Evolución del sistema de programación de clústeres
Kubernetes se ha convertido en el estándar de facto en el área de la orquestación de contenedores. Todas las aplicaciones se desarrollarán y ejecutarán en Kubernetes en el futuro. El propósito de esta serie de artículos es presentar los principios de implementación subyacentes de Kubernetes de una manera profunda y sencilla.
Kubernetes es un sistema de programación de clústeres. Este artículo presenta principalmente algunas arquitecturas de sistemas de programación de clústeres anteriores de Kubernetes. Al analizar sus ideas de diseño y las características de la arquitectura, podemos estudiar el proceso de evolución de la arquitectura del sistema de programación de clústeres y el problema principal que debe considerarse en el diseño de la arquitectura. Eso será muy útil para entender la arquitectura de Kubernetes.
Necesitamos entender algunos de los conceptos básicos del sistema de programación de clústeres, para que quede claro, explicaré el concepto a través de un ejemplo, supongamos que queremos implementar un Cron distribuido. El sistema administra un conjunto de hosts Linux. El usuario define el trabajo a través de la API proporcionada por el sistema. el sistema realizará periódicamente la tarea correspondiente en función de la definición de la tarea, en este ejemplo, los conceptos básicos se encuentran a continuación:
- Clúster: los hosts Linux administrados por este sistema forman un grupo de recursos para ejecutar tareas. Este grupo de recursos se denomina Clúster.
- Trabajo: Define cómo el clúster realiza sus tareas. En este ejemplo, Crontab es exactamente un trabajo simple que muestra claramente lo que debe hacer(script de ejecución) a qué hora (intervalo de tiempo).La definición de algunos trabajos es más compleja, como la definición de un trabajo que debe completarse en varias tareas, y las dependencias entre tareas, así como los requisitos de recursos de cada tarea.
- Tarea: Un trabajo debe programarse en tareas de rendimiento específicas. Si definimos un trabajo para realizar un script a la 1 de la mañana todas las noches, entonces el proceso de script realizado a la 1 de la mañana todos los días es una Tarea.
Al diseñar el sistema de programación de clústeres, las tareas principales del sistema son dos:
- Programación de tareas: Una vez que los trabajos se envían al sistema de programación de clústeres, los trabajos enviados deben dividirse en tareas de ejecución específicas y los resultados de ejecución de las tareas deben rastrearse y monitorizarse. En el ejemplo del Cron distribuido, el sistema de programación debe iniciar el proceso a tiempo de acuerdo con los requisitos de la operación. Si el proceso no se realiza, el reintento es necesario, etc. En algunos escenarios complejos, como Hadoop Map Reduce, el sistema de programación debe dividir la tarea Map Reduce en el Mapa múltiple correspondiente y Reducir tareas, y, en última instancia, obtener los datos del resultado de ejecución de la tarea.
- Programación de recursos: se utiliza esencialmente para hacer coincidir tareas y recursos, y se asignan los recursos adecuados para ejecutar tareas de acuerdo con el uso de recursos de los hosts en el clúster. Es similar al proceso de algoritmo de programación del sistema operativo, el objetivo principal de la programación de recursos es mejorar la utilización de los recursos en la medida de lo posible y reducir el tiempo de espera para las tareas bajo la condición del suministro fijo de recursos, y reducir el retraso de la tarea o el tiempo de respuesta (si es una tarea por lotes, se refiere al tiempo de inicio a fin de las operaciones de tarea, si se trata de tareas de tipo de respuesta en línea, como aplicaciones web, que se refiere al tiempo de respuesta de cada solicitud), la prioridad de la tarea debe tomarse en consideración posible (los recursos se asignan equitativamente a todas las tareas). Algunos de estos objetivos son contradictorios y deben ser equilibrados, como la utilización de los recursos, el tiempo de respuesta, la equidad y las prioridades.
