se encuentra in situ en sus oficinas. Usted compra el hardware, las salas de servidores y contrata al personal para que lo ejecute. También se denominan almacenes de datos locales, locales o locales (gramaticalmente incorrectos).
Hechos, dimensiones y medidas
Los elementos básicos de la información en un almacén de datos son hechos, dimensiones y medidas.
Un hecho es la parte de sus datos que indica una ocurrencia o transacción específica. Por ejemplo, si su negocio vende flores, algunos datos que vería en su almacén de datos son:
- Vendí 30 rosas en la tienda por9 19.99
- Ordenó 500 macetas nuevas de China por $1500
- Salario pagado del cajero para este mes $1000
Varios números pueden describir cada hecho, y a estos números los llamamos medidas. Algunas medidas para describir el hecho de “ordenar 500 macetas nuevas de China por $1500” son:
- Cantidad pedida-500
- Costo – $1500
Cuando los analistas trabajan con datos, realizan cálculos de medidas (por ejemplo, suma, máximo, promedio) para obtener información. Por ejemplo, es posible que desee saber el número promedio de macetas que pide cada mes.
Una dimensión categoriza hechos y medidas y proporciona información de etiquetado estructurada para ellos; de lo contrario, ¡solo serían una colección de números desordenados! Algunas dimensiones para describir el hecho de ‘ordenar 500 macetas nuevas de China por $1500’ son:
- País de compra-China
- Hora de compra-1 p. m.
- Fecha prevista de llegada-6 de junio
No puede realizar cálculos de dimensiones explícitamente, y hacerlo probablemente no sería muy útil: ¿cómo puede encontrar la “fecha de llegada promedio para los pedidos”? Sin embargo, es posible crear nuevas medidas a partir de dimensiones, y estas son útiles. Por ejemplo, si conoce el número promedio de días entre la fecha de pedido y la fecha de llegada, puede planificar mejor las compras de existencias.
Normalización y desnormalización
La normalización es el proceso de organizar de manera eficiente los datos en un almacén de datos (o en cualquier otro lugar que almacene datos). Los objetivos principales son reducir la redundancia de datos, es decir, eliminar cualquier dato duplicado, y mejorar la integridad de los datos, es decir, mejorar la precisión de los datos. Hay diferentes niveles de normalización y no hay consenso para el “mejor” método. Sin embargo, todos los métodos implican almacenar piezas de información separadas pero relacionadas en tablas diferentes.
Hay muchos beneficios para la normalización, como:
- Búsqueda y clasificación más rápidas en cada tabla
- Las tablas más simples hacen que los comandos de modificación de datos sean más rápidos para escribir y ejecutar
- Menos datos redundantes significa que ahorra espacio en disco y, por lo tanto, puede recopilar y almacenar más datos
La desnormalización es el proceso de agregar deliberadamente copias redundantes o grupos de datos a datos ya normalizados. No es lo mismo que los datos no normalizados. La desnormalización mejora el rendimiento de lectura y facilita mucho la manipulación de tablas en los formularios que desee. Cuando los analistas trabajan con almacenes de datos, por lo general solo realizan lecturas de los datos. Por lo tanto, los datos desnormalizados pueden ahorrarles grandes cantidades de tiempo y dolores de cabeza.
Beneficios de la desnormalización:
- Menos tablas minimiza la necesidad de uniones de tablas, lo que acelera el flujo de trabajo de los analistas de datos y los lleva a descubrir información más útil en los datos
- Menos tablas Simplifica las consultas y genera menos errores
Modelos de datos
Sería muy ineficiente almacenar todos los datos en una tabla masiva. Por lo tanto, su almacén de datos contiene muchas tablas que puede unir para obtener información específica. La tabla principal se llama tabla de hechos, y las tablas de dimensiones la rodean.
El primer paso para diseñar un almacén de datos es construir un modelo de datos conceptual que defina los datos que desea y las relaciones de alto nivel entre ellos.
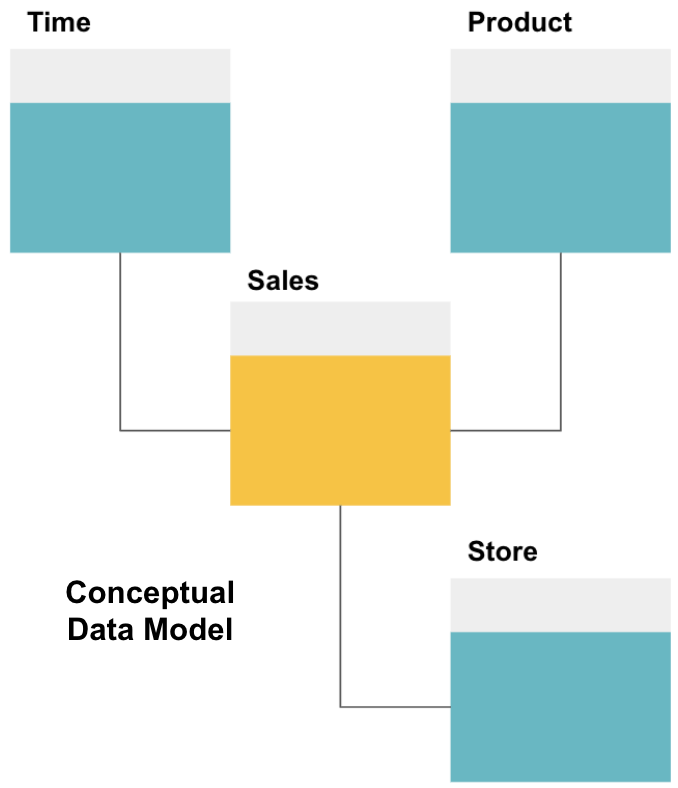
Aquí, hemos definido el modelo conceptual. Almacenamos datos de ventas y tenemos tres tablas adicionales-Hora, Producto y Tienda – que proporcionan información adicional y más detallada sobre cada venta. La tabla de hechos es Ventas, y las otras son tablas de dimensiones.
