Búsqueda común: El proyecto de código abierto recuperando PageRank
Regístrate en nuestros resúmenes diarios del cambiante panorama del marketing de búsqueda.
Nota: Al enviar este formulario, usted acepta los términos de Third Door Media. Respetamos su privacidad.

En los últimos años, Google ha reducido lentamente la cantidad de datos disponibles para los profesionales de SEO. Primero fueron los datos de palabras clave, luego la puntuación del PageRank. Ahora es un volumen de búsqueda específico de AdWords(a menos que estés gastando algo de dinero). Puedes leer más sobre esto en el excelente artículo de Russ Jones que detalla el impacto de la investigación de su empresa y los conocimientos sobre los datos de flujo de clics para la desambiguación del volumen.
Un elemento en el que nos hemos involucrado realmente recientemente es Common Crawl data. Hay varios equipos en nuestra industria que han estado usando estos datos durante algún tiempo, así que me sentí un poco tarde para el juego. Common Crawl data es un proyecto de código abierto que raspa todo Internet a intervalos regulares. Afortunadamente, Amazon, al ser la gran compañía que es, ayudó a almacenar los datos para ponerlos a disposición de muchos sin los altos costos de almacenamiento.
Además de los datos de rastreo Comunes, existe una organización sin fines de lucro llamada Búsqueda común cuya misión es crear un motor de búsqueda transparente y de código abierto alternativo, lo contrario, en muchos aspectos, de Google. Esto despertó mi interés porque significa que todos podemos jugar, modificar y destrozar las señales para aprender cómo funcionan los motores de búsqueda sin la enorme inversión de tiempo de comenzar desde cero.
Common Search data
Actualmente, Common Search utiliza las siguientes fuentes de datos para calcular sus rankings de búsqueda (esto se toma directamente de su sitio web):
- Rastreo común: El repositorio abierto más grande de datos de rastreo web. Esta es actualmente nuestra fuente única de datos de página sin procesar.
- Wikidata: Una base de datos enlazada gratuita que actúa como almacenamiento central para los datos estructurados de muchos proyectos de Wikimedia como Wikipedia, Wikivoyage y Wikisource.
- Lista negra UT1: Mantenida por Fabrice Prigent de la Université Toulouse 1 Capitole, esta lista negra categoriza los dominios y las URL en varias categorías, incluidas “adulto” y “phishing”.”
- ODP: También conocido como el proyecto Open Directory, es el directorio web más antiguo y más grande que aún está vivo. Aunque sus datos no son tan fiables como en el pasado, todavía los usamos como fuente de señales y metadatos.
- Gráficos de hipervínculos de Web Data Commons: Gráficos de todos los hipervínculos de un archivo de rastreo común de 2012. Actualmente estamos utilizando su archivo de Centralidad Armónica como una señal de clasificación temporal en dominios. Planeamos realizar nuestro propio análisis del gráfico web en un futuro próximo.
- Alexa top 1M sites: Alexa clasifica los sitios web en función de una medida combinada de vistas de página y usuarios únicos del sitio. Se sabe que está demográficamente sesgado. Lo estamos usando como una señal de clasificación temporal en dominios.
Clasificación de búsqueda común
Además de estas fuentes de datos, en la investigación del código, también utiliza la longitud de URL, la longitud de ruta y el PageRank de dominio como señales de clasificación en su algoritmo. He aquí, desde julio, Common Search ha tenido sus propios datos en el PageRank a nivel de host, y todos nos lo perdimos.
Llegaré al PageRank (PR) en un momento, pero es interesante revisar el código de Rastreo Común, especialmente el ranker.la parte py se encuentra aquí, porque realmente puedes sentarte en el asiento del conductor ajustando el peso de las señales que usa para clasificar las páginas:
signal_weights = {"url_total_length": 0.01,"url_path_length": 0.01,"url_subdomain": 0.1,"alexa_top1m": 5,"wikidata_url": 3,"dmoz_domain": 1,"dmoz_url": 1,"webdatacommons_hc": 1,"commonsearch_host_pagerank": 1}
De particular interés, también, es que la búsqueda Común utiliza BM25 como la medida de similitud de la palabra clave con el cuerpo del documento y los metadatos. BM25 es una mejor medida que TF-IDF porque tiene en cuenta la longitud del documento, lo que significa que un documento de 200 palabras que tenga su palabra clave cinco veces es probablemente más relevante que un documento de 1500 palabras que lo tenga el mismo número de veces.
También vale la pena decir que el número de señales aquí es muy rudimentario y obviamente le faltan muchos de los refinamientos (y datos) que Google ha integrado en su algoritmo de ranking de búsqueda. Una de las cosas clave en las que estamos trabajando es usar los datos disponibles en Common Crawl y la infraestructura de Búsqueda Común para hacer búsquedas de vectores de temas para contenido que sea relevante en función de la semántica, no solo de la coincidencia de palabras clave.
En el PageRank
En la página aquí, puedes encontrar enlaces al PageRank a nivel de host para el Rastreo Común de junio de 2016. Estoy usando el que se titula pagerank-top1m.txt.gz (top 1 millón) porque el otro archivo tiene 3 GB y más de 112 millones de dominios. Incluso en R, no tengo suficiente máquina para cargarla sin tapar.
Después de la descarga, deberá traer el archivo a su directorio de trabajo en R. Los datos del PageRank de Búsqueda común no están normalizados y tampoco están en el formato limpio 0-10 en el que todos estamos acostumbrados a verlo. Usos comunes de búsqueda ” max (0, min(1, float (rank) / 244660.58)) ” – básicamente, el rango de un dominio dividido por el rango de Facebook – como el método de traducir los datos en una distribución entre 0 y 1. Pero esto deja algunas brechas definidas, ya que esto dejaría el PageRank de Linkedin como un 1.4 cuando se escala en 10.