Hadoop MRv1
Map Reduce es un tipo de modelo de computación paralela. Hadoop puede ejecutar este tipo de plataforma de gestión de clústeres de computación paralela. MRv1 es la versión de primera generación del motor de programación de tareas Map Reduce de la plataforma Hadoop. En resumen, MRv1 es responsable de programar y ejecutar el trabajo en el clúster, y volver a los resultados de cálculo cuando un usuario define un cálculo de reducción de mapa y lo envía al Hadoop. Así es como se ve la arquitectura de MRv1:
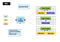
La arquitectura es relativamente simple, la arquitectura Maestro / Esclavo estándar tiene dos componentes principales:
- El rastreador de trabajos es el componente principal de administración del clúster, que es responsable de la programación de recursos y la programación de tareas.
- El rastreador de tareas se ejecuta en cada máquina del clúster, que es responsable de ejecutar tareas específicas en el host y del estado de los informes.
Con la popularidad de Hadoop y el aumento de varias demandas, MRv1 tiene los siguientes problemas que mejorar:
- El rendimiento tiene un cierto cuello de botella: el número máximo de nodos que admiten la administración es de 5.000, y el número máximo de tareas de operación de soporte es de 40.000. Todavía hay margen de mejora.
- No es lo suficientemente flexible para extender o admitir otros tipos de tareas. Además de las tareas de tipo reducido de mapas, hay muchos otros tipos de tareas en el ecosistema de Hadoop que deben programarse, como Spark, Hive, HBase, Storm, Oozie, etc. Por lo tanto, se necesita un sistema de programación más general, que pueda admitir y extender más tipos de tareas
- Bajo uso de recursos: MRv1 configura estáticamente un número fijo de ranuras para cada nodo, y cada ranura solo se puede usar para el tipo de tarea específico (Mapear o Reducir), lo que genera el problema de la utilización de recursos. Por ejemplo, un gran número de tareas de mapas están en cola para recursos inactivos, pero de hecho, un gran número de ranuras de reducción están inactivas para máquinas.
- Problemas de varios alquileres y varias versiones. Por ejemplo, diferentes departamentos ejecutan tareas en el mismo clúster, pero están aislados lógicamente entre sí, o ejecutan diferentes versiones de Hadoop en el mismo clúster.
YARN
YARN (Otro Negociador de recursos) es una segunda generación de Hadoop ,el propósito principal es resolver todo tipo de problemas en MRv1. La arquitectura de hilo se ve así:

La simple comprensión de YARN es que la principal mejora sobre MRv1 es dividir las responsabilidades del JobTrack original en dos componentes diferentes: Administrador de recursos y Maestro de aplicaciones
- Administrador de recursos: Es responsable de la programación de recursos, administra todos los recursos, asigna recursos a diferentes tipos de tareas y extiende fácilmente el algoritmo de programación de recursos a través de una arquitectura conectable.
- Maestro de aplicaciones: Es responsable de la programación de tareas. Cada trabajo (llamado Aplicación en YARN) inicia un Maestro de aplicaciones correspondiente, que es responsable de dividir el trabajo en tareas específicas y solicitar recursos del Administrador de recursos, iniciar la tarea, rastrear el estado de la tarea e informar los resultados.
Echemos un vistazo a cómo este cambio de arquitectura resolvió varios problemas de MRv1:
- Divida las responsabilidades de programación de tareas originales de Job Tracker y obtenga mejoras significativas en el rendimiento. Las responsabilidades de programación de tareas del Rastreador de trabajos original se dividieron para ser realizadas por el Maestro de aplicaciones, y el Maestro de aplicaciones se distribuyó, cada instancia solo manejó la solicitud de un trabajo, por lo que promovió el número máximo de nodos de clúster de 5,000 a 10,000.
- Los componentes de programación de tareas, Maestro de aplicaciones y programación de recursos se desacoplan y se crean dinámicamente en función de las solicitudes de trabajo. Una instancia Maestra de aplicaciones es responsable de un solo trabajo de programación, lo que facilita la compatibilidad con diferentes tipos de trabajos.