El siguiente paso es definir un modelo de datos lógico. Este modelo describe los datos en detalle en inglés sencillo sin preocuparse de cómo implementarlos en código.
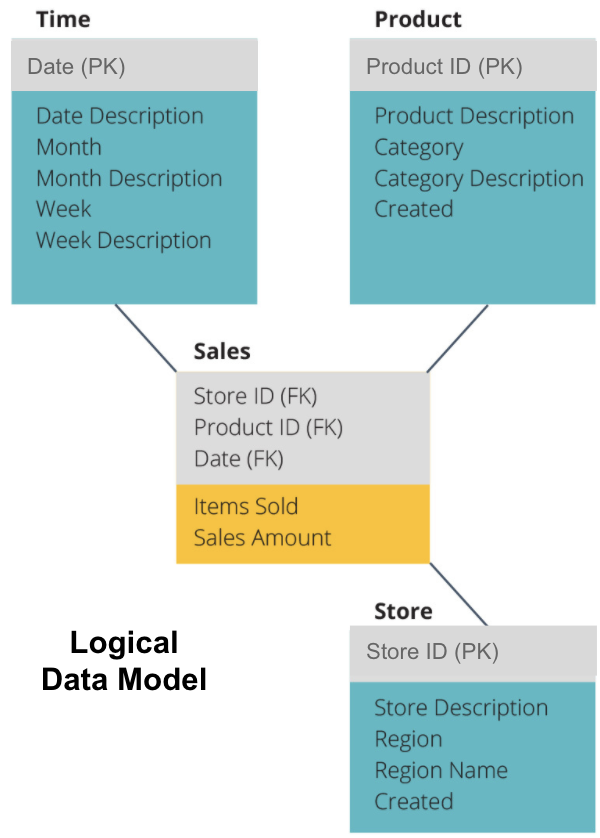
Ahora hemos rellenado la información que contiene cada tabla en un inglés sencillo. Cada una de las tablas de dimensión de Tiempo, Producto y Almacén muestra la Clave primaria (PK) en el cuadro gris y los datos correspondientes en los cuadros azules. La tabla de ventas contiene tres Claves foráneas (FK) para que pueda unirse rápidamente con las otras tablas.
La etapa final es crear un modelo de datos físicos. Este modelo le indica cómo implementar el almacén de datos en código. Define las tablas, su estructura y la relación entre ellas. También especifica los tipos de datos para las columnas, y todo se nombra como estará en el almacén de datos final, es decir, todo en mayúsculas y conectado con guiones bajos. Por último, cada tabla de dimensiones comienza con DIM_ y cada tabla de hechos comienza con FACT_.
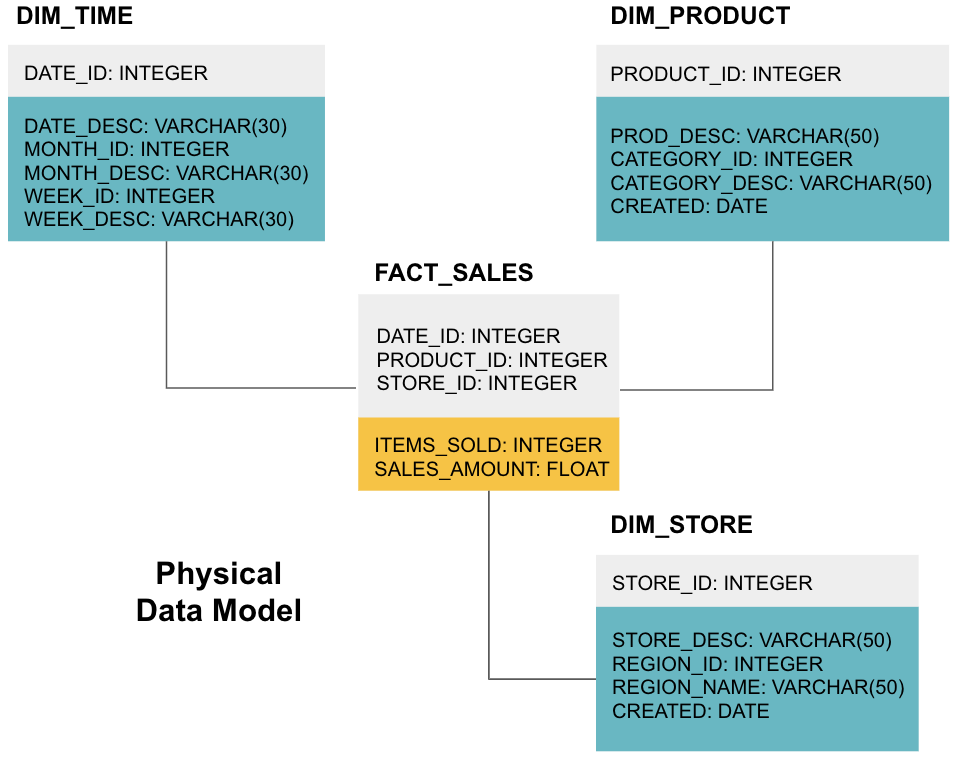
Ahora ya sabe cómo diseñar un almacén de datos, pero hay algunos matices en las tablas de hechos y dimensiones que explicaremos a continuación.
Tabla de datos
Cada función comercial, por ejemplo, ventas, marketing, finanzas, tiene una tabla de datos correspondiente.
