Indexación secundaria distribuida escalable en Scylla

El modelo de datos de Scylla y Apache Cassandra divide los datos entre nodos de clúster mediante una clave de partición definida por el esquema de base de datos. El uso de una clave de partición proporciona una forma eficiente de buscar filas con la clave de partición, ya que puede encontrar el nodo que posee la fila mediante el hash de la clave de partición. Desafortunadamente, esto también significa que encontrar una fila usando una clave que no sea de partición requiere un análisis completo de la tabla que es ineficiente. Los índices secundarios son un mecanismo en Apache Cassandra que permite búsquedas eficientes en claves que no son de partición mediante la creación de un índice.
En esta entrada de blog aprenderás:
- Cómo implementa Apache Cassandra Índices secundarios mediante indexación local
- Por qué decidimos adoptar una estrategia de implementación diferente para Scylla mediante indexación global
- Cómo afecta la indexación global cómo debe usar la Indexación secundaria
- Cómo crear sus propios Índices Secundarios y usarlos en sus consultas CQL de aplicación
El tamaño de un índice es proporcional al tamaño de los datos indexados. Como los datos en Scylla y Apache Cassandra se distribuyen a varios nodos, no es práctico almacenar todo el índice en un solo nodo. Apache Cassandra implementa Índices secundarios como índices locales, lo que significa que el índice se almacena en el mismo nodo que los datos que se indexan desde ese nodo. La ventaja de un índice local es que las escrituras son muy rápidas, pero la desventaja es que las lecturas tienen que consultar potencialmente cada nodo para encontrar el índice en el que realizar una búsqueda, lo que hace que los índices locales no se puedan escalar en clústeres grandes. Además de los índices secundarios nativos, Apache Cassandra también tiene otro esquema de indexación local, SSTable Attached Secondary Index (SASI), que admite consultas y búsquedas complejas. Sin embargo, desde el punto de vista de la escalabilidad, tiene exactamente las mismas características que los índices secundarios originales.
Las vistas materializadas en Scylla y Apache Cassandra son un mecanismo para desnormalizar automáticamente los datos de una tabla base a una tabla de vistas utilizando una clave de partición diferente. Esto resuelve el problema de escalabilidad de los índices locales, pero tiene un costo de almacenamiento porque necesita duplicar toda la tabla en el peor de los casos. Por lo tanto, las vistas materializadas no sustituyen a los índices secundarios para todos los casos de uso. Sin embargo, las Vistas Materializadas proporcionan la infraestructura necesaria para implementar Índices Secundarios utilizando la indexación global, que es el enfoque de implementación adoptado para Scylla.
Indexación global
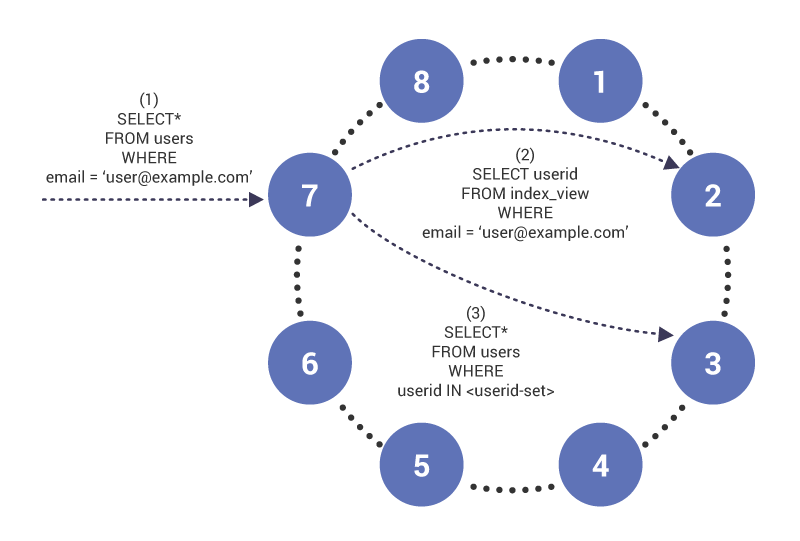
Scylla adopta un enfoque diferente al de Apache Cassandra e implementa Índices secundarios utilizando indexación global. Con la indexación global, se crea una Vista materializada para cada índice. La Vista materializada tiene la columna indexada como clave de partición y la clave primaria (clave de partición y claves de agrupamiento) de la fila indexada como claves de agrupamiento. Scylla divide las consultas indexadas en dos partes: (1) una consulta en la tabla de índice para recuperar las claves de partición de la tabla indexada y (2) una consulta a la tabla indexada utilizando las claves de partición recuperadas. El beneficio de este enfoque es que podemos usar el valor de la columna indexada para encontrar la fila de la tabla de índice correspondiente en el clúster para que las lecturas sean escalables. La desventaja del enfoque es que las escrituras son más lentas que con la indexación local debido a toda la sobrecarga de mantener la vista de índice actualizada.