- Se introduce la tecnología de aislamiento de contenedores, cada tarea se ejecuta en un contenedor aislado, lo que mejora en gran medida la utilización de recursos de acuerdo con la demanda de recursos de la tarea que se pueden asignar dinámicamente. La desventaja de esto es que la administración y asignación de recursos de YARN solo tienen una dimensión de memoria.
Arquitectura Mesos
El objetivo de diseño de YARN sigue siendo servir a la programación del ecosistema Hadoop. El objetivo de Mesos se acerca, está diseñado para ser un sistema de programación general, que puede administrar la operación de todo el centro de datos. Como vemos, el diseño arquitectónico de Mesos usó mucho HILO como referencia, la programación de trabajos y la programación de recursos están a cargo de los diferentes módulos por separado. Pero la mayor diferencia entre Mesos e HILADO es la forma de programar los recursos, un mecanismo único llamado Oferta de recursos está diseñado. La presión de la programación de recursos se libera aún más, y la escalabilidad de la programación de trabajos también aumenta.

Los componentes principales de Mesos son:
- Mesos Master: Es un componente responsable exclusivo de la asignación de Recursos y los componentes de la administración, que es el Administrador de Recursos correspondiente al HILO interno. Pero el modo de operación es ligeramente diferente si se discutirá más adelante.Marco
- : es responsable de la programación de trabajos, los diferentes tipos de trabajos tendrán un Marco correspondiente, como el marco Spark que es responsable de los trabajos Spark.
Oferta de recursos de Mesos
Puede parecer que las arquitecturas Mesos y YARN son bastante similares, pero, de hecho, en el aspecto de la gestión de Recursos, el Maestro de Mesos tiene un mecanismo de Oferta de Recursos muy único (y algo extraño:
- EL HILO es Tirar: Los recursos proporcionados por el Administrador de recursos en YARN son pasivos,cuando los consumidores de recursos (Maestro de aplicaciones) necesitan recursos, puede llamar a la interfaz del Administrador de recursos para obtener recursos, y el Administrador de recursos solo responde pasivamente a las necesidades del Maestro de aplicaciones.
- Mesos es Push: Los recursos proporcionados por Master of Mesos son proactivos. Maestro de Mesos tomará regularmente la iniciativa de empujar todos los recursos disponibles actuales (las llamadas Ofertas de Recursos, lo llamaré Oferta de ahora en adelante) al Marco. Si hay tareas que el Framework debe realizar, no puede solicitar recursos de forma activa, a menos que se reciban las ofertas. Framework selecciona un recurso calificado de la Oferta para aceptar (esta moción se llama Aceptar en Mesos) y rechazar las ofertas restantes (esta moción se llama Rechazar). Si no hay suficientes recursos calificados en esta ronda de Oferta, tenemos que esperar a que la próxima ronda de Master proporcione la Oferta.
Creo que cuando veas este mecanismo de Oferta activo, tendrás la misma sensación conmigo. Es decir, la eficiencia es relativamente baja, y surgirán los siguientes problemas:
- la eficiencia en la toma de decisiones de cualquier Marco afecta a la eficiencia general. Por coherencia, Master solo puede proporcionar una Oferta a un Marco a la vez, y esperar a que el Marco seleccione la Oferta antes de proporcionar el resto al siguiente marco. De esta manera, la eficiencia de la toma de decisiones de cualquier Marco afectará a la eficiencia general.
- “perder” mucho tiempo en frameworks que no requieren recursos. Mesos no sabe realmente qué Marco necesita recursos. Por lo tanto, habrá un Marco con necesidades de recursos que se está haciendo cola para la Oferta, pero el Marco sin necesidades de recursos recibe la Oferta con frecuencia.
En respuesta a los problemas anteriores, Mesos ha proporcionado algunos mecanismos para mitigar los problemas, como establecer un tiempo de espera para que el Marco de Trabajo tome decisiones, o permitir que el Marco de trabajo rechace ofertas configurándolo como estado de Supresión. Dado que no es el centro de esta discusión, los detalles se descuidan aquí.