Las tablas de hechos tienen dos tipos de columnas: columnas de dimensiones y columnas de hechos. Las columnas de dimensiones, de color gris en nuestros ejemplos, contienen claves foráneas (FK) que se utilizan para unir una tabla de hechos con una tabla de dimensiones. Estas claves foráneas son las Claves Primarias (PK) para cada una de las tablas de dimensiones. Las columnas de datos, de color amarillo en nuestros ejemplos, contienen los datos y las medidas reales que se analizarán, por ejemplo, el número de artículos vendidos y el valor total en dólares de las ventas.
Una tabla de hechos sin hechos es un tipo particular de tabla de hechos que solo tiene columnas de dimensiones. Estas tablas son útiles para el seguimiento de eventos, como la asistencia de estudiantes o la licencia de empleados, ya que las dimensiones le dicen todo lo que necesita saber sobre los eventos.
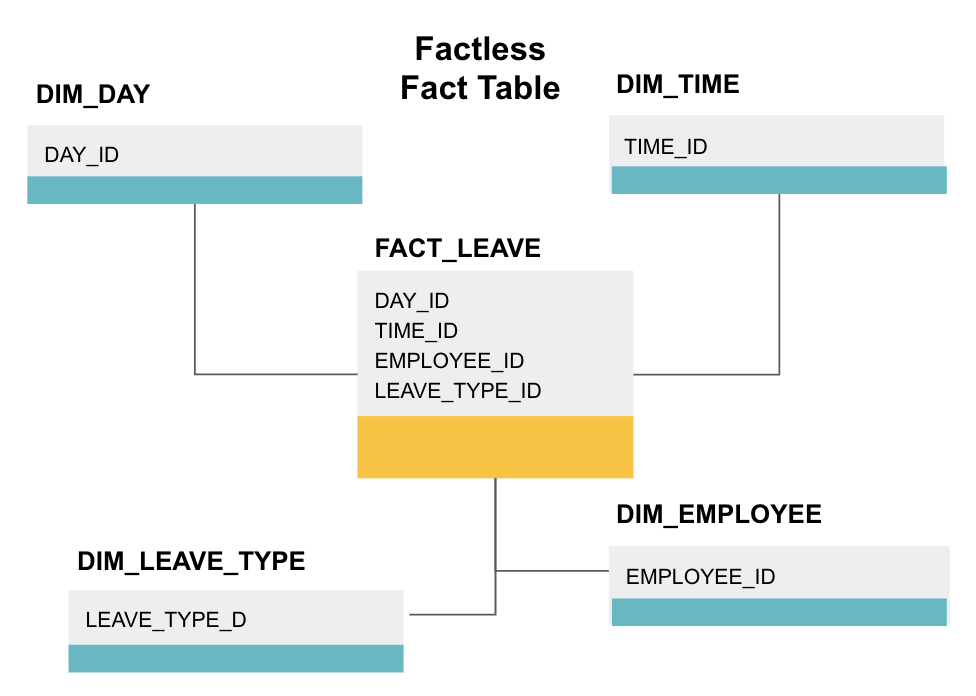
La tabla de datos sin hechos anterior rastrea la licencia de los empleados. No hay hechos, ya que solo necesita saber:
- Qué día estaban libres (DAY_ID).
- Cuánto tiempo estuvieron apagados (TIME_ID).
- Que estaba de baja (EMPLOYEE_ID).
- El motivo de su licencia, p. ej. enfermedad, vacaciones, cita con el médico, etc. (LEAVE_TYPE_ID).
Esquema de estrella vs. Esquema de copo de nieve
Los almacenes de datos anteriores tienen un diseño similar. Sin embargo, esta no es la única manera de organizarlos.
Los dos esquemas más comunes utilizados para organizar los almacenes de datos son star y snowflake. Ambos métodos utilizan tablas de dimensiones que describen la información contenida en una tabla de hechos.
El esquema star toma la información de la tabla fact y la divide en tablas de dimensiones desnormalizadas. El énfasis del esquema star está en la velocidad de consulta. Solo se necesita una unión para vincular las tablas de hechos a cada dimensión, por lo que consultar cada tabla es fácil. Sin embargo, dado que las tablas están desnormalizadas, a menudo contienen datos repetidos y redundantes.
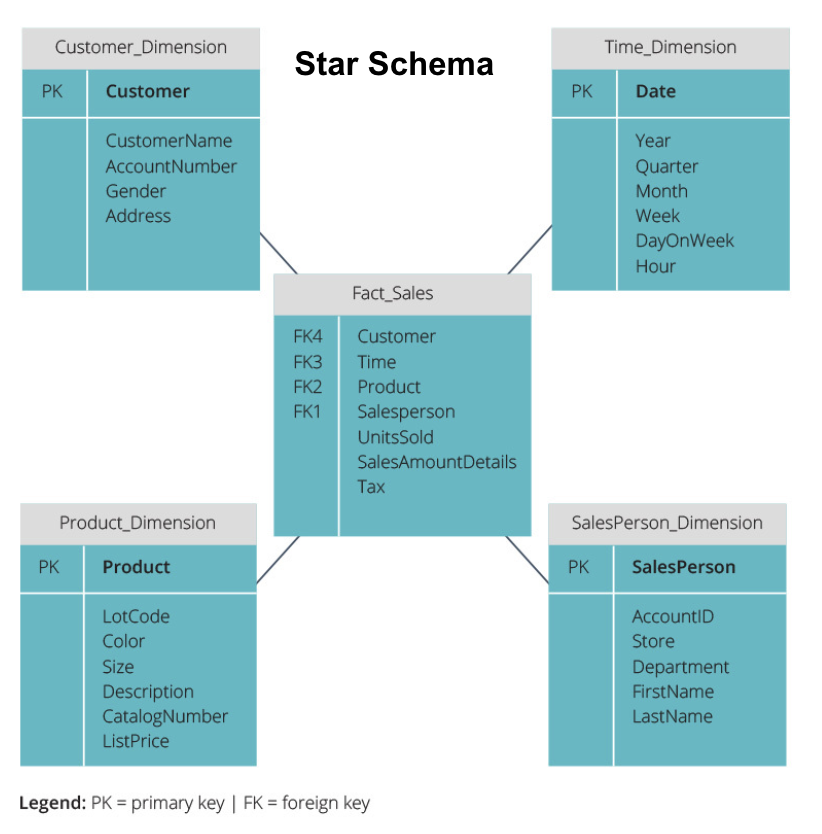
El esquema de copo de nieve divide la tabla de hechos en una serie de tablas de dimensiones normalizadas. La normalización crea más tablas de dimensiones y, por lo tanto, reduce los problemas de integridad de los datos. Sin embargo, las consultas son más difíciles con el esquema de copo de nieve porque necesita más uniones de tabla para acceder a los datos relevantes. Por lo tanto, tiene menos datos redundantes, pero es más difícil acceder a ellos.