El siguiente código cargará el conjunto de datos y agregará una columna de relaciones públicas con una mejor aproximación a las relaciones públicas:
#Grab the datadf <- read.csv("pagerank-top1m.txt", header = F, sep = " ")#Log NormalizelogNorm <- function(x){ #Normalize x <- (x-min(x))/(max(x)-min(x)) 10 / (1 - (log10(x)*.25))}#Append a Column named PR to the datasetdf$pr <- (round(logNorm(df$V2),digits = 0))
Tuvimos que jugar un poco con los números para llegar a un lugar cercano (para varias muestras de dominios para los que recordé las relaciones públicas) a las antiguas relaciones públicas de Google. A continuación se muestran algunos resultados de PageRank de ejemplo:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Aquí está una parcela de 100.000 muestras aleatorias. La puntuación del PageRank calculada está a lo largo del eje Y, y la puntuación de búsqueda común original está a lo largo del eje X.
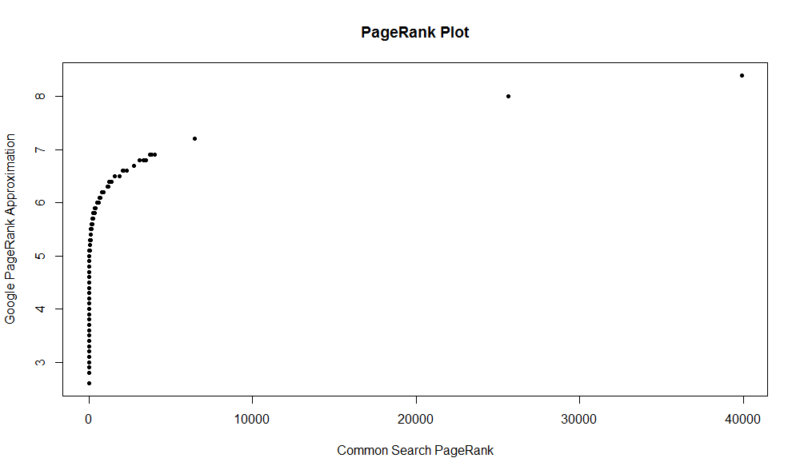
Para obtener sus propios resultados, puede ejecutar el siguiente comando en R (Simplemente sustituya su propio dominio):
df

Tenga en cuenta que este conjunto de datos solo tiene el primer millón de dominios por PageRank, por lo que de los 112 millones de dominios que se indexan en búsquedas Comunes, es muy probable que su sitio no esté allí si no tiene un perfil de enlaces bastante bueno. Además, esta métrica no incluye ninguna indicación de la nocividad de los enlaces, solo una aproximación de la popularidad de su sitio con respecto a los enlaces.
Búsqueda Común es una gran herramienta y una gran base. Estoy deseando involucrarme más con la comunidad de allí y, con suerte, aprender a comprender mejor los detalles detrás de los motores de búsqueda trabajando realmente en uno. Con R y un poco de código, puede tener una forma rápida de verificar las relaciones públicas de un millón de dominios en cuestión de segundos. Espero que hayan disfrutado!
Regístrate en nuestros resúmenes diarios del cambiante panorama del marketing de búsqueda.
Nota: Al enviar este formulario, usted acepta los términos de Third Door Media. Respetamos su privacidad.
Sobre El Autor

JR Oakes es el director de técnica SEO de investigación en la Locomotora. Anteriormente fue director de SEO técnico en la agencia Adapt Partners. Trabaja con clientes en una amplia gama de frentes, incluidos problemas técnicos, rendimiento, CTR, capacidad de rastreo, contenido y análisis de datos. A JR le encantan las soluciones de prueba, codificación y creación de prototipos para problemas difíciles de marketing de búsqueda. Cuando no está trabajando, le gusta leer sobre tecnologías emergentes, tocar el bajo, ver baloncesto universitario, cocinar y pasar tiempo con sus amigos y familiares. También es uno de los coorganizadores de Raleigh SEO Meetup, Raleigh SEO Conference y RTP SEO Meetup.