La consulta en una columna indexada se ve de la siguiente manera. Supongamos que una tabla se ve así:
Y una consulta en la columna email, que no es una clave de partición, pero tiene un índice:
En la fase (1), la consulta llega al nodo 7, que actúa como coordinador de la consulta. El nodo se da cuenta de que estamos consultando en una columna indexada y, por lo tanto, en la fase (2), emite una tabla de lectura a índice en el nodo 2, que tiene la fila de la tabla de índice para “”. La consulta devuelve un conjunto de ID de usuario que se utilizan en la fase (3) para recuperar el contenido de la tabla indexada.
Ejemplo
primero Tenemos que crear un esquema. En este ejemplo, tenemos una tabla que representa la información del usuario con userid como clave de partición y nombre, correo electrónico y país como columnas regulares:
Luego rellenamos la tabla con algunos datos de prueba generados con Mockaroo:
Los índices secundarios están diseñados para permitir consultas eficientes de columnas que no son claves de partición. Si bien Apache Cassandra también admite consultas en columnas de claves que no son de partición utilizando ALLOW FILTERING, eso es muy ineficiente (requiere escanear toda la tabla) y actualmente Scylla no es compatible (consulte el número 2200 para obtener más detalles).
Puede indexar columnas de tabla con la instrucción CREATE INDEX. Por ejemplo, para crear índices para columnas de correo electrónico y país, ejecute las siguientes instrucciones CQL:
Scylla crea automáticamente una Vista materializada que tiene la columna indexada como clave de partición y la clave primaria de la tabla de destino (clave de partición y claves de agrupamiento) como claves de agrupamiento.
Por ejemplo, la Vista materializada para el índice en la columna email se ve de la siguiente manera:
Si la vista anterior se creara como una tabla normal, se vería de la siguiente manera:
La columna email se utiliza como clave de partición para la tabla de índice y userid se incluye como clave de agrupamiento, lo que nos permite encontrar eficientemente claves de partición para la tabla de destino utilizando solo email.
Puede usar el comando DESCRIBE para ver todo el esquema de la tabla ks.users, incluidos los índices y vistas creados:
Ahora con el Índice Secundario en su lugar, puede consultar columnas indexadas como si fueran claves de partición:
¡Hemos terminado con el ejemplo!
¿Cuándo usar índices secundarios?
Los índices secundarios son (en su mayoría) transparentes para la aplicación. Las consultas tienen acceso a todas las columnas de la tabla y puede agregar y eliminar índices sin cambiar la aplicación. Los índices secundarios también pueden tener menos sobrecarga de almacenamiento que las Vistas Materializadas porque los índices secundarios solo necesitan duplicar la columna indexada y la clave primaria, no las columnas consultadas, como en una Vista Materializada. Además, por la misma razón, las actualizaciones pueden ser más eficientes con índices secundarios porque solo los cambios en la clave primaria y la columna indexada causan una actualización en la vista de índice. En el caso de una vista materializada, una actualización de cualquiera de las columnas que aparecen en la vista requiere que se actualice la vista de respaldo.
Como siempre, la decisión de usar Índices Secundarios o Vistas Materializadas realmente depende de los requisitos de su aplicación. Si necesita el máximo rendimiento y es probable que consulte un conjunto específico de columnas, debe usar Vistas materializadas. Sin embargo, si la aplicación necesita consultar diferentes conjuntos de columnas, los índices secundarios son una mejor opción porque se pueden agregar y eliminar con menos carga de almacenamiento, dependiendo de las necesidades de la aplicación.
¿Desea obtener más información sobre los índices secundarios? Echa un vistazo a mi presentación de Scylla Summit 2017 en SlideShare. Si desea probar esta característica, se espera que esté en la próxima versión de Scylla 2.2.