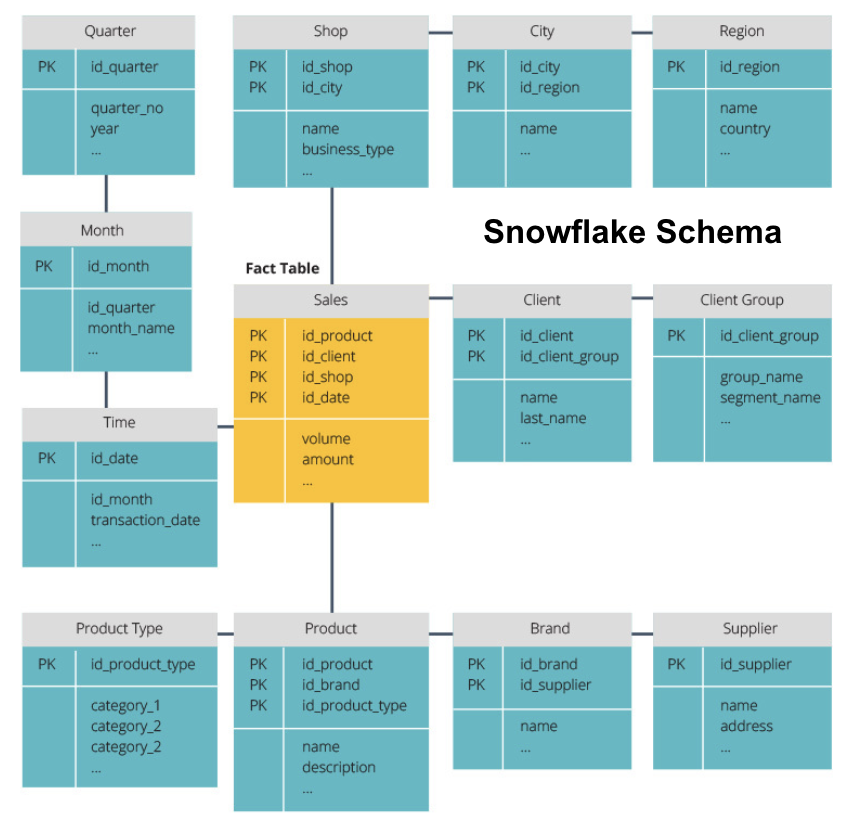
Ahora explicaremos algunos conceptos más fundamentales del almacén de datos.
OLAP vs. OLTP
El procesamiento de transacciones en línea (OLTP) se caracteriza por transacciones de escritura corta que involucran las aplicaciones front-end de la arquitectura de datos de una empresa. Las bases de datos OLTP enfatizan el procesamiento rápido de consultas y solo se ocupan de los datos actuales. Las empresas los utilizan para capturar información para los procesos empresariales y proporcionar datos de origen para el almacén de datos.
El procesamiento analítico en línea (OLAP) le permite ejecutar consultas de lectura complejas y, por lo tanto, realizar un análisis detallado de los datos transaccionales históricos. Los sistemas OLAP ayudan a analizar los datos en el almacén de datos.
Arquitectura de tres niveles
Los almacenes de datos tradicionales suelen estructurarse en tres niveles:
- Nivel inferior: Un servidor de base de datos, normalmente un RDBMS, que extrae datos de diferentes fuentes mediante una puerta de enlace. Las fuentes de datos que se incorporan a este nivel incluyen bases de datos operativas y otros tipos de datos de interfaz, como archivos CSV y JSON.
- Nivel medio: Un servidor OLAP que
- Implementa directamente las operaciones, o
- Asigna las operaciones en datos multidimensionales a operaciones relacionales estándar, por ejemplo, aplanar datos XML o JSON en filas dentro de tablas.
- Nivel superior: Las herramientas de consulta y generación de informes para el análisis de datos y la inteligencia de negocios.
Almacén de datos virtual / Data Mart
El almacenamiento de datos virtual utiliza consultas distribuidas en varias bases de datos, sin integrar los datos en un almacén de datos físico.
Los Data marts son subconjuntos de almacenes de datos orientados a funciones empresariales específicas, como ventas o finanzas. Un almacén de datos generalmente combina información de varios data marts en múltiples funciones empresariales. Sin embargo, un data mart contiene datos de un conjunto de sistemas de origen para una función empresarial.
Kimball vs. Inmon
Hay dos enfoques para el diseño del almacén de datos, propuestos por Bill Inmon y Ralph Kimball. Bill Inmon es un informático estadounidense reconocido como el padre del almacén de datos. Ralph Kimball es uno de los arquitectos originales del almacenamiento de datos y ha escrito varios libros sobre el tema.
Los dos expertos tenían opiniones contradictorias sobre cómo debían estructurarse los almacenes de datos. Este conflicto ha dado lugar a dos escuelas de pensamiento.