De hecho, hay algunas ventajas obvias para los Mesos que usan este mecanismo de oferta activa:
- El rendimiento es evidentemente mejorado. Un clúster puede admitir hasta 100 000 nodos según las pruebas de simulación, para el entorno de producción de Twitter, el clúster más grande puede admitir 80 000 nodos. la razón principal es que la oferta activa del mecanismo Maestro Mesos simplifica aún más las responsabilidades de los Mesos. el proceso de programación de recursos, emparejamiento de recursos a tareas, en Mesos se divide en dos etapas: recursos para Ofrecer y Ofrecer a tareas. El Maestro Mesos solo es responsable de completar la primera fase, y la correspondencia de la segunda fase se deja al Marco.
- Más flexible y capaz de cumplir con políticas de programación de tareas más responsables. Por ejemplo, la estrategia de uso de recursos de All Or Nothings.
Algoritmo de programación de Mesos DRF (Equidad de Recursos Dominante)
En cuanto al algoritmo DRF, en realidad no tiene nada que ver con nuestro entendimiento de la arquitectura de Mesos, pero es muy básico e importante en Mesos, así que explicaré un poco más aquí.
Como se mencionó anteriormente, Mesos proporciona Oferta al Marco a su vez, por lo que ¿qué Marco debe seleccionarse para proporcionar Oferta cada vez? Este es el problema central que debe resolver el algoritmo DRF. El principio básico es tener en cuenta tanto la equidad como la eficiencia. Al tiempo que se satisfacen todas las necesidades de recursos del Marco, debe ser lo más justo posible evitar que un Marco consuma demasiados recursos y deje morir de hambre a otros marcos.
DRF es una variante del algoritmo de equidad min-max. En términos simples, es seleccionar el Marco con el Uso de Recursos Dominante más bajo para proporcionar la Oferta cada vez. ¿Cómo calcular el Uso Dominante de Recursos del Framework? De todos los tipos de recursos ocupados por el marco, se selecciona como Recurso Dominante el tipo de recurso con la tasa de ocupación de recursos más baja. Su tasa de ocupación de recursos es exactamente el Uso de Recursos Dominante del Marco. Por ejemplo, una CPU de Framework ocupa el 20% del Recurso total, el 30% de la memoria y el 10% del disco. Por lo tanto, el uso de recursos dominante del Marco será del 10%, el término oficial llama a un disco como recurso dominante, y este 10% se llama Uso de Recursos dominante.
El objetivo final del DRF es distribuir los recursos por igual entre todos los marcos. Si un Framework X acepta demasiados recursos en esta ronda de Oferta, tomará mucho más tiempo obtener la oportunidad de la siguiente ronda de Oferta. Sin embargo, los lectores cuidadosos encontrarán que hay una suposición en este algoritmo, es decir, después de que el Marco acepte recursos, los liberará rápidamente, de lo contrario habrá dos consecuencias:
- Otros marcos mueren de hambre. Un marco A acepta la mayoría de los recursos del clúster a la vez, y la tarea se sigue ejecutando sin salir, de modo que la mayoría de los recursos están ocupados por el marco A todo el tiempo, y otros marcos ya no obtendrán los recursos.
- Muere de hambre. Debido a que el uso de recursos dominante de este marco siempre es muy alto, por lo que no hay posibilidad de obtener una oferta durante mucho tiempo, por lo que no se pueden ejecutar más tareas.
Por lo tanto, Mesos solo es apto para programar tareas cortas, y los Mesos se diseñaron originalmente para tareas cortas de centros de datos.
Resumen
De la arquitectura grande, toda la arquitectura del sistema de programación es arquitectura Maestra / esclava, el extremo esclavo se instala en cada máquina con requisitos de administración, que se utiliza para recopilar información del host y realizar tareas en el host. Master es principalmente responsable de la programación de recursos y la programación de tareas. La programación de recursos tiene mayores requisitos de rendimiento y la programación de tareas tiene mayores requisitos de escalabilidad. La tendencia general es discutir los dos tipos de desacoplamiento del deber y completarlos por diferentes componentes.