El enfoque Inmon es un diseño de arriba hacia abajo. Con la metodología Inmon, el almacén de datos se crea primero y se considera el componente central del entorno analítico. A continuación, los datos se resumen y distribuyen desde el almacén centralizado a uno o más centros de datos dependientes.
El enfoque de Kimball toma una vista ascendente del diseño del almacén de datos. En esta arquitectura, una organización crea mercados de datos separados, que proporcionan vistas a departamentos individuales dentro de una organización. El almacén de datos es la combinación de estos data marts.
ETL vs. ELT
Extraer, transformar, cargar (ETL) describe el proceso de extraer los datos de los sistemas de origen (típicamente sistemas transaccionales), convertir los datos a un formato o estructura adecuada para consultas y análisis, y finalmente cargarlos en el almacén de datos. ETL aprovecha una base de datos provisional separada y aplica una serie de reglas o funciones a los datos extraídos antes de la carga.
Extraer, cargar, Transformar (ELT) es un enfoque diferente para cargar datos. ELT toma los datos de fuentes dispares y los carga directamente en el sistema de destino, como el almacén de datos. A continuación, el sistema transforma los datos cargados bajo demanda para permitir el análisis.
ELT ofrece una carga más rápida que ETL, pero requiere un sistema potente para realizar las transformaciones de datos bajo demanda.
Almacén de datos empresarial
Un almacén de datos empresarial está concebido como un almacén unificado y centralizado que contiene toda la información transaccional de la organización, tanto actual como histórica. Un almacén de datos empresarial debe incorporar datos de todas las áreas temáticas relacionadas con el negocio, como marketing, ventas, finanzas y recursos humanos.
Estas son las ideas centrales que componen los almacenes de datos tradicionales. Ahora, veamos qué almacenes de datos en la nube han agregado encima de ellos.
Los conceptos de almacén de datos en la nube
Los almacenes de datos en la nube son nuevos y cambian constantemente. Para comprender mejor sus conceptos fundamentales, lo mejor es aprender sobre las principales soluciones de almacenamiento de datos en la nube.
Tres soluciones líderes de almacenamiento de datos en la nube son Amazon Redshift, Google BigQuery y Panoply. A continuación, explicamos conceptos fundamentales de cada uno de estos servicios para proporcionarle una comprensión general de cómo funcionan los almacenes de datos modernos.
Conceptos de almacén de datos en la nube: Amazon Redshift
Los siguientes conceptos se utilizan explícitamente en el almacén de datos en la nube de Amazon Redshift, pero pueden aplicarse a soluciones de almacén de datos adicionales en el futuro basadas en la infraestructura de Amazon.
Clústeres
Amazon Redshift basa su arquitectura en clústeres. Un clúster es simplemente un grupo de recursos informáticos compartidos, llamados nodos.
Nodos
Los nodos son recursos informáticos que tienen CPU, RAM y espacio en disco duro. Un clúster que contiene dos o más nodos se compone de un nodo líder y nodos de cómputo.
Los nodos Leader se comunican con los programas cliente y compilan código para ejecutar consultas, asignándolo a nodos de cómputo. Los nodos de cómputo ejecutan las consultas y devuelven los resultados al nodo líder. Un nodo de cómputo solo ejecuta consultas que hacen referencia a tablas almacenadas en ese nodo.
Particiones/sectores
Amazon divide cada nodo de cómputo en sectores. Un sector recibe una asignación de memoria y espacio en disco en el nodo. Múltiples sectores operan en paralelo para acelerar el tiempo de ejecución de la consulta.
Almacenamiento en columnas
Redshift utiliza almacenamiento en columnas, lo que permite un mejor rendimiento de las consultas analíticas. En lugar de almacenar registros en filas, almacena valores de una sola columna para varias filas. Los siguientes diagramas lo aclaran:
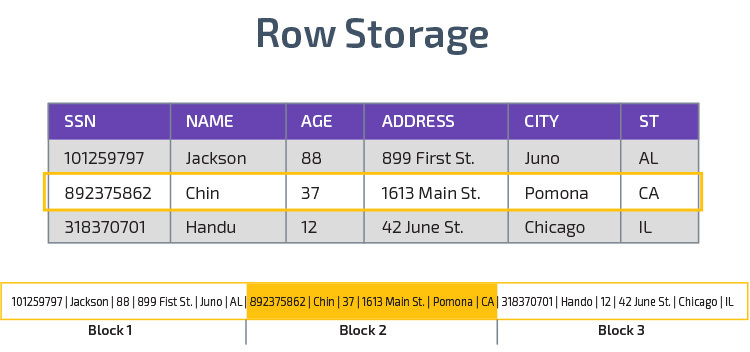
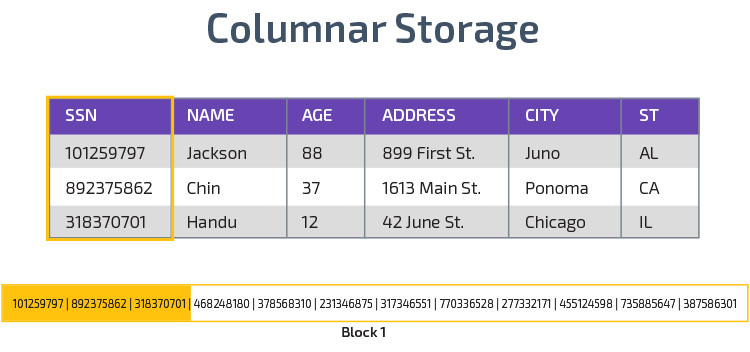
El almacenamiento en columnas permite leer datos más rápido, lo que es crucial para consultas analíticas que abarcan muchas columnas en un conjunto de datos. El almacenamiento en columnas también ocupa menos espacio en disco, ya que cada bloque contiene el mismo tipo de datos, lo que significa que se puede comprimir en un formato específico.
Compresión
La compresión reduce el tamaño de los datos almacenados. En corrimiento al rojo, debido a la forma en que se almacenan los datos, la compresión se produce a nivel de columna. Redshift le permite comprimir información manualmente al crear una tabla, o automáticamente mediante el comando COPIAR.
Carga de datos
Puede usar el comando COPIAR de Redshift para cargar grandes cantidades de datos en el almacén de datos. El comando COPIAR aprovecha la arquitectura MPP de Redshift para leer y cargar datos en paralelo desde archivos en Amazon S3, desde una tabla de DynamoDB o salida de texto desde uno o más hosts remotos.
También es posible transmitir datos a Redshift mediante el servicio Amazon Kinesis Firehose.
Almacén de bases de datos en la nube: Google BigQuery
Los siguientes conceptos se utilizan explícitamente en el almacén de datos en la nube de Google BigQuery, pero pueden aplicarse a soluciones adicionales en el futuro basadas en la infraestructura de Google.
Servicio sin servidor
BigQuery utiliza arquitectura sin servidor. Con BigQuery, las empresas no necesitan administrar unidades de servidor físico para ejecutar sus almacenes de datos. En su lugar, BigQuery administra dinámicamente la asignación de sus recursos informáticos. Las empresas que utilizan el servicio simplemente pagan por el almacenamiento de datos por gigabyte y las consultas por terabyte.
Sistema de archivos Colossus
BigQuery utiliza la última versión del sistema de archivos distribuido de Google, con el nombre en código Colossus. El sistema de archivos Colossus utiliza algoritmos de compresión y almacenamiento en columnas para almacenar datos con fines analíticos de manera óptima.
Motor de ejecución Dremel
El motor de ejecución Dremel utiliza un diseño en columnas para consultar grandes almacenes de datos rápidamente. El motor de ejecución de Dremel puede ejecutar consultas ad hoc en miles de millones de filas en segundos porque utiliza un procesamiento paralelo masivo en forma de arquitectura de árbol.
La arquitectura de árbol distribuye consultas entre varios servidores intermedios desde un servidor raíz. Los servidores intermedios envían la consulta a servidores hoja (que contienen datos almacenados), que escanean los datos en paralelo. En el camino de regreso al árbol, cada servidor hoja envía resultados de consulta, y los servidores intermedios realizan una agregación paralela de resultados parciales.
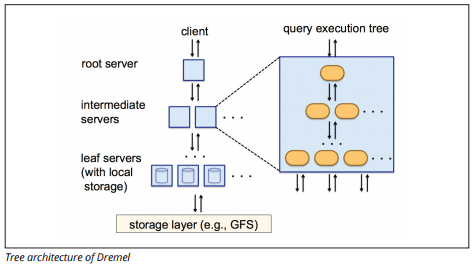
Fuente de imagen
Dremel permite a las organizaciones ejecutar consultas en hasta decenas de miles de servidores simultáneamente. Según Google, Dremel puede escanear 35 mil millones de filas sin un índice en decenas de segundos.
Intercambio de datos
La arquitectura sin servidor de Google BigQuery permite a las empresas compartir datos fácilmente con otras organizaciones sin necesidad de que estas inviertan en su propio almacenamiento.
Las organizaciones que deseen consultar datos compartidos pueden hacerlo, y solo pagarán por las consultas. No es necesario crear costosos silos de datos compartidos, externos a la infraestructura de datos de la organización, y copiar los datos a esos silos.
Transmisión por secuencias e ingestión por lotes
Es posible cargar datos en BigQuery desde el almacenamiento en la nube de Google, incluidos archivos CSV, JSON (delimitados por una nueva línea) y Avro, así como copias de seguridad del almacén de datos de Google Cloud. También puede cargar datos directamente desde una fuente de datos legible.
BigQuery también ofrece una API de streaming para cargar datos en el sistema a una velocidad de millones de filas por segundo sin realizar una carga. Los datos están disponibles para su análisis casi de inmediato.
Conceptos de almacén de datos en la nube: Panoply
Panoply es un almacén todo en uno que combina ETL con un potente almacén de datos. Es la forma más fácil de sincronizar, almacenar y acceder a los datos de una empresa al eliminar el desarrollo y la codificación asociados con la transformación, integración y administración de big data.
A continuación se muestran algunos de los conceptos principales del almacén de datos Panoply relacionados con el modelado de datos y la protección de datos.
Claves principales
Las claves principales garantizan que todas las filas de las tablas sean únicas. Cada tabla tiene una o más claves primarias que definen lo que representa una sola fila única en la base de datos. Todas las API tienen una clave primaria predeterminada para las tablas.
Claves incrementales
Panoply utiliza una clave incremental para controlar atributos para cargar datos de forma incremental en el almacén de datos desde fuentes en lugar de recargar todo el conjunto de datos cada vez que algo cambia. Esta función es útil para conjuntos de datos más grandes, que pueden tardar mucho tiempo en leer los datos casi sin cambios. La clave incremental indica el último punto de actualización para las filas de esa fuente de datos.
Datos anidados
Los datos anidados no son totalmente compatibles con suites BI y consultas SQL estándar: Panoply se ocupa de los datos anidados mediante el uso de un modelo fuertemente relacional que no permite valores anidados. Panoply transforma los datos anidados de estas maneras:
- Subtablas: De forma predeterminada, Panoply transforma los datos anidados en un conjunto de tablas de relación de muchos a muchos o de uno a muchos, que son tablas relacionales planas.
- Aplanamiento: Con este modo habilitado, Panoply aplana la estructura anidada en el registro que la contiene.
Tablas de historial
A veces es necesario analizar los datos haciendo un seguimiento de los cambios de datos a lo largo del tiempo para ver exactamente cómo cambian los datos (por ejemplo, las direcciones de las personas).
Para realizar estos análisis, Panoply utiliza tablas de historial, que son tablas de series temporales que contienen instantáneas históricas de cada fila de la tabla estática original. A continuación, puede realizar consultas directas de la tabla original o revisiones de la tabla rebobinando a cualquier punto del tiempo.
Transformaciones
Panoply utiliza ELT, que es una variación del proceso de integración de datos ETL original. Una vez que haya inyectado datos del origen en su almacén de datos, Panoply los transforma inmediatamente. Este proceso le ofrece análisis de datos en tiempo real y un rendimiento óptimo en comparación con el proceso ETL estándar.
Formatos de cadena
Panoply analiza los formatos de cadena y los maneja como si fueran objetos anidados en los datos originales. Los formatos de cadena admitidos son CSV, TSV, JSON, línea JSON, formato de objeto Ruby, cadenas de consulta de URL y registros de distribución web.
Protección de datos
Panoply está construido sobre AWS, por lo que cuenta con las últimas funciones de cifrado y parches de seguridad proporcionados por AWS, incluido el cifrado RSA acelerado por hardware y el conjunto específico de características de seguridad de Amazon Redshift.
La protección adicional proviene del cifrado en columnas, que le permite usar sus claves privadas que no están almacenadas en los servidores de Panoply.
Control de acceso
Panoply utiliza la verificación en dos pasos para evitar el acceso no autorizado, y un sistema de permisos le permite restringir el acceso a tablas, vistas o columnas específicas. La detección de anomalías identifica consultas procedentes de equipos nuevos o de un país diferente, lo que le permite bloquear esas consultas a menos que reciban aprobación manual.
Lista blanca de IP
Le recomendamos que bloquee las conexiones de fuentes no reconocidas mediante un firewall o un grupo de seguridad de AWS y que incluya en la lista blanca el rango de direcciones IP que las fuentes de datos de Panoply siempre usan al acceder a su base de datos.
Conclusión: Conceptos tradicionales vs. de Almacén de datos en breve
Para concluir, resumiremos los conceptos presentados en este documento.
Conceptos tradicionales de almacén de datos
- Hechos y medidas: una medida es una propiedad en la que se pueden realizar cálculos. Nos referimos a una colección de medidas como hechos, pero a veces los términos se usan indistintamente.
- Normalización: el proceso de reducir la cantidad de datos duplicados, lo que conduce a un almacén de datos más eficiente en memoria que es más lento de consultar.Dimensión
- : Se utiliza para categorizar y contextualizar hechos y medidas, lo que permite el análisis y la presentación de informes sobre esas medidas.
- Modelo de datos conceptual: Define las entidades de datos críticos de alto nivel y las relaciones entre ellas.
- Modelo de datos lógicos: Describe relaciones de datos, entidades y atributos en un lenguaje sencillo sin preocuparse por cómo implementarlos en código.
- Modelo de datos físicos: Una representación de cómo implementar el diseño de datos en un sistema de gestión de base de datos específico.
- Esquema de estrellas: Toma una tabla de hechos y divide su información en tablas de dimensiones desnormalizadas.
- Esquema de copo de nieve: Divide la tabla de hechos en tablas de dimensiones normalizadas. La normalización reduce los problemas de redundancia de datos y mejora la integridad de los datos, pero las consultas son más complejas.
- OLTP: Los sistemas de procesamiento de transacciones en línea facilitan un procesamiento rápido y orientado a las transacciones con consultas simples.
- OLAP: El procesamiento analítico en línea le permite ejecutar consultas de lectura complejas y, por lo tanto, realizar un análisis detallado de los datos transaccionales históricos.
- Data mart: un archivo de datos centrado en un tema o departamento específico dentro de una organización.
- Enfoque de Inmon: El enfoque de almacén de datos de Bill Inmon define el almacén de datos como el repositorio de datos centralizado para toda la empresa. Los Data marts se pueden construir desde el almacén de datos para satisfacer las necesidades analíticas de diferentes departamentos.
- Enfoque de Kimball: Ralph Kimball describe un almacén de datos como la fusión de data marts de misión crítica, que se crean primero para satisfacer las necesidades analíticas de diferentes departamentos.
- ETL: Integra los datos en el almacén de datos extrayéndolos de varias fuentes transaccionales, transformando los datos para optimizarlos para su análisis y, finalmente, cargándolos en el almacén de datos.
- ELT: Una variación de ETL que extrae datos sin procesar de las fuentes de datos de una organización y los carga en el almacén de datos. Cuando es necesario, se transforma para fines analíticos.
- Almacén de datos empresarial: El EDW consolida datos de todas las áreas temáticas relacionadas con la empresa.
Conceptos de almacén de datos en la nube: Amazon Redshift como ejemplo
- Clúster: Un grupo de recursos informáticos compartidos basados en la nube.Nodo
- : Un recurso informático contenido dentro de un clúster. Cada nodo tiene su propia CPU, RAM y espacio en disco duro.Almacenamiento en columnas
- : Almacena los valores de una tabla en columnas en lugar de filas, lo que optimiza los datos para consultas agregadas.Compresión
- : Técnicas para reducir el tamaño de los datos almacenados.
- Carga de datos: Obtención de datos de fuentes en el almacén de datos basado en la nube. En Redshift, puede usar el comando COPIAR o un servicio de transmisión de datos.
Conceptos de almacén de datos en la nube – BigQuery como ejemplo
- Servicio sin servidor: El proveedor de nube administra dinámicamente la asignación de recursos de la máquina en función de la cantidad que consume el usuario. El proveedor de nube oculta las decisiones de administración de servidores y planificación de la capacidad de los usuarios del servicio.
- Sistema de archivos Colossus: Un sistema de archivos distribuido que utiliza algoritmos de almacenamiento en columnas y compresión de datos para optimizar los datos para su análisis.
- Motor de ejecución Dremel: Un motor de consultas que utiliza procesamiento paralelo masivo y almacenamiento en columnas para ejecutar consultas rápidamente.
- Intercambio de datos :En un servicio sin servidor, es práctico consultar los datos compartidos de otra organización sin invertir en almacenamiento de datos; simplemente paga por las consultas.
- Transmisión de datos: Insertar datos en tiempo real en el almacén de datos sin realizar una carga. Puede transmitir datos en solicitudes por lotes, que son varias llamadas a la API combinadas en una solicitud HTTP.
Tradicional vs Cloud Análisis de Costo-Beneficio
| Costo/Beneficio | Tradicional | en la Nube |
| Costo | Gran costo inicial para comprar e instalar un prem sistema. Necesita hardware, salas de servidores y personal especializado (que paga de forma continua). Si no está seguro de cuánto espacio de almacenamiento necesita, existe el riesgo de altos costos hundidos que son difíciles de recuperar. |
No es necesario comprar hardware, salas de servidores ni contratar especialistas. Sin riesgo de costos hundidos: comprar más almacenamiento en el futuro es fácil. Además, el costo del almacenamiento y la potencia de cómputo están disminuyendo con el tiempo. |
| Escalabilidad | Una vez que maximice la capacidad de sus salas de servidores o hardware actuales, es posible que tenga que comprar hardware nuevo y construir/comprar más lugares para alojarlo. Además, necesita comprar suficiente espacio de almacenamiento para hacer frente a las horas punta; por lo tanto, la mayoría de las veces, la mayor parte de su almacenamiento no se utiliza. |
Puede comprar fácilmente más almacenamiento cuando lo necesite. A menudo solo tiene que pagar por lo que usa, por lo que hay poco o ningún riesgo de pagar de más. |
| Integraciones | Como la computación en la nube es la norma, la mayoría de las integraciones que desea realizar serán para servicios en la nube. Conectar su almacén de datos personalizado a ellos puede resultar difícil. |
Como los almacenes de datos en la nube ya están en la nube, conectarse a una gama de otros servicios en la nube es sencillo. |
| Seguridad | Usted tiene el control total de su almacén de datos. Comparando la cantidad de datos que alojas con Amazon o Google, eres un blanco más pequeño para los ladrones. Por lo tanto, es más probable que lo dejen solo. |
Los proveedores de almacenes de datos en la nube tienen equipos llenos de ingenieros de seguridad altamente calificados cuyo único propósito es hacer que su producto sea lo más seguro posible. Las empresas más destacadas del mundo las gestionan y, por lo tanto, implementan prácticas de seguridad de clase mundial. |
| Gobierno | Usted sabe exactamente dónde están sus datos y puede acceder a ellos localmente. Menos riesgo de que los datos altamente confidenciales infrinjan inadvertidamente la ley, por ejemplo, viajando por todo el mundo en un servidor en la nube. |
Los principales proveedores de almacenamiento de datos en la nube se aseguran de cumplir con las leyes de gobernanza y seguridad, como el RGPD. Además, ayudan a su empresa a asegurarse de que cumple con las normas. Ha habido problemas con respecto a saber exactamente dónde están sus datos y dónde se mueven. Estos problemas se están abordando y resolviendo activamente. Tenga en cuenta que almacenar grandes cantidades de datos altamente confidenciales en la nube puede ir en contra de leyes específicas. Este es un caso en el que la computación en la nube puede ser inapropiada para su negocio. |
| Fiabilidad | Si su prem almacén de datos falla, es su responsabilidad para solucionarlo. Su equipo de TI tiene acceso al hardware físico y puede acceder a todas las capas de software para solucionar problemas. Este acceso rápido puede hacer que la resolución de problemas sea mucho más rápida. Sin embargo, no hay garantía de que su almacén tenga una cantidad particular de tiempo de actividad cada año. |
Los proveedores de almacenes de datos en la nube garantizan su fiabilidad y tiempo de actividad en sus acuerdos de nivel de servicio. Operan en sistemas distribuidos masivamente en todo el mundo, por lo que si hay un fallo en uno, es muy poco probable que le afecte. |
| Control | Su almacén de datos está hecho a medida para satisfacer sus necesidades. En teoría, hace lo que quieres que haga, cuando lo quieres, de una manera que entiendes. | No tiene control total sobre su almacén de datos. Sin embargo, la mayoría de las veces, el control que tienes es más que suficiente. |
| Velocidad | Si usted es una empresa pequeña en una ubicación geográfica con una pequeña cantidad de datos, su procesamiento de datos será más rápido. Sin embargo, estamos hablando de milisegundos vs segundos para que algunos procesos se completen. Es poco probable que una gran empresa que opera en varios países vea ganancias de velocidad significativas con un sistema local. |
Los proveedores de la nube han invertido y creado sistemas que implementan Procesamiento Paralelo Masivo (MPP), motores de arquitectura y ejecución personalizados y algoritmos de procesamiento de datos inteligentes. Los almacenes de datos en la nube son el resultado de años de investigación y pruebas para crear recursos optimizados para la velocidad y el rendimiento. En algunos casos, puede ser ligeramente más lento que en el prem, pero estos retrasos a menudo son insignificantes para los seres humanos (segundos frente a milisegundos). |
Panoply es un lugar seguro para almacenar, sincronizar y acceder a todos los datos de su empresa. Panoply se puede configurar en minutos, no requiere mantenimiento continuo y proporciona soporte en línea, incluido el acceso a arquitectos de datos experimentados. Pruebe Panoply gratis durante 14 días.
Más información sobre los Almacenes de datos
- Arquitectura de almacén de datos: Tradicional vs. Cloud
- Base de datos vs. Almacén de datos
- Data Mart vs. Almacén de